
一种基于特征提取的教育视频资源推送方法*
2016-06-02 10:50:47文孟飞胡超于文涛刘伟荣
现代远程教育研究 2016年3期
□文孟飞 胡超 于文涛 刘伟荣
一种基于特征提取的教育视频资源推送方法*
□文孟飞胡超于文涛刘伟荣
摘要:丰富的网络教育视频资源满足了学习者自主选择学习内容、时间和地点的需求。然而资源自身及其平台存在着内容质量参差不齐、优质教育资源匮乏、资源同质化、资源推送方式单一等问题,学习者难以快速高效地从海量的资源中获取与自身需求相关的有价值的资源。为让学习者高效获取个性化教育视频资源,在进行资源推送时,研究采用深度学习方法准确识别出视频资源中的知识点,通过构造视频中的知识点、视频质量和学习者需求之间的特征向量作为支持向量机的输入,由支持向量机决定是否将视频资源推送给学习者。将学习者对推送结果的实际点击率和学习者反馈的满意度作为方法的性能评价指标。这种推送方法关注学习者的兴趣需求和视频特征的结合,能更好地满足学习者的要求并提升学习效率,具有较大的应用潜力。
关键词:教育视频资源;特征提取;深度学习;支持向量机;推送方法
一、引言
信息技术的快速发展和广泛应用深刻影响着人们的学习、工作和生活。互联网已成为人们搜索、获得和发布信息的重要平台,其自由开放的特性极大程度促进了教育资源的共建共享,信息技术对教育教学的革命性影响日趋明显,学习者通过信息化学习环境可以自主选择学习内容、时间和地点,突破了传统课堂教与学的模式。
教育资源在互联网上同时以文本、图片、声音和视频等多种形式呈现。其中,教育视频资源以其丰富生动的音频和图像信息,最类似于课堂上听和看的学习模式,吸引着众多学习者和教师的关注与使用。当前MOOC、微课、翻转课堂等的教育视频资源在飞速增长,然而这些教育视频资源为学习者提供丰富学习资源之时,也使学习者面临这样的一些问题(郭进成,2013):教育视频资源的内容质量参差不齐,优质教育资源少。教育资源共享平台多数仍是以物为主,忽略了学习者的个性化特征,为不同的学习对象提供相同的学习资源,不能从根本上满足用户的个性化学习需求;教育资源杂而多,学习者需要花费更多的时间和精力来寻找对自己真正有用的那部分资源。尤其是对于缺乏专业的搜索能力的学习者,这一问题特别突出,大大降低了学习效率。
国内外已有学者对资源推送方法进行了探索(Resnick et al.,1997;许海玲等2009;Linden et al., 2010),如基于内容的推送,基于关联规则的推送,基于协同过滤的推送,基于知识的推送等。这些传统的推送方法是研究推送的基础,但由于单个算法都有自身的限制,不能直接用于信息量大、知识点丰富的学校教育视频资源的推送上。因此亟需一种能根据学习者个性化需求,帮助和引导学习者快速获取所需资源的推送方法。研究在内容推送的基础上提出一种利用深度学习和支持向量机的基于特征提取的教育视频资源推送方法,以实现向学习者推送有效资源的目的。
二、资源推送现状及研究途径
Resnick和Varian于1997年提出的个性化推送系统为网络用户的有用信息快速获取带来了希望。个性化推送系统根据用户的个性需求特征主动地为用户推送可能感兴趣的信息资源,突破了传统完全靠人力获取资源的方式,其作为一种行之有效的获取有效资源的方法而得到了众多研究者和研究团体的广泛关注。
