
粒子群算法及其在订单分批中的应用研究
2016-05-31 08:42马廷伟雷全胜李军罗盛照
物流科技 2016年3期
马廷伟 雷全胜 李军 罗盛照


摘 要:物流中心是现代物流活动的关键场所,而订单分拣环节占到其工作的50%以上。文章旨在通过制定合理的订单分批策略以改善人工拣选系统中拣选作业的工作效率。订单分批通过将多个订单合成一个批次或更大的订单以减少工作量并让分拣过程得以更有效的实施。文章提出的基于粒子群的分批算法考虑将粒子群算法用于求解订单分批问题,为了使算法匹配所要求解的问题,对二进制粒子群算法进行了改进。最后利用Matlab仿真软件进行仿真实验,进而得出了较经典的启发式算法更好的求解结果。
关键词:供应链管理;分拣策略;订单分批;粒子群算法
中图分类号:F251 文献标识码:A
Abstract: Logistics center is the key place of modern logistics activities, and the order picking process accounts for more than 50% of the work. Order batching reduces the amount of work and make the sorting process more effective by synthesizing a batch or larger order with multiple orders. In order to solve the problem of the requirements for the algorithm, the binary particle swarm optimization algorithm is improved in order to solve the problem. At last, the simulation experiment is carried out by using Matlab simulation software, and the result is better than the classical heuristic algorithm.
Key words: supply chain management; sorting strategy; order batching; particle swarm optimization
0 引 言
物流系统是供应链准确高效运作的基本保障,在物流系统各个环节中,物流中心连接了供应链的各个部分,是物品流通的关键节点,也是管理者关注的重点。在物流中心的各项活动中,分拣是最为重要的一项活动,其成本约是整个中心运营成本的50%~65%[1],分拣的效率不仅关系到整个运营的成本,还直接影响到客户服务水平。人工分拣系统可以分为人到货系统和货到人系统,本文主要研究人到货系统,即拣选人员驾驶拣货设备逐个到货位进行拣选。在人工分拣系统中管理者通常要考虑三个操作层面的问题:储位分配即货物如何在存储区进行存放以及对不同的货物如何设计存放位置;订单分批即如何将订单进行分批处理以节省总的拣选时间;路径优化即如何最小化每一次拣选的路程。其中订单分批对订单拣选的运作效率起到非常关键的作用,良好的分批方法能有效减少拣选人员用于采集订单指定物品所需的时间从而提高产能增加柔性。本文介绍了粒子群算法的概念与主要步骤,提出了一种适用于订单分批问题的算法PSOBM(Particle Swarm Optimization Bat-ching Method)。
1 粒子群算法
