
基于CUDA的多路高清视频流解码器设计与实现
2016-05-10 03:17唐昆鹏陈庆奎
电子科技 2016年4期
唐昆鹏,陈庆奎
(上海理工大学 光电信息与计算机学院,上海 200093)
基于CUDA的多路高清视频流解码器设计与实现
唐昆鹏,陈庆奎
(上海理工大学 光电信息与计算机学院,上海200093)
摘要针对多视频流解码和显示时CPU占用率过高等问题。设计了基于统一计算设备架构(CUDA)平台上的GPU多视频流并行化处理方案,定义了表示GPU显卡设备和解码器的数据结构,通过解码函数接口的调用可适用于多种视频播放器中去。实验结果表明,所设计的解码器大幅降低了多视频解码显示中CPU的占用率,同时与JM实现的软件解码方案相比,解码单路720 p的高清视频CPU占用率同比降低约30%,所以此硬件解码方案表现出更加高效的多视频流解码处理能力。提高了系统性能和资源复用率,并能保持较低的能量消耗。
关键词多视频流解码;CUDA;并行化;占用率;能量消耗
H.264[1]作为目前视频压缩领域编码效率较高的编码标准,具有低带宽高画质的压缩能力,比H.263和MPEG-4编码效率提高约50%[2]。但其实现算法复杂度和计算量较高、目前CPU的计算能力在解码720 p和1 080 p等高清视频时性能不足。
于是,GPU被设计用于为并行计算提供支持,并分担部分视频解码的任务[3-4],利用GPU内部具有众多并行计算核心来编写GPU上运行的代码,结合NVIDIA的CUDA[5-6]平台,将高密度计算量和耗时的任务移植到GPU上。与基于平台实现GPU加速的DXVA技术相比,CUDA平台上的解码方案具有更好的解码速度、效率和跨平台性。本文将GPU加速解码的方案与H.264学术研究使用的JM18.4软件解码方案进行比较,在解码速度和帧率上表现出较高的优势。同时,为满足多路视频会议和监控设备等应用需求,提出了基于CUDA的多视频流解码方案,实验表明,该设计大幅降低了解码多路高清视频时CPU的占用率,有效提高系统多视频流并行解码能力[7]。
1关键技术
NVIDIA公司开发的统一计算设备架构(Compute Unified Device Architecture,CUDA)[8-9]为GPU增加一个易用的编程接口。CPU负责派生出运行在GPU设备处理器上的多线程任务(CUDA称为内核函数)。GPU设有内部调度器将这些内核程序分配到相应的GPU硬件上。NVIDIA C编译器NVCC作为CUDA架构核心用来编译分离出GPU和CPU代码,GPU代码被编译成GPU计算汇编代码PTX并经CUDA Driver支持运行在GPU。H.264采用多模式运动估计[10]、帧内预测、多帧预测等先进实用技术,以更低的码率和压缩画质成为行业标准。其解码框架图如图1所示。