推送系统中最常用的推送方法是基于内容的推送和基于协同过滤的推送。基于内容的推送系统有Personal Web Watcher(Dunja,1996),Syskill & Webert(Michael et al.,1998)等;基于协同过滤的系统有SiteSeer(James et al.,1997),Let's Browse(Lieberman et al.,1999)。这些原型系统对个性化服务的设计与实现具有指导作用,但也都存在着很多不足。基于内容的推送结果直观且推送效率高,但难以区分资源的质量,只能根据用户已有兴趣发现相似兴趣资源,不能发现用户新兴趣。基于协同过滤的推送能够发现用户潜在的兴趣,但是不能准确识别相似用户。
传统推送系统的不足促使研究者对其进行相应的改进,并取得了一定的成果。CYCLADES(the Open Collaborative Virtual Archive Service Environment)系统采用基于用户的协同过滤技术,提供面向一般性推荐服务,它能为不同教学中产生的学习活动提供推荐,不仅仅适用于一个社区(Avancini et al.,2004)。Tang和Mccalla提出一种自我进化的智能推荐系统,该系统通过分析用户和系统的交互行为,从网上动态获取学习资源并集成到系统中,为学习者实时提供有效的学习内容(Tang & Mccalla,2004)。邢春晓等在传统协同过滤方法的基础上提出基于时间的数据权重和基于资源相似度的数据权重两种改进方案,从而及时反映用户兴趣变化(邢春晓等,2007)。何安(2007)提出协同过滤和聚类组合的推送方法,通过先将物品聚类,较好地减少数据稀疏性,再结合协同过滤方法来处理大量稀疏的数据。
以上算法均是针对单个推送算法的优化和两种推送方法的组合,而多种算法的融合为推送算法的改进提供了新的思路。王宏宇(2007)通过融合算法设计新的推送算法,提出将机器学习中的贝叶斯网络与统计学习方法应用于推荐算法融合,设计了一种支持向量机回归实现的基于内容推荐的算法,提高了推送精度,减少了推送时间。但其研究中使用的是原始的贝叶斯网络提取特征,其表达能力有限,并且其中的贝叶斯网络主要用于构建用户档案模型。深度学习(Hinton et al.,2006)因其能够自动识别出数据的特征,便于初始问题的特征提取,该方法能够克服传统特征提取方法存在的问题。中小学教育视频资源丰富,亟需对视频资源快速自动提取特征,进而进行有效地推送。支持向量机(Support Vector Machine,SVM)(张学工,2004)是一种基于统计学习理论的机器学习方法,通常用来进行模式识别、分类、以及回归分析。
研究采用深度学习对视频资源提取特征,然后构造视频中的知识点、视频质量和学习者需求之间的特征向量,作为支持向量机的输入,再由支持向量机决定是否将视频资源推送给学习者。这是一种基于深度学习和支持向量机的教育视频资源推送方法,能向学习者推送有效的视频资源。
三、推送系统架构
整个系统主要包括三个部分:用户需求提取、深度学习视频知识点识别和支持向量机推送。系统整体架构如图1所示。
