
基于WordNet的语义相似度算法改进研究
2016-05-14 15:48沈国祥
软件导刊 2016年5期
沈国祥


摘要:本体匹配解决了本体异构问题,作为本体匹配的关键技术,相似度算法决定了匹配的精度和效率。WordNet中概念节点的语义距离常作为相似度算法的依据。设计了一种新的语义距离计算方法及相似度算法,并以此搭建一个本体匹配框架进行了验证。
关键词:本体匹配;WordNet;语义距离;语义相似度
DOIDOI:10.11907/rjdk.161033
中图分类号:TP312
文献标识码:A 文章编号:1672-7800(2016)005-0034-04
0 引言
随着Internet的发展,语义Web技术解决了海量信息与高效利用之间的突出矛盾。语义Web通过在资源信息中加入语义信息,使信息的内容与表示分离处理,为描述的信息赋予了良好的语义,实现了计算机对海量信息处理的自动化和智能化,极大提高了信息使用效率。
作为语义Web中的关键技术,本体得到了越来越广泛的应用,本体已经成为语义Web中知识表示的标准。为了实现语义信息共享,各个领域纷纷定义了相应的本体标准,但本体构造一直没有一个统一的规范和标准,从而导致本体存在各种异构问题。为了更有效地使用和重用本体来完成信息交换与集成任务,就必须找出不同本体之间的映射关系,即本体匹配技术。
根据文献[1]对本体匹配流程的描述,可以将本体匹配总结为5个步骤:①本体特征(概念、关系、属性等)提取;②选择本体匹配的实体对;③语义相似度计算;④人工干预;⑤匹配输出,其中相似度计算是整个流程的核心技术,也是本文研究的主要内容。对于相似度计算可以从自然语言、字符串、本体结构信息、本体推理等多角度进行。
本体匹配技术研究及本体匹配系统构建取得了一批成果。目前,常见的本体匹配有基于语言学特征、基于结构和基于实例等多种方法。
1 WordNet简介
WordNet[2]是在美国普林斯顿大学G. Miller教授的指导下,由心理学家、语言学家和计算机工程师联合设计的一种基于认知语言学的英语词典,是基于语言特征的本体匹配方法中常用的外部资源。
WordNet使用同义词集合代表概念,词汇关系在词语之间体现,语义关系在概念之间体现。虽然WordNet中存在着多种语义关系,如同义关系、反义关系、整体与部
分关系等,但is-a关系是WordNet中最重要的一种关系,所有的名词概念和动词概念都可以通过这种关系来联接,如图1所示。本文所研究的语义相似度计算都是基于这种关系的。
3 改进的相似度算法
总结以上研究成果,每种方法都对后面的研究作出了一定的贡献,同时也存在一些不足。因为相似度计算本身就是一个主观性较强的工作,理解上的相异导致算法的不同也就不足为奇了。
针对现有方法的不足,在分析前人成果的基础上,加上笔者的理解,提出了一种基于WordNet的新的相似度算法。该相似度算法改进了现有算法的某些不足,降低了计算复杂度,并且把相似度的值限制在[0,1]范围之内。在详细描述本文算法之前,先介绍本文中改进算法所依据的概念、假设等。正如语义相似度具有主观性一样,这些概念和假设具有一定的主观性而不一定具有普遍性。
3.1 相关假设假设1:语义距离和语义相似度具有反比性,即语义距离越大,相似度越小;语义距离越小,相似度越大。
假设2:假如两个概念的语义距离为0,则相似度为1。
假设3:假设某一概念是父概念的唯一分类,则两个概念间的语义距离为0。
假设4:WordNet语义树中相同词性的两个概念,相似度不为0;两个词性不同的概念,相似度为0。
假设5:两个概念的语义相似度不仅与语义距离相关,而且与它们所处的深度相关。
3.2 相关概念
