
基于ARIMA模型对我国服务贸易进出口额的趋势分析
2016-05-14 04:40蒋志增
智富时代 2016年6期
蒋志增
【摘 要】本文对我国1982-2012年服务贸易进出口额进行分析,运用Box-Jenkins方法建立ARIMA(1,2,2)模型,检验结果表明该模型有较好的预测结果,可以把握短期我国服务贸易进出口趋势,并为政府促进我国服务贸易出口制定政策提供参考。
【关键词】ARIMA模型;服务贸易进出口额;预测
2013年我国的服务贸易进出口总额5396.4亿美元,全球排名位居第三,但服务贸易逆差继续扩大,服务贸易仅占我国外贸出口总额11.5%,以制造业为代表的货物贸易出口遭受挫折,对外开放模式亟待转型。同时,服务贸易迎来发展契机,服务贸易增长一定程度上弥补了货物出口下滑缺口。服务贸易正成为中国摆脱当前外贸困境的突破口。
一、ARIMA模型建模思想及步骤
ARIMA模型是Box-Jenkins提出的时间序列预测方法,基本思想是将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模型来近似描述这个序列。这个模型一旦被识别,就可以根据时间序列的过去值及现在值来预测未来值。
ARIMA模型建模分为四个步骤:(1)平稳性检验;(2)统计量描述;(3)参数估计;(4)诊断分析。
二、ARIMA模型的建立及预测
本文采用的样本数据均为年度数据,样本期为1982-2012年,关于中国服务贸易出口额的年度数据来源于WTO国际贸易统计数据库、中国商务部和国家外汇管理局网站。
(一)服务贸易出口额序列平稳化检验
用EXt代表中国服务贸易出口额年度数据序列,对时间序列数据进行观察发现,EXt序列存在很明显的增长趋势,只有在1997年亚洲金融危机和2008年次贷危机时出现过下降,这表明时间序列EXt存在异方差,需要对其进行对数转换以消除异方差,然后进行差分。
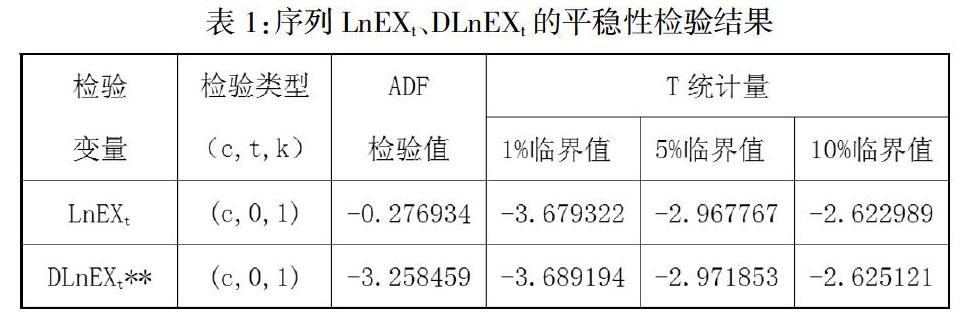
EXt数据序列具有长期上升趋势,非水平平稳,本文对我国服务贸易出口额的序列取对数形式记为LnEXt,我们对序列LnEXt进行一阶差分,采用ADF(Augmented Dickey -Fuller)方法进行序列单位根检验。检验结果显示(见表1),LnEXt序列在5%显著性水平下是非平稳时间序列,经过一阶差分之后,DLnEXt序列在5%显著性水平下是平稳时间序列。
注:**表示在5%的水平上显著;D代表一阶差分;检验类型中的c表示带有常数项,t表示带有趋势项,k表示采用的滞后阶数,根据AIC、SC最优信息准则确定。
(二)ARIMA模型阶数p与q的确定
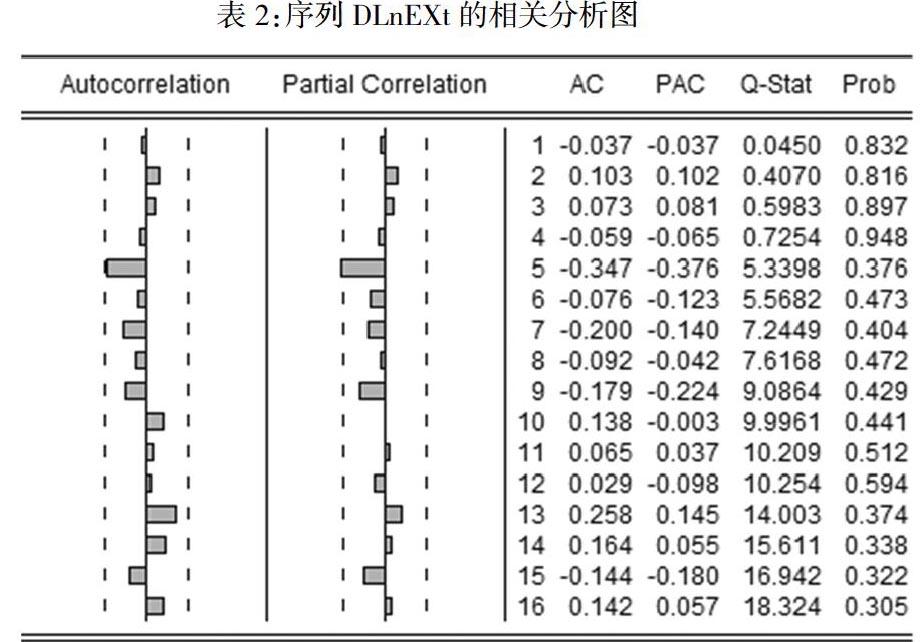
经过一阶差分后,DLnEXt变为平稳时间序列,故d=1,所以我们选取ARIMA(p,1,q)模型来对两序列进行建模。接下来,确定自回归阶数和移动平均阶数,可以根据自相关函数和偏相关函数的截尾性质和拖尾性质来判断。判断规则如下:对于AR(p)模型,其偏自相关函数在p阶后为零,即具有截尾性质,而自相关函数不能在某一步后立即为零,即具有拖尾性质;对于MA(q)模型,其自相关函数在q阶后为零(截尾),而偏相关函数不能在某一步后为零(拖尾)。根据上述规则,我们利用下图DLnEXt的相关分析图确定p和q值,可以得出,DLnEXt序列的自相关函数和偏相关函数在滞后5期处显著不为零,且有截尾特征,可初步判定p=q=5。
