
基于投影的文本图像版面分割算法研究
2016-05-30 03:09魏传义
现代计算机 2016年10期
魏传义,陈 勤,2,张 旻,2
(1.杭州电子科技大学信息安全部级重点实验室,杭州310018;2.杭州电子科技大学计算机学院,杭州 310018)
基于投影的文本图像版面分割算法研究
魏传义1,陈勤1,2,张旻1,2
(1.杭州电子科技大学信息安全部级重点实验室,杭州310018;2.杭州电子科技大学计算机学院,杭州310018)
摘要:版面分割算法是版面分析的重要组成部分,考虑自顶向下方法的效率优势以及所处理对象的特殊性,提出一种分列投影版面分割算法。该算法首先将文本图像进行列分区,划分为若干个列,然后对每一列进行投影扫描,通过多次投影将文本图像分割成若干个子区域。实验结果表明,该方法继承投影法本身计算速度快的特点,同时还可以避免图像信息弧度对版面分割的影响,并且对版面较复杂的文本图像也能够准确地分割。
关键词:文本图像;版面分割;自顶向下;分列投影
0 引言
信息时代发展之迅速,信息的不断膨胀对文本图像的存储产生巨大压力,因此需要对这些信息进行分层压缩。分层是把文本图像分离成前景层和背景层,然后采用不同的压缩编码技术,前景层主要包括文本和线条组成的一些区域,背景层包括纸的背景纹理和一些图片区域。分层的过程是对文本图像进行理解分析的过程,因此要通过版面分析的手段对文本图像进行分层。首先将文本图像划分为若干个子区域,然后通过区域识别将这些子区域进行分类。
文本图像的版面分割算法可以分为两类:自顶向下[1-2]和自底向上[3]。自顶向下方法从全局出发,逐步划分为多个子区域,代表性的方法有投影法[4-6]和游程平滑算法[7]。自顶向下方法的优点是速度快,但是对版面较复杂的情形适应性差。自底向上方法从像素或小区域出发,将具有相似特征的区域进行合并,最终形成多个子区域,常用的方法有区域生长法和区域分裂合并法。自底向上方法注重细节,但是计算量大。由于至今仍没有一个通用的方法,针对特定的场景要使用特定的方法。考虑到所要处理对象的特殊性,光照不均匀的情况可以由局部自适应二值化方法进行处理,倾斜的图像可以由倾斜校正方法处理,但是有时候会出现拍照的时候由于纸张不平或者角度不正确,导致图像中的文字、表格和图形会产生一定的弧度。标准的投影法从全局出发,将整个文本图像进行水平和竖直投影,通过投影轮廓图进行区域划分。当采集到的文本图像中含有弧度信息时,投影所产生的轮廓图特征就不明显,为版面分割带来了一定的困难。
本文提出一种分列投影版面分割算法,首先将文本图像划分为N列,然后对每一列进行水平和垂直方向投影,通过多次投影将文本信息划分为多个子区域。实验结果表明,该方法继承了投影法本身计算速度快的特点,同时还可以避免图像弧度对版面分割的影响,并且对排版较复杂的文本图像也有很好的适应性。
1 文本图像版面分割主要思路
首先将整个图像分成N个部分,每一部分高度不变,宽度是原来的1/N,划分结构如图1所示。由图1可以看出,对于一个含有一定弧度信息的文本图像,如果将整个文本图像划分为多列,每一列中信息的弧度基本可以忽略不计。因此可以有效地避免弧度对投影的影响,提高分割的准确度。
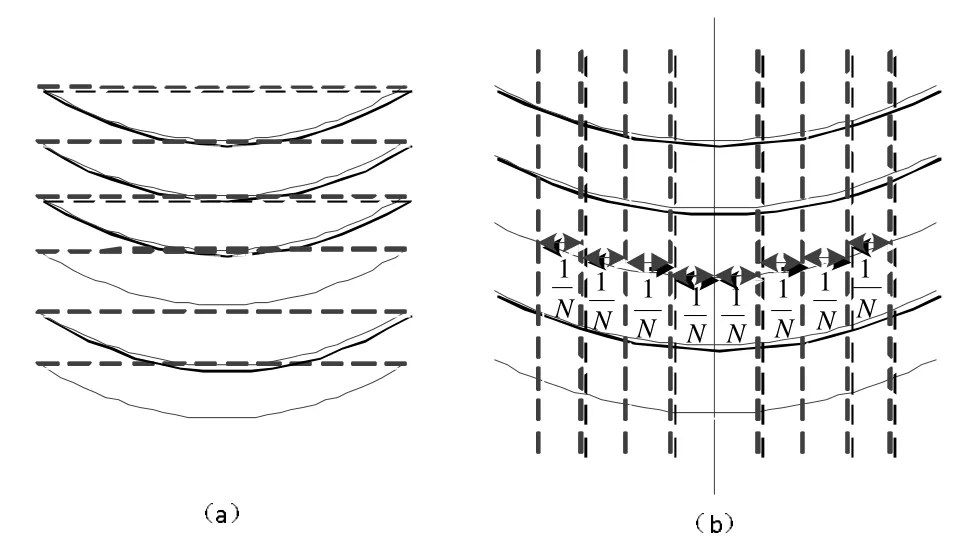
图1 含有弧度文本图像的分列结构图
经过分列之后,对每一列进行投影扫描,为了能更准确地进行版面分割,本文采用多次投影法。
