
Web垂直搜索引擎实现过程的研究
2016-05-14 00:24张弘弦田玉玲
现代电子技术 2016年8期
关键词:爬虫
张弘弦 田玉玲

摘 要: Web垂直搜索引擎是一个复杂的信息系统,目前大多数研究都集中在解决搜索引擎中出现的某一个方面的问题,仍缺乏对Web垂直搜索引擎完整实现过程的相关研究。针对这个问题,提出一种三层架构的Web垂直搜索引擎的实现过程,整个过程包含数据准备、查询处理和界面交互。使用Java语言和相关的开源工具,对实现过程描述的具体任务进行实际操作,实现了一个查询手机信息的Web垂直搜索引擎。该三层架构和实现过程有效地为构建面向主题的完整Web垂直搜索引擎提供了理论依据和实践指导。
关键词: Web搜索; 搜索引擎实现; 垂直搜索架构; 爬虫
中图分类号: TN911?34 文献标识码: A 文章编号: 1004?373X(2016)08?0055?05
Research on implementation process of Web vertical search engine
ZHANG Hongxian, TIAN Yuling
(School of Computer Science and Technology, Taiyuan University of Technology, Taiyuan 034000, China)
Abstract: The Web search engine is a complex information system. However, most researches are concentrated on one detailed problem appearing in a aspect of the search engine, but they lack of the correlational research on the complete implementation process of Web vertical search engines. Aiming at this problem, the implementation process of a Web vertical search engine with a three?layer architecture is proposed, in which data preparation, query processing and interface interaction are contained. An actual operation of a certain task describing the implementation process was performed with Java platform and relative open?source tools. And by this operation, the Web vertical search engine that could query mobile information was realized. The three?layer architecture and implementation process provide a theoretical basis and practical guidance for building a complete subject?oriented Web vertical search engine.
Keywords: Web search; search engine implementation; architecture of vertical search engine; crawler
0 引 言
