
基于稀疏子空间聚类的跨域人脸迁移学习方法
2016-05-25 00:37朱俊勇
中山大学学报(自然科学版)(中英文) 2016年5期
朱俊勇,逯 峰
(1. 中山大学数据科学与计算机学院, 广东 广州 510006;2. 广州市刑事科学技术研究所,广东 广州510050)
基于稀疏子空间聚类的跨域人脸迁移学习方法
朱俊勇1,2,逯 峰2
(1. 中山大学数据科学与计算机学院, 广东 广州 510006;2. 广州市刑事科学技术研究所,广东 广州510050)
人脸识别的效果很大程度上依赖于已标定的训练数据的规模,当训练样本严重不足时类内及类间分布的估计将会出现严重偏差。考虑到人工标定的成本过高,如果能对与目标问题相关的一些已有数据加以利用,以此来取代人工标定数据或减少人工标定的数据量,将为训练样本不足的人脸识别问题提供一套可行的解决方案。为此,拟针对这一问题发展出一种基于稀疏子空间聚类和鲁棒主成分分析的人脸迁移学习方法,在辅助数据满足多线性子空间假设下,能从无类标的异源辅助数据中实现信息迁移,挖掘对目标分类问题有益的成分。
稀疏子空间聚类;低秩矩阵分解;鲁棒主成分分析;跨域人脸迁移学习
最近几年,随着机器学习的快速推广和海量视频数据的日益剧增,计算机视觉领域的多个关键研究方向诸如人脸识别、物体检测、车辆分析等等取得了重大突破[1-2]。但是,目前主流的学习方法受限于大量的标记样本,当已标记的训练数据严重不足时,计算机在学习过程中往往会出现过拟合现象,使得学习得到的模型在测试过程中无法获得应有的效果。本文主要研究在有限标定样本的情况下,如何从未标定的异源辅助数据中挖掘对人脸识别有益的可迁移成分。这一问题的研究对于许多应用而言具有非常实际的意义,譬如,护照或身份证件上通常附带了一张“标准”照片,所谓“标准”是指人脸拍摄的环境是相对理想的,如人脸正面朝向摄像机、均匀光照环境、中性表情等等,而在实际应用中,实时采集的人脸图像往往处于非可控的环境当中,容易受到光照、姿势、表情等因素的干扰,在缺少先验信息的情况下要实现两者的匹配将相当困难[3]。因此,假如能对非目标个体在不同环境下的人脸辅助数据加以利用,将有可能为先验信息缺乏的人脸识别问题提供一种可行的解决思路。考虑到大规模人脸系统的样本标定工作非常耗时,并且目标个体的训练样本在某些情况下很难得到,发展一种基于无类标辅助数据的人脸识别方法显得非常有必要。
迁移学习通过从已有模型或数据中提取对目标问题有用的辅助信息[4-5],已逐渐成为学术界关注的焦点。迁移学习的总体目标是在目标域样本不足的情况下最大化利用与目标域相关的异源辅助数据,从中挖掘对目标分类问题有用的信息。与传统的机器学习方法(如有监督学习、半监督学习)不同,迁移学习方法涉及的源域及目标域样本并不一定要满足独立同分布假设,甚至可以是来自于不同(但相关)的类别。然而,要采用怎样的基准,使用哪种量化方式去衡量源域及目标域数据的相关性,迁移哪些相关特征,一直都是困扰迁移学习的关键问题。
虽然,传统的无监督和半监督学习方法,如主成分分析(PCA)[6-7]、无监督鉴别投影 (UDP)[8]、半监督线性鉴别分析(SDA)等[9],均可利用未标识或部分标识的辅助数据进行信息迁移,但是,这些方法基于数据同源假设,对迁移学习中目标域数据与源辅助数据来自不同类别的情况并不一定适用。
目前,现有的迁移学习方法主要集中研究辅助数据带有类标的情形,并且,源域与目标域之间的关系往往已知[10]。然而,要确定目标域与源域样本之间的关系已是非常困难的事情,在某些情况下这种关联无法得到精确表达,很难分辨出辅助数据中的哪一部分的信息可能有利于目标域的分类问题。最近提出的研究工作表明,目标域与源域之间关联性可在一定程度上适当放松[5],但这种方法的代价是要知道所有辅助数据的类标信息,以全监督的形式对辅助数据加以利用。考虑到样本的标定工作非常消耗人力和时间,对于大规模辅助数据的情况并不适用。
