
基于项目反应理论的公开招聘考试的最优题型选择
2016-06-05 14:18:00陈冠宇熊碧莲姜亚丽陈海平栗小霞
中国考试 2016年1期
陈冠宇 熊碧莲 李 霓 姜亚丽 陈海平 丁 玎 栗小霞
基于项目反应理论的公开招聘考试的最优题型选择
陈冠宇1熊碧莲1李 霓1姜亚丽1陈海平1丁 玎2栗小霞2
本研究基于项目反应理论,探索题目变动的公开招聘考试的最优题型。利用《北京市新进人员通用能力考试》专业技术岗位1 000名考生成绩,通过探索性因素分析保证仅包含一个维度的情况下,使用项目反应理论等级反应模型分析10个题型的性能。先将各个题型不同题目的得分加和,将不同得分的频数转换为等级,分别计算区分度、难度、类别反应曲线和信息函数。最优题型用两种方法确定,一是选取信息量占比高于均值的题型,二是排除各种参数达不到常用标准的题型。两种方法得到非常接近的结果,即逻辑推理、图表解读、短文加工、阅读理解四个题型最优。
项目反应理论;经典测量理论;等级反应模型;类别反应曲线
1 引言
《北京市新进人员通用能力考试》(以下简称《通用能力考试》)是北京市事业单位公开招聘考试,2012年开始推广使用。它基于北京市事业单位公开招聘工作人员的基本需要研发,重点考察进入事业单位岗位工作所需的公共基本能力。报考岗位分为管理岗、专业技术岗和工勤岗,每种岗位使用一套试卷,其中管理岗和专业技术岗采用的题型较多,考试时间为150分钟。为了提高《通用能力考试》针对不同岗位考查的有效性,同时减少考试时间,以提高考试的效度和效率,有必要探索其最优题型。
根据经典测量理论筛选最优题型的统计方法存在局限性。[1-2]经典测量理论对于测验项目的分析主要通过项目的难度和区分度进行,受样本量和样本特征等因素的影响,故不能很好地估计项目特性。[3]而项目反应理论对信效度以及潜在作答反应的理解不同于经典测量理论,并且提供经典测量理论所没有的信息。[4]项目反应理论有以下优点:①项目反应理论用信息量代替信度概念,能够借助信息函数(Information Function)针对不同考生精确估计每个项目及测验的测量误差,[5]给不同能力水平考生的估计提供了独立的信度指标。②基于不同能力水平、项目区分度和作答结果之间的关系,能够考察题目对不同能力考生的区分情况,不会因为由于简单选择与总分相关的项目导致因素结构变化。即使是多因素结构,只要应用多维项目反应理论(Multidimensional Item Response Theory)就不会出现类似问题。[6]③项目反应理论的参数估计不依赖于样本量和项目量,具有参数不变性。[7]也就是说项目反应理论在排除随机误差的情况下,对于项目参数而言,在不同总体下的估计值应该是一致的,这意味着简版的信效度与完整版没有区别。因此,项目反应理论能够避开传统简版测验开发存在的问题,保证简版测验的质量。
鉴于《通用能力考试》的特点,本研究采用项目反应理论的等级反应模型(Graded Response Model,GRM)进行分析。GRM将各个题型的题目进行合并,作为多级评分项目进行处理,可以消除题组内项目间的相依问题。[8]GRM根据各个项目的积累反应分布,计算出不同分数等级之间的阈值。[9]GRM用θ表示考生能力水平,假定其平均数为0,方差为1,理论上θ的取值范围为正无穷到负无穷,一般为了方便讨论限制为[-3,3],但并不意味着一定服从正态分布。[10]GRM每道题目的类别反应曲线(Catego⁃ry Response Curve,CRC)通过难度参数b提供特质水平一定情况下所有选项的作答概率,同时通过项目区分度参数a来估计不同特质水平下项目的区分情况。类别反应曲线揭示不同能力考生在不同题型上取得不同得分的概率,一个具有良好检验力的项目应该保证能力越高的考生越有可能得高分,能力越低的考生得低分的可能性越大。项目信息函数是项目反应理论用来刻画一个测试或一道试题有效性的工具,反映不同特性的项目在评价不同考生能力水平时的信息贡献关系,[11]实现对不同项目的评价。项目提供的信息量越大,表明这个项目在评价此能力水平时越有价值。
