
基于K—means聚类算法成绩分析的应用探究
2016-05-30 15:32张贵元
科技创新导报 2016年3期
张贵元
摘 要:数据挖掘是在海量的数据中寻找模式或规则的过程。随着学校招生规模的扩大,在校学生成绩分布越来越复杂,传统的成绩分析有一定的局限性,该文介绍了K-means聚类算法的原理和算法流程,针对学生成绩数据进行选择、预处理,运用K-means聚类算法对学生成绩数据进行聚类挖据分析等。通过聚类结果分析,打破原有成绩分析得局限,使现有数据体现更好的价值,从而辅助教学管理者做出相应决策,更好地提高教学质量。
关键词:数据挖掘 K-means算法 聚类分析 成绩分析
中图分类号:TP31 文献标识码:A 文章编号:1674-098X(2016)01(c)-0090-03
Abstract:Data mining is the process of finding patterns or rules in massive data. With the expansion of school enrollment,students in grades distribution are more and more complex,the traditional performance analysis has some limitations.This paper introduces the theory and algorithm process of K-means clustering algorithm,to choose for student achievement data,preprocessing, on student achievement data clustering mining to analysis using the K-means clustering algorithm.Through the analysis of clustering results,breaking the original performance analysis is limited,so that the existing data to reflect the better value,so as to assist the teaching managers to make corresponding decisions,to better improve the quality of teaching.
Key Words:Data mining;K-means algorithm;Clustering analysis;Performance analysis
