
基于HowNet和PAT树的网购评语情感分析
2016-05-18 02:37:09李永忠胡思琪
图书情报研究 2016年3期
李永忠 胡思琪
(福州大学经济与管理学院福州350108)
基于HowNet和PAT树的网购评语情感分析
李永忠 胡思琪
(福州大学经济与管理学院福州350108)
在对相关研究情况进行总结与分析的基础上,通过对HowNet情感词典进行扩展并利用基于PAT树和统计相结合的分词方法,对从淘宝网站中获取的评论内容进行分析,结果表明,基于HowNet和PAT树的情感分析方法对分析网购评论的情感倾向性行之有效,并以淘宝一女装商家为例进行实证研究,最后指出进一步探索情感倾向性分析的几个方向。
HowNet情感词典PAT树网购评语情感分析
1 引言
互联网的极速发展,现代信息化的迅速普及,使得网络成为高效、快捷的信息交流平台,它已经深入到人们的学习、工作和生活中,成为日常生活中不可或缺的一部分。网络购物拥有多方面的优势,如快捷、时尚、省时省力、可选性强等。随着网上购物人数的与日俱增,商品评语的数量也呈指数型增长,同时每个消费者在评论商品的时候,由于用语习惯的不同,会导致评论的无组织性和非结构化。并且每条评语可能评价的是商品的不同方面,顾客想了解某一方面的内容就需要从大量评语中寻找,这将会十分的不易。直接浏览商品的评论信息不仅耗时耗力,也很难形成一个客观整体的印象。顾客在浏览评语时主要想了解的一是顾客对该商品的总体印象,褒多于贬或者贬多于褒;二是商品某一具体属性的信息,如外观、质量、服务态度等。各大购物网站的评论功能,给了消费者了解商品实际情况的信息渠道和平台,其及时、便捷、互动的特性满足了顾客的信息需求。Nielsen公司的调研显示,70%的用户借助网上评论选择商品,其受信任程度仅次于亲友推荐[1]。对淘宝评语进行分析汇总,并将分析结果展示给消费者以及卖家,具有巨大的研究和应用价值。
2 相关研究情况
本文对基于情感词典的网购评论进行分析和研究,根据网购评论来判断其情感倾向性,因此,对于情感倾向性的分析就变得至关重要。情感分析方面的研究工作在近年来开始大量涌现,这些研究方法大致可以分为两种:一种是基于情感词典和语言知识的无监督学习方法,另外一种是基于情感类别标注数据的监督学习方法。本文所采用的是基于情感词典的无监督学习方法。
对于无监督学习方法,朱嫣岚、闵锦、周雅倩等学者基于HowNet,提出了两种词汇语义倾向性计算的方法,分别是基于语义相似度的方法和基于语义相关场的方法。他们通过实验证明,这两种方法在汉语常用词中的判别准确率可达80%以上,因此具有一定的实用价值[2]。曾淑琴、吴扬扬基于HowNet提出了词语相关度模型,这个模型可以计算同种词性以及不同词性之间的相关度,融合了词语的相似度、关联度和实例因素,综合获得词语的内在相关性。他们通过对比实验发现这个模型所计算的词语相关度值更加符合人们主观上对词语相关性的认识[3]。柳位平、朱艳辉、栗春亮等学者在中文词语相似度计算方法的基础上,提出了一种中文情感词语的情感权值的计算方法,并以HowNet情感词语集为基准,构建了中文基础情感词典。他们利用该词典结合TF-IDF特征权值计算方法,对中文文本情感倾向进行判别,通过实验结果表明,该方法取得了不错的分类效果[4]。
监督学习方法是由Pang和Lee于2004最早提出的用来解决文本情感分类问题的方法,它的整体思想是采取多种特征选择方法,并同时采用朴素贝叶斯模型、支持向量机模型和最大熵模型等来识别电影评论中所包含的情感[5]。
基于PAT树的相关研究中,杨文峰和李星利用PAT树实现了一种可变长统计语言模型。在该模型的基础上,通过相关性检测,从540M汉语语料中自动提取出了12万个关键词候选字串。最后,经过分析和筛选,候选字串的准确度由82.3%上升到96.1%。其实验结果表明,基于PAT树的统计语言模型是实现未登录词提取的有力工具[6]。