第一个部分为用户需求提取,它的工作是通过采集和分析学习者的网络行为来提取学生的网络资源需求。用户需求提取模块是个性化推送的基础模块,负责收集用户的学习信息。一方面通过在线学习情况调查获取学生主动描述出来的显式信息,例如学生的年级、课程学习情况以及考试成绩等基本学习状况;另一方面通过行为跟踪收集用户在资源使用过程中的隐式学习信息。行为跟踪主要包括:(1)用户的资源使用信息:通过用户对资源的点击、下载、收藏和评价等信息,选取用户需要的学习资源,提取用户对已有资源的需求描述。(2)用户的资源搜索信息:通过搜索引擎日志(站内搜索和嵌套外部的,如Baidu,Google等)记录用户检索的信息,采用Web挖掘技术(韩勃,2012)获取用户学习行为数据,在服务器端通过挖掘Web日志来跟踪收集学生的学习行为数据;在客户端则利用Cookie、安装浏览器插件等方法进行数据采集,并根据这些行为数据分析学习者的学习兴趣和偏重点。用户信息收集模块获得的数据(包括基本信息、学习偏好、学习状况)将用来对学习者进行建模。通过分析用户模型所得到学习者对学习资源的需求描述将作为支持向量机的输入。
第二个部分为深度学习视频知识点识别。首先采用深度学习进行教育资源特征提取。采用深度自动编码器利用无监督逐层贪心预训练和系统性参数优化的多层非线性网络,从无类标数据中提取高维复杂输入数据的分层特征,并得到原始数据的分布式特征。深度自动编码的学习模型分为输入层、共享表示层以及输出层。在输入层通过采用稀疏玻尔兹曼机进行预训练得到资源的特征模态。在共享表示层通过采用典型关联分析方法找到特征模态的转换表示,从而最大化模态之间的关联性。最后,在输出层得到深度学习模型所识别出来的教学中的知识点,把该知识点作为下一步支持向量机进行分类的输入量。通过数据的训练来确定隐藏层与输入层之间的权值,优化支持向量机的工作性能,更好地呈现输入数据的内容。
第三个部分为支持向量机推送部分。首先建立用户与学习资源的联系,形成特征向量。然后采用径向基核函数分别构建支持向量机,最终实现学习资源的主动推送。基于支持向量机的学习资源推送算法主要有两个阶段:学习阶段和学习资源推送阶段。学习阶段主要包括:学习资源预选取、建立训练样本集、选择核函数、获取相应参数。学习阶段之后为资源主动推送阶段的实施过程。系统的性能指标为学习者对推送结果的实际点击率和满意度。实际点击率可由网站后台统计得到,满意度可以通过对学习者进行满意度调查问卷得到。
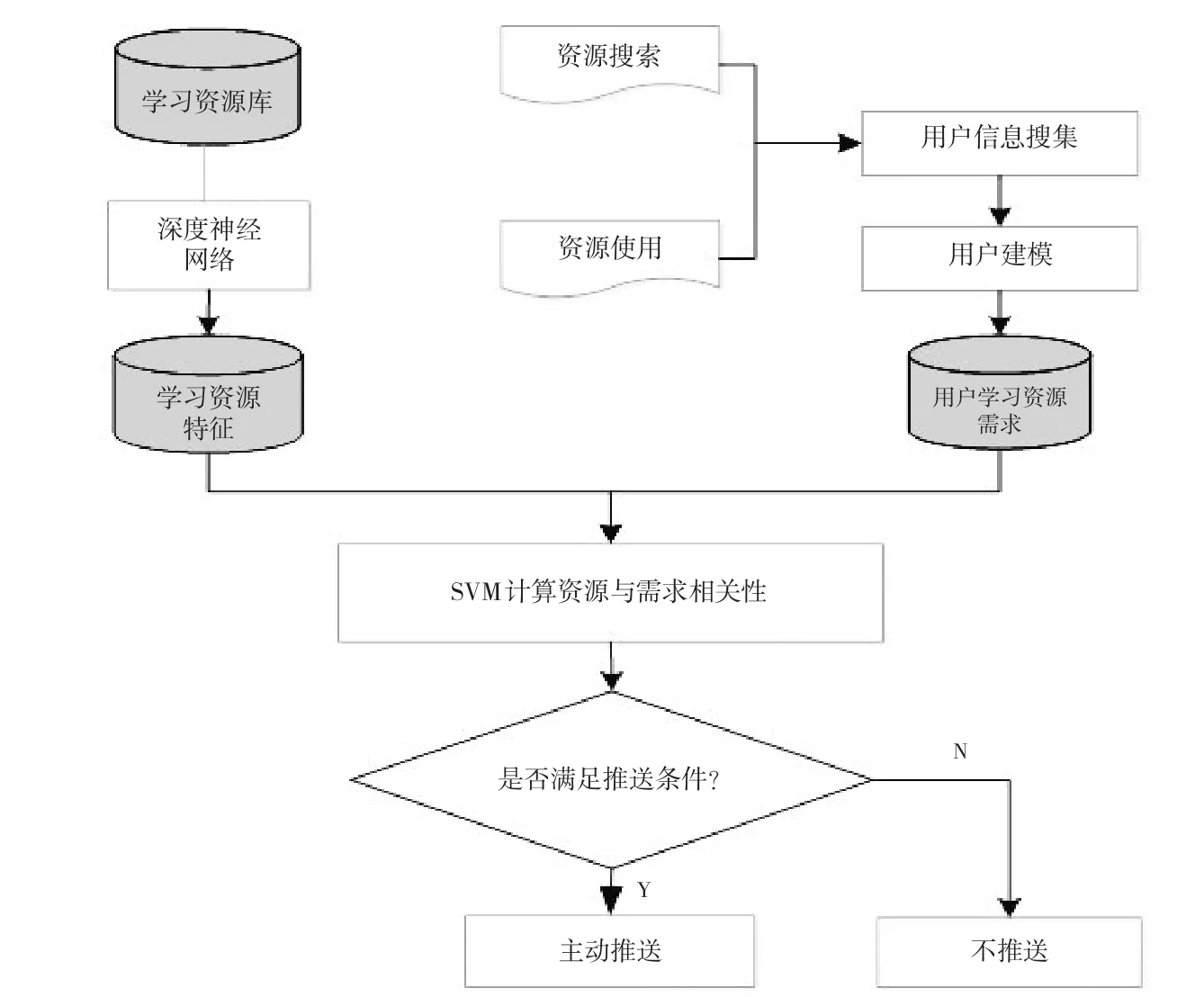
图1 基于深度学习和支持向量机的教育视频资源推送策略
四、学习者建模
学习者建模是对学习者的学习特征进行描述的过程,推送系统中的学习者模型不仅包括学习者的姓名、性别等基本信息,还包括能够反映学习者学习进度、知识水平及其个性化(如兴趣、爱好)的信息,这为学习者推荐合适的学习资源提供了依据。
由此,研究中的学习者模型可从学习风格偏好、认知水平和测试评价等多个方面进行描述(黄俊,2013)。学习者模型的形式化描述如下:
学习者模型={基本信息,学习偏好,学习状况}
1.学习者基本信息
学习者基本信息包括姓名、性别、年级、擅长科目等,由学习者提供。
2.学习者个性化兴趣特征
个性化兴趣特征包括学习者对教学内容、教学方式、教学时间等方面的偏好,如学生喜欢诗词类的学习内容,喜欢互动式教学,喜欢长时间学习。这类信息难以直接获得,需通过对学习者的访问记录进行数据挖掘、分析访问记录中隐含的学习者个性化特征而获得。
3.学习者学习状况
学习状况主要描述学习者的知识学习状态,包括学习知识的广度和深度。
(1)学习知识的广度