在現代信息化被广泛应用的时代,在我们日常教学中,面对错综复杂的学生成绩信息和各种各样的学习方法和学习方式,针对学生不及格的课程成绩信息群体,我们传统的数据分析有一定的局限性,通常还是停留在简单的统计、查询和汇总等层面,往往对这些数据背后的深一层原因无所了解,而聚类分析通过数据挖掘技术对这个数据群体进行处理,通过聚类、划分、分群,将有助于学校从堆积如山的数据中,发掘有利于教学的具有针对性的信息。利用聚类分析方法能从数据中找出相关的特征或模式,可以帮助学校针对不学生的学习状况,制定针对性的教学策略,对学生信息聚类和分组可以帮助改善学生学习成绩,并且可以根据此数据信息预测将来的成绩趋势,辅助学校进行教学管理。
1 聚类分析
数据挖掘的方法中聚类是对记录分组,把相似的记录放在一个类别里。聚类和分类的区别是聚类不依赖于预先定义好的类,不需要训练集。
聚类分析中,首先需要确定基本聚类分析原则,在各聚集内部数据对象间之间,追求的是相似度最大化。而在各聚集对象之间,追求的是相似度最小化。在进行聚类分析时,聚类分析所获得的组可视为同类别的归属,也可视为该类归属的数据对象集合。聚类分析已经在模式识别图像处理、市场分析和数据分析等领域得到了广泛应用。
2 K-means聚类算法
学生成绩挖掘分析主要目标是针对学生成绩数据进行聚类分析,挖掘出数据隐含的不同学生群体信息。而K-means聚类算法是数据挖掘基于划分最经典的聚类方法,也是易于实现的算法。主要思想是首先初始化K个聚类簇中心,使用一定的准则将所有样本点分到不同的K个簇中;接着计算现有的K个簇的质心,确定新的簇心。一直循环迭代,直到簇心的移动距离小于某个给定的阈值。如果初始簇心选择不好时,K—means的结果会很差,所以一般是多运行几次,按照一定标准选择一个比较好的结果。
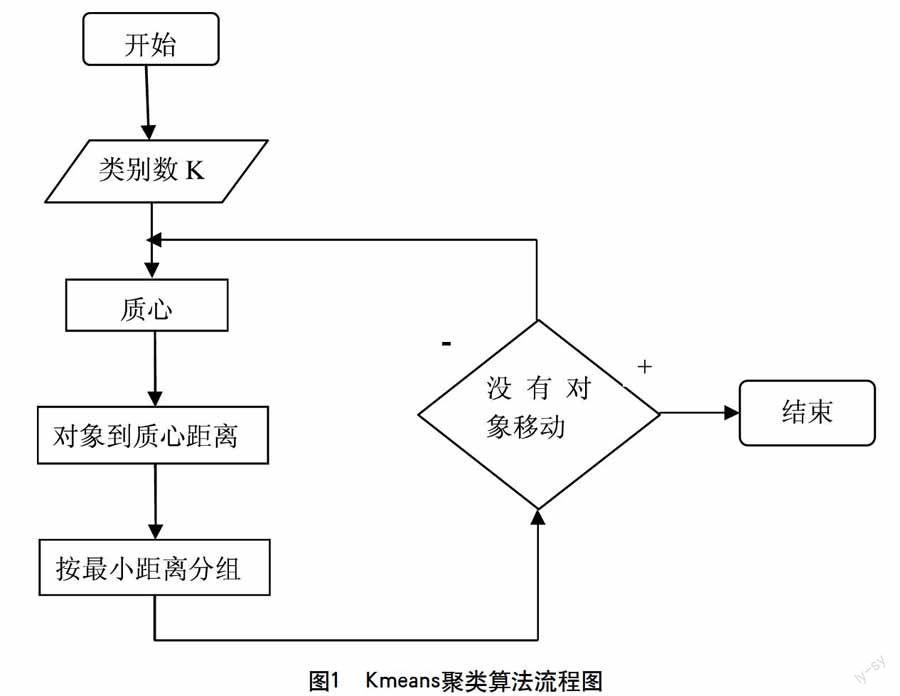
K-means聚类算法的主要流程如下。
(1)初始化K个聚类中心。
(2)计算每个点到聚类中心的距离,将每个点划分到离该点最近的类别中去。
(3)更新个类别中所有点的坐标均值,并将其作为新的聚类中心。
(4)反复执行(2)(3),直到聚类中心不再进行大范围移动或者聚类次数达到要求为止。
算法的流程图如图1所示。
3 K-means聚类算法应用
在使用K-means聚类算法聚类分析之前,必须对数据进行预处理,信息数据预处后,才可以利用K-means聚类算法对处理后的成绩数据聚类分析,最后将聚类结果可视化展示。
3.1 数据预处理
学生成绩数据库中,由于少数学生的个别错误信息和虚假信息可能导致聚类中心偏移,从而对聚类结果产生影响。需要在研究各属性值的总体分布后,删除这些对聚类结果准确性有所影响的部分极值。因此要对数据进行清洗、去重和修正等操作。
在进行学生成绩信息分析挖掘过程中,不是所有的属性信息都和学生成绩信息分析任务有关,比如进行学生聚类分析时的学生专业等属性。因此,在进行数据转换过程中,把和学生成绩数据分析挖掘不相关的属性去除有助于提高数据挖掘的效率,节省分析挖掘时间,将与挖掘分析任务相关的数据进行格式转换,对一些属性值进行数字量化,使得转换后的数据更好地适合数据挖掘分析。
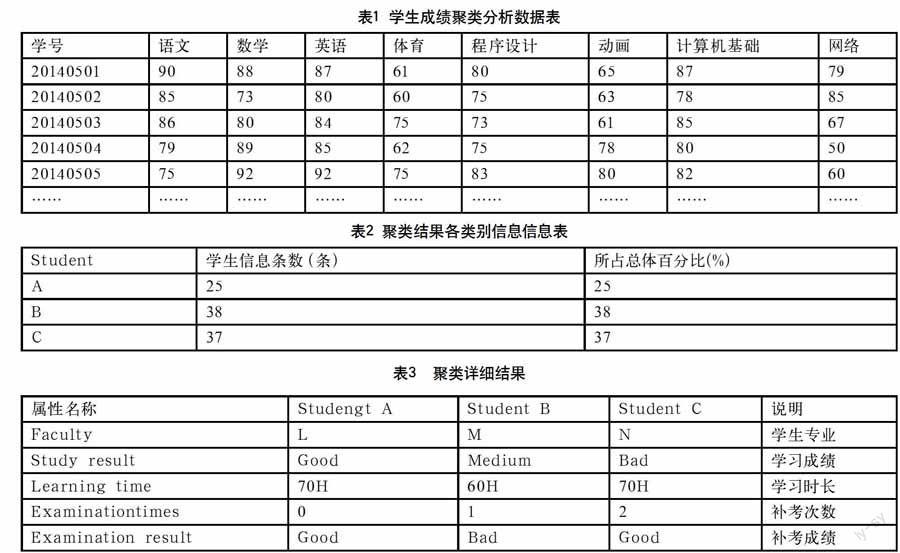