从Web网页中抽取评论文本是本文对网购评论研究必须要做的。李慧、沈洁、张舒[7]等于2007年提出了一种新颖的REA(Review Extract Algorithm)算法对评论信息进行发现与抽取。抽取过程的完全自动化也因刘伟、严华梁、肖建国[8]等的研究得到了进一步的实现。由于本文的研究对象是来自于淘宝网的评论内容,与以往相关研究的不同之处在于,淘宝网对外提供淘宝开放平台(Taobao Open Platform),本文通过淘宝开放平台这个更为便捷的方式来获取评论内容。
3 评论内容的获取与处理
3.1 获取评论内容
立足于淘宝中的各类电子商务业务,淘宝开放平台同时也能够提供一些原材料给所有来自淘宝外部的合作伙伴,这些原材料包括账号体系、API、数据安全等。本文研究的是淘宝评语的倾向性分析,因此要获取的是淘宝网的评论数据,就需要找出一个接口,这个接口作为从淘宝网导出数据的媒介。在这个对外部用户提供的开放平台中,它调用接口的方式是通过API来实现的,并且这些API都基于REST协议,兼容多种编程语言。通过按照top的规范POST来调用参数,这样淘宝评论数据就可以通过相应的接口返回来,以此来完成整个数据的获取。
3.2 评论内容的清洗
一件商品拥有着大量的用户评论,但是,真正能为研究者的分析提供有价值信息的评论内容却是十分有限的。一个很重要的原因是网页本身包含有众多的结构元素,这些无关的结构元素对评论内容造成了很大的干扰;另外一个很重要的原因是网页本身的内容以及商品评论的内容中多多少少都会存在与评论无关的信息,如广告等。正是由于存在着上述原因,使得评论获取的难度进一步加大,如果获取的评论内容不符合分析的要求,那么情感倾向性的分析结果也将会有很大的误差[9]。为此,需要对获取的评论内容进行一些必要的处理。下面就列出了一些网页内容处理的方法:
(1)在很多电子商务网站中,一些买家并不会对所买的产品进行评论或者忘记评论,网站系统会在一定的时间后自动默认生成好评,另外,也会有一些买家同时也是卖家,甚至还有一些是专门的广告党,专门在评论内容中为自己的商品做广告等等。对于上述这些情况,可以整理出网站系统中默认的好评词和一些明显的广告词,将其过滤掉。
(2)在同一个卖家购买了多个同样商品的买家,很有可能将一样的评论内容复制粘贴到每一件商品的评论栏中,造成评论的重复。针对重复两次或者两次以上的评价语句,处理方法是只保留其中一条评论内容。
(3)经过上述方法处理后,如果评论内容中仍然包含有繁体字、错别字等,可将它们都过滤掉。3.3中文分词
中文分词[10](Chinese Word Segmentation)是指将一个个汉字序列切分成一个一个单独的词的过程。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。本文采用基于PAT树和统计相结合的分词方法。
PAT树作为一种特殊形式的树结构[11],它的查找结构是运用半无限长字串(semi-infinite string,简称sistring)来作为字符串的。其主要的节点包括:内部节点,用来存储不同的bit位在整个sistring字节序列中的位置(根节点,是所有sistring二进制码中第一个不同的位的位置);外部节点(叶子节点),其作用是记录sistring的首字符在完整sistring中的初始位置(字符索引)和sistring出现的频次;左指针,若是待存储的sistring在内部节点所存储的bit位置上的数据是0,那么将这个sistring存储到该节点的左子树中去;右指针,若数据是1,那么就存储到该节点的右子树中去。
这种方法的思路是首先进行文本分割,即对获取的文本进行切割,切割标志为中英文标点符号、空格,并用“/”代替,形成以“/”分割的所有短语的集合,删除所有非汉语字符,只保留中文字符。然后进行正序数组和逆序数组的准备,将切割后的短语转换成半无穷大串数组,并将这些数组去重、合并,统计出各sistring的频次,为构建PAT树做准备。最后进行中文PAT树的构建、检索和遍历,从而完成分词过程。
虽然基于PAT树和统计相结合的分词方法有着很高的效率,但该方法也是有一定的局限性,比如说可能会分割出一些共现频度很高,但却并不是词的常用字组,例如“之一”、“这一”、“有的”等等之类的词,并且对常用词的识别精度较差,时空开销会比较大。
4 网购评语倾向性判断