从2000年开始,Web垂直搜索引擎开始赢得用户的亲睐[1?2]。视频、音乐、图片、软件、贴吧、地图分门别类展开搜索,专业性更强,主题相关性更高。然而Web垂直搜索引擎的应用主题并不局限,拥有非常广阔的发展空间,例如面对电子商务的商品搜索,数码产品信息搜索以及近年开始出现的微博搜索。垂直搜索的出现主要有两个方面的原因:一是通用搜索引擎索引Web的全部内容变得越来越难,而垂直搜索引擎索引数据量较小且专业,投入成本也相对较低;二是垂直搜索引擎提供的搜索质量较高,因为它可以搜索到通用搜索引擎不能搜寻到的页面,而且在可搜索页面上提供更强有力的搜索功能。垂直搜索引擎与通用搜索引擎的最大区别在于对网页信息进行结构化信息抽取,即将网页的非结构化数据提取成特定的结构化数据。构建一个垂直搜索引擎主要有两种方法:一种方法是通过爬虫爬取某种主题网页而构建专业索引;另一种方法是为用户提供专业化搜索的接口。
Web搜索引擎是种复杂、多组件信息检索系统的具体应用[3],也因其应用在拥有超大规模数据的互联网中,使构建Web搜索引擎变得比较困难。已有众多的研究者参与到Web搜索引擎的研究中,Brin和Page发表论文首次公开大规模Web搜索引擎Google的设计原型[4],提出Web搜索引擎的基本组件包括爬虫(Crawler)、索引组件、搜索组件、排序系统以及反馈组件。高效Web垂直搜索的关键之一在于爬虫能否精确爬取主题相关的Web文档,Soumen等人提出聚焦爬虫[5](Focused Crawler),利用一种能够评估网页是否与主题相关的分类器选择性地爬取与预定义主题相关的页面,实现了以目标为导向的爬取。文献[6]开发了一种潜语义索引分类器,将链接分析和文本内容结合起来,目的是抓取指定主题域的Web文档。文献[7]设计并实现了一种基于网格架构的大型Web搜索引擎,讨论实现流程和细节,对Web垂直搜索引擎的研究提供了宝贵的经验。信息检索领域的研究成果对Web搜索引擎有着较高的参照价值,特别是检索模型的研究更加重要,Web搜索引擎的排序组件好坏很大程度上决定了用户体验。信息检索模型得到了飞速发展,传统的检索模型包括布尔模型、向量空间模型、概率模型、语言模型。现代检索模型的建立大多通过排序学习方法得到,即利用机器学习技术在数据集上自动创建排序模型[8]。这些研究成果很多通过开源软件实现,这些工具不仅为开发软件提供先进的技术支持,而且大大缩短了开发周期。
本文提出了一种Web垂直搜索引擎的实现过程,以该过程为基础开发了一个查询与手机相关信息的Web垂直搜索引擎,并且对实现原理和细节进行了详细的阐述。此垂直搜索引擎可以为搜索手机相关信息的用户提供直观的、快捷的、有效的手机信息搜索服务,验证了这种实现过程的有效性和完整性。
1 Web垂直搜索引擎的实现过程
Web垂直搜索引擎与通用搜索引擎原理类似,都需要从互联网上下载网页、建立索引,响应用户查询。但是垂直搜索引擎可以返回结构化的数据,这些数据经过人工分析与整理再存入数据库中。本文将Web垂直搜索引擎的实现过程分为3层,分别为:数据准备层、提供查询服务层、前台交互层。这3层可互相独立开发,最终整合到一起形成一套完整的Web垂直搜索引擎。图1为一种Web垂直垂直搜索引擎实现过程。
1.1 数据准备层
数据准备层的目的是准备用于检索的数据,这些数据最终存放在关系数据库中并建立倒排索引。Web垂直搜索引擎的目的是为用户提供更专业、主题性更强的搜索服务,这种服务与大量主题相关的数据为基础,数据处理分为两个阶段,第一个阶段为采集原始数据,原始数据来自互联网某些主题性较强的、数据来源可靠的网站。原始数据大多是未经处理的无结构网页,这些原始网页无法支持搜索服务并返回给用户查看。第二阶段为数据分析与处理,将原始无结构网页中的数据转换为结构化数据,并将这些结构化数据存储在关系数据库中,这些存储在数据库中数据最终以更加直接的形式展示给用户。然而,关系数据库中模糊查询难以应对海量数据查询,所以需要建立一种面向词汇的数据结构,即倒排索引,以实现毫秒级的查询性能。
数据准备层主要包含以下5个过程:
(1) 选择主题信息来源网站和网页
认真选择主题信息来源网站以确保原始数据的可靠性,通常需要遵循以下4个原则:来源网站没有屏蔽爬虫对网页的爬取;网页内容不是JavaScript动态生成的。爬虫不需要模拟浏览器解释脚本去生成网页内容,否则会严重影响爬虫效率;网站中网页URL有统一的风格。这样的URL更容易被爬虫抓取,数据更加准确;选择访问量比较大的知名网站,保证数据源可靠性。