知识点一般是由教学专家根据学科的特点和实际教学情况进行的系统、科学的划分,以保证知识内容的局部完整性。研究采用知识点表示领域知识的最小完整单元。知识点可以构建学生的知识体系,也能在一定程度上反映出学生当前的知识广度。因此而建立的学生的知识广度模型如下:
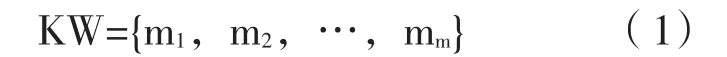
其中,m1={a1,a2,…,an};m2={b1,b2,…,bn};…mn={m1,m2,…,mn};
式子a1~an,b1~bn,m1~mn都表示知识点的数值。当学习者学习了某个知识点,则该知识点的属性值为1。反之,该知识点的属性值为0。因此,如果测量该学习者所学某一课程的全部知识点,就能得到表示该学生某一学科的知识体系向量。然而,知识点之间的关系并不是完全独立的,而是有依赖、继承、分解等关系,由知识点构建的知识体系具有层次结构。因此,研究采用一个有层次之分的向量组表示学习者的知识广度。
(2)学习知识的深度
不同阶段的学习者学习的知识点不同,研究将中小学学习者分为12个阶段(如下表所示)。
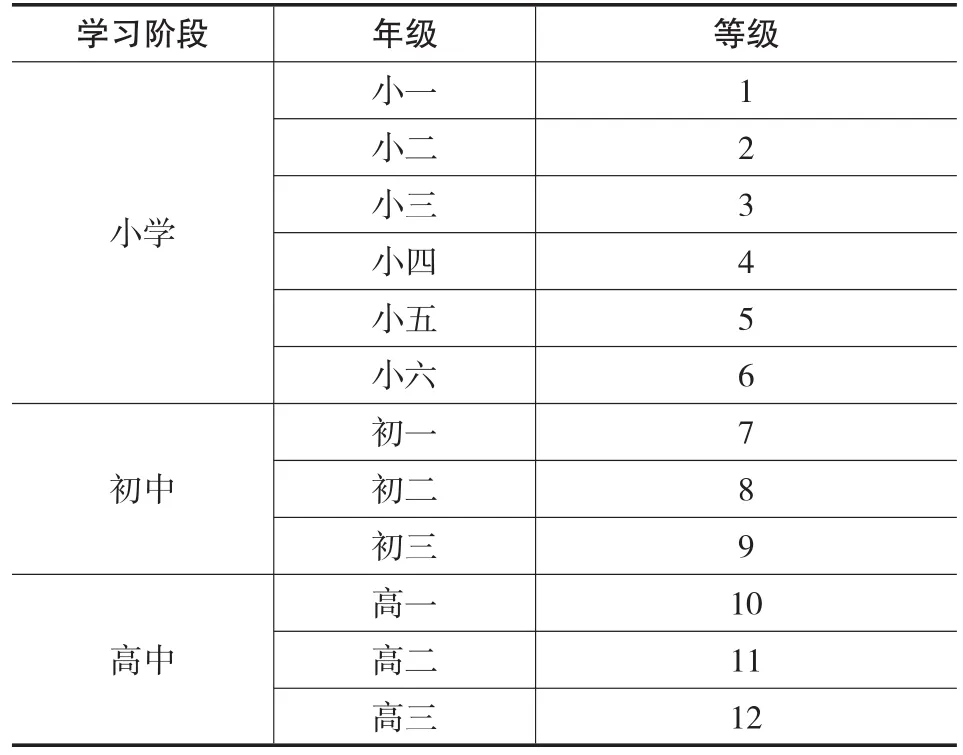
表 中小学学习阶段的划分
根据学生所处的年级,在知识深度的量化过程中,引入变量g表示学生所处的不同年级,变量取值是处于区间[1,12]的整数。
在一个学习阶段里,即具有相同的g值,为了更好地考核学生对知识的掌握情况,一般系统会通过进行多次测验来综合评定。

其中,ci表示第i次测试的成绩(假设每次测试的满分均为100分)。wi表示一门课的各种测试中第i次测试占的比重,它的取值在[0,1]之间,必须满足
综合学习者的知识广度和知识深度两个方面,建立的领域知识模型为:

通过对学习者的学习偏好和学习状况进行分析,得到学习者的学习需求,作为支持向量机的输入。
五、基于深度学习的知识点提取
教育视频中知识点的提取是进行其个性化推送的前提,研究采用基于深度学习的方法能有效并准确提取所需知识点。
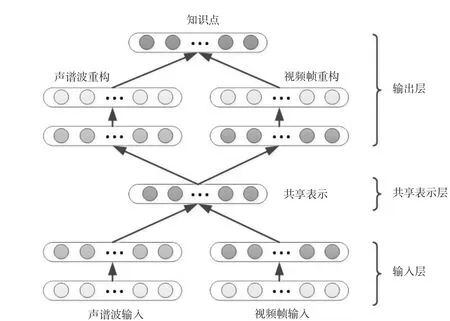
图2 深度自动编码器学习模型
视频是一种既包含音频又包含图像的合成资源,为根据视频特征更准确识别知识点,研究采用多模态的识别方法,即将视频资源的深度学习模型描述为视听双模态的特征学习,其中该模型的双输入分别是连续声谱图和视频帧。
在进行知识点识别与提取前,需对所需要的相关资源的特征进行预训练。预训练过程采用稀疏限制玻尔兹曼机(Restricted Boltzmann Machines,RBM)。RBM是一个具有隐藏变量和可见变量的无向图模型。隐藏变量和可见变量之间存在对称性的连接,但隐藏变量之间或者可见变量之间没有连接。并且可见变量作为实值单元,隐藏变量作为二值单元。研究采用对比差异来学习RBM模型的参数。同时为了调整该模型的稀疏度,我们鼓励每一个隐藏单元采用正则惩罚时期具有预决定的期望激活。
视频资源的深度学习模型采用基于稀疏理论的深度自动编码器(Jiquan et al.,2011)。深度自动编码器是一种利用无监督逐层贪心预训练和系统性参数优化的多层非线性网络从无标签数据中提取高维复杂输入数据的分层特征,并得到原始数据的分布式特征表示的深度学习神经网络结构,其主要工作是复现输入内容。当自动编码器的输入为无标签数据时,其首先需要经过一个输入数据编码的过程,将该编码作为输入的一个表示,然后再进行表示的解码,这样就可以获得输入数据的信息,如果该解码信息与原始输入信息相像,可以肯定编码的过程是可靠的,进而调整编码与解码过程的权重,进一步减小信息重构的误差,提高知识点识别的准确度。