4.1 基于HowNet的情感词典扩展
HowNet(中文名称为知网)是一个以汉语和英语的词语所代表的概念为描述对象,同时以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库[12]。它提出一切的概念都是由形态不一的义原组合而成的,而且能够根据一个有限的义原集体来构建一个无限的概念集体,同时描绘出概念与概念之间的联系,对于属性之间的关系也可被描绘出来。刘群和李素建提出一种运算义原间相似程度的方法,该方法如公式(1)所示,义原树中的距离由dist(p1,p2)来代表,而α则表示一个正的可变参数[13]。
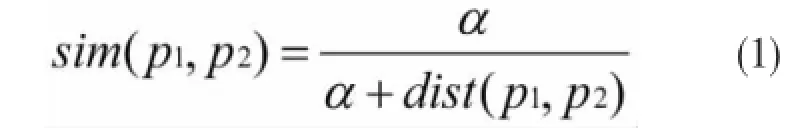
在判断某个词的情感倾向方面刘群和李素建的方法还不是很完善。例如“美丽”与“贼眉鼠眼”是一对相对立的词,运用该方法得出的相似度为0.81,而“美丽”与“优雅”是一对相近的词,但是它们的相似度却为0.78,比0.81还要低。江敏、肖诗斌、王弘蔚等[14]的词汇相似度的运算方法给出了全新的见解,方法见公式(2)。

同时,有以下规定:①若是一对义原间存在着对义或者反义,那么其相似度为-l;②若是一对义原的路径中存在着对义或者反义,那么其相似度就为-1*sim(p1,p2)。sim(p1,p2)所表示的是把距离最近的一对存在着对义或者反义的义原节点当作是同一个节点来看待,然后再配合运用前面所提到的公式(1)。
任何一个词的语义倾向性度量值,都可运用前面所提到的方法,依据这个词和两组基准词的语义关系的密切度运算出来。对于这两组基准词中的每一个词来说,它们皆有其显著的倾向性,其中一组代表正面情感,另一组代表负面情感。倾向性度量值可由公式(3)计算得出,在公式中正面基准词组由seedl代表,负面基准词组由seed2代表,它们的个数分别是n和m:

若结果是正数,那么说明该词是褒义的,若结果是负数,那么说明该词是贬义的。本文采用HowNet特有的关于情感研究方面的专用词典,并依据公式(3)求出其中各个词的情感强度以及情感倾向,同时通过对已有的情感词典进行扩展,得到了一个更完整的情感词典HWSD。HWSD一共收纳了8 337个中文词汇,有褒义词4 093个,贬义词4 244个。
4.2 修饰词词典的构建
网民在评论的时候,会用大量的副词来对情感词汇进行修饰,因此为了更好地计算出评论的倾向性,需要建立一个修饰词词典。文献[15]给出了副词的各种类型以及它们所主要囊括的词汇,本文抽取当中带有不同语气强弱的副词以及否定副词来建立修饰词词典。运用一个二元组Item〈Adv,Modality〉来代表,当中Adv代表的是词汇的名称,Modality代表的是这个词的语气强度,它的取值范围在-1或(0,2)之间。否定副词的语气强度为-1,其它副词的语气强度在(0,2)之间,越是靠近0则代表这个副词所表示的强度就越弱,越是接近2则代表这个副词所表示的强度就越强烈。
4.3 网购评语倾向性判断
修饰词词典构建完成后,就可以进行最后的评语倾向性判断了,具体的网购评语倾向性判断过程如图1所示:

图1 淘宝评语倾向性判断过程
由于网购用户的评语大多都很简短,因此对于已经分词好的评语,依据搭建完成的情感词典以及修饰词词典,就可以快速、精准的运算出评语的倾向性了。本文通过逗号、句号等标点符号将各条评语划分成n个句子,用Sen1、Sen2、…、Senn来表示。同时抽取出每个句子中的情感词,若是情感词Wi之前有1~2个副词对其进行修饰,并且这1~2个副词Advi1、Advi2位于修饰表中,则该情感词所呈现出来的倾向性以及强度,可由公式(4)求得。
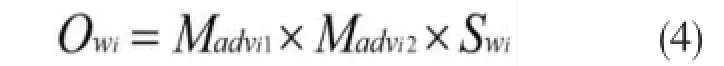
如果句子Senm中包含有k个情感词,并记作W1、W2、…、Wk,那么该句子Senm所呈现出来的倾向性以及强度,可由公式(5)求得。
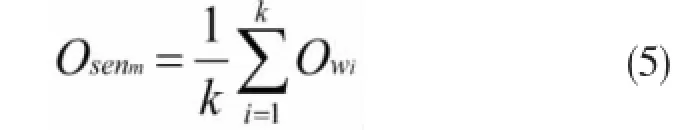
则包含有n个句子的评语Ci最终所呈现出来的倾向性,可由公式(6)求得。