为此,本文拟发展一种迁移学习模型,通过稀疏子空间聚类和鲁棒主成分分析,从无类标辅助数据中挖掘可迁移成分。与本研究更为相关的是,Raina等[11]提出的自学习方法(Self-taught Learning, STL),该方法利用大量无类标的辅助数据建构特征词典,并通过稀疏编码得到目标样本在该词典下的表达作为分类特征。然而,自学习方法不加筛选地使用所有辅助数据,并且词典的学习过程只关注表达误差而忽略鉴别特性的提取,对目标分类问题并不一定能带来积极的效用。与自学习方法相比,本文的方法属于鉴别学习模型,以目标域的样本分类为最终目标。
此外,Wolf 等[12]提出了一种使用目标类别信息的迁移学习方法——基于单样本的相似性核学习(One-shot Similar Kernel, OSSK)。该方法事先定义一个特殊的负样本集,并根据两个样本与该集合的关系来确定样本间的单样本相似度(one-shot similarity),从而间接地得到两者的关系。Dai等[13]也提出了一种基于无类标辅助数据的迁移学习方法,该方法通过图模型来刻画目标数据与源数据的相互关系,采用的是直推式学习框架,在学习的同时需要用到所有测试样本,对实际应用有一定的限制。
为了克服现有模型的以上缺点,本文提出一种基于稀疏子空间聚类的迁移学习方法。得益于稀疏子空间聚类方法的自表达特性[14],该方法能从大量无类标辅助数据中自动发现具有相近子空间表达的样本子集,进而通过鲁棒主成分分析分解出低秩的人员成分和稀疏的噪声成分[15],结合目标域的鉴别信息加以利用,一方面能够扩宽目标域的人员鉴别能力,另一方面减少目标域受到同类噪声的影响。同时,通过引入正交匹配追踪(Orthogonal Matching Pursuit, OMP)[14]以及快速主成分追踪(Fast Principal Component Pursuit, FPCP)[16]等加速技术,本文方法能处理大规模数据并有效减少时间开销。
1 相关工作
本文方法通过稀疏子空间聚类以及鲁棒主成分分析对无类标辅助数据进行分析和挖掘,本节将围绕稀疏子空间聚类以及鲁棒成分分析两种方法进行简要介绍。
1.1 稀疏子空间聚类
(1)
其中Aj∈RD×dj为线性子空间Φj的一组基,sk∈Rdk为非零向量,其余{sj∈Rdj}j≠k均为零向量。特别地,若每一个线性子空间Φj的样本足够多(样本数远大于内蕴维数)且能张成整个子空间Φj,而Φj中的任意一个样本x均能表达为X/{x}的线性组合,则称样本集X具有自表达特性[14]。基于该假设,稀疏子空间聚类问题可归结为以下优化问题:
s.t.X=XC, diag (C) = 0
(2)
求得稀疏表达的系数矩阵C*后,通常取G=|C*|+|C*T|构建联姻矩阵,进而使用谱聚类[]即可得到稀疏子空间聚类的最终结果。
一般地,以上优化问题的复杂度随着X规模的增大会急剧增长,Pati等[17]通过引入正交匹配追踪技术(OMP)将该问题近似为基追踪问题,通过贪心策略依次从样本集中选取“最优表达”的样本,从而快速估算出每个样本在该样本集下的自表达系数。该方法大大提升了稀疏子空间聚类的运算能力,使其能够快速处理10万量级的样本集。
1.2 鲁棒主成分分析
鉴于传统主成分分析问题容易受到干扰噪声、缺失数据等影响,鲁棒主成分分析基于原始数据的低秩假设,通过将带噪观测数据分解成低秩成分和稀疏噪声成分,估计出原始数据的近似表达,在视频背景建模[15]、图像鲁棒特征提取及图像对齐[18]方面有着广泛应用。