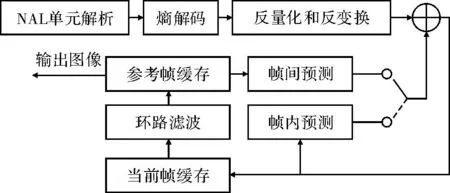
图1 H.264解码流程
2CUDA解码器设计与实现
GPU硬件加速将一部分解码任务从CPU端转移到GPU端来完成,将解码后的数据保存在显存中,在GPU内部完成解码后视频数据的后期处理工作(颜色空间转换、缩放、与OpenGL交互处理等)。CUDA硬件解码的处理架构为:将解码的MC(Motion Compensation)、IDCT、VLD(Variable-Length Decoding)、Deblocking转移到GPU中处理。
2.1CUDA解码器缓冲区
解码器需要使用硬件解码单元,然后向硬件单元传送一些配置参数,CUDA中每个参数均以对应的缓冲区来传送,需要先申请缓冲区然后填充对应类型的缓冲区。解码器需要传入代表不同缓冲区的4个参数:图片参数缓冲区、码流缓冲区、条带控制命令缓冲区和量化矩阵缓冲区。
(1)图片参数缓冲区。在CUDA解码器解码当前帧时需要一个对当前帧描述的参数,对于多个编码标准可使用CUVIDPICPARMS结构体来描述。图片级别中图片的信息会不一样,所以每解码一帧图片之前,此结构体都要被传送。以下是CUVIDPICPARMS结构体的定义:
typedef struct_CUVIDPICPARAMS
{
int PicWidthInMbs;
int FrameHeightInMbs;
unsigned int nBitstreamDataLen;
const unsigned char *pBitstreamData;
……
union {
CUVIDH264PICPARAMS h264;
…
} CodecSpecific;
} CUVIDPICPARAMS;
该结构体详细定义了图片层数据,例如,比特流缓存区中的字节数nBitstreamDataLen,pBitstreamData指针指向当前帧,union部分表示的不同视频流编码标准;
(2)条带参数。条带控制参数用来描述当前码流,用_CUDA_Slice结构体进行描述和定义:
typedef struct_CUDA_Slice {
UINT DataLocation;
UINT SliceDataInBuffer;
USHORT isBadSliceChopping;
} CUDA_Slice;
DataLocation表示传输码流中nalu单元包含的编码数据起始字节数,SliceDataInBuffer表示总的码流传输字节数,isBadSliceChopping表示传输的码流是否含有起始码;