粒子群优化算法(Particle Swarm Opti-mization, PSO)是一种基于群的随机优化技术,由Kennedy和Eberhart[2]在1995提出,粒子群算法涉及到演化计算,并与遗传和进化策略有着密切的联系。群体智能是该算法中一个核心的思想,内容为在群体中对信息的社会共享使得整个群体具有一定演化优势。粒子群优化算法的基本思想是:一个群体中的每个个体都能够“记忆”一个最佳值以及与这个最佳值相关的位置信息,同时每个个体还知道其他个体所了解到的最佳值与位置信息,这样对每个个体来说可以根据这些信息调整自己的位置以保持与其它个体的同步[3]。因此,对这样的个体需包含至少三方面的内容:当前运动的方向、自己的经验、群体的经验,相比其他的表述,粒子更适合描述具有速度和加速度这样概念的个体,这也是为什么这一算法被称为粒子群。群体对两个质量因子pbest和gbest做出反应,在两个因子间响应的定位确保了响应的多样性。群体只有在gbest改变时才改变其状态。
假设搜索空间中有P个粒子,每个粒子是一个n维向量,其中第i个粒子遵循下面的运动规律:
惯性权重系数使得搜索更加灵活并提高了搜索的精确程度,大大提升了粒子群算法的可用性,因此具有惯性权重系数的粒子群算法被称为标准粒子群算法(Standard Particle Swarm Optimization),粒子的运动过程如图1所示:
当w≥1时,粒子的速度在整个迭代期间会不断增加,并导致粒子逐渐脱离种群;
当 0 Shi和Eberhart还建议对惯性权重的取值逐渐减小,即惯性权重系数是随时间递减的函数wt,并指出其取值范围在0.4,1.2之间算法具有较好的搜索效果,其中权重值在0.4,0.9区间上具有很好的局部搜索能力,而值在0.9,1.2区间上具有很好的全局搜索能力,至于更侧重局部搜索能力还是全局搜索能力要视具体问题而定。 加速度C和C也被称作学习因子,一般C和C取值相同且大于零,即C=C>0,此时粒子被“吸引”向最优位置靠拢,若C>C有利于求解多峰问题,而如果C
2 粒子群算法设计
本文采用粒子群算法解决订单分批问题出于以下几点考虑:
(1)粒子群具有快速的搜索能力,取得一个满意的解比寻找最优解更加实际;
(2)粒子群算法同样是一种随机搜索算法,通过改变参数的方式可以灵活地进行调整;
(3)粒子群算法规则简单易于实现。
2.1 粒子群算法的步骤
利用粒子群算法进行求解分批问题遵循下列步骤:
2.2 编码设计
编码方式的选择从很大程度上影响到搜索空间的规模和搜索的质量,对于离散空间来说一般将一个二进制串作为问题的一个解[6],为了求解订单分批问题,本文对所有解进行自然数编码,即问题的每一个解是一个自然数串,串中的每一位表示在该位置的订单所放入的批次号,设有订单向量该向量在搜索空间映射了N个位置,每个位置可以用一个粒子表示。若表示一个粒子的位置向量,该向量的每个分量x=j, j∈1,BatchNum代表了订单被分到第j批次,编码过程如表1所示。
解向量中相同编号的数字表示对应序号的订单被放入了同一个批次。
2.3 粒子群的拓扑结构
在每一次迭代中,每个粒子都根据自己的认知和社会认知调整自己的行为,当群体的数目决定之后即确定了一个社会规模,每个粒子可以决定向群体中的某些个体学习,这些个体往往被称为精英粒子,或者向邻近的粒子学习。不同的学习方式决定了整个算法的收敛速度,一般来说,采用学习精英粒子(群体中具有最好适应值的粒子)的策略使得算法收敛更快,局部搜索能力也更好;而采用向邻近粒子学习的方式则具有更好的全局搜索能力。另外粒子还能够选择需要学习的相邻粒子的数量,数量越多意味着包含精英粒子的几率也越大,所以收敛的速度也就越快,将粒子的邻近视为一个个的搜索邻域,选择和定义这些邻域的方式称为粒子群的拓扑结构。本文采用向群体的精英粒子学习的方式,该种方式能够充分发挥粒子群算法快速搜索的特点。
2.4 位置更新方式
标准的粒子群算法由于速度更新公式产生的是连续的值,因此特别适合处理具有连续搜索空间的问题,前面介绍了标准粒子群的一种改进版本——二进制粒子群算法,该种算法尝试通过改变位置更新的方式来适应离散的模型,本质上讲二进制粒子群算法不同于粒子群算法,每个粒子的位置用取值0和1的向量来表示,速度被映射到0,1区间上得到一个长度等同于粒子位置向量的概率串,表示每个位取0或1的概率。刘建华[7]提出了一种改进的二进制粒子群算法并验证了其鲁棒性,本文借鉴其研究成果,提出一种适用于分批问题的离散粒子群算法PSOBM。
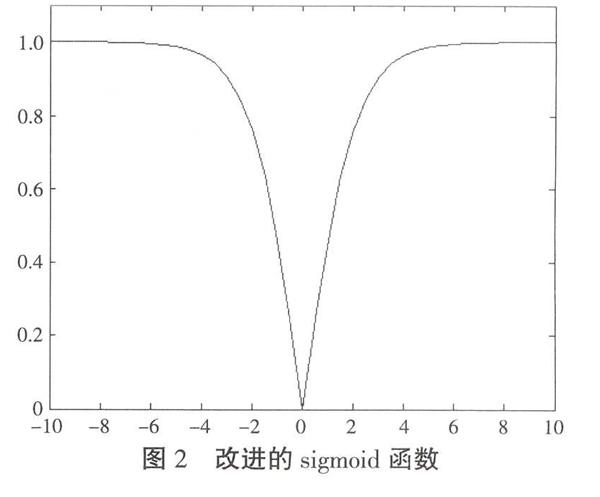