文本图像版面分割的算法流程分为以下几个步骤:
(1)首先对文本图像进行预处理等一系列操作,然后在水平方向上进行投影扫描,通过投影图确定区域的上下边界。
(2)对每一个确定上下边界的区域,在竖直方向上进行投影扫描,同时运用游程平滑算法,确定区域的左右边界,形成了若干个矩形区域。
(3)对每一个矩形区域,在水平方向上进行二次投影扫描,将每个矩形区域划分出多个子矩形区域。
(4)对每一个子矩形区域进行特征提取,并将这些子区域进行识别分类。
2 分列投影版面分割
在上面的步骤中,投影方法分为3类:(1)水平方向投影;(2)竖直投影;(3)二次水平方向投影。
2.1水平方向的投影
二值化后的图像只有黑白两种颜色,像素灰度值为0和255,这里约定黑像素点记为1,白像素点记为0。即:

对二值图像从上到下逐行进行扫描,并同时获取每个扫描行的黑像素点,并统计黑像素点(即value(i,j)=1)的个数。即:
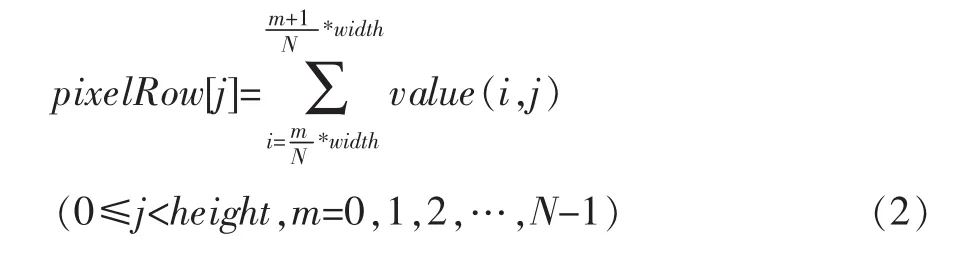
设定适当的阈值W,当pixelRow[j]>W时,记为1,否则记为0。即:
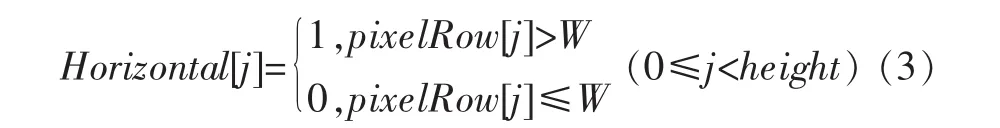
对于计算后得到的值Horizontal[j],遍历整个数组,当数组里的值由0变为1时,把j的值记录在flagStart[ ]中,当值由1变为0时,把j的值记录在flagEnd[ ]中,这两个标记所记录的是连续黑像素的上下边界,记录边界是为了能够更好地定位出所要分割的区域。
将Horizontal[j]中连续的黑像素值进行累加,得到多个值,每个值都表示一段连续的长度(L1,L2,…,Li,…,Ln),n为连续长度段的个数。文本图像中可能会包含有部分图片区域,由于图片区域的像素点比较密集,所以图片的黑像素的连续长度一般要比文字的要长,为了能够准确地定位出图片所在的大概区域,可以分为以下3种情况:
(1)由大量的文本图像统计可知:对于铺满整张的文本图像,当n≤8时,文本图像中必然存在较多的图片、表格等,在这种情况下,设定阈值T1,当Li>T1时,记录Li的上下边界;对于只铺满一部分的文本图像,阈值T1同样适用。
(2)对于铺满整张的文本图像,当n>8时,文本图像中存在较少的图片、表格等,在这种情况下,设置阈值T2,当Li>T2时,记录Li的上下边界;对于只铺满一部分的文本图像,阈值T2同样适用。
(3)对于纯文字的文本图像,通常会有一些大号字体,粗体等文字,这些字体的特征有时会和图片、表格的特征有些类似。这样的情况下,无论是铺满整张的文本图像,还是只铺满一部分的文本图像,都适用于上述两种情况下的阈值T1和T2,并记录Li的上下边界。
2.2竖直方向的投影
对于二值化处理后的文本图像,经过水平方向的投影之后,基本确定了一些区域(d1,d2,…,di,…,dn),这些区域具有可能包含图片、表格等具有类似特征的上下边界,然后对区域di从左到右进行扫描。由于字与字之间是有间隙的,不同特征的区域之间也是有间隙的。一般情况下,不同特征区域间的间隙要比文字间的间隙大,为了能更好地分割出一块整体的区域,不至于把每个字符都分割开来,需要把文字间的间隙进行填充。
