
支撑教学资源的推荐算法原型系统设计
2016-05-31 08:41李玮何富乐骆嘉伟殷樱
中国教育信息化·高教职教 2016年3期
关键词:个性化推荐
李玮 何富乐 骆嘉伟 殷樱


摘 要:计算机的普及和网络的发展改变了现有的教学模式,教育资源的数字化、网络化成为了一个必然趋势。在这个“信息过载”的时代,推荐机制根据用户特征兴趣解决所需信息和搜索之间的矛盾。然而传统推荐算法计算效率低下,存在可扩展性低、算法运用场景不明确等问题。Hadoop利用分布式的环境,将计算任务通过资源调度分配到集群环境中,多台机器并行运算,减少了计算时间。所以本文在推荐算法理论和实现机制的基础上阐述了基于项目的ItemCF的实现方法和实现过程,有效增加推荐算法的实用性,为个性化推荐和教学资源的管理提供了便利。
关键词:Hadoop;推荐机制;ItemCF;个性化推荐
中图分类号:TP3 文献标志码:A 文章编号:1673-8454(2016)05-0033-05
互联网在改变人类生产生活的同时,也为学习和教育带来了一场深刻变革,这场变革就是在信息技术支撑下的教育信息化[1]。网络中教育资源管理平台是将多种形式的教学资源有层次地组织起来,对教学资源进行采集、管理、检索和利用的学习辅助系统,它打破了传统教育方式在时空上的限制,使学习者能够更加灵活、自主地学习[2]。然而,随着教育资源在数量和规模上的不断扩大,网络上的资源也呈现“爆炸式增长”,面对大量的教学资源,用户很难从中发现适合自己的有用信息,资源利用率低。因此针对用户的个性化推荐服务成为网络远程教育中亟待研究和解决的问题[3]。