对于最合适的模型,经过综合比较我们选择ARIMA(5,1,4)模型。
(三)模型估计
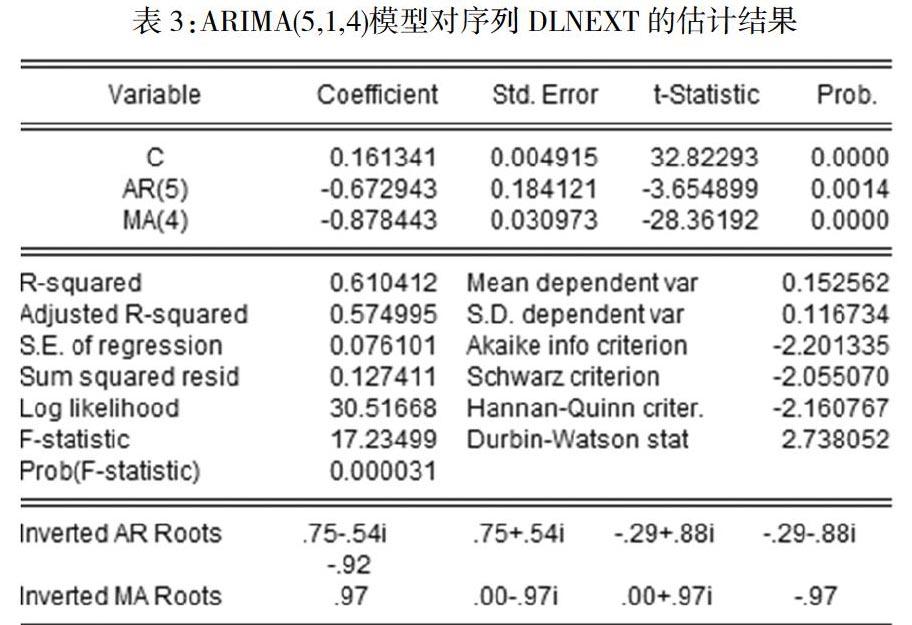
对序列DLnEXt采用ARIMA(5,1,4)模型,添加一个截距项,两个滞后变量进行拟合分析。利用NLS估计建立估计方程,如表1所示:
得到估计方程:
DLnEXt=0.161341-0.672943 DLnEXt-5 -0.878443εt-4+εt
(32.82293) (-3.654899) (-28.36192)
R2= 0.610412 F= 17.23499 DW= 2.738052 AIC= -2.201335
可得:Ext=exp(LnEXt-1+0.161341-0.672943 DLnEXt-5 -0.878443 DLnEXt-4+Ut)
由表1可知,各参数在5%的显著水平上均通过t检验,Inverted AR Roots(自回归特征方程根倒数)均在单位圆内,说明模型是稳定的。
(四)模型评价及预测
表4是2011-2013年模型预测值与真实值的比较,预测数据经公式EXt=EXP(LNEXt)转换为非对数形式。由表4可知,此模型的预测误差相当小,除了2013年预测误差高于2%外,其余均在2%的范围以内,说明利用该模型进行预测效果很好。
从表3可看出,预测值与实际值差异不大,这说明ARIMA 模型对中国服务贸易出口额预测效果较好。预测相对差异的绝对值为2%-26%之间,2011-2012 年的平均预测误差仅为1.5%。因此,ARIMA(5,1,4)模型可分别用于今后几年中国服务贸易出口的预测。
三、对中国服务贸易进口额时间序列建立ARIMA模型
(一)数据处理
首先对服务贸易进口额序列对数化处理,并进行单位根检验,为非平稳时间序列模型,我们对其进行一阶差分,差分结果可以通过显著性水平5%的单位根检验。
(二)设定模型
观察一阶差分后的中国服务贸易进口额时间序列自相关和偏自相关图,经过多次比较研究,我们选取ARIMA(6,1,6)模型对其进行拟合和预测,拟合的结果如表5所示:
建立方程如下:
DLnIMt=0.175668-0.307951 DLnIMt-6-0.946495t-6+εt
(6.955882) (-2.891162) (27.82016)
R2=0.722039 F= 27.27505 DW= 2.338741 AIC= -1.597461
可得:IMt=exp(LnIMt-1 +0.175668-0.307951 DLnIMt-6-0.946495εt-6+εt)
方程各参数均通过显著性水平为5%的t检验,Inverted AR Roots均在单位圆内,说明模型稳定。对模型进行残差检验,由P值可知残差也通过了白噪声检验,残差中已经没有可以提取的有用的信息。
(三)预测
从表6可看出,预测值与实际值差异不大,这说明ARIMA模型对中国服务贸易进口额预测效果较好。预测相对差异的绝对值为1%-20%之间,2011和2013两年的平均预测误差仅为4%。因此,ARIMA(6,1,6)模型可分别用于今后几年中国服务贸易进口额的预测。