2 研究方法
2.1 研究数据
本研究的数据来自于《通用能力考试》2011年 3月1 000名专业技术岗考生的考试成绩(学生版的IRTPRO统计软件限制,样本量不能超过1 000)。前期研究表明,《通用能力考试》具有良好的信效度,经过连续5年的实际应用,用人单位反应良好。[12-14]专业技术岗的《通用能力考试》共有10种题型,分别是时新知识、空间关系、逻辑推理、文稿校对、句段排序、阅读理解、图表解读、图形比较、短文加工及实用写作。除空间关系、逻辑推理、句段排序、阅读理解和图表解读这些传统题型外,采用的新题型经过了专家论证和研究分析,证明了其有效性。[15]目前它已经成为北京市事业单位进人的基本考试,每次更换题目但题型保持不变。
2.2 验证性因素分析
使用项目反应理论对题目进行分析必须考虑拟合度(goodness of fit),如果拟合度过低则其研究结果没有意义。目前对项目反应理论的模型拟合研究并没有给出一个绝对的标准,[16-18]一般认为基本的要求是满足单维度假设,建议使用验证性因素分析来证实。[19]本研究采用LISREL 8.8进行验证性因素分析,检验10个题型仅包含一个因素的假设。验证性因素分析的结果为:χ2=74.09,df=35,P= 0.00013,RMSEA=0.029,CFI=0.99,NNFI=0.98,表明满足GRM的单维度假设,10个题型仅仅测量一个因素。
2.3 项目反应理论的计算
采用IRTPRO 3.1对各个题型的总分进行项目反应理论的分析。按照GRM先要对同一项目的不同等级进行分析。只要各个等级分布了全距足够大的考生能力水平,那么项目参数的估计就不依赖于具体的考生样本群体及分布。[20]把各个题型的总分看作顺序变量,在不改变顺序的情况下,将一些人数过少的分数合并排列等级,尽量使得不同等级有足够的考生用于估计。10种题型转换后的等级数分别是8、4、7、8、5、6、7、7、8和6,各个等级确保有足够的不同能力的考生用于参数估计。
3 结果与分析
3.1 拟合度检验
使用IRTPRO软件对GRM进行拟合度分析,结果如表1所示。RMSEA(root-mean-square error of approximation)是近似误差均方根,评价模型不拟合的程度。一般地,RMSEA=0表示模型完全拟合,RMSEA<0.05表示模型接近拟合。本研究获得的RMSEA值为0,据此可认为《通用能力考试》数据能够完全拟合GRM。M2类似于卡方值,本研究中并不显著,表示模型可以接受。[21-22]

表1 模型拟合度检验
3.2 参数估计
把每个题型当作项目,采用最大似然法(Maxi⁃mum Likelihood Estimation)分析《通用能力考试》数据,估计出GRM的区分度参数和难度参数如表2所示。
a为该测验的项目区分度参数,b为难度参数。表2显示,《通用能力考试》10种题型的区分度在0.47~1.51,均值为0.96(SD=0.34)。根据既往的理论研究,a值在0.01~0.24为非常低,0.25~0.63为低,0.64~1.34为中等,1.35~1.69为高。[23]表2大部分题型区分度中等,其中时新知识和图形比较的区分度较低,而逻辑推理和阅读理解的区分度较高。