具体而言,给定观测样本集Z∈Rd×N,鲁棒主成分分析的目标是要求解以下问题:
s.t.Z=L+S
(3)
其中L为低秩成分,S为稀疏成分,‖·‖*为核范数,λ为平衡系数。
针对以上问题,学术界提出了大量高效实用的求解方法,典型方法包括奇异值收缩[18]、增广拉格朗日乘子法(ALM)[19]、非精确ALM[20]、快速主成分追踪(FPCP)[16]等。其中快速主成分追踪法在同类测试中表现优异[21],适合处理大规模数据。
快速主成分追踪法仍是以观测数据的低秩估计为目的,将原问题(3)转化为等价问题:
s.t. rank(L)=t
(4)
进而采用交替优化的准则求解转化后的目标函数:
s.t. rank(L)=t
(5)

(6)
其中子问题(5)可通过基于Lanczos的局部奇异值分解[20]进行快速求解,而子问题(6)则可经由样本属性值收缩(element-wiseshrinkage)进行快速估算[16]。
2 模型建立
本节将针对目标域标定数据严重不足的情况,研究如何利用相关的异源无类标辅助数据实现人脸信息迁移。以下内容将着重介绍基于稀疏子空间聚类及鲁棒主成分分析的异源人脸信息挖掘技术,在此基础上发展出一种易于表达的子空间人脸迁移学习方法。
给定少量的目标域样本,我们希望通过利用大量未标定的异源数据来辅助得到适用于目标分类的鉴别子空间学习模型。尽管目标域数据和辅助数据并不一定来自同一组个体并且大多数辅助数据均不含类标信息,我们仍希望通过某些策略挖掘出其中有利于目标分类问题有用的信息。
2.1 异源无类标辅助数据子空间聚类
虽然目标域人脸数据和辅助人脸数据来源不同,且图像之间存在较大差异,但两者也存在着相似的结构、边缘或轮廓,在不受外界因素影响的状态下所有人的正脸图像近似满足正态分布[22],人脸数据之间存在某些隐含的关联信息。
一般地,我们很容易通过搜索引擎或社交网络收集到部分人在不同状态下的人脸数据,但这些人脸图像可能存在光照、姿态、遮掩等影响。为此,我们假设辅助数据来源于多个人在不同环境下的成像,我们的思路是通过稀疏子空间聚类对无类标人脸数据作预处理,挖掘出辅助数据中潜在的多子空间结构,进而采用鲁棒主成分分析对同一子空间内的多张人脸图像进行低秩分解,分离出与人员身份相关的低秩成分以及稀疏的噪声成分。下面将详细介绍异源无类标辅助数据信息挖掘的具体方法。
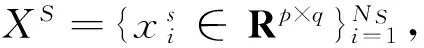
OMP算法[13]:c*=OMP(A,b)
输入:A=[a1,…,aM],b,kmax,ε
1: 初始化k=0,q0=x,T0=∅
2:whilek
4:qk+1=(I-PTk+1)b,PTk+1是由{aj}j∈Tk + 1引导间的投影映射
5:k←k+1
6:endwhile


图1 稀疏子空间聚类实例Fig.1 An example of sparse subspace clustering
2.2 异源无类标辅助数据鲁棒主成分分析
在2.1我们对无类标的辅助数据赋予了虚拟的类标,同类的样本张成了一个低维的子空间,因此,由同类的样本集组成的样本矩阵具有天然的低秩特性。考虑到人脸图像可能受到光照、姿态、遮掩等影响,对其进行鲁棒特征提取能有效地分离出与人员身分相关的低秩成分以及与噪声相关的稀疏成分。为此,下文将针对2.1节得到的稀疏子空间聚类的结果,在每个聚类中应用快速主成分追踪方法进行鲁棒特征的提取。
不妨记Zj为第j个聚类,根据低秩假设,样本集Zj可分解成Lj+Sj,其中Lj为低秩成分,Sj为稀疏成分,Lj和Sj的求解可通过快速主成分追踪实现,即求解以下优化问题:
s.t. rank(Lj)=t
(7)
其中t一般取较小的值,譬如t=1。
由此,我们从无类标辅助数据中分离出鲁棒的人员低秩成分和稀疏噪声成分(如图2所示),在下一节我们将结合目标域的数据,对辅助数据中的低秩成分和噪声成分加以利用。
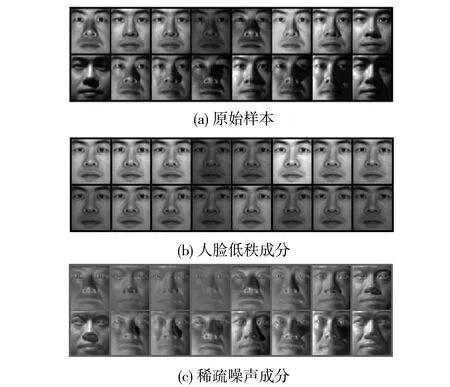
图2 鲁棒主成分分析实例Fig.2 An example of robust principal component analysis
2.3 基于异源辅助数据的人脸子空间迁移学习
在人脸识别的许多现实应用中,用于注册的人脸图像往往只有单张或少数几张,而且均为“理想状态”下的成像,这在一定程度上影响了注册人员人脸模型的完备性,使得在人脸识别过程中当存在外界环境干扰时容易出现错误识别。为了克服该问题,一般的做法是标定一个庞大的人脸数据库,涵盖不同环境下同一组人员的各种人脸变化。但数据标记的成本非常的高,实施较为困难。另一种可行的思路是引入与问题相关的无类标异源辅助数据,通过对数据进行预处理挖掘出可能对目标问题有利的信息。
在本节,我们将从两方面探索信息迁移的策略。根据人脸分布的高斯假设[22],不同个体的人像近似满足高斯分布,且相同个体的所有人像也能近似看成高斯分布。因此,为了提高人脸识别的能力,一方面可以通过增加不同个体的人脸图像来逼近类间分布,另一方面则可尽量减小相同个体不同人像间的类内差异。在无任何先验条件的情况下,增加个体的数目能丰富人脸总体分布的采样,有可能更好地描述总体高斯分布,同时也为类间的鉴别信息提供了更多依据;而在减小类内差异方面,则可通过分析相关辅助数据的内部差异,寻找减小该类差异的方法并将其应用到目标问题中。

s.t. WTW=I
(8)
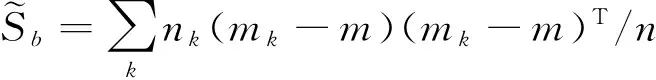

特别地,当目标人员只有单张训练图像时,Sw为零,目标函数(8)仍可通过求解广义特征值问题得到。
3 模型实验与验证
3.1 实验设置
考虑到本文的方法主要是在目标域训练样本不足的情况下从大量无类标异源辅助数据中挖掘可迁移信息,为了验证其在人脸识别问题中的有效性,该实验选用了6个人脸数据库并将其分成目标数据库以及辅助数据库两组,其中目标数据库包含CMU-PIE正面人脸图像子集[23]、AR数据库[24]以及ORL数据库;而辅助数据则来源于ExtendedYaleB数据库[25]、JAFFE数据库[26]以及UMIST数据库[27]。由于CMU以及YaleB数据库主要用于研究光照影响,AR和JAFFE均有表情因素,而ORL以及UMIST数据库主要涉及姿势变化,我们将其分成相应的三组,采用“YALEB-CMU”的形式来标记使用YaleB作为辅助数据时CMU库上的识别情况。对于每一个目标数据库,我们只选取一张正常状态下的人脸图像(正面光照、中性表情、正面拍摄图像)作为训练样本,其余用作测试样本。人脸图像均使用分块局部二值模式[28]进行特征编码。
本节比较了多种迁移学习以及相关的子空间学习方法,包括OSSK[12],STL[11],PCA[6],UDP[8]以及SDA[9],相关参数均使用原文的推荐值。
3.2 实验结果及分析
考虑到本文的方法基于无类标的辅助数据,我们与相关的无监督迁移学习方法作了相应比较。自学习方法(STL)是无监督迁移学习的典型代表,能从大量无类标数据中挖掘可迁移信息。然而相比之下,STL方法侧重于源辅助数据和目标域数据的统一表达,而本文的方法则更关注如何使用辅助数据来增强目标域的分类性能。如图3所示,由于本文的方法基于鉴别成分分析,其识别效果普遍要比STL方法高10%到20%。另外,我们还与单样本相似核学习方法(OSSK)进行了横向比较,尽管该方法也能使用无类标辅助数据对目标分类的边界进行修正,但效果要稍逊于本文提出的基于稀疏子空间聚类的人脸迁移学习方法,与之相比本文方法对辅助数据的可迁移信息挖掘更加的全面,在总体识别率上获得10%的提升。