(3)码流和量化参数缓冲区。解码器进行反量化时的量化参数将会保存在量化矩阵缓冲区中,结构体定义为:
typedef struct_CUDA_Qmatrix {
unsigned char WeightScale4×4[6][16];
unsigned char WeightScale8×8[2][64];
} CUDA_Qmatrix;
该数据结构体中包含两种不同类型的反量化参数矩阵,分别为4×4和8×8大小。同时将显存中的一块地址分配给码流缓冲区,再通过这块码流缓冲区向GPU传送解码的码流。
2.2CUDA解码流程
CUDA提供加速解码的接口函数API,本文基于该API实现并行化的视频解码,图2显示了该解码器的解码流程。
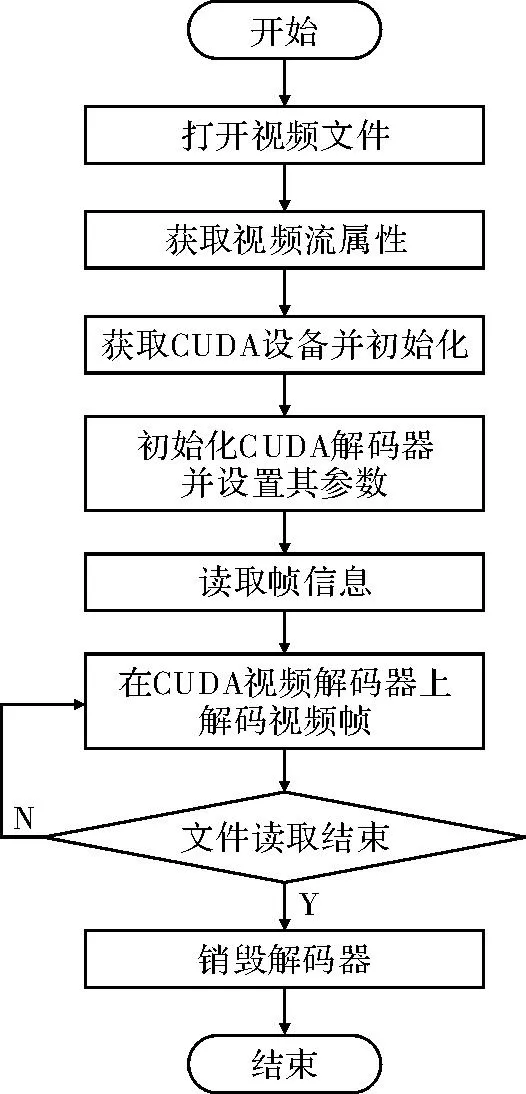
图2 解码基本流程图
步骤1读取视频文件,使用cuvidparseVideoData()函数解析视频帧信息;
步骤2初始化CUDA解码器设备并设置相关参数,例如:显卡序号、显存分配大小等;
步骤3将步骤1获得的视频帧信息,如:文件头标记、文件大小(payload)、时间戳等读入视频帧结构体。再将该结构体数据传入解码函数cuvidDecodePicture(),然后执行解码任务;
步骤4完成步骤3后,获得原始YUV数据,因为在GPU中完成解码,这些数据仍保留在设备显存中,用于视频的播放显示,也可以拷贝到主机内存做其他操作;
步骤5解码完成一帧数据后,进行文件结束标记检查,读取完成则销毁CUDA解码器、否则使用read_frame_data()读取下一帧数据。
CUDA视频解码库使用两种不同的GPU加速引擎,即显卡硬件和视频处理器VP。本文通过使用多线程技术,不同线程分配不同的显示任务并执行,cuvidMapVideoFrame线程使用映射技术,从VP解码帧得到映射后的CUDA设备指针信息;cuD3D9ResourceGetMappedPointer线程从D3D纹理中获取设备指针信息;cudaPostProcessFrame线程连续调用帧数据后处理函数,并把结果返回给映射D3D纹理;cuD3DUnmapResources线程让驱动释放指针给D3D9,表示已经完成修改,可以在D3D9中安全使用;cuvidUnmapVideoFrame线程释放VP解码帧。
2.3多视频流解码架构设计与实现
单视频流解码时通过充分利用CUDA平台实现的解码器完成GPU硬件加速解码,为解决多路视频解码问题,本文重新定义代表显卡设备的数据结构和代表解码器的数据结构,便于多码流的数据管理和调度。驱动程序可实现多个对象共用一个硬件设备,则在视频解码中解码器便可关联到同一个显卡设备。