按照一般经验,参数b最好在-2~2之间,这样可以避免试题太难或太易的情况。将题型的得分转换为不同等级后,不同的等级有其相应的阈值参数,b1到b7代表了得分等级2到8的阈值参数(任何人得分在最低等级之上,所以不需要估计最低等级的阈值参数)。如空间关系有4个等级,等级2到等级4对应b1到b3。表2各个题型不同分数等级的难度参数在整个能力范围内分布并不均匀,难度梯级差有大有小,显示分数等级的难度递增不够平稳。所有题型都有小于-2.0的难度参数值,表明所有题型的最低分数等级很容易,绝大多数考生都可以获得这一分数;时新知识、文稿校对、句段排序、图表解读、图形比较以及实用写作6个题型都有大于2.0的难度参数,表明这些题型的高分等级难度比较大,而逻辑推理和短文加工两个题型的高分端难度接近2.0,尚属比较好,只有空间关系和阅读理解两个题型的最高分数等级的难度值小于2.0,显示这两个题型难度偏低,而时新知识和图形比较两个题型最高分数等级的难度值分别为5.08和4.20,显示这两个题型的高分等级很难,同时这两个题型的区分度最低。
3.3 类别反应曲线
类别反应曲线的横轴为考生的能力水平,从左至右代表能力由低到高,纵轴为作答正确的概率,从下到上代表答对的可能性由低到高,每一条曲线代表了不同能力水平的考生在该题型中获得相应等级分数的可能性。一般而言,性能好的项目中高能力的考生更有可能获得高等级分数。
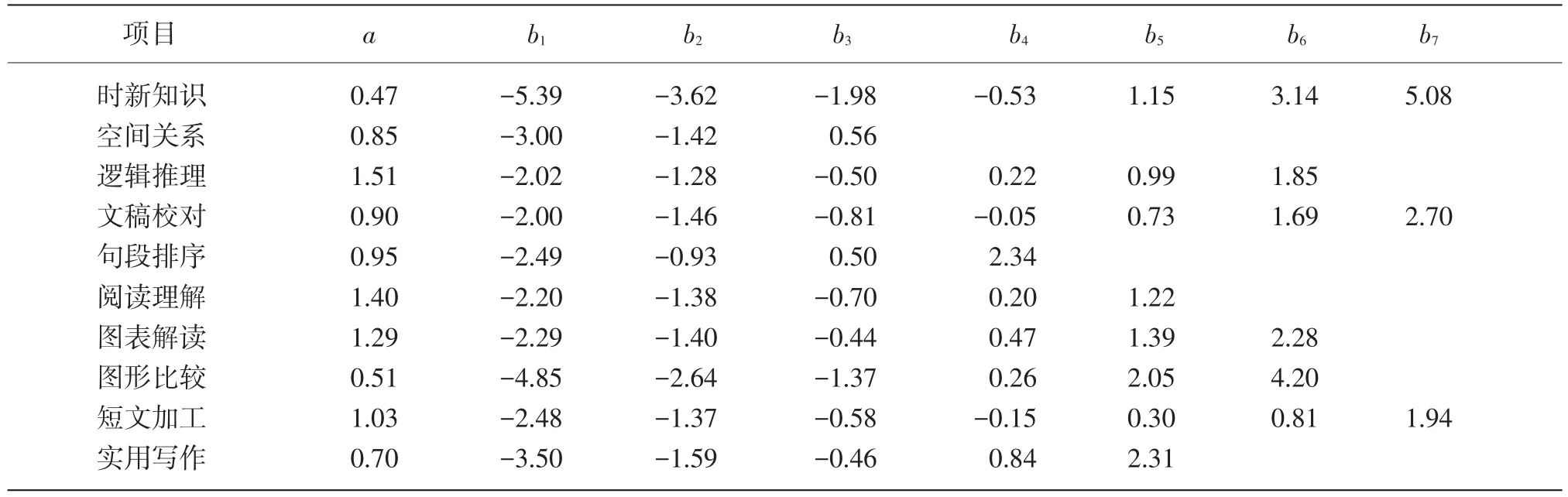
表2 《通用能力考试》专业技术岗题型参数
图1是10种题型的类别反应曲线。其中,时新知识和图形比较两个题型不同等级得分的曲线比较平坦(峰值小),彼此难以区分,表明其区分不同能力水平考生的效果较差。文稿校对和实用写作两个题型的中间等级峰值也偏小,曲线间难以区分,其他题型特别是逻辑推理、句段排序、图表解读、阅读理解对不同分数等级的区分都很理想。
3.4 题型的信息量
在项目反应理论中,信息量表示的是项目和测验在评价考生能力水平状态时所提供的信息的确定性水平。一道题的信息量越大,表示它对准确评价考生能力水平的贡献越大,也就能越准确地估计考生水平。
图2是10种题型的信息函数,表3是每种题型的信息总量以及占总测验信息量的比重。可以看到,各项目的信息量在2.22~19.38之间,占比在2.51%~19.38%之间。同时结合表2和图1,可知信息量低的题型对应的类别反应曲线都较为平坦且曲线重叠难以区分,而能够区别不同能力考生作答反应的题型,给出的信息量也更多。逻辑推理、句段排序、图表解读和短文加工4个题型的信息量较大,其信息量之和超过总信息量的2/3,达到67.79%。

图1 各题型的类别反应曲线
如上文所述:一道题的信息量越大,表示它对准确评价考生能力水平的贡献越大。同理,在一道题的角度上,题目提供的信息量在不同的能力水平上是不同的,出现最大的信息量的能力水平,即为题目区分度最高的位置,也就是说题目对于这一能力水平的被试提供了最大的信息量,最能区分这一能力水平的考生。表4显示,几乎所有题型最大信息量位置对应的都是平均水平以下的能力水平,即除文稿校对和图表解读两个题型外,其他题型区分度最高点对应的能力水准都低于群体平均水平,意味着大多数题型最适合区分的人群是低于平均水准的考生群体。

图2 项目信息函数
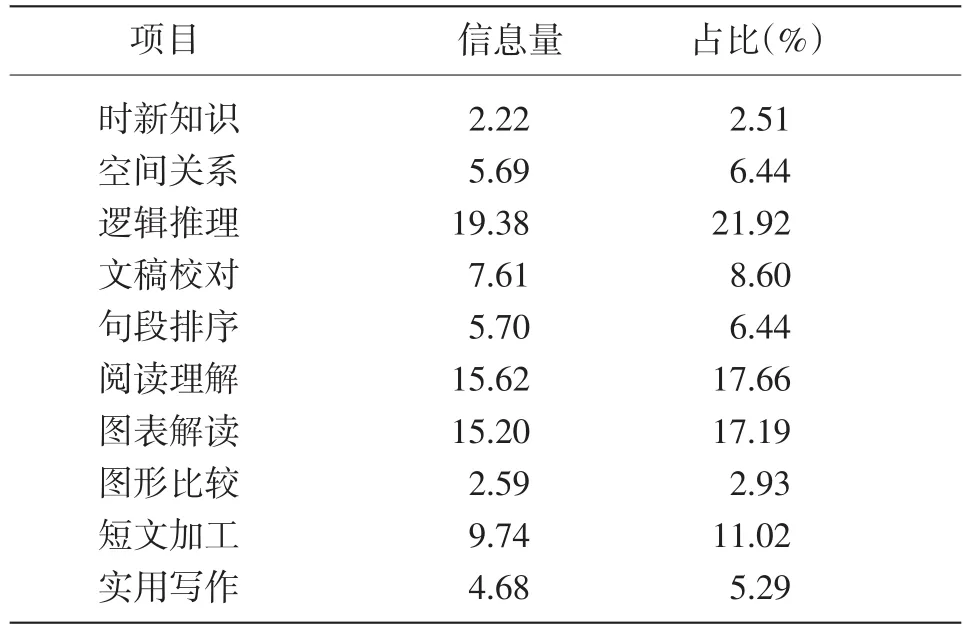
表3 测验项目信息量及其占比

表4 各题型最大信息量及其出现时所对应的能力水平(θ)

图3 测验信息函数
将各个题型对某一能力水平考生的信息量加和,就能得到测验信息函数(Test Information Func⁃ tion,TIF),反映整个《通用能力考试》对于该能力水平的考生提供了多少信息量。从图3能够清晰地看到《通用能力考试》对于考生能力水平评估的总体情况,图中虚线为逻辑推理、阅读理解、图表解读和短文加工4个信息量最大题型构成的简版考试信息量。可以看到,《通用能力考试》能在评估中等能力水平的考生时能提供最大的信息量,而对于能力水平较低的考生不能提供太多的信息,且能力水平升高时信息量快速下降。