根据前面所采用的编码方式,粒子的位置向量即解向量每一位取值不是0和1,而是一系列取值上连续的正整数,若某一位为j则表示与该位对应的订单i被分到了第j个批次。为了表示粒子的运动过程,将速度映射为概率串,表示每一位增加或减少的可能性,位置更新不是以概率变为0或1,而是以一定概率加上C或减去C,从而使得粒子的某一位置分量向精英粒子的对应位置分量靠近。对于订单数目较少时C取值为1,当订单数目较大时可以考虑采用较大的C来加快算法收敛的速度。前面提到的速度映射sigmoid函数变成了如下的形式:
rand是取值均匀分布在0,1区间上的随机变量,在图2中注意到如果速度v的取值过大则所映射的概率也越接近于1,也就是说位置值一定改变,从而失去了随机性,为了避免这种情况的发生引入一个最大速度值V从而将v限定在-V,V范围内。V的取值不易过大,这样就失去了设置该值的意义,本文将V取值为6。
2.5 可行解的保证
经过上述变化过程,解的结构发生了改变,由于所要求解的问题带有约束条件,从而可能产生一些无法满足要求的解,需要保证解的可行性。经过上述映射变换后的解向量可能具有如下这样的形式:X=16,0,-2,0,5,5,16。
向量的每一个分量表示的是批次编号,而这里却出现了负数和很大的数字,而且各编号的值也不是连续的,这似乎不是我们希望得到的结果,其实这样的解是有意义的,如果仅仅用不同的数字代表不同的批次,所让人困惑的就只是序号的问题,可以通过下面的算法保证批次的序号是连续的:
将x升序,不重复的排列到向量Y=-2,0,5,…,16,检查X的每一个分量,如果第m个分量的值等于Y中第n个分量的值,则将改变X中的那个分量变为n,n即是Y个分量的索引值。该过程的matlab代码如下:
for n = 1: lengthY
for m = 1: lengthX
if Xm=Yn
Xm=n
end
end
end
经过上面的步骤,X=4,2,1,2,3,3,4,这样还是没法保证解是可行的,为了满足约束,引入一个纠正函数Check_and_Correct。将任意解转化为分批问题可行解的步骤如下:
(1)分别考察每个批次;
(2)对当前考察的批次,判断是否违反约束,在这里是保证每批次订单物品数量不超过拣选设备容量;
(3)如果满足约束条件则考察下一批次;
(4)如果不满足约束条件,则对当前的批次进行拆分,拆分的原则是取该批次中的第一个订单;
(5)将(4)中拆分出来的订单放入物品数量最小的一个批次,如果放入该批次后使得原本满足约束变为不满足,则打开一个新的批次;
(6)返回(4)直到考察批次满足约束为止;
(7)直到考察完最后一个批次。
该过程的伪代码如图3所示。
2.6 程序流程设计
图4显示了利用粒子群算法求解分批问题的程序流程设计,该设计采用模块化编程,在主函数PSOBM中包含了算法的整个流程,在外围有三个主要的子函数以供调用,分别是纠正函数,位置更新函数和适应度计算函数。在有子函数调用的地方做出了标注。
3 参数选择
3.1 惯性权重
为了平衡粒子群算法局部搜索能力和全局搜索能力,Shi和Eberhart为最早提出的粒子群算法引入了一个惯性权重w,具有惯性权重的粒子群算法被称为标准粒子群算法,Shi和Eberhart还建议将w取值为0.9,1.2,这样能够取得较好的优化效果。惯性权重定义了粒子的当前速度受先前速度的影响程度,权重越大局部搜索能力越弱,而全局搜索能力得到加强。对于本文所研究的模型来说,惯性权重定义了某种随机性使得能够在更大的范围内搜索到有用的解,然而在算法的后期这种随机性使局部搜索不够。Shi和Eberhart在此基础上还提出了一种适应策略,即权重值是一个变化范围,在迭代的一开始采用较大的权重值
W,随着迭代次数增加权重逐渐减小到一个固定值W,每次迭代惯性权重取值为:
w=w-w-w (7)
这样算法就能在一开始拥有很好的全局搜索能力,而在后期拥有不错的局部搜索能力,鉴于此本文将采用这种惯性权重设置。
3.2 初始速度