2.3.1显卡和解码器数据结构定义
显卡数据结构定义:
typedef struct DeviceManager {
HWND Hwnd;
IDirect3D9 *pD3D9;
IDirect3DDevice9 *pD3DD9;
IDirect3DDeviceManager9 *pD3DManager;
Unsigned PCI_Vendor;
Unsigned DecoderNum;
} DeviceManager;
其中,Hwnd是程序创建的一个用来显示的窗口句柄,pD3D9和pD3DD9分别表示显卡对象和显卡设备,pD3Dmanager代表显卡设备的管理器,主要是用来管理多个解码器共享显卡设备的,PCI_Vendor表示显卡制造厂商,DecoderNum是表示与显卡关联的解码器个数,解码器定义的数据结构如下:
typedef struct_CUDADecoder {
DeviceManager *pD3DManager;
IDirectXVideoDecoder *pCUDADecoder;
IDirect3DSurface9 **pD3D9Surface;
CUVIDPICPARAMS cudaPicParams;
CUDA_Slice cudaSliceData;
CUDA_Qmatrix cudaQmatrix;
Seq_parameter_rasp_t sps;
Pic_parameter_rasp_t pps;
} CUDADecoder;
pD3Dmanager是解码器关联的显卡设备,pCUDADecoder是创建的解码器,pD3D9 surface是解码后的数据存放的表面,CUVIDPICPARAMS,CUDA_Slice和CUDAQmatrix是硬件解码单元使用的数据缓冲区结构体,sps和pps是H.264标准中所标示的条带控制参数和图像控制参数。这里基于CUDA提供的接口函数API做了一次封装,便于应用程序调用。同时定义设备的创建和解码接口,几个主要接口函数为:
(1)CUresult。InitDeviceManager(DeviceManager *pManager),该函数主要功能是显卡初始化、显卡设备的创建和类型检测等;
(2)CUresult。CreateCUDADecoder(CUDADecoder *pDecoder),该函数依据所关联的DeviceManager创建一个相应的硬件解码器对象,并将所关联的DeviceManager数据结构中的解码器计数器加1;