我们规定,如果Oci的得分在[-0.1,0.1]之间,那么该评论记为中性评论,如果大于0.1,则记为正向评论,如果小于-0.1,就为负向评论。
有了每条评语的得分之后,就可以根据这些得分以及评语的个数来得出该商品的综合评分。计算过程为分别统计正向评论、负向评论和中性评论的个数,求出正向评论、负向评论和中性评论的得分总数,得到商品的综合得分,平均得分也可以因此得到。最后,通过统计正向评论、负向评论和中性评论所占的百分比,来了解顾客对该商品的喜爱程度。我们规定,正向评论的百分比在85%以上,表明用户喜爱此种商品,正向评论的百分比在75%~85%之间,则说明用户比较喜欢该种商品,正向评论的百分比在65%~75%之间,则说明用户对该种商品的情感一般,如果正向评论的百分比低于65%,那么就表示该商品不受用户喜爱。
在淘宝网站中,按销售数量排名,分别是女装(女士精品)、化妆品(护肤品)、珠宝(首饰、手表)和日用品,因此为了使样本具有代表性,本文选择了一家卖女装的商家进行研究,从中选择某件商品中的1 382条评论进行情感倾向性分析。通过最终计算可以得到:
该商品的综合评分为344.2分,平均得分为0.249分。其中正向评论个数为1 220个,所占比例为88.28%,中性评论个数为136个,所占比例为9.84%,负向评论个数为26个,所占比例为1.88%。那么,淘宝网就可以将这些数据展示在评论网页中供消费者浏览,消费者可以从这些数据中了解到,该商品是很受用户喜爱的,可以放心购买;同时,其他商家也可以照此与自家的产品进行比较,明确自家商品不足的地方,可想法改进。
5 结论
目前,情感分析领域的研究主要集中在主观性内容识别、褒贬情感分类以及在线评论的经济价值挖掘等几个方面[16],大部分研究借鉴文本挖掘、信息检索、机器学习、自然语言处理、统计学等方面的技术和方法,也提出了一些针对评论情感分析的特定方法。孙先和段卓将基于词典的情感分析方法引入到微博的情感分析中去,他们综合考虑了程度、否定副词等上下文语境对情感词的影响,从实验结果来看,其方法比较有效[17]。但该方法还比较简单直观,准确率并不是很高。因此,为了提高准确率,本文运用HowNet情感词典并进行相关扩展,运用基于PAT树和统计相结合的分词方法,来更好地完成评论情感分析工作。
本文通过对商品评论的分析来研究淘宝网用户的情感倾向性,整合用户购买某一商品后的感受,同时统计不同用户的评论信息,综合展示商品的受欢迎程度。淘宝等购物网站就可以把商品评论的综合数据呈现出来给消费者以及卖家浏览,从这些数据中消费者可以了解到其他用户对于某种商品的情感倾向性分布,以此来优化自己的购买决策;同时生产商和销售商一方面可以了解到消费者对其商品和服务的反馈信息,另一方面还可以知道消费者对自己和对竞争对手的评价,从而来改进自身的产品并改善服务,从中赢得竞争优势。
目前,电子商务管理的热点问题和难点问题众多,网购评论情感倾向性分析就是其中之一,也正因为如此,为了电子商务的良好发展,在情感倾向性分析方面仍需要投入更多的时间和精力。在本文研究的基础上,还可以进行进一步探索的方向大致包括以下几点:
(1)本文所涉及的领域比较少,基于HowNet的情感词典较单一,可以通过从多种情感词典出发来分析评论的倾向性,这样汇总得到的结果会更为理想。
(2)数据库中保存了评论的IP地址和评论时间,可以进一步分析淘宝消费者的地域和评论时间与该话题之间的联系,也许能挖掘到更为有趣的信息。
(3)增强对包括附和、讽刺、比喻、正话反说等等这些更加复杂、更加自由的网购评论的处理能力。同时,与时俱进的搜集更多不同的习惯用语以及句式的不同搭配等。
总体来说,网购评论的情感倾向性研究还不是很完善,还有很长的路要走,仍需相关技术研究人员投入更多的时间与精力。
[1]Global Trust in Advertising and Brand Messages[EB/OL].[2015-06-30].http://www.nielsen.com/us/en/insights/reports/ 2012/global-trust-in-advertising-and-brand-messages.html.