推荐机制的存在就是为了消费者解决所需信息与搜索之间的矛盾。在推荐过程中,系统能够自动地追踪用户的历史行为并据此为每位用户的兴趣建模,从而给用户推送能够满足他们兴趣和需求的信息[2]。本文将个性化推荐技术应用在资源分配网中,对用户和资源进行建模,利用推荐算法为用户推荐最适合的学习资源。本文设计的原型系统也可以广泛应用于远程教育资源中,这样学习者就不再是被动的网页浏览者,而是信息的主动参与者[1]。
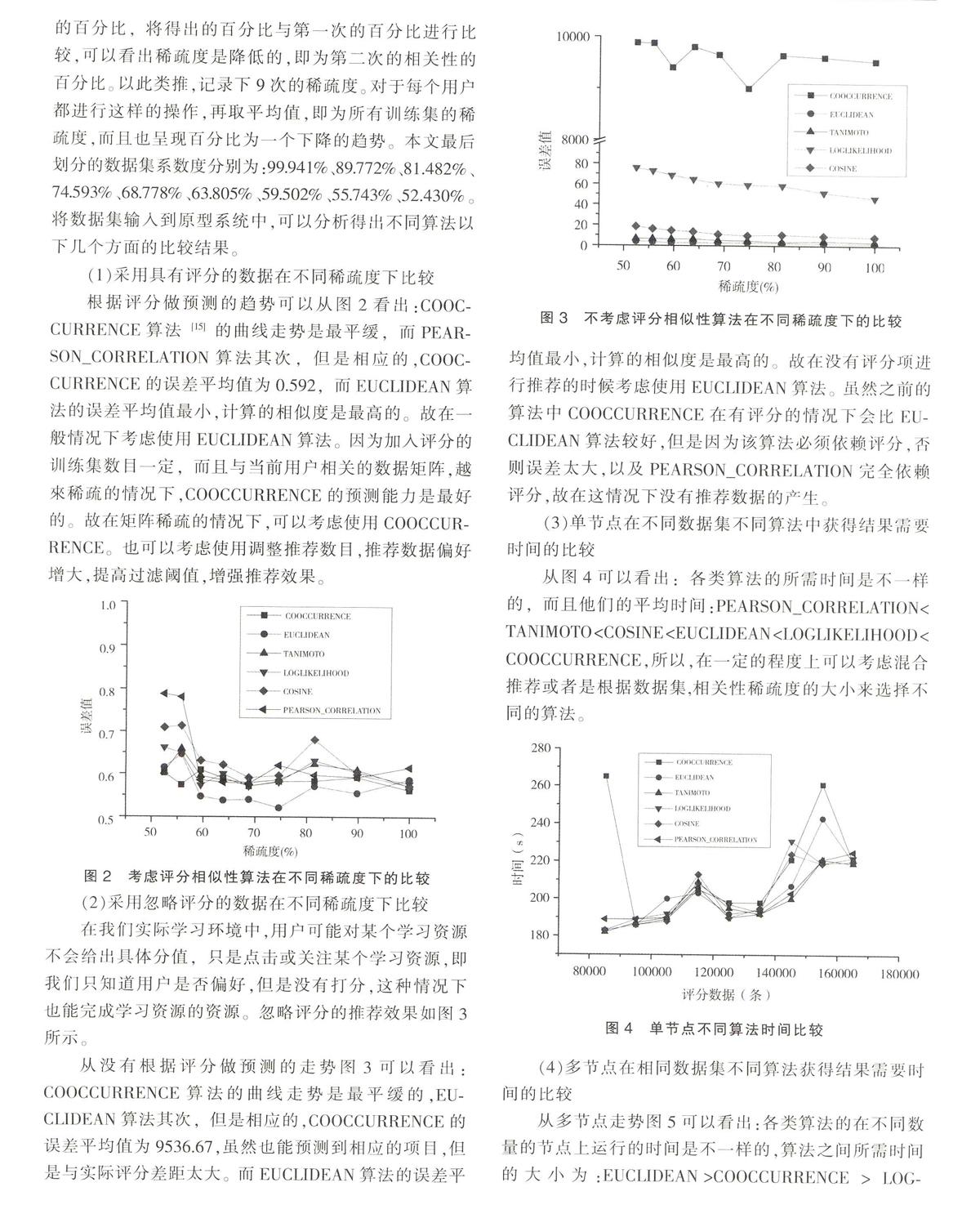
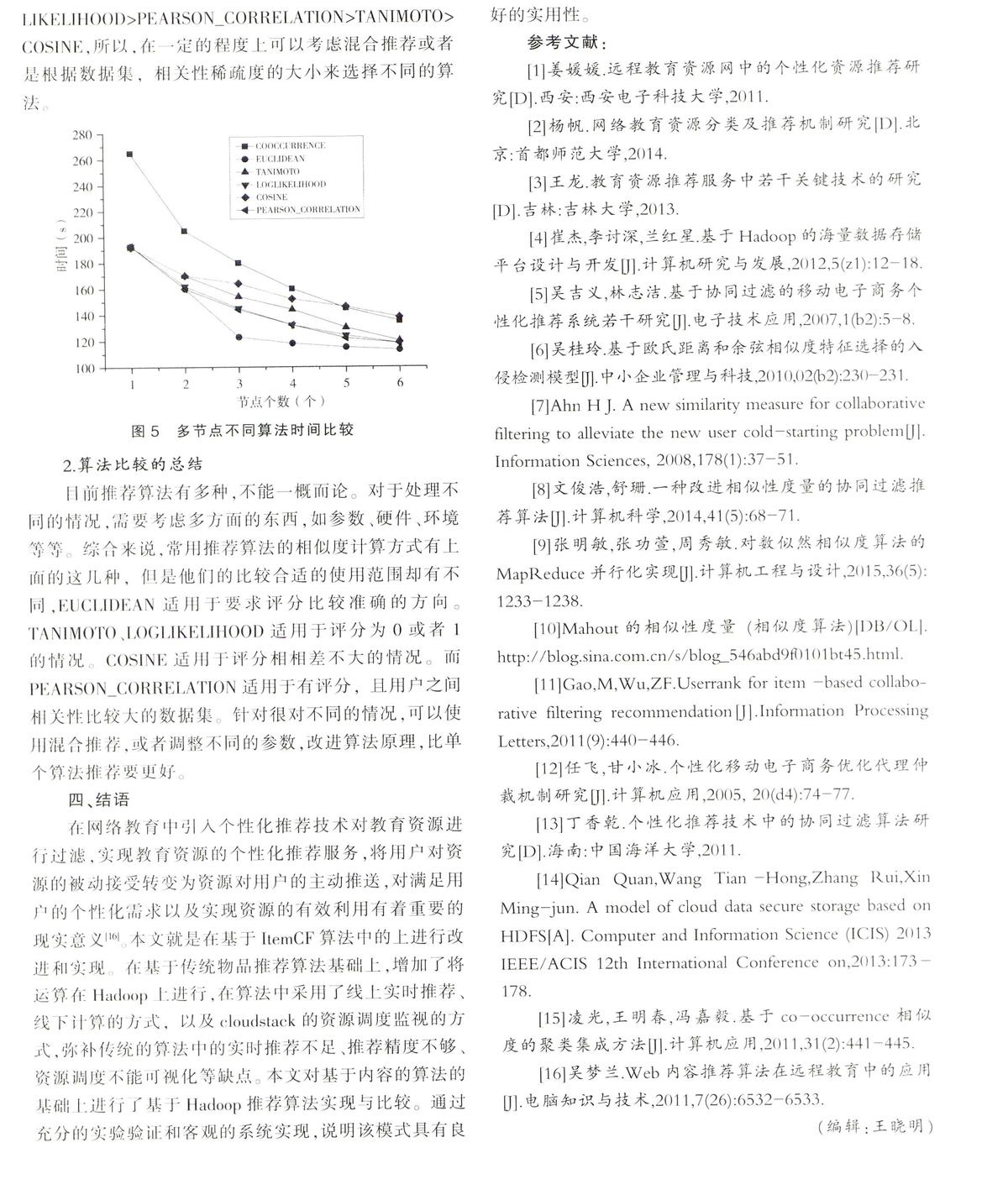
文中通过编写mapreduce程序,构建用户物品矩阵,构建物品相似度矩阵,获得相似度。运用hadoop[4]搭建分布式环境,以实现算法分布式运算的效果。设计出基于Hadoop推荐算法的比较模型,对不同场景下的所得结果误差进行绘图分析,得出不同相似度计算方法之间优劣的结论。同时又通过定时器以及其他方式,提前将推荐的结果计算好,存储数据库中。对推荐时直接获取计算好的结果进行展示,以实现实时推荐[5]的功能。
一、基于项目的推荐算法(ItemCF)
目前的推荐算法中有很多分类方法,最主要的有两种:基于用户的推荐算法和基于项目的推荐算法。本文采用的是基于项目的推荐算法。
基于项目的推荐算法是着重点在于项目的相似度计算。虽然该算法与基于用户的推荐算法都是基于社会化的环境,但是在比较大型的网站上的时候,由于用户数量往往大于相应资源的数量,以及项目的数据量是相对稳定的,在这情况下该算法不仅相似度计算量小,而且计算结果不需要频繁更新,用户获得相应的更快的数据资源。