此外,实验部分还比较了半监督鉴别子空间学习方法(SDA)。作为经典的半监督特征子空间提取模型,SDA在流形学习的理论框架下有效地对线性鉴别分析方法(LDA)进行扩展,使之适用于只有部分样本标定的情况。在SDA方法的模型背景下,通常要求无类标的辅助数据样本与带类标的目标问题样本具有相同的分布特性,当带类标的训练样本严重不足时即可通过辅助数据的流型结构来刻画目标域的潜在样本分布。从图3的结果来看,SDA的性能与STL方法相当,但与本文的方法相比总体上存在一定差距。其原因可能是SDA的同源假设,当辅助数据与目标域数据差异较大且无类标的辅助数据远远多于带类标的训练样本时,辅助数据的流形结构刻画未必与目标域的分类问题有直接关系。反观本文提出的方法,从异源无类标辅助数据中分离出鉴别成分和噪声成分进而与目标分类问题有效结合,更可能筛选出对目标问题有价值的信息。
最后,本节还与主流的一些无监督子空间学习方法,如主成分分析(PCA)和无监督鉴别投影(UDP)作了横向比较。对于这些方法,我们将目标域中带类标的训练样本以及所有无类标的辅助数据作为训练集,学习出相应的投影矩阵,再根据测试样本的投影结果进行后续比对。从图3的结果可以发现,UDP的识别结果不太理想,其原因与半监督学习方法的情况相似,由于UDP方法的目标是要保持原始数据的局部结构,当辅助数据的数量远远超过目标域数据时这些方法学习到的模型将会偏向于保持辅助数据的潜在流形结构而与目标分类问题没有直接的关系。而PCA的性能则相对稳定,由于PCA的目标是最大化地保留样本总体方差,当目标域每类个体只有单个样本时,样本的总体方差与类间方差是一致的。
3.3 模型鲁棒性分析

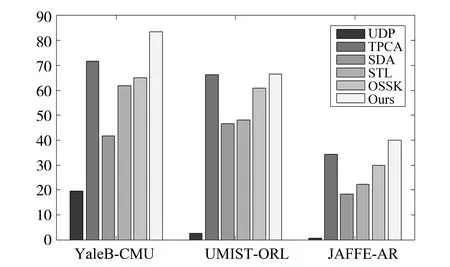
图3 各种算法在三组数据集下的实验结果Fig.3 Results of all algorithms on three data settings
由表1可以发现,取定相同聚类个数的前提下,稀疏子空间聚类算法的随机优化策略对聚类的结果影响不大,识别结果的最小值与最大值非常接近,因此可认为基于正交匹配追踪的稀疏子空间聚类方法的随机优化策略未对本方法造成显著的影响。而从聚类个数的设定来看,其取值并不限于真实的类别数,尽管不同的设定会造成1%~2%的偏差,但最终结果仍相对稳定,在实际应用中可根据情况取定一个常值。
4 结 论
本文提出了基于稀疏子空间聚类的跨域人脸迁移学习方法,在人脸辅助数据的多线性子空间前提假设下,通过稀疏子空间聚类的正交匹配追踪方法以及鲁棒主成分分析方法对异源辅助数据进行信息挖掘,剥离出鉴别成分和噪声成分,进而在Fisher准则的基础上对目标分类问题进行修正。该方法继承了正交匹配追踪、快速主成分追踪等方法的特性,能够快速有效地处理大规模无类标数据,对无监督迁移学习提供了一种可行的思路。

表1 不同参数下本文方法的识别结果Table 1 Results of proposed method under different parameters %
[1]SUNY,LIANGD,WANGXG,etal.DeepID3:facerecognitionwithverydeepneuralnetworks[J/OL].ComputerScience, 2015[2015-02-03].http:∥arxiv.org/abs/1502.00873.