游程平滑算法(RLSA)是扫描并检测同一行上的黑像素点之间的距离,当任意两个相邻黑像素之间的白像素游程长度小于设定的阈值时,则将这两点之间的所有白像素点转换为黑像素点。例如,对于水平扫描线上的一段游程,L=(P1,P2,…,Pi,Pi+1,…,Pj-1,Pj,…,Pn),其中游程L1=(P1,…,Pi)和L3=(Pj,…,Pn)是1-游程(即黑像素游程),而L2=(Pi+1,…,Pj-1)是0-游程(即白像素游程),设定阈值T,当L2的长度j-i-1小于设定的阈值T时,则将两个黑像素游程L1和L3连接起来(即把游程L2的全部平滑成黑像素点)。以T=4为例,如图所示的平滑过程中,其中有两个1-游程之间的0-游程长度为3,因此要被平滑为1-游程,这样通过游程扫描连接起来的1-游程的长度为10。
平滑前:1111100000 1111100011
平滑后:1111100000 1111111111
利用游程平滑算法,设定阈值T3,当字符内以及字符间的间隙小于T3时就被填充,不同的区域就更加明显了,然后再通过竖直方向的投影,把不同的区域划分开并记录不同区域的左右边界(原理同水平方向的投影),有了上下边界和左右边界,基本可以确定一些完整的矩形区域。
2.3二次水平方向的投影
经过竖直方向的投影之后,不同区域的上下边界和左右边界虽然已经确定,但是由于文字和图片或者表格在同一矩形区域的情况,以及部分水平区域错位的情况下,已经形成的矩形区域中不完全只包含图片、表格等。为了提高分割的准确率,对这些矩形区域再次进行水平投影,并把每一段连续的黑像素都进行分割,并重新记录上下边界,最终形成一系列的矩形区域(D1,D2,…,Di,…,Dn),并为每一个Di设置标记Mi=0。
分列投影的版面分割算法使用了多次投影的方法,投影次数为三次,并同时使用游程平滑算法。分列投影不仅可以有效地避免弧度对投影的影响,同时还有效地避免了双栏错位对投影的影响,提高了分割的准确度。在第二次投影时,使用了游程平滑算法,可以避免对文本行的过度分割。该算法速度快,执行效率高。不仅重视全局信息,同时也间接从局部出发,对于版面排版较复杂的文本图像也能较好地适应。
3 区域识别
对于得到的一系列矩形区域(D1,D2,…,Di,…,Dn),每一个Di可能是纯文字、图片、或者表格等,为了能更好地区分,需要对它们进行一些特征值的提取。因为最终需要的只有图片区域,对于其他区域予以排除即可。图片区域在二值化之后仍有大量而又密集的黑像素点,并且分布也不规则;而文字和表格等主要是由线条组成,字与字之间存在间隙,通过提取有效的特征值,可以准确地区分图片区域和其他区域。
(1)投影特征
版面分割得到的各个子区域Di在竖直方向上的投影存在着比较大的差异,文字区域和表格区域的投影峰值具有明显的周期性,而图片区域并不具有这些特点。文字区域由于文字间有间隙,因此垂直投影会出现周期性间断,表格区域由于存在表格框线,水平和垂直投影都会出现明显的周期性峰值。
(2)交错计数
交错计数所表示的是在图像某个方向上,像素黑白交替变换的频率。本文提取图像各个矩形区域Di在水平方向(PH)、竖直方向(PV)、对角线方向(PD)的交错计数。如公式(4)、(5)、(6)所示:

式(4)中:⊕表示异或运算。由于文字区域和表格区域主要是由线条组成,区域内会出现频繁的黑白像素交替,同样,对于大号黑体和粗体文字,黑白交替也会比较频繁,而图片区域则不会。
(3)边缘比
边缘比定义为子区域Di中边缘化后黑像素点总数和Di中黑像素点总数的比值。计算如公式(7)所示:

