
基于ALS协同过滤算法的个性化推荐研究与应用
2016-05-28 09:09董银
无线互联科技 2016年6期
董银
摘要:随着大数据和数据挖掘技术的不断发展和成熟,个性化推荐越来越发挥着重要作用。为了能够更有效地向用户推荐其感兴趣的产品,文章研究了在Spark平台架构基础上使用ALS协同过滤算法在个性化推荐系统中的应用,并对该系统作了性能和效果的评估。根据实验表明,基于Spark平台的ALS算法能有效地为用户推荐其所感兴趣的产品,从而达到个性化推荐的目的。
关键词:个性化推荐;协同过滤;Spark;ALS
随着互联网数据的不断增加,如何快速而高效地从如此丰富而复杂的大量数据中为用户挑选出自己真正感兴趣和喜欢的信息变得越来越紧迫。近年来随着个性化推荐系统的兴起和发展,为解决这些问题提供了重要手段。推荐系统通过记录和分析用户所产生的日志数据构建用户的兴趣模型,再通过用户的兴趣模型为用户推荐其喜欢和感兴趣的产品。目前个性化推荐系统在购物网站和新闻网站等领域得到了广泛的应用,比如Amazon购物网站、豆瓣、今日头条等。目前在推荐系统中应用最为成功和广泛的推荐技术是协同过滤。
协同过滤是指收集用户过去的行为以获得其对产品的显式或隐式信息,即根据用户对物品或者信息的偏好,发现用户的相关性或者物品本身的相关性,然后再基于这些相关性进行推荐。目前,基于协同过滤的推荐分为基于物品的协同过滤(ItemCF)、基于用户的系统过滤(UserCF)和基于模型的协同过滤(ModelCF)。为了更加快速、有效和准确地为用户推荐其喜欢的产品,本文主要研究了基于Spark平台上的ALS协同过滤算法的个性化推荐系统。
1 Spark简介
Spark是一个基于内存计算的分布式框架,提高了在大数据环境下数据处理的实时性,同时保证了高可伸缩性和高容错性。Spark中的计算模型和Hadoop中的MapReduce类似,不同于Hadoop的是,Spark的计算过程是在内存中进行的,从而减少了硬盘的读写操作,可以将多个操作进行合并后计算,因此提升了计算速度。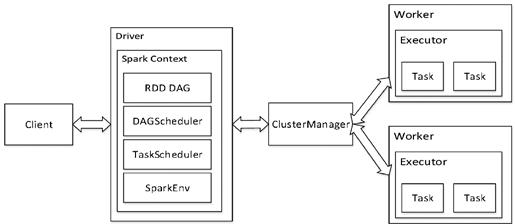
图1为Spark架构图,其整体流程为:Client作为客户端将应用程序提交到Driver中,Driver则向Master(即ClusterManager)申请资源,然后将应用程序转换为RDD Graph,再由DAGScheduler将RDD Graph转换为Stage的有向无环图提交给TaskScheduler,由TaskScheduler将任务分发给Woker节点中的Exeutor执行。
2 ALS算法研究
ALS是Alternating Least Squares的缩写,意为交替最小二乘法。该方法常用于基于矩阵分解的推荐系统中。例如:将用户(user)对商品(item)的评分矩阵分解为2个矩阵:一个为商品所包含的隐含特征矩阵,一个为用户对商品隐含特征的偏好矩阵。在这个矩阵分解的过程中,评分缺失项得到了填充,因此可以基于这个填充的评分给用户作商品推荐了。以下就ALS算法理论做一个介绍。

3 ALS算法在个性化推荐上的应用
为了实现ALS算法在Spark平台上的具体应用。本文的系统结构主要由3个模块组成,分别为输入模块、推荐模块和输出模块。输入模块主要将用户的行为数据转换成用户偏好数据,再运用数字表示用户对产品的偏好。推荐算法模块主要是通过ALS模型的协同过滤算法生成推荐结果。输出模块是将通过推荐算法产生的推荐结果(去除掉一些用户已购买过的产品),生成最终的推荐列表从而为用户进行推荐。如图2所示,为本文中个性化推荐系统的处理流程。
3.1 用户偏好数据处理
通过解析用户访问网站所产生的行为日志,对用户行为数据进行数据预处理操作(即ETL操作),得到用户对某产品的浏览、购买、评论、加入购物车和加入心愿单行为数据,作为用户画像模型的5组向量,再结合实际生活情况按5种不同行为分别赋予不同的权值。通过对用户的行为进行加权处理后得到用户对某产品的偏好得分。其中,偏好得分计算公式为:S =购买*0.4 +评论*0.15+购物车*0.25+心愿单*0.15+浏览*0.05,依此方法,最终形成用户对所有产品的偏好得分,从而生成用户的偏好模型。
3.2 构建ALS推荐模型
通过(1)中建立的用户偏好模型是ALS的输入样本,其后的处理过程是:首先输入用户的偏好数据(偏好数据格式为:用户ID、产品ID、偏好得分),然后初始化ALS权值,计算通过ALS预测的偏好得分和训练样本中的偏好得分的均方差,使其RMSE小于预定值,若未小于预定值则继续训练增加的模型,最后为用户产生推荐列表。
3.3 Spark平台上的实现
ALS算法在Spark平台上的实现过程是:首先将用户偏好数据从数据库中导出上传到HDFS(Hadoop Distribute File System)上,再使用SparkContext类中的textFile函数加载HDFS上的偏好数据文件并创建RDD(Resilient Distributed Datasets),作为ALS训练的输入数据。其次,输入迭代次数向量I=(5,8,10,15,20)T和隐含因子向量R=(5,10,20,30,40,50,60,70)T,通过不断初始化参数即循环选择I和R的值,代入ALS类中的train(ratings,rank,numIterations,lambda)(其中:ratings为用户的偏好数据,rank为R中的隐含因子,numIterations为I中的迭代次数,lambda为正则化参数本文中取0.01)函数中,生成用户偏好的预测结果,计算每次更新参数后模型的RMSE,最终通过获取最小的RMSE来确定最优参数的取值。最后使用最优的ALS模型为用户做推荐,使用MatrixFactorizationModel中的recommendProductsForUsers方法为每个用户生成推荐结果,并使用RDD中的saveAsTextFile函数将结果保存到HDFS上。