[2]HEKM,ZHANGXY,RENSQ,etal.Delvingdeepintorectifiers:surpassinghuman-levelperformanceonimagenetclassification[J/OL].ComputerScience2015. [2015-02-06].http:∥arxiv.org/abs/1502.01852.
[3] 张智斌,赖剑煌,谢晓华,等. 基于高低频分量融合的人脸识别方法[J]. 中山大学学报(自然科学版), 2013, 52(4): 1-6.
[4]STARKM,GOESELEM,SCHIELEB.Ashape-basedobjectclassmodelforknowledgetransfer[C].InternationalConferenceonComputerVision, 2009: 373-380.
[5]LIFF,FERGUSR,PERONAP.One-shotlearningofobjectcategories[J].IEEETPAMI, 2006, 28(4): 594-611.
[6]TURKM,PENTLANDA.Eigenfacesforrecognition[J].JournalofCognitiveNeuroscience, 1991, 3(1): 71-86,.
[7] 左军, 周灵, 孙亚民. 基于RBF神经网络PCA变换的识别技术[J]. 中山大学学报(自然科学版), 2014, 53(6):135-139.
[8]YANGJ,ZHANGD,YANGJY,etal.Globallymaximizing,locallyminimizing:unsuperviseddiscriminantprojectionwithapplicationstofaceandpalmbiometrics[J].IEEETPAMI, 2007, 29(4): 650-664.
[9]CAID,HEX,HANJ.Semi-superviseddiscriminantanalysis[C].InternationalConferenceonComputerVision, 2007: 1-7.
[10]PANSJ,TSANGIW,KWOKJT,etal.Domainadaptationviatransfercomponentanalysis[J].IEEETNN, 2011, 22(2): 199-210.
[11]RAINAR,BATTLEA,LEEH,etal.Self-taughtlearning:transferlearningfromunlabeleddata[C].ICML, 2007: 759-766.
[12]WOLFL,HASSNERT,TAIGMANY.Theone-shotsimilaritykernel[C].ICCV, 2009: 897-902.
[13]DAIW,JINO,XUEGR,etal.Eigentransfer:aunifiedframeworkfortransferlearning[C].ICML, 2009, 193-200.
[14]CHONGY,DANIELPR,RENÉV,etal.Scalablesparsesubspaceclusteringbyorthogonalmatchingpursuit[C/OL].CVPR, 2016[2016-05-05].http:∥arxiv.org/abs/1507.01238.
[15]CANDÉSEJ,LIX,MAY,etal.Robustprincipalcomponentanalysis[J].JournaloftheACM,2000, 1(1): 1-73.
[16]RODRIGUEZP,WOHLBERGB.Fastprincipalcomponentpursuitviaalternatingminimization[C].ICIP, 2013: 69-73.