(2) 网站和网页内容分析
分析网页的目的是定向抓取网页,在确定主题信息来源网站之后,为了能够准确获取主题数据,需要对网站的URL结构进行分析,找出实际拥有主题信息的一级URL页面,该页面通常拥有该主题下全部子主题的二级URL链接,分析出这些二级URL链接作为种子链接交给爬虫。分析方法主要以人工观测为主,以程序分析为辅。通过观察一级网页URL规律,查看网页源码,再设计抽取二级URL的计算机程序,利用程序自动抽取种子链接。
(3) 定向抓取网页
抓取网页的目的是把主题相关的网页下载到本地磁盘。爬虫是一种能够从互联网上自动抓取网页并下载到本地的程序,这种程序的输入是一些URL链接,这些链接也称之为种子,爬虫抓取种子网页的结果是将所有相关目标网页下载到本地磁盘中。
(4) 分析并抽取网页内容到本地
将网页中无规则的数据规范地保存到本地文件中,数据保存采取统一的格式,使其能够存入数据库并建立全文索引。
(5) 存入数据库并建立索引
格式化的数据不能仅存储在文本文件中,否则提取数据的开销非常大。将数据存储到数据库中,使用数据库统一管理所有数据,这样访问速度与安全性也大大增强。搜索引擎中数据准备过程中最关键的技术就是建立索引,用户查询首先访问的是索引而不是数据库,通过索引查找关键词然后返回结果文档的数据库ID,再到数据库中查找具体记录。
数据准备层的任务集中于数据采集、预处理、数据存储以及索引。这一层的活动对用户不可见,最终的产物是保存主题相关结构化数据的数据库以及这些数据上的倒排索引。
1.2 提供查询服务层
查询服务层首先将用户的查询字符串转换为可识别的对象,并进行预处理,然后发送给相应的查询方法处理,最后返回与查询字符串匹配的数据对象列表。要得到最后的数据对象列表实际经过2次查询,第一次查询倒排索引得到所有相关文档ID,这次查询的时间复杂度是O(1),因为倒排索引的词典结构多为哈希表。第二次查询将文档ID发送至数据库引擎,根据文档ID查询文档的全部信息,并且将所有查询到的文档以对象的方式返回。
1.3 前台交互层
前台交互层的重点主要是加强用户输入和输出的体验,主要包含两个方面:一是随着用户按键自动弹出提示关键字列表;二是直接展示查询结果详细信息。列表提示功能使用Ajax异步响应,当onkeyup事件发生后,向数据库服务器发送模糊查询SQL语句,将查询结果列表返回给JavaScript代码,JavaScript修改dom将提示列表展示在搜索框下面。查询结果显示数据要直接,例如查询数码产品的结果中,产品图片和参数直接显示在页面上,技术上同样是利用Ajax技术减少延时来增加用户体验。
2 Web垂直搜索引擎具体实现
下面基于以上实现过程在Java平台上构建查询手机相关信息的Web垂直搜索引擎,构建过程分别按照图1中的3层进行实现,并对关键技术和实现原理进行总结和描述。
2.1 数据准备层实现
(1) 选择主题信息来源网站和网页。根据选择主题网站的原则,最终确定选择太平洋电脑网(http://www.pconline.com.cn/)作为手机信息数据的来源网站,数据源网站可以有多个。作为一个综合性IT网站,手机频道的一级URL页面为:
http://product.pconline.com.cn/mobile/list.shtml
(2) 网站和网页内容分析。通过查看一级URL页面源码,并且分析网站URL链接规律,得出手机信息数据所在的URL地址规格,如下所示:
手机信息:http://product.pconline.com.cn/mobile/品牌/编号.html。
手机图片:http://img.pconline.com.cn/images/product/编号
确定URL规格的目的是为了确定抓取哪些URL规格的页面。获取所有手机品牌的URL链接后将这些链接作为种子,送给爬虫抓取。