1.基于欧式距离的相似度计算方法(EUCLIDEAN)
基于欧氏距离的相似性(欧氏距离)[6]是最简单和最容易的相似度计算方法
在公式(1.5)中O表示的是实际观测频次,E指的是期望频次。对数似然相似度算法原理是统计数据中有多少是重叠的,有多少是不重叠,以及都没有的个数。主要用于处理无打分情况的偏好数据,比Tanimoto系数的计算方法更为智能。
6.基于斯皮尔曼相关相似度计算方法(COOCCURRENCE)
斯皮尔曼相关性可以理解为是排列后(Rank)用户喜好值之间的Pearson相关度。假设对于每个用户,我们找到他最不喜欢的物品,重写他的评分值为“1”;然后找到下一个最不喜欢的物品,重写评分值为“2”,依此类推。然后我们对这些转换后的值求Pearson相关系数,这就是Spearman相关系数[10]。
斯皮尔曼相关度的计算舍弃了一些重要信息,即真实的评分值。但它保留了用户喜好值的本质特性——排序(ordering),是建立在排序的基础上计算的。
二、原型系统的设计
基于Hadoop的推荐算法的实现和比较的主要目标是设计一个能够比较不同算法之间的误差,从而选取较好的推荐算法,在此场景下给用户比较准确的推荐,不仅仅实现资源的推荐,在此基础上还实现线下计算,线上推荐的,用户评分,收集用户新评分的功能。
猜你喜欢
东方教育(2016年8期)2017-01-17
软件导刊(2016年11期)2016-12-22
电脑知识与技术(2016年27期)2016-12-15
电脑知识与技术(2016年27期)2016-12-15
商(2016年34期)2016-11-24