4 结论
本研究通过项目反应理论的等级反应模型对《通用能力考试》进行最优题型分析,发现根据题型信息量占比大于均值得出的结果,与综合权衡区分度、难度、类别反应曲线和信息函数得出的最优题型都是逻辑推理、图表解读、短文加工、阅读理解。表2的区分度和等级难度参数值表明,《通用能力考试》既有容易得分的题型(阅读理解和空间关系),又有比较难的题型(时新知识和图形比较),两者结合既可以让考生得到一个基本分数,同时也能够有效拉开分数距离,为择优留出空间。
目前已经有研究者采用项目反应理论进行最优题型的分析,但还没有统一的标准。[24-25]常用的方法有两种:一是比较测验项目的信息函数,选择信息量较大的题目;[26]二是通过对信息量进行计算,求出测量的标准误,即(TIF即测验信息函数),并据此进行分析。[27]两种方法归根结底都是依赖测验信息函数,谋求简版测验的测验信息量尽可能接近完整版测验。本研究选择题型信息量占总信息量的比例进行取舍,所有题型平均占比为10%,占比高于此均值的题型有逻辑推理、阅读理解、图表解读和短文加工4个题型,表示它们最优。
另外,本研究认为最优题型可以结合区分度、难度、类别反应曲线和信息函数进行综合考虑。从区分度参数看,只有时新知识和图形比较没有达到要求;从难度参数看,只有空间关系不太理想;从类别反应曲线看,时新知识和图形比较较差,文稿校对和实用写作稍微差强人意;从题型的信息量看,时新知识和图形比较信息量最小,其次略显美中不足的是空间关系、句段排序和实用写作。综合上述结果,10种题型中,逻辑推理、图表解读、阅读理解和短文加工4种题型的各项指标都不错,是最优题型。
综合考虑的结果与上述信息量占比的选择结果相同,都是逻辑推理、图表解读、阅读理解和短文加工,与使用经典测量理论开发的《通用能力考试》简版最优题型一致,这4个题型构成的简版测验满足α型错误概率小于0.05、统计检验力达0.9以上、考生覆盖率达95%以上的标准。[28]显然,研究验证了根据经典测验理论的最优简版构成。
5 研究局限与展望
第一,考试数据。本研究选取的数据仅仅只是一次专业技术岗的考生成绩,由于不同岗位针对的考生不同,不同时间考试选取的具体题目不同,因此分析的结果可能会有误差的存在。虽然项目反应理论不依赖于具体样本,但是仍然会受到随机误差的影响。[29]
第二,等级划分。根据频数分布将测验总分转换为等级数据,从某种意义而言是减少了题目提供的信息,同时忽视了猜测的可能性,并且可能高估总体测验的信息量。[30]因此进一步研究可以考虑采用承认相依性的题组模型(testlet model)。
要指出的是,本研究以及既往的简版研究都是以专业技术岗的某一次考试成绩为依据,这个结论是否适合其他岗位的《通用能力考试》,以及每次考试是否会因为考生样本、考试题目的变动而影响最优题型的确定,还有待追踪。
[1]Daseking,M.,Petermann,F.,&Waldmann.H.Estimation of Gener⁃al Intelligence in Neurological Settings by a Short Form of the WAIS-IV[J].Aktuelle Neurologie,2014,41(6):349-355.
[2][28]陈海平,姜亚丽,车宏生.事业单位新进人员通用能力考试最优简版探究[J].北京师范大学学报(自然科学版),2015(3): 320-325.
[3]Cohen,J.The statistical power of abnormal-social psychological re⁃search:A review[J].Journal of abnormal and social psychology, 1962,65(3):145-153.