(3)CUresult。CUDADecodeFrame(CUDADecoder *pDecoder,NALU_t *pNalu,RECT *pRect),该函数作为解码器的接口,含有3个主要参数,第一个参数代表解码器,pNalu代表码流的一个NALU单元,pRect代表解码器解码产生的数据将会在显示窗口中呈现的显示区域;
(4)CUresult。DestroyCUDADecoder(CUDADecoder *pDecoder),该函数的功能是释放解码器设备,同时将相关联的数据结构DeviceManager中的解码器计数量减去1;
(5)CUresult。DestroyDeviceManager(DeviceManager *pManager),该函数的功能是释放显卡设备,销毁创建的数据显示窗口。函数会在销毁之前检查所关联的解码器个数是否为0,若<0,就不执行任何操作并返回,以保证安全的调用。
2.3.2多视频流解码调度
系统的整体执行流程如图3所示,具体到解码一帧数据时解码器的内部执行流程如图4所示。其中解码器内部添加阻塞锁以避免多个解码器同时竞争使用一个硬件解码单元,这样便可开启多个解码线程进行多路视频流的解码。
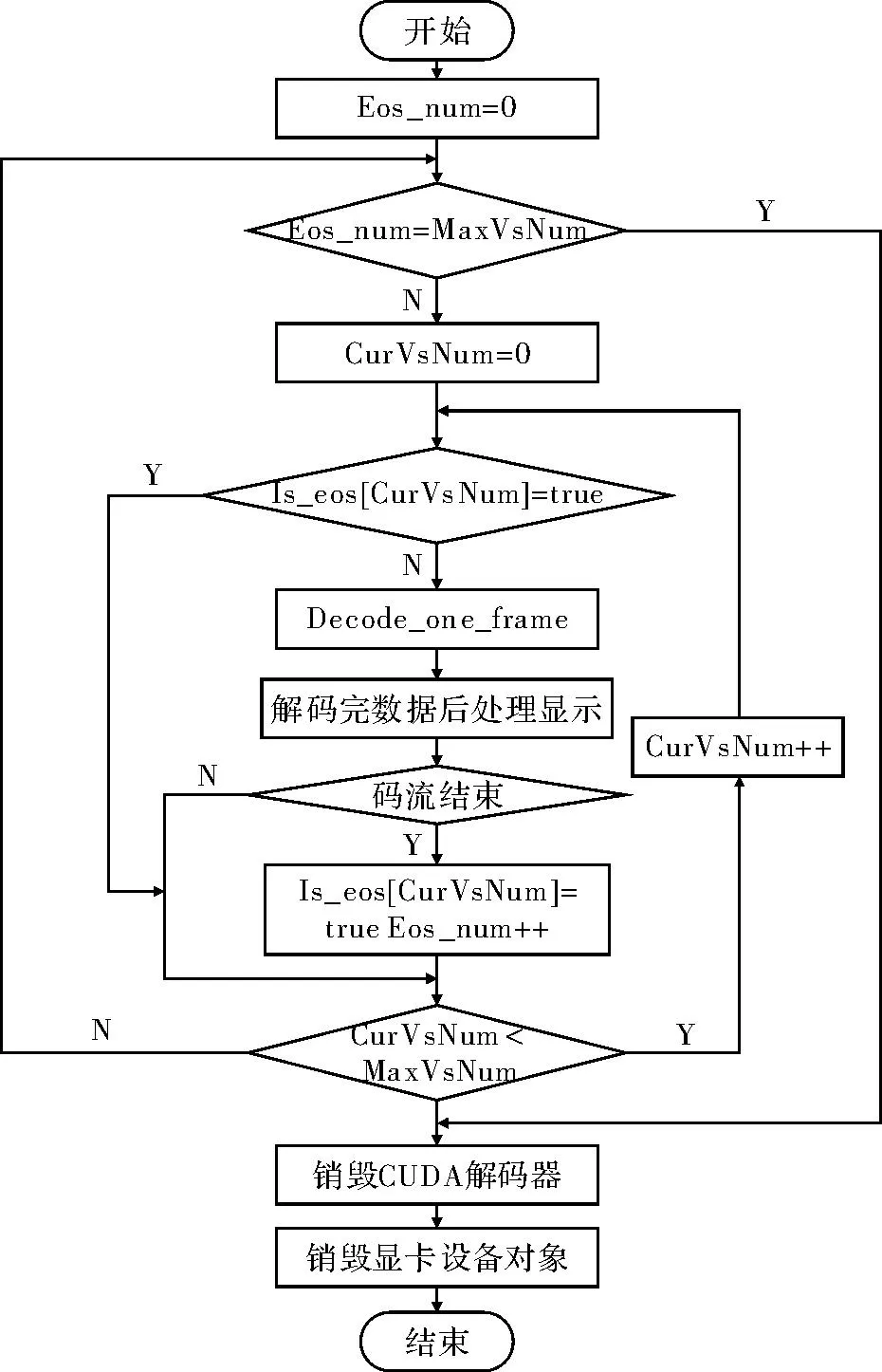
图3 多码流解码算法流程图
设计思想为:同时输入几个视频流,这几个码流轮流解码直至全部解码完成,共用解码器的主体部分,达到资源复用的目的。其中,Eos_num代表已解码完成的视频流个数,MaxVsNum最大解码视频流个数,CurVsNum当前解码的视频流序号,Is_eos[CurVsNum]判断序号为CurVsNum的视频流是否解码完成。
多码流的解码,必须保持各码流之间的独立性,解码器主体函数中,需要做一些修改。比如码流缓冲区、存放解码图像的缓冲区、存储码流的SPS和存储码流的PPS等结构体分别为不同的码流分配不同的存放空间。解码每一帧时的帧级和宏块级变量均会被重新赋值,对各帧之间的解码没有影响,因此不用修改。多码流级别的全局变量为所有码流可见,生命周期是整个解码的过程,所以需要增加一维,深度设置为最大解码视频流的个数,每个码流占用其中一维,这样多个码流的解码操作互不干涉。
3实验结果与性能分析
测试平台环境相关参数为:双核Intel Core 2 Duo E8400 CPU,主频3.00 GHz,内存4 GB,GPU为NVIDIA GeForce GTX 280,显存容量为1 GB,流处理器(SP)个数240个,操作系统为Windows7,CUDA 5.5,并在Visual Studio 2010环境下调试编译,计时函数采用Win32 API中的GetTickCount()函数,精确到ms。