四、结论
(一)中国服务贸易出口额呈递增趋势。
中国服务贸易出口序列是受多种制约因子影响的非平稳时间序列,是一组依赖于时间变化的随机变量,可用ARIMA模型予以近似描述。
(二)中国服务贸易进口额呈递增趋势
2011-2013年中国服务贸易进口预测相对差异为1%-20%,平均预测误差仅为4%。这表明所建立的具体模型,即ARIMA(6,1,6)模型,适合中国服务贸易进口数据的特点,可利用其对中国未来几年服务贸易进口额进行预测分析。
(三)中国服务贸易逆差额呈扩大趋势
2014-2015年贸易逆差仍然存在,逆差缺口呈递增趋势,逆差缺口分别为1012 亿美元、1627亿美元。准确的服务贸易进出口预测可为国家科学制定服务贸易政策和合理规划服务贸易进出口提供重要的理论依据。
【参考文献】
[1]FAN J,YAN Q. Nonlinear Time Series: Nonparametric and Parametric Methods[M].Beijing:Science Press,2006:10-13.
[2]BOX G,JENKINS G. Time Series Analysis,Forecasting and Control[M]. San Francisco: Holden Day,1970:1-11.
[3]DICKEY D,FULLER W. Distribution of the estimators for autoregressive time series with a unit root[J].Journal of the American Statistical Association,1979,(74):427-431.
[4]AKAIKE H,Cononicial correlation analysis of time series and the use of an information criterion,in systems identification:Advances and case studies[M]. New York:Academic Press,1976:27-96.
[5]沈汉溪,林坚.基于ARIMA 模型的中国外贸进出口预测:2006-2010[J].国际贸易问题,2007,(6).
[6]张晓峒.Eviews 使用指南与案例[M].北京:机械工业出版社,2006.
[7]国家商务部网站,2013年度《中国服务贸易统计》数据表组,
http://tradeinservices.mofcom.gov.cn/c/2014-01-08/233308.shtml
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
疯狂英语·初中天地(2018年6期)2018-11-24
现代商贸工业(2016年22期)2016-12-27
电子技术与软件工程(2016年20期)2016-12-21
时代金融(2016年29期)2016-12-05
商(2016年27期)2016-10-17
商(2016年19期)2016-06-27