基于稀疏理论的深度自动编码器对原始自动编码器的隐含层添加了约束条件并增加了隐含层数量,因而当隐含层神经元的数量很大时,该类自动编码器依然能发现输入数据的结构特征。该深度自动编码器能提取高维数据变量的稀疏解释性因子,保留原始输入的非零特征,增加表示算法的鲁棒性,增强数据的线性可分性,使分类边界变得更加清晰,并且能在一定程度上控制变量的规模,改变给定输入数据的结构,丰富原有信息,提高信息表述的全面性和准确率。
基于以上分析,研究提出一种基于深度自动编码器的知识点提取方案,如图2所示。
该学习模型分为输入层、共享表示层以及输出层。
输入层:为视频资源的两个特征模态,即声谱波和视频帧,该两个特征采用稀疏玻尔兹曼机进行预训练。
共享表示层:这一层的关键是找到特征模态的转换表示,从而最大化模态之间的关联性。研究采用典型关联分析(Canonical Correlation Analysis,CCA)的方法寻找声谱波和视频帧数据的线性转换,从而形成性能优良的共享表示。
其中,典型相关分析有助于综合地描述两组变量之间的典型相关关系,先将较多变量转化为少数几个典型变量,再通过其间的典型相关系数来综合描述两组多元随机变量之间关系的统计方法。运用典型相关分析,其基本程序是从两组变量各自的线性函数中各抽取一个组成一对,它们应是相关系数达到最大值的一对,称为第1对典型变量,类似地就可以求出第2对、第3对……,这些成对变量之间互不相关,各对典型变量的相关系数称为典型相关系数。所得到的典型相关系数的数目不超过原两组变量中任何一组变量的数目。共享层采用典型相关分析方法,目的是最大程度发现声谱波和视频帧数据两者之间的关联点,进而应用深度学习更精准地识别教育视频中的知识点。
输出层:输出该深度学习模型所识别出来的教学视频中的知识点,该知识点作为下一步支持向量机进行分类的输入量。
综上所述,深度自动学习编码模型的工作流程如下:首先利用稀疏玻尔兹曼机对视频资源进行预训练,得到视频资源的两个特征模态,即声谱波和视频帧;然后利用典型关联分析方法找到声谱波和视频帧数据的线性转换并形成优良的共享表示;最后输出该视频中包含的知识点,作为支持向量机的输入。
六、基于支持向量机的个性化学习资源推送设计
研究采用SVM技术对含有深度学习提取到的特征信息的学习资源进行主动推送,但并不是所有的资源都要进行推送。其关键问题是选择哪些资源进行推送。研究的目的是根据用户的特征进行资源的匹配性推荐,即推荐适合用户的信息。通过建立学习资源与用户需求的关联,在学习资源库中智能化选择最适合该学习者的学习资源,并进行主动推送。
为了更好地实现学习资源的个性化推送,首先需要建立起用户需求与学习资源的联系,并形成特征向量。然后采用径向基核函数构建支持向量机,最终实现学习资源的个性化推送。基于支持向量机的学习资源推送算法主要包括学习阶段和学习资源推送阶段。
1.用户需求与学习资源之间的关联
基于支持向量机的资源推送主要通过知识点来建立用户需求与学习资源之间的关联。知识点是教学活动过程中传递教学信息的基本单元,包括理论、原理、概念、定义、范例和结论等。一门课程的学习可以看成是对一系列知识点的学习过程。