由速度更新公式(3),如果没有右边的第一项v则粒子群算法就等效为一个局部搜索算法,v提供了粒子变化的方向,因此进行第一次迭代时的初始速度V的选取就非常关键,然而,由于粒子群算法是一种随机搜索算法,一开始我们并不知道对哪儿子空间进行搜索会最快找到最优解,所以要想确定最优的初始速度显得有些困难,本文采用随机的方式产生初始速度V。
3.3 学习因子
学习因子定义了粒子向群体最优粒子以及相邻粒子学习的能力,学习分为两个部分,自我认知部分即该粒子历史最好的位置和社会认知部分即邻域中粒子的最好位置,分别用c和c两个参数来进行控制。问题是对特定的问题,我们并不知道c和c的取值应该是多少,只能通过反复试验的方法,通常的文献中取c=c=2,为讨论学习因子的取值对算法的影响,设有30个订单,初始惯性权重w=1.2,初速度V随机产生,首先看看两个因子中有一个取0的情况:
图5、图6中显示的是粒子群中的精英粒子随着迭代次数的变化,最小路径的取值情况。当c=0, c=3时,算法的收敛很快,在50代左右取到了最优值,当c=3, c=0时算法收敛于一个较大的值,原因是算法中强调了精英粒子的重要性,因此通过向精英粒子学习能够获得更好的适应值,而只通过自我认知则几乎没有可能找到最优的值,但是自我认知仍然是有用的,它扩大了算法的搜索范围,图7显示算法在目标值为2 200左右进行了搜索。为了找到更好的解,不仅需要搜索更大的范围,同时也要求更多地向优秀的粒子学习。图7给出了在c=1, c=3时的情况,在此种情况下不仅搜索范围更大而且所得目标值也更好。
4 算法性能与结果分析
为了进一步验证上述算法的有效性,在此将先进先出算法和在许多文献中证明有很好效果的节约算法作为参考基准,粒子群算法的参数设置如表2所示:
拣选设备容量设为60,实验结果如图8所示:
图8的结果显示,粒子群算法在订单数目变化的情况下都具有比先到先服务准则(FCFS)和节约算法(SAVING)更好的性能,PSOBM平均比节约算法有5%~6%的改善,并且基于群的演化方法具有更好的适应性,体现在对不同的环境都有类似的表现,因而可以认为采用粒子群算法求解订单分批问题得到的效果更好。
5 结束语
粒子群算法是近年来比较热门的研究方向,由于算法简便易行且计算快速而受到各个邻域的关注,本文依照粒子群算法提出了一种适用于订单分批问题的算法PSOBM,讨论了算法设计的各个细节,并给出算法程序流程设计,最后通过实验结果与其他方法进行了比较,得出粒子群方法效益更高的结论。
参考文献:
[1] Manzini R. Warehousing in the Global Supply Chain[M]. London: Springer, 2012:105-155.
[2] Eberhart R, Kennedy J. Particle Swarm Optimization[C] // IEEE, 1995.
[3] 陈恩修. 离散群体智能算法的研究与应用[D]. 济南:山东师范大学(博士学位论文),2009.
[4] Shi Y, Eberhart R. A Modified Particle Swarm Optimizer[C] // IEEE, World Congress on Computational Intelligence, AK, USA, 1998:69-73.
[5] 严露. 粒子群算法研究与应用[D]. 成都:电子科技大学(硕士学位论文),2013.
[6] 陈曦. 离散粒子群算法的改进及其应用研究[D]. 合肥:安徽大学(硕士学位论文),2014.
[7] 刘建华. 粒子群算法的基本理论及其改进研究[D]. 长沙:中南大学(博士学位论文),2009.
猜你喜欢
中小企业管理与科技·中旬刊(2016年11期)2017-02-17
南水北调与水利科技(2016年5期)2016-12-27
预测(2016年5期)2016-12-26
智富时代(2016年12期)2016-12-01
智富时代(2016年12期)2016-12-01
商情(2016年40期)2016-11-28
商(2016年32期)2016-11-24
商(2016年27期)2016-10-17
科学与财富(2016年28期)2016-10-14
科技视界(2016年20期)2016-09-29