[4]Akiskal,H.S.,Mendlowicz,M.V.,Jean-Louis,G.,et al.TEMPSA:validation of a short version of a self-rated instrument designed to measure variations in temperament[J].Journal of Affective Disor⁃ders,2005,85(1):45-52.
[5][20]Theiling,J.,&Petermann,F.Neuropsychological Profiles on the WAIS-IV of ADHD Adults[J/OL].Journal of attention disorders, 2014:1509099359.[2015-09-20].http://jad.sagepub.com/content/ early/2014/01/21/1087054713518241.abstract.
[6]杜文久,肖涵敏.多维项目反应理论等级反应模型[J].心理学报, 2012(10):1402-1407.
[7]Rupp,A.A.,&Zumbo,B.D.Understanding parameter invariance in unidimensional IRT models[J].Educational and Psychological Measurement,2006,66(1):63-84.
[8]Thissen,D.,Steinberg,L.,&Mooney,J.A.Trace Lines for Testlets: A Use of Multiple Categorical Response Models[J].Journal of Edu⁃cational Measurement,1989,26(3):247-260.
[9]Samejima,F.Evaluation of mathematical models for ordered poly⁃chotomous responses[J].Behaviormetrika,1996,23(1):17-35.
[10]Baker,F.B.The Basics of Item Response Theory(Second Edition)[M].ERIC Clearinghouse on Assessment and Evaluation,2001.
[11]罗照盛,欧阳雪莲,漆书青,等.项目反应理论等级反应模型项目信息量[J].心理学报,2008(11):1212-1220.
[12]陈海平,姜亚丽,车宏生.事业单位新进人员通用能力考试最优简版探究[J].北京师范大学学报(自然科学版),2015(3):320-325.
[13]陈海平,刘远我,张志红,等.我国事业单位公开招聘考试的现状与挑战——全国省地人事考试中心调查[C]//中国心理学会成立90周年纪念大会暨第十四届全国心理学学术会议.西安, 2011.
[14][15]朱凤艳,陈海平,车宏生,等.事业单位公开招聘考试新题型预试研究[J].心理学探新,2013(3):271-280.
[16]Drasgow,F.,Levine,M.V.,&Williams,E.A.Appropriateness measurement with polychotomous item response models and stan⁃dardized indices[J].British Journal of Mathematical and Statistical Psychology,1985,38(1):67-86.