其中:
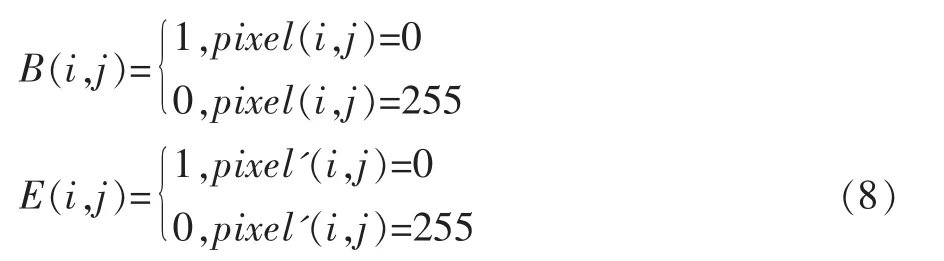
式(8)中,pixel'(i,j)表示区域Di中先进行二值化处理,再边缘化后的像素灰度值。由于文字和表格区域中是由大量的线条组成,边缘化后的信息非常丰富,因此,在进行边缘提取后,会保留大量的边缘像素点。而图片区域则并不具备这个特点。
对投影特征、交错计数和边缘比这些特征值的提取之后,通过这些特征值设计一个合适的判定策略,当子区域Di符合图片的特征时,记录其区域范围,并令Mi=1;否则,予以排除。
4 实验结果与分析
为了验证本章所提出的分列投影版面分割算法的有效性,针对含有弧度区域信息的文本图像,实验结果如图2(c)和(d)所示。
由图2可以看出,图(a)是原图,图(b)是二值化图,图(c)和(d)是由图(a)通过分列投影版面分割算法得到的结果。实验结果表明,该算法对于含有弧度的文本图像能够较好地进行分割,并且对于版面较为复杂的文本图像也能得到较好的结果。
由图(c)可知,部分的粗体文字也被分割了出来。因为这些粗体文字同样还有大量的像素点,具有和图片区域类似的特征,可以划分到该区域内。但是还有一部分粗体文字被划分到了图(d)的部分,主要是由于那部分区域的弧度较大所引起的。
同时本文还搜集了500幅文本图像,并对每幅图像都进行处理,处理步骤如图3所示。
总共500幅样本图像,经过人工筛选后,其中213幅为纯文本图像,287幅为图文混合图像,通过图3所示的流程对文本图像进行处理,实验结果如表1所示。

图2 弧度型文本图像分割效果图
参考文献:
[1]G. Nagy and S. Seth. Hierarchical Representation of Optically Scanned Documents[C]. ICPR(7),1984: 347-349.
[2]F.M. Whal,K.Y. Wong and R.G. Casey. Block Segmentation and Text Extration in Mixed Text/Image Documents[C]. CGIP,1982,20: 375-390.
[3]陈明,丁晓青,吴佑寿.多层次可信度指导下的自底向上的版面分析算法.模式识别与人工智能,2003,16(2): 198-203.
[4]王海琴,戴汝为.基于投影和递归的版面理解算法[J].模式识别与人工智能,1997,10(2): 118-126.
[5]Laurence Likforman-Sulem,Abderrazak Zahour. Text Line Segmentation of Historical Documents:a Survey [J]. International Journal on Document Analysis and Recognition,2007,9: 123-138.
[6]Zujovic. J,Pappas T N,Neuhoff D L. Structural Similarity Metrics for Texture Analysis and Retrieval[C]. Proceedings of the 2009 16th IEEE International Conference on Image Processing,Egypt: 2009. 225-228.