为了更清晰地建立用户需求与学习资源之间的关联,需要描述知识点之间的关系。知识点之间的关系包含从属关系和支持关系。在从属关系中,不包含任何其他知识点的称为元知识点;而包含其他知识点的称为复合知识点。知识点的支持关系是指知识点的先修后修关系,因为学习是一种循序渐进的过程,知识点在学习过程中具有一种必然的先后衔接关系。一个知识点当前是否可学习往往取决于另一些知识点是否学习过,或者说后者是前者的预备知识。在学习某一知识点之前必须先学习相关的另一知识点,这两者之间的关系即为先修关系。在学习某一知识点之后,由本知识点直接支持的知识点,这两者之间就直接构成了后修关系。

图3 某课程知识结构分解图
通过支持关系构建的知识点关系图是一个有向无环图(DAG)(林海平等,2010),如图3所示。课程中的实例、解说等学习对象统称为学习资源,并将每个学习对象用“隶属”关系隶属于某个知识点,由此构成图3所示的某课程知识结构分解图。其中,课程知识域数据库(KDDB)包含了课程中所有的知识点,并定义各知识点之间的关系;学习对象数据库(LODB)包含此课程的所有学习资源对象,并定义每个学习对象与知识点的隶属关系。根据知识点划分的颗粒度不同,可分为复合知识点F和元知识点Y。
学习资源主要由学习资源包含的知识点列表(Slist)和学习资源难度(N)、学习视频的清晰度(Q)以及点击率(Sq)来进行形式化的描述。学习资源与用户需求的绝对距离AD(S,R)表示学习资源与用户所需的知识点的相关性,即前面所描述的支持程度,绝对距离越大则表示相关性越小。而学习资源与用户需求的相对距离AD(S,R)主要表示学习资源中知识点与用户需求中知识点的先修后修关系。用户需求的知识点包括用户浏览记录和所提供的关键词,用Rlist表示用户需求的知识点列表。
2.特征向量的选择
资源是否推送可以通过支持向量机进行学习分类,因此需要构造特征向量作为支持向量机的输入。当用户浏览资源后,系统可根据其浏览的学习资源记录关键词,同时根据其需求主动推送学习资源。因此,需要构造学习资源与用户需求的特征向量主要包括:学习资源与用户需求的绝对距离、相对距离,学习资源的学习难度,学习资源的清晰度及点击率。
3.基于支持向量机的个性化学习资源推送设计
(1)支持向量机原理
SVM是从线性可分情况下的最优分类面发展而来的,基本思想可用图4的两维情况说明。图中圆形和方形分别代表两类样本,H为分类线,分别为各类中离分类线最近的样本且平行于分类线的直线,它们之间的距离叫做分类间隔。所谓最优分类线就是要求分类线不但能将两类正确分开(训练错误率为0),且能使分类间隔最大。
对于非线性问题,可以通过非线性变换转换为某个高维空间中的线性问题,再变换空间求最优分类面。对于非线性数据集,SVM可通过一种核函数将非线性空间映射到高维空间而实现线性分类。

图4 线性可分情况下的最优分类线
目前SVM最常用的核函数主要有三类:线性核函数、多项式核函数和径向基(RBF)核函数。这些核函数中RBF应用最广,无论是小样本还是大样本,高维还是低维等情况,RBF核函数均适用。相比其他的函数RBF,核函数具有以下优点:
其一,RBF核函数可以将一个样本映射到一个更高维的空间,而且线性核函数是RBF的一个特例,换言之,如果考虑使用RBF,就没有必要考虑线性核函数了。
其二,与多项式核函数相比,RBF需要确定的参数要少,核函数参数的多少直接影响函数的复杂程度。另外,当多项式的阶数比较高时,核矩阵的元素值将趋于无穷大或无穷小,而选择RBF会减少数值的计算困难。