3.1JM18.4软件解码与CUDA解码对比
针对不同视频流文件进行测试,JM18.4软件解码器与CUDA解码器在解码时间、帧率上做对比,分别如图5和图6所示。
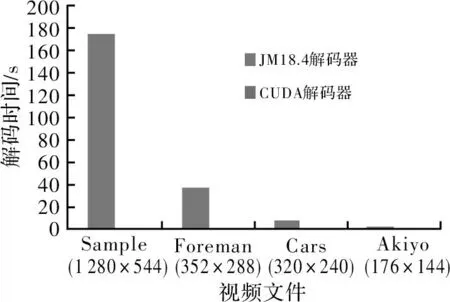
图4 解码时间对比
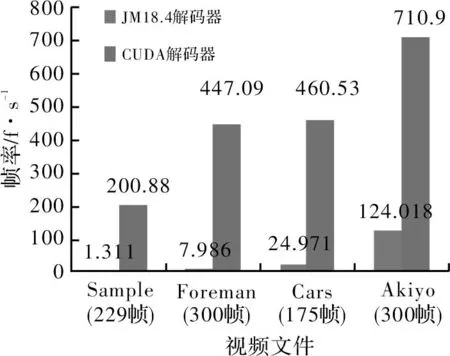
图5 帧率对比
以同时解码视频流文件Sample为例,从帧率上比较,CUDA是JM18.4的近115倍,解码时间上也只有后者的0.6%,实验结果表明,基于CUDA优化的GPU并行加速解码方案比JM18.4软解码具有更好的性能和效率,因此使用GPU并行化加速视频流解码具有较大的优势。
3.2基于CUDA的多视频流解码器性能评测
通过CPU解码与基于CUDA的GPU解码器进行了多视频解码的对比测试,测试视频文件为720 p的高清视频,码率平均为14.8 Mbit·s-1,衡量标准为每解码30帧图像的时间。开启6个解码线程同时解码,本文主要测试解码器的解码速度和CPU的占用率这两个标准,测试结果如图7和表1所示。
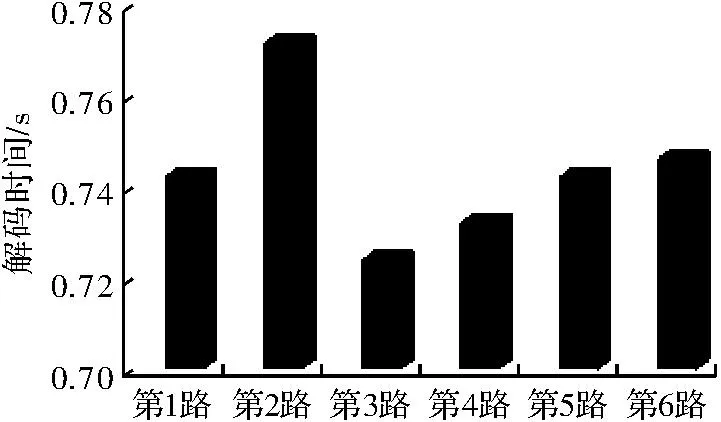
图6 6路视频解码时间
帧率最低为24帧/s,画面才会保持流畅,这里编码器采用30帧/s,同时解码6路720 p的高清视频,平均时间0.74 s,可计算得帧率为40.43。所以可保证流畅的播放视频画面。
基于GPU的硬件解码方案,负担高计算量的解码任务同时,同时降低了CPU的占用率,取1路720 p高清视频解码,对比试验如表1所示。
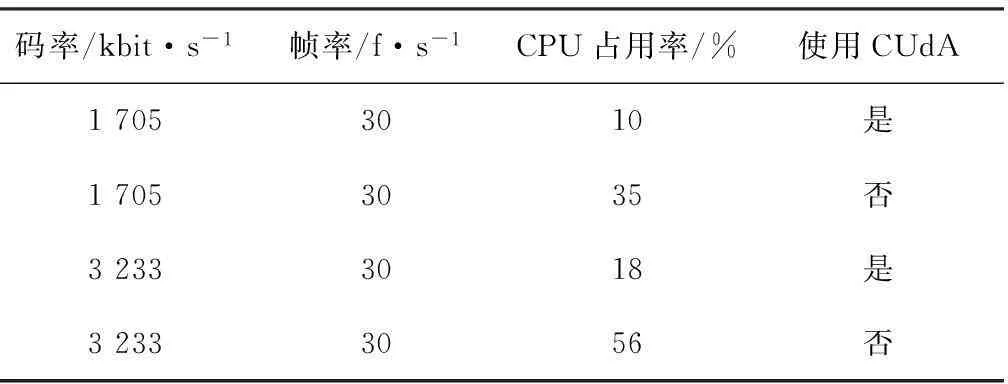
表1 CPU占用率
由表1实验数据可看出,基于CUDA的解码器播放高清视频时可大幅降低CPU占用率,提高多视频流的解码能力,图7中6路视频解码保持帧率40.43时,CPU占用率不到100%。若将线程的分配和设备的初始化设计进一步优化,则可降低CPU的占有率。
4结束语
本文研究了基于CUDA的GPU视频解码技术,实现了并行化的多视频流解码方案,实验结果证明,与软件解码方案JM18.4比较,GPU等硬件并行化加速处理方案对视频解码的具有更高的处理效能,降低CPU的占用率近30%,提高了多路视频解码的能力,具有较好的研究与应用价值。使解码器同时解码更多数量和更高分辨率的高清视频流是今后需要继续研究的内容。
参考文献
[1]毕厚杰.新一代视频压缩编码标准[M].北京:人民邮电出版社,2005.