(3) 定向抓取网页。爬虫的输入是待抓取URL种子链接,而爬虫抓取的结果就是将预定抓取的HTML和图片等资源下载到本地磁盘。本次开发使用开源爬虫框架Heritrix[9],它是一个开源的Java爬虫框架,它保留了各种各样的配置接口用于定制和扩展爬虫的功能,为了能够准确抓取目标资源,从官方文档中了解Heritrix本身运行机制并进行配置和定制。
(4) 分析并抽取网页内容到本地抓取到的原始网页和图片不能被直接利用,需要将网页中的有用数据抽取出来并以一定的格式保存起来,这个过程可以称之为结构化数据提取。每一个有效的HTML文件都对应一个txt文件,txt文件的内容和文件名称都有固定的结构。本次开发中将文件名规范为这样的格式:“手机名?型号?时间字符串.txt”。txt文件的内容格式如下:
原始网页URL
品牌名(如华为)
价格
属性名1:值1(如操作系统:android2.2)…
============================
产品图片编码后的文件名
结构化提取包含3个过程:一个是文件的I/O操作,此操作可以使用Java.io包实现;另一个是从HTML网页中提取数据,此操作可以使用开源解析软件实现;第三个过程是对图片进行转存处理,这个过程的目的是将手机信息和图片名称进行映射,新图片名将原图片名经过MD5编码后得到。HTML元素之间是以分层嵌套的结构组织在一起的,HTML文档的这种结构称为HTML文档树。本次开发中使用开源HTML解析库HtmlParser[10],使用这个库可以方便快速地从HTML网页中提取标签节点,文本节点和和属性节点的值。同样,在开发过程中使用该解析包需要了解其API和调用机制,这些内容来源于官方文档。
(5) 存入数据库并建立索引。磁盘中的数据文件是结构化数据,但是仍然不能直接作为查询的直接数据源,其原因在于磁盘I/O速度较慢。故而将这些文件的信息存入关系数据库中,数据库表的字段对应文件内容结构的字段,每一个文件的数据都对应表的一条记录。在查询数据库时按照产品的主关键字(如ID号)查询,查询效率较高。但是用户的查询是若干关键词,实际是字符串格式,如果直接将查询关键词放入SQL语句中,向数据库发送模糊查询匹配关键词,那么对于成千上万的记录来说效率非常低。所以,并不能直接对数据库进行查询关键词的模糊查询,而首先将查询发送给倒排索引进行查询。
倒排索引一种面向词汇的查找结构,通常使用哈希表存储,故查询效率非常高。倒排索引包括两个部分:一个部分是词典;另一个部分是倒排列表。建立索引的过程中,首先要使用分词程序对手机信息文本文件分词建立词典,每个词典项中包含一个指向对应倒排列表的指针,倒排列表由若干倒排项组成,倒排项存储的是包含该词汇的文档属性(文档ID,词频,单词在该文档中出现的位置)。
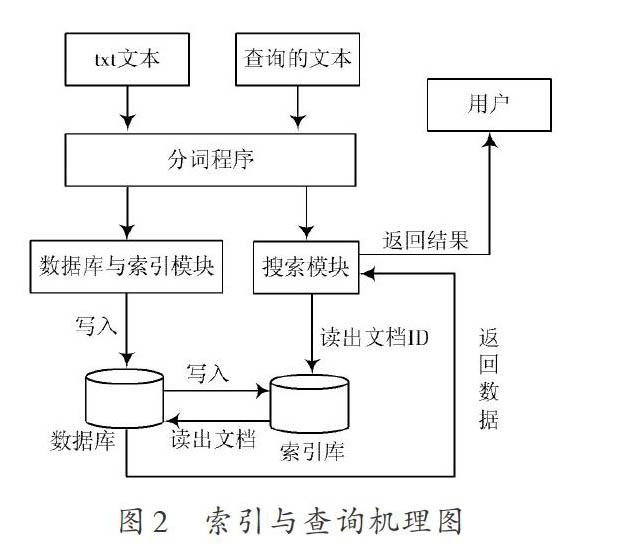
用户的查询首先由同样的分词程序切割为若干词汇,然后查询词典找出对应倒排列表,按照某种规则对倒排列表进行合并,然后将最后的文档列表ID发送给数据库查询整个文档信息,进而将数据库的返回结果展示给用户。综上,用户的查询处理过程为:“查询索引”→“获取每个相关文档的数据库ID”→“查询数据库”→“返回给用户”。这种查询机制决定了必须先将手机信息存储在数据库,然后建立索引,构建索引和执行查询的机理如图2所示。
本次开发中使用MySQL数据库存储数据,使用开源Java全文检索工具包Lucene建立索引[11],使用基于词库的字符串匹配分词模式,以正向最大匹配为分词算法,配合极易中文分词组件进行分词。基于词库的分词原理是使用正向最大匹配算法扫描待分词文本,将扫描出的词汇与词库中的词进行比对,按照一定的匹配粒度去判别该词汇是否被切分出来加入索引中,所以分词前必须在原有词库基础上增加主题相关的词汇作为词库的一部分,开发中首先解析所有txt文件名,将所有手机名称和不同的型号解析出来作为词汇单独存储在一个文本文件中,通过简单的配置即可将文件的词汇加入到极易分词的词库中,选用极易分词组件的另一个原因是它实现了Lucene标准分词解析器的接口,从而可以直接整合进Lucene[12]。对于查询字符串必须使用同样的分词程序去分词,以同样的规则切分出待查询词汇,在索引的词典中查询是否存在该词汇,如果存在则返回该词汇对应的倒排列表,否则返回空,对于多词汇查找的处理是根据逻辑运算对倒排列表进行合并后再返回。倒排列表中的文档排序模型是经典的向量空间模型,该模型以文档的TF*IDF值为向量的特征,实际参数可以在Lucene中按需设置。