[17][19]Hambleton,R.K.Fundamentals of item response theory[M]. Newbury Park:Sage publications,1991.
[18]Ostini,R.,&Nering,M.L.Polytomous item response theory mod⁃els[M].Thousand Oaks:Sage,2006.
[21]Maydeu-Olivares,A.,&Joe,H.Limited-and full-information esti⁃mation and goodness-of-fit testing in 2ncontingency tables:a uni⁃fied framework[J].Journal of the American Statistical Association, 2005,100(471):1009-1020.
[22]Maydeu-Olivares,A.,&Joe,H.Limited information goodness-offit testing in multidimensional contingency tables[J].Psychometri⁃ka,2006,71(4):713-732.
[23][24]Allen,V.,Rahman,N.,Weissman,A.,et al.The Situational Test of Emotional Management-Brief(STEM-B):Development and validation using item response theory and latent class analysis [J].Personality and Individual Differences,2015(81):195-200.
[25]Bourion-Bédès,S.,Schwan,R.,Epstein,J.,et al.Combination of classical test theory(CTT)and item response theory(IRT)analy⁃sis to study the psychometric properties of the French version of the Quality of Life Enjoyment and Satisfaction Questionnaire-Short Form(Q-LES-Q-SF)[J].Quality of Life Research,2015,24(2):287-293.
[26]Mueller,A.E.,Segal,D.L.,Gavett,B.,et al.Geriatric Anxiety Scale:item response theory analysis,differential item functioning, and creation of a ten-item short form(GAS-10)[J].International Psychogeriatrics,2014(7):1-13.
[27]Liu,Y.,Wang.J.,Hinds,P.S.,et al.The emotional distress of chil⁃dren with cancer in China:an item response analysis of C-Ped-PROMIS Anxiety and Depression short forms[J].Quality of Life Re⁃search,2014(6):1-11.
[29]罗照盛.项目反应理论基础[M].北京:北京师范大学出版社, 2012.
[30]Wang,X.,Bradlow,E.T.,&Wainer,H.A general Bayesian model for testlets:Theory and applications[J].ETS Research Report Se⁃ries,2002(1):37.
Choosing the Best Item Types of a Public Recruitment Examination based on Item Response Theory
CHEN Guanyu,XIONG Bilian,LI Ni,JIANG Yali,CHEN Haiping,DING Ding&LI Xiaoxia
This research based on Item Response Theory,explores the best item type of a public recruitment examination.By using the scores of 1 000 candidates who took the Basic Abilities Test of Beijing Public Institutions for a professional/technical position,the characteristics of its 10 subtests are analyzed with IRT Graded Response Model after its factors are confirmed to be only one through explorative factor analysis.The study firstly adds up the scores of all items of each subtest,then converts them into the graded ranks according to their frequency and gets their parameters of discrimination,difficulty,characteristic response curves(CRCs)and information function.Two methods were used to obtain the best subtests:one is to select a subtest that its information percentage is above the average of all subtests,the other one is to delete a subtest that its parameters do not meet normal standards.It is found that the two methods bring quite similar result:Logic Reasoning,Graph Comprehension,Essay Processing and Reading Comprehension are the best four item types,which confirms the conclusion from its analysis of Classical Testing Theory.
Item Response Theory;Classical Testing Theory;Graded Response Model;Category Response Curve
G405
A
1005-8427(2016)01-0039-8
本研究得到北京市人事考试中心委托课题“北京市事业单位同步考试数据分析及新题型完善”及北京师范大学哲学社会科学报告支持项目“基于大数据的我国彩票业发展监测平台研究”(编号:SKZZP2013003)资助。
陈海平,男,北京师范大学心理学院,博士
1北京师范大学心理学院(北京 100875)
2北京市人事考试中心(北京 100036)
猜你喜欢
中国校外教育(2019年12期)2019-04-15 11:14:34
西南交通大学学报(2018年5期)2018-11-08 10:59:16
江淮论坛(2018年4期)2018-08-24 01:22:30
趣味(语文)(2018年7期)2018-06-26 08:13:48
福建中学数学(2016年5期)2016-11-29 02:45:52
考试周刊(2016年88期)2016-11-24 13:30:50
新闻传播(2016年11期)2016-07-10 12:04:01
心理学探新(2015年3期)2015-12-27 06:25:14
计算机工程(2015年4期)2015-07-05 08:29:20
少年科学(2014年10期)2014-11-14 07:38:17