[2]朱嫣岚,闵锦,周雅倩,等.基于HowNet的词汇语义倾向计算[J].中文信息学报,2005,20(1):14-20.
[3]曾淑琴,吴扬扬.基于HowNet的词语相关度计算模型[J].微型机与应用,2012,31(8):77-80.
[4]柳位平,朱艳辉,栗春亮,等.中文基础情感词词典构建方法研究[J].计算机应用,2009,29(10):2875-2877.
[5]Pang B,Lee L.A sentimental education:Sentiment analysis using subjectivitysummarization based on minimum cuts[C]//Proceedings of the 42nd annual meeting on Association for Computational Linguistics.Association for Computational Linguistics,2004:271-278.
[6]杨文峰,李星.基于PAT TREE统计语言模型与关键词自动提取[J].计算机工程与应用,2001(15):17-20.
[7]李慧,沈洁,张舒,等.基于页面分块与信息熵的评论发现及抽取[J].计算机应用研究,2007,24(2):269-271,291.
[8]刘伟,严华梁,肖建国,等.一种Web评论自动抽取方法[J].软件学报,2010,21(12):3220-3236.
[9]Hu M,Liu B.Mining and summarizing customer reviews[C]//Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining.ACM,2004:168-171.
[10]李淑英.中文分词技术[J].科技信息,2007(36):65-66.
[11]柳佳刚,曾利军.基于PAT-tree的中文搜索引擎结果聚类算法[J].情报杂志,2009,28(12):32-34.
[12]HowNet knowledge database[EB/OL].[2015-06-30].http://www.keenage.com/.
[13]刘群,李素建.基于《知网》的词汇语义相似度的计算[OL].
[2015-06-30].http://www.docin.com/p-23739023.html.
[14]江敏,肖诗斌,王弘蔚,等.一种改进的基于《知网》的词语语义相似度计算[J].中文信息学报,2008,22(5):84-89.
[15]现代汉语副词表[OL].[2015-06-30].http://wenku.baidu. com/link?url=BoCWgoG04G_iOO0tDvaZZS85de5VEdgRRNHOXtQ9w6GjurS0B1DShCCJ-zQvZBoISVuRFBmbgpWqoj-B06c8KU9usI6SyY8QMb7q8oSjy7wq.
[16]张紫琼,叶强,李一军.互联网商品评论情感分析研究综述[J].管理科学学报,2010,13(6):84-96.
[17]孙先,段卓.基于情感词语义的中文微博情感挖掘[J].信息与电脑,2013(3):84-85.
(责任编校骆雪松)
Sentiment Analysis of the Comments on Online Shopping Based on HowNet and PAT Tree
Li Yongzhong,Hu Siqi
School of Economics and Management,Fuzhou University,Fuzhou 350108,China
By summarizing and analyzing the related research,extending the HowNet sentiment dictionary and adopting the combined approaches of PAT tree and statistics the present article makes an analysis of the comments obtained from the website of Taobao.The results showed that it is effective to employ the sentiment analysis method based on HowNet and PAT tree to analyze the sentimental tendency of comments on online shopping.In addition,taking a business selling women’s clothes as an example,an experimental study was conducted.Several directions of further exploring the sentimental tendency were also pointed out at the end of the paper.
HowNet sentiment dictionary;PAT tree;comment on online shopping;sentiment analysis
G353.12
李永忠,男,1963年生,副教授,研究方向为电子政务、信息产业合作,发表论文50余篇;胡思琪,女,1993年生,2013级信息管理与信息系统专业硕士研究生,发表论文1篇。
猜你喜欢
保健医苑(2022年5期)2022-06-10 07:47:04
有色金属(矿山部分)(2021年4期)2021-08-30 06:10:42
作文大王·低年级(2020年2期)2020-03-13 08:10:04
数学大王·低年级(2020年2期)2020-03-13 08:09:51
四川文学(2020年11期)2020-02-06 01:54:52
商周刊(2018年23期)2018-11-26 01:22:22
新闻研究导刊(2015年17期)2015-12-25 12:36:42
语言与翻译(2015年4期)2015-07-18 11:07:43
散文百家(2014年11期)2014-08-21 07:16:36
中央民族大学学报(自然科学版)(2014年3期)2014-06-09 08:54:32