(2)推送的实现
推送主要分为学习阶段与学习资源主动推送阶段。
学习阶段的实施过程包括:预选取学习资源、建立训练样本集、选择核函数、获取相应参数。
预选取学习资源:根据用户的浏览记录,系统将根据相关原则预选取一些资源,推荐给用户。
建立训练样本集:每一个预挑选出来的学习资源与用户需求生成特征向量,如果用户点击选取了此学习资源,则归类为1,否则归类为0。
选择核函数:依据麦瑟(Mercer)定理按实际情况为SVM选择适当的核函数相关参数,作为高维特征空间在低维输入空间的等效形式。选择适当的核函数可将复杂特征空间映射到一个简单的高维空间,且高维空间中两特征向量间的点积可由核函数在低维特征空间中对应两特征向量计算而得到,这样降低了分类器的复杂度,而不用担心由于引入核函数而引起的维数灾难。
获取相应参数:通过训练样本集,求解二次规划式,获得每一个SVM的支持向量及相应的拉格朗日(Lagrange)乘子。
资源主动推送阶段的实施过程是:首先导入前面学习阶段所获得的参数,包括训练样本数据、每个样本对应的拉个朗日乘子以及支持向量等。然后在用户每次浏览后预选取若干个学习资源,将每个学习资源与用户需求和资源质量(包括资源的学习难度、清晰度和点击率)生成输入特征向量(RD (S,R),AD(S,R),N,Q,Sq),根据分类函数计算其输出值(0或者1)。最后是资源的推送,将输出结果为1的特征向量中的学习资源推荐给用户。
七、结论
为提高教学资源的利用率和资源获取的效率,研究提出了一种基于深度学习和支持向量机相结合的方法对网络上大量学习资源进行推送。针对以往基于资源推送系统中很多资源上传者在描述资源时,只是简单地描述内容信息,没有全面、详细地描述导学资源介绍的相关知识的问题,采用深度神经网络和支持向量机相结合的方式对缺少分类和标签信息的教育资源实现推送。采用深度自动编码器,进行资源的深度共享,从而有效准确识别出教学资源中的知识点,然后构造资源的知识点、质量和用户需求之间的特征向量,作为支持向量机的输入,根据支持向量机中的分类函数决定是否推送,实现资源根据用户需求自动推送。通过学习者对推送结果的实际点击率和满意度作为方案的性能评价指标。这种方案关注学习者的兴趣需求和视频特征的结合,具有广泛的市场前景和应用潜力。
参考文献:
[1]郭进成(2013).基于本体的教育资源推送服务研究[D].呼和浩特:内蒙古大学: 1.
[2]韩勃(2012). E-Learning环境中学习行为挖掘的设计与实现[D].济南:山东大学: 4-11.
[3]何安(2007).协同过滤技术在电子商务推荐系统中的应用研究[D].杭州:浙江大学: 28-38.
[4]黄俊(2013).基于学生特征模型的教育云资源推送技术[D].广州:华南理工大学: 19-23.
[5]林海平,檀晓红,申瑞民(2010).基于知识结构图的个性化学习内容生成算法[J].上海交通大学学报,(3):418-422.
[6]邢春晓,高凤荣,战思南(2007).适应用户兴趣变化的协同过滤推荐算法[J].计算机研究与发展,(2):296-301.
[7]许海玲,吴潇,李晓东(2009).互联网推荐系统比较研究[J].软件学报,(2): 350-362.
[8]王宏宇(2007).商务推荐系统的设计研究[D].合肥:中国科学技术大学: 108-123.