此次数据源是以东莞理工学校2014级计算机专业学生成绩为数据源,选取2014级100名学生的8门课程成绩数据,经过初步的一些修正和转换,学生数据属性包括:專业、年级、班级、学号、学习科目、学习课时、科目成绩、学科评分等信息,学生成绩数据部分信息如表1所示。
3.2 K-means聚类算法应用
针对预处理后的学生成绩数据,使用聚类算法K—means进行,分析挖掘不同学生群体类别信息,并将得到的挖掘结果输入分析结果可视化模块中进行输出展示。使用的学生成绩数据信息是表1中的100条成绩数据记录,聚类分析的实验环境是通过SPSS软件中的“K-均值聚类法”,给定聚类数为3,经过信息数据预处理模块、信息分析挖掘模块、分析结果可视化模块的处理,最终得到Cluster-A、Cluster-B和Cluster-C三种群体。总体的类别信息如表2所示。
经过聚类,可以发现,目前该学校的学生群体基本上可以分为A、B、C三类,每类学生群体有自己的类别属性,表3是部分聚类详细结果。
3.3 聚类结果分析
根据K-means聚类的结果分析可以看出,A类学生一共25个,是属于整个群体中优秀的;C类学生一共37个,是属于整个群体比较差的;B类学生一共38个,属于A类和C类之间。从整个聚类结果分析,C类学生的比例和B类学生的比例相当,而且A类学生不足该群体1/3,优秀学生所占比例较少,C类学生所占比例较大,这样就给教师有一个预警作用,需要加强B类学生,需要有针对地制定策略帮助C类学生,提高他们的成绩。
通过表3观察,A类学生群体中各种属性值都是比较好的,说明A类学生的各方面综合素质还是比较高的,C类学生的学习时长和A类是同等的,那就说明针对C类的学生他们同样付出了,但是效果不好,那就可以有针对地进行学习方法的辅导,多元化帮助他们。而B类中大家可以观察到他们的补考成绩是差的,那就应该对于B类学生加强他们对于补考的重视,提高他们补考成绩,从而不影响他们毕业和升学。
4 结语
通过介绍在大数据和信息化背景下,针对学生不及格数据信息进行聚类分析。聚类分析目前已经被广泛地应用于各个行业,文章重点针对K-means聚类算法的主要思想和算法流程进行阐述,同时基于K-means聚类算法挖掘的学生成绩分析,通过每一类群体属性的不同,学校可以制定具有针对性的教学策略,促进学生学习成绩得改善和提高。
参考文献
[1] 孙吉贵,刘杰,赵连宇.聚类算法研究[J].软件学报,2008,19(1):48-61.
[2] 谭庆.基于K-means聚类算法的分析研究[J].河南大学学报,2009(4):412-415.
[3] 廖文果,廖光萍.基于数据挖掘的图书馆创新服务研究[J].软件导刊,2014(8):116-118.
[4] 汪福成.可视化数据挖掘在水利工程管理中的使用[J].环球市场信息导报,2015(39):74.
猜你喜欢
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