图2 索引与查询机理图
2.2 提供查询服务层实现
提供查询服务作为一个中间层,在整个搜索引擎中起着非常重要的连接作用,它接收用户的查询字符串并预处理,然后在索引和数据库中查询相关文档并返回给用户。
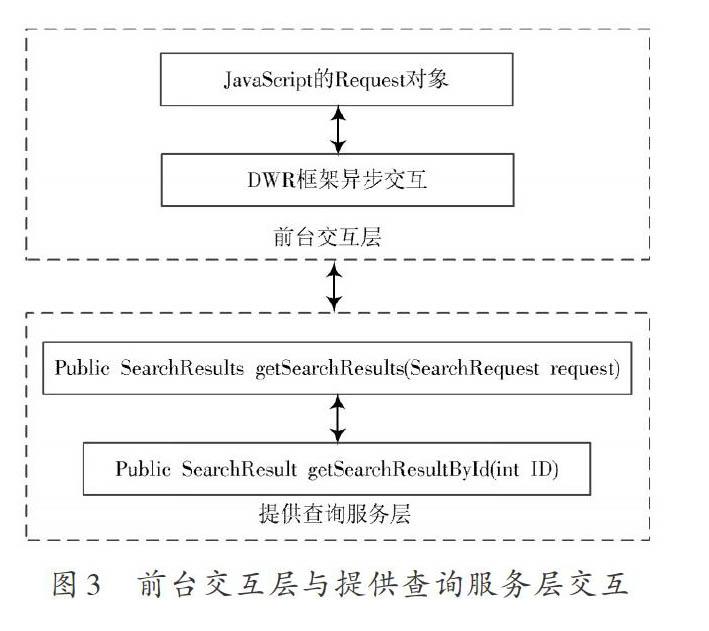
通过图2可知搜索模块和分词模块一起提供查询服务,实验中分词模块与建立索引所用分词的模块有相同的配置,而搜索模块承担查询索引和数据库的任务,由Lucene提供的搜索模块实现,开发中这2个任务分别由2个方法实现,它们是查询服务类中的2个方法,查询索引方法的参数是查询关键词对象,返回的是相关文档列表对象,查询数据库方法的参数是整型的文档ID,返回文档对象,如图3所示。
2.3 前台交互层实现
前台交互是直接面向用户的应用层,为了增加用户在输入和输出上的体验,分别实现2种功能:一是用户每次敲击按键时都会提示关键词列表;二是结果列表页面上直接展示主要结果,包括图片和其他重要属性。开发中,列表提示的数据来源于已经抽取得到的手机相关词汇,将这些词汇存入MySQL数据库的一张表里,针对该表设计一个查询方法,参数是用户按键后提交的当前字符串,实现机理是向该表发送模糊查询,返回字符串数组(一般规定提示字符串个数不超过10)。
图3 前台交互层与提供查询服务层交互
该方法的调用是通过用户触发onkeyup事件,随即以Ajax机制向服务器发送字符串并完成调用,前端通过Ajax代码接收返回的字符串数组作为显示数据,使用JavaScript改变dom的方式将这些字符串以列表的方式显示在输入框的下面。当点击搜索按钮后,开始向服务器发送查询,前台交互层与中间层的交互如图3所示,它们的交互通过Ajax框架DWR来完成,这样有效降低延时,能够明显提高用户体验。用户查询的关键字(query)以及每页的起始索引号(startindex)封装在Request对象中,直接通过Ajax发送给查询服务层的SearchServiceImpl对象的getSearchResults方法,该方法返回的SearchResults对象包含了相关文档ID的列表,然后将文档的ID作为参数发送给getSearchResultById方法查询数据库,返回文档全部信息并封装在SearchResult对象中,最后将SearchResult对象返回到前台展示给用户。
3 结 论
实验中多次查询的平均时间在毫秒级,完成了整个Web垂直搜索引擎的设计目标。验证了这种实现过程的完整性和有效性。提出的三层架构面向的是构建主题相关的Web垂直搜索引擎,通过实现查询手机信息的Web垂直搜索引擎来提供一种可操作的实施方案,为成功构建其他面向其他主题的Web垂直搜索引擎提供理论依据和技术参照。整个实现过程利用了Java平台下的优秀开源软件包,包含了可定制爬虫Heritrix、网页解析库HTMLParser、索引及查询工具包Lucene、Ajax框架DWR、Bean容器Spring以及MySQL数据库,这些开源软件为搜索引擎的实现提供了强大的支持,对于这些软件的具体使用方法和过程本文没有详细赘述,而重点讨论了构建搜索引擎的实现过程、技术要点和方法。
由于垂直搜索引擎索引数据本身就是面向主题的,所以检索结果的主题相关度、正确率必然比通用搜索引擎高,而且展示数据的能力更强。纵观现有的研究成果,作者认为未来Web垂直搜索引擎主要的研究方向有以下几个方面:
(1) 结构化数据提取自动化。爬虫应该能够自动发现、发掘Web上主题相关的来源网站,并能够自动对网站内容评级,能够实时监控Web主题网站的页面变化并更新本地的页面,通过自动化的爬虫的监控、爬取、抽取与更新操作增强搜索引擎的灵活性。