图3 文本图像处理流程图
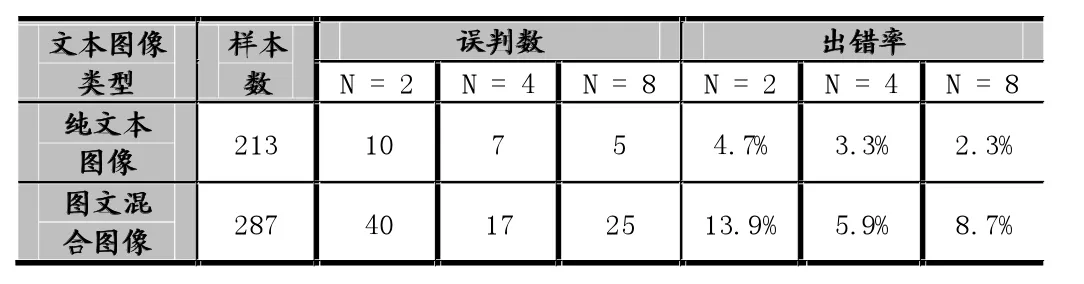
表1 实验数据结果统计
如表1所示,N为分列数。当N=4时,无论是纯文本图像,还是图文混合图像,都有较好的结果。对于纯文本图像,不同分列数的分割效果都比较好,虽然此时N=8的效果要好于N=4,但是对于图文混合图像,参数N越大,越容易对图片区域的过度分割,导致部分信息丢失,分割出错。
综合考虑以上情况,取参数N=4较好。
图2和表1的实验结果表明,有弧度的情形适合使用分列投影的方法。该方法从全局出发,将整体进行分列,并对每一部分进行版面分割,避免了弧度对投影分割所产生的影响。而自底向上的方法是从局部到整体的思想,对每一部分进行合并形成不同的区域。由于文本图像中含有弧度,在进行合并的时候,会把不同的区域进行粘连。如图4所示。

图4 自底向上方法的区域合并
由图4可知,当使用自底向上方法对文本图像进行区域合并时,由于弧度的影响,会使不同类型的区域进行粘连,容易导致分割不彻底,会将不同类型的区域混合在一起,产生错误的分割结果。
5 结语
本文所提出的分列投影版面分割算法,实现不复杂,运算速度快。对于目前大部分的文件资料、图书馆学习资料都有较好地分割效果。相对于标准的投影法,当文本图像是混合文本图像时,分割的准确率有了较大地提升。不仅可以有效地避免弧度对投影的影响,同时还有效地避免了双栏错位对投影的影响,对版面较复杂的文本图像也有较好的适应性。
研究过程中发现该方法仍然存在一些不足之处,阈值的选取对版面分割起到了关键的作用,直接影响分割的效果,对于版面很复杂的文本图像,该算法虽然有所改善,但是适应性依然不高。这些不足之处需要在以后的深入研究中逐步解决。
[7]C Strouthopoulos,N Papamarkos,C Chamzas. PLA Using RLSA and A Neural Network[J]. Engineering Applications of Artifical Intelligence,1999,12:119-138.
[8]王绪.文本图像处理与表格图像识别算法研究[D].解放军信息工程大学,2010.
[9]靳从.中文版面分析关键技术的研究[D].南京理工大学,2007.
[10]郭丽,孙兴华,王正群,等.一种基于连通域的版面分割方法[J].计算机工程与应用,2003,5:103-107.
陈勤,男,教授,硕士生导师
张旻,男,博士,讲师
Research on Document Image Layout Segmentation Algorithm Based on Projection
WEI Chuan-yi1,CHEN Qin1,2,ZHANG Min1,2
(1.Ministerial Key Laboratory of Information Security,Hangzhou Dianzi University,Hangzhou 310018;2.College of Computer Science,Hangzhou Dianzi University,Hangzhou 310018)
Abstract:Layout segmentation algorithm is an important part of layout analysis, considers the efficiency advantage of the top-down approach and the special properties of the processed object, presents a breakdown projection layout segmentation algorithm. Firstly, the text image column partition, is divided into several columns. Then for each column projection scanning, by repeatedly projected the text image split into several sub-regions. Experimental results show, this method inherits the projection method to calculate the characteristics of speed, while avoids the influence of the curvature of the page segmentation, and for more complex text layout image also be able to accurately split.
Keywords:Document Image; Layout Segmentation; Top Down; Breakdown Projection
收稿日期:2016-01-21修稿日期:2016-03-24
作者简介:魏传义(1990-),男,河南商丘人,硕士研究生,研究方向为智能图像处理
文章编号:1007-1423(2016)10-0033-06
DOI:10.3969/j.issn.1007-1423.2016.10.008
基金项目:浙江省重大科技计划项目