[9]张学工(2004).关于统计学习理论与支持向量机[J].自动化学报,26(1):32-42.
[10]Avancini,H.,& Straccia,U.(2004). Personalization,Collaboration,and Recommendation in the Digital Library Environment Cyclades[A]. Proceedings of the IADIS International Conference Applied Computing(AC-04)[C]. Lisbon,Portugal: IADIS:589-596.
[11]Dunja,M.(1996). Personal Web Watcher: Design and Implementation[R].Departmentof Intelligent Systems JStefan Institute.
[12]Hinton,G. E.,& Salakhutdinov,R. R.(2006). Reducing the Dimensionality of Data with Neural Networks[J]. Science,313(5786):504-507.
[13]Lieberman,H.,Dyke,N. V.,& Vivacqua,A.(1999). Let's Browse: A Collaborative Browsing Agent[J]. Knowledge-Based Systems,12(8):427-431.
[14]Linden,G.,Smith,B.,& York,J.(2010). Amazon.com Recommendations: Item-to-Item Collaborative Filtering[J]. IEEE Internet Computing,7(1):76-80.
[15]James. R.,& Marcos,J. P.(1997). Siteseer: Personalized Navigationforthe Web[J].Communicationsofthe ACM,40(3):73-75.
[16]Jiquan,N.,Aditya,K.,& Mingyu,K. et al.(2011). Multimodal Deep Learning[A]. Proceedings of the 28th International Conference on Machine Learning(ICML-11)[C]. Bellevue,Washington,Usa:689-696.
[17]Michael,P.,Jack,M.,&Daniel,B.(1998). Syskill & Webert: Identifying interesting web sites[C]. Thirteenth National Conference on Artificial Intelligence-volume.23(4):54-61.
[18]Resnick,P.,& Varian,H. R.(1997). Recommender Systems[J]. Communications of the ACM,40(3): 56-58.
[19]Tang,T.,& Mccalla,G.(2004). Evaluating a Smart Recommender for an Evolving E-learning System: A Simulation-Based Study[A]. Tawfik,A. Y.,& Goodwin,S. D.(2004). Advances in Artificial Intelligence[M]. Springer Berlin Heidelberg:439-443.
The Implementation of Educational Video Resources Recommendation Method Based on Feature Extraction
Wen Mengfei,Hu Chao,Yu Wentao,Liu Weirong
Abstract:The plentiful network educational video resources meet the demand of learners to select learning content,learning time and learning place by themselves. However,it's difficult for learners to obtain worthwhile resources associated with their needs from the massive resources quickly and efficiently because of some problems existing in the resources or the resources platform such as the varied quality of resource content,the scarcity of high-quality educational resources,resources homogenization,the single mode of resources pushing. To allow learners to get personalized educational video resources efficiently,when recommending resources,this research uses deep learning method to identify the knowledge points of video resources accurately. Then the feature vector structured by the knowledge points of video resources,video quality and the needs of learners serves as the input of the support vector machine,which is responsible for deciding whether to recommend video resources to the learners or not. The performance evaluating indicators of this proposed method includes the actual click rate of the recommended resources by learners and the satisfaction degree fed back by learners. This proposed method focuses on the combination of the learners' interests and video features,which can better meet the requirements of learners and enhance the ability of learners with great potential in application.
Keywords:Educational Video Resources;Feature Extraction;Deep Learning;Support Vector Machine;Recommendation Method
收稿日期2016-03-25责任编辑曾艳
作者简介:文孟飞,博士,副教授,湖南省教育科学研究院(湖南长沙410005);胡超(通信作者),博士,讲师,中南大学信息与网络中心(湖南长沙410083);于文涛,博士,中南林业科技大学计算机与信息工程学院(湖南长沙410018);刘伟荣,博士,副教授,中南大学信息科学与工程学院(湖南长沙410083)。
*基金项目:湖南省教育科学“十二五”规划重点资助项目“云计算环境下基础教育优质数字资源建设与应用研究”(XJK014AJC001);国家自然科学基金项目“云计算中资源共享的分层博弈联盟形成与定价机制研究”(61379111)。
中图分类号:G434
文献标识码:A
文章编号:1009-5195(2016)03-0104-09 doi10.3969/j.issn.1009-5195.2016.03.012
猜你喜欢
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
电子技术与软件工程(2016年20期)2016-12-21 10:21:33
价值工程(2016年32期)2016-12-20 20:36:43
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
价值工程(2016年29期)2016-11-14 00:13:35
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
科学与财富(2016年28期)2016-10-14 21:19:17