(2) 用户个性化。个性化搜索引擎尽管理论上已经得到发展,但是从理论到实际应用还需要继续研究,搜索引擎应该能够自动识别用户种类、意图,对用户的需求进行精确预测,并对歧义进行自动矫正,重点在推荐系统、相关反馈方面进行完善。
(3) 数据可靠性。由于垂直搜索引擎的返回结果大多是领域相关的内容,返回给用户的结果应该对用户负责,在医疗、问答、新闻、学术等领域的返回结果应保证数据来源的准确性,对排名靠前的结果应特别进行自动的审核,保证信息的可靠性。
本文通讯作者为田玉玲。
参考文献
[1] 刘天娇,周瑛.浅析近年来网络搜索引擎研究现状:以2001至2010年为例[J].情报科学,2012(8):1192?1195.
[2] 王文钧,李巍.垂直搜索引擎的现状与发展探究[J].情报科学,2010(3):477?480.
[3] 王斌.从信息检索到搜索引擎[J].产品安全与召回,2009(4):38?43.
[4] BRIN S, PAGE L. The anatomy of a large?scale hypertextual Web search engine [J]. Computer networks and isdn systems, 1998, 30: 107?117.
[5] CHAKRABARTIA Soumen, VAN DEN BERGB Martin, DOMC Byron. Focused crawling: A new approach to topic?specific Web resource discovery [J]. Computer networks, 1999, 31: 1623?1640.
[6] ALMPANIDIS G, KOTROPOULOS C, PITAS I. Combining text and link analysis for focused crawling: An application for vertical search engines [J]. Information systems, 2007, 32(6): 886?908.
[7] CAMBAZOGLU Barla, KARACA Evren, KUCUKYILMAZ Tayfun, et al. Architecture of a grid?enabled Web search engine [J]. Information processing & management, 2007, 43(3): 609?623.
[8] LIU Tie?yan. Learning to rank for information retrieval [J]. Foundations and trends in information retrieval, 2009, 3: 225?331.
[9] 白万民,苏希乐.Heritrix在垂直搜索引擎中的应用[J].计算机时代,2011(9):7?9.
[10] 桂林斌.基于HtmlParser抽取动态异构Web信息的研究与实现[J].计算机与数字工程,2009,37(7):161?164.
[11] 张俊,李鲁群,周熔.基于Lucene的搜索引擎的研究与应用[J].计算机技术与发展,2013,23(6):230?232.
[12] 黄翼彪.实现Lucene接口的中文分词器的比较研究[J].科技信息,2012(12):246?247.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
网络安全和信息化(2020年5期)2020-12-29
计算机与数字工程(2020年10期)2020-12-07
数码设计(2019年5期)2019-12-20
计算机与网络(2018年10期)2018-06-14
电脑知识与技术·经验技巧(2018年1期)2018-05-30
电子测试(2018年1期)2018-04-18
电子制作(2018年2期)2018-04-18
电子制作(2017年9期)2017-04-17