4 实验和结论
4.1 实验环境
本实验组建的Spark集群由1台Master主机、7台Slaver主机组成。实验中使用的数据为用户每天在网站中产生的行为数据,通过分析用户的行为日志和ETL操作将其转换为用户对产品的偏好得分。其中共有11924653行用户对产品的偏好数据、662926个用户和75288个产品构成。
4.2 性能评估
为了验证基于Spark 平台下ALS协同过滤算法对推荐性能的影响,本文使用不同数目的Spark集群节点来做实验以获得较优的效果。图4为推荐模型训练时间随工作节点数目变化的情况。
由图3可以看出随着集群节点的增多,Spark ALS模型训练时间不断减少,但其处理速度并不是随着节点增加而线性减少的。从图4可知当工作节点增加到4个时,模型训练速度的变化开始没有那么明显了,根据Amdahl定律,并行化的程序所获得的加速比和程序中可并行执行的代码有直接关系,因此,处理时间并不是随着节点线性变化的。
4.3 推荐效果评估
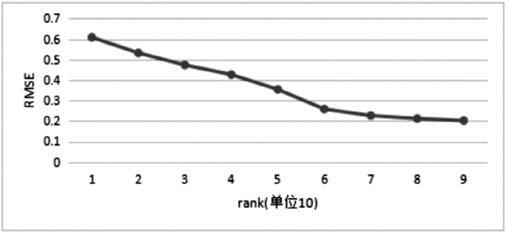
本文中通过调整隐含因子数量(rank)和计算的迭代次数(numIterations)来减小RMSE的值,从而达到最好的推荐效果。由图4可以得出随着隐含因子的增大,其模型均方差越小,表示其预测的模型越接近真实的偏好模型。
5 结语
本文首先对Spark和ALS协同过滤算法作了介绍和原理推导,然后研究了基于Spark平台下的ALS协同过滤算法在个性化推荐上的性能和效果,发现基于Spark平台下的ALS推荐模型可以为用户合理、有效地推荐其感兴趣的产品,从而可以提高用户的体验度和网站的转换率等。
[参考文献]
[1]李宇澄.协同过滤算法研究[D].上海:复旦大学,2005.
[2] Koren Y,Bell R,Volinsky C.Maxtrix factorization techniques for recommender systems[J].Computer,2009(8):30-37.
[3]Apache Spark.[EB/OL].[2013-12-20].http://spark.apache.org/.
[4]Wbite T.Hadoop权威指南[M].3版.北京:清华大学出版,2010.
[5]Pilaszy I,Zibriczky D,Tikk D.Fast ALS-based Matrix Factorization for Explicit and Implicit Feedback Datasets[C]// Proceedings of the fourth ACM conference on Recommender systems.New York:ACM,2010.
[6]李改,李磊.,基于矩阵分解的协同过滤算法[J].计算机工程与应用,2011(30):4-7.
[7]Hill M D,Mary M R.Amdahls law in the multicore era[J].Computer,2008(7):33-38.
Research and Application of Personalized Recommendation Based on ALS Collaborative Filtering Algorithm
Dong Yin
(School of Computer Science, Wuyi University, Jiangmen 529020, China)
Abstract: With the continuous development of big data and data mining technology, more personalized recommendation system has played an important role. In order to more effectively to recommend interesting products for user, this paper studies the application that using ALS collaborative filtering algorithm in personalized recommendation system on the spark paltform and evaluating the performance and effectiveness of the system. According to the experimental results show that the ALS algorithm based on Spark platform can effectively recommend the products they are interested in, so as to achieve the goal of personalized recommendation.
Key words: personalized recommendations; collaborative filtering; Spark; ALS
猜你喜欢
东方教育(2016年8期)2017-01-17
中国新通信(2016年22期)2017-01-13
软件导刊(2016年11期)2016-12-22
现代情报(2016年11期)2016-12-21
电脑知识与技术(2016年27期)2016-12-15
电脑知识与技术(2016年27期)2016-12-15
电脑知识与技术(2016年26期)2016-11-24
商(2016年34期)2016-11-24