[17]PATIYC,REZAIIFARR,KRISHNAPRASADP.Orthogonalmatchingpursuit:recursivefunctionapproximationwithapplicationtowaveletdecomposition[C].ConferenceonSignals,IEEE, 1995: 1-3.
[18]PENGY,GANESHA,WRIGHTJ,etal.RASL:robustalignmentbysparseandlow-rankdecompositionforlinearlycorrelatedimages[J].IEEETSE, 2012, 34(11): 2233-2246.
[19]LIUG,LINZ,YUY.Robustsubspacesegmentationbylow-rankrepresentation[C].ICML, 2010: 663-670.
[20]LINZ,CHENM,MAY.TheaugmentedLagrangemultipliermethodforexactrecoveryofcorruptedlow-rankmatrices[J].EprintArxiv, 2010, 9.
[21]SOBRALA,BOUWMANST,ZAHZAHEH.LRSLibrary:low-rankandsparsetoolsforbackgroundmodelingandsubtractioninvideos[M]∥Robustlow-rankandsparsematrixdecomposition:Applicationsinlmageandvideoprocessing, 2016.
[22]CHEND,CAOX,WANGL,etal.Bayesianfacerevisited:ajointformulation[C].ECCV, 2012, 566-579.
[23]SIMT,BAKERS,BSATM.TheCMUpose,illumination,andexpressiondatabase[J].PatternAnalysis&MachineIntelligence,IEEE, 2010, 25(12): 1615-1618.
[24]MARTNEZAM,KAKAC.Pcaversuslda[J].IEEETPAMI, 2001, 23(2): 228-233.
[25]GEORGHIADESAS,BELHUMEURPN,KRIEGMAND.Fromfewtomany:Illuminationconemodelsforfacerecognitionundervariablelightingandpose[J].IEEETPAMI, 2001, 23(6): 643-660.
[26]LYONSMJ,BUDYNEKJ,AKAMATSUS.Automaticclassificationofsinglefacialimages[J].IEEETPAMI, 1999, 21(12): 1357-1362.
[27]GRAHAMDB,ALLINSONNM.Characterisingvirtualeigensignaturesforgeneralpurposefacerecognition[J].ComputerandSystemSciences, 1998, 163:446-456.
[28]AHONENT,HADIDA,PIETIKAINENM.Facedescriptionwithlocalbinarypatterns:applicationtofacerecognition[J].IEEETPAMI, 2006, 28(12): 2037-2041.
Cross-domain face transfer learning based on sparse subspace clustering
ZHU Junyong1,2, LU Feng2
(1.School of Data and Computer Science, Sun Yat-sen University, Guangzhou 510006, China;2. Insititute of Criminal Science and Technology, Guangzhou 510050, China)
The quality of a face recognition system heavily depends on the amount of labeled training data. Bias would probably exist in both in-class and between-class scatter when there is few labeled data. Considering the cost of manual labeling is too high, an alternative choice is to make use of existing data which is related to the objective problem. In this way, it is able to alleviate the dependence of manual labeling via exploring numerous related data, offering a feasible solution to the case of lacking sufficient labeled training samples. To this end, a face transfer learning approach based on the sparse subspace clustering and robust principal component analysis is proposed, which allows employing unlabeled source data under the multi subspace assumption and mining useful information for the objective problem.
sparse subspace clustering; low rank matrix decomposition; robust principal component analysis; cross-domain face transfer learning
10.13471/j.cnki.acta.snus.2016.05.001
2016-05-18
中国博士后科学基金资助项目(2015M582469);国家自然科学基金资助项目(61573387)
朱俊勇(1986年生),男;研究方向:人脸识别、迁移学习;通讯作者:逯峰;E-mail: lfgdga@163.com
TP391.4
A
0529-6579(2016)05-0001-07
猜你喜欢
河北理科教学研究(2021年3期)2022-01-18
发明与创新(2021年39期)2021-11-05
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
中国交通信息化(2019年10期)2019-11-16
铁道通信信号(2019年6期)2019-10-08
动漫星空(2018年9期)2018-10-26
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