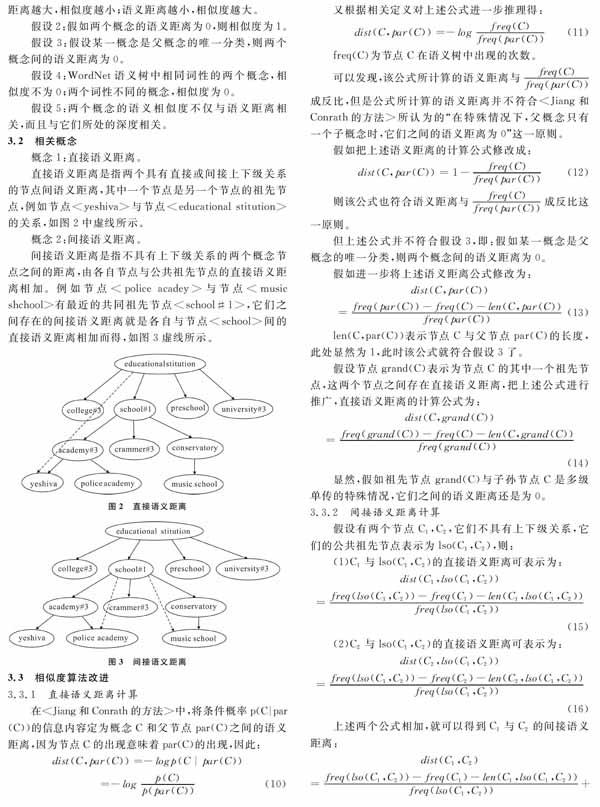
概念1:直接语义距离。直接语义距离是指两个具有直接或间接上下级关系的节点间语义距离,其中一个节点是另一个节点的祖先节点,例如节点
概念2:间接语义距离。
间接语义距离是指不具有上下级关系的两个概念节点之间的距离,由各自节点与公共祖先节点的直接语义距离相加。例如节点
可以发现,改进的相似算法与其它两种算法在相似度趋势上基本保持一致,验证了改进后的算法具有一定的合理性和科学性。从整体结果来看,改进后的算法在查全率和查准率上比其它两种方法均有所提高,证明改进后的算法具有一定实际意义。
4 结语
作为本体匹配的关键技术,相似度计算直接对本体匹配的结果有着决定性影响。不可否认的是,相似度是一个主观性较强的概念,因此在相似度计算中所用语义距离及其它相关的概念和认识也具有一定的主观性。
本文通过对前人基于WordNet的相似度算法研究,形成了一种改进算法,并以此建立一个本体匹配的框架进行验证。仅基于WordNet的本体匹配算法在匹配效果上不一定令人满意。因此,要将该算法应用于实际工作中,还需要与其它类型的算法综合考虑,以提高匹配精度和广度,这正是需要进一步研究的工作。
参考文献:
[1]M EHRIG,S STAAB.QOM:Quick ontology mapping[C]. In Proeeedings of the Intemational Semantic Web Conference(ISWC),2004:683-697.
[2]梁健,吴丹. 种子概念方法及其在基于文本的本体学习中的应用[J]. 图书情报工作, 2006,50(9):18-21.
[3]WU Z ,PALMER M. Verb Semantics and Lexical Selection[C]. In Proeeedings of the 32nd Annual Meeting of the Association for Computational Linguistics,Las Cruces,New Mexico,1994:133-138.
[4]PHILIP RESNIK.Using information content to evaluate semantic similarity[C].In Proceedings of the 14th Intemational Joint Conference on Artificial Intelligence,1995:102-119.
[5]JIANG J,CONRATH D.Semantic similarity based on corpus statistics and lexical taxonomy[C].In Proeeedings of Intemational Conferenee on Researeh in Computational Linguistics,Taiwan,1997:19-33.
[6]LIN, DEKANG.An information-theoretic definition of similarity[C].In Proeeedings of the 15th International Conference on Machine Leaming,Madison,WI,1998:296-304.
[7]KALYANPUR A,PARSIA B,HORRIDGE M,et al.Finding all justications of OWL DL entailments[C].In Proceedings of ISWC,2007:267-280.
(责任编辑:杜能钢)