[2]李超,柴文磊,刘劲松.高清视频会议系统技术浅析[J].信息安全与技术,2010(10):50-51.
[3]侯兴松,刘大齐,盛凯,等.H.264并行编码中负载平衡方法[J].中国图象图形学报,2012,17(8):911-918.
[4]张舒,楮艳利.GPU高性能运算之CUDA[M].北京:中国水利水电出版社,2009.
[5]Shane Cook.CUDA并行程序设计:GPU编程指南[M].北京:机械工业出版社,2014.
[6]董亚清.基于GPU的线性调频信号脉冲压缩算法实现[J].电子科技,2013,26(12):12-16.
[7]Youngsub K O,Youngmin Y I,Soonhoi H A.An efficient parallel motion estimation algorithm and X264 parallelization in CUDA[C].Tampere,Finland:2011 Conference on Design and Architectures for Signal and Image Processing(DASIP),2011:4521-4536.
[8]Jae-Jin Lee,Kyungjin Byun.Multi-core architecture for video decoding[J].SoC Design Conference(ISOCC),2012,3(12):4-7.
[9]Juurlink B,Alvarez-Mesa M,Chi C C,et al.Scalable parallel programming applied to H.264/AVC decoding[M].New York,USA:Springer-Verlag,2012.
[10]Kovács P T,Nagy Z,Barsi A,et al.Overview of the applicability of H.264/MVC for real-time light-field applications[C].Budapest,Hungary:Proceeding of 3D TV Conference,2014.
欢 迎 刊 登 广 告
请访问:www.dianzikeji.orgE-mail:dzkj@mail.xidian.edu.cn
联系电话:029-88202440传真:029-88202440
Design and Implementation of Multi-stream Hd-decoder Based on Cuda
TANG Kunpeng,CHEN Qingkui
(School of Optical-Electrical and Computer Engineering,University of Shanghai for Science and Technology,Shanghai 200093,China)
AbstractA GPU multi-stream parallel decoding implementation based on compute unified device architecture (CUDA) platform is designed to solve the high CPU load problem in multi-video decoding and display.The data structure of the graphics processing unit (GPU) device and video decoder are defined.By calling the decoding function interface,the decoder can be used in variety of video players efficiently.The experimental results show that this decoder can greatly reduce the CPU utilization.Also,compared with the JM reference software decoder,CPU utilization is remarkably reduced by 30% when decoding the single road 720 p high definition video synchronously.So the decoder based on hardware enjoys higher efficiencyin video parallel decoding.Besides,the system performance and resource reuse rate are improved together with lower energy consumption.
Keywordsmulti-video decoding;CUDA;parallelization;occupancy;energy consumption
中图分类号TN919.8;TP338
文献标识码A
文章编号1007-7820(2016)04-071-05
doi:10.16180/j.cnki.issn1007-7820.2016.04.019
作者简介:唐昆鹏(1989—),男,硕士研究生。研究方向:并行计算。陈庆奎(1966—),男,博士,教授。研究方向:并行计算等。
基金项目:国家自然科学基金资助项目(60970012);高等学校博士学科点专项科研博导基金资助项目(20113120110008);上海重点科技攻关基金资助项目(14511107902)
收稿日期:2015- 08- 21
猜你喜欢
体育科技文献通报(2022年4期)2022-10-21
体育科技文献通报(2022年3期)2022-05-23
计算机工程与设计(2022年3期)2022-03-22
作文中学版(2020年1期)2020-11-25
企业文化(2020年8期)2020-06-03
魅力中国(2019年6期)2019-07-21
汽车文摘(2017年5期)2017-12-05
新乡学院学报(2015年6期)2015-11-06
安阳工学院学报(2015年2期)2015-09-26
中国老年学杂志(2015年5期)2015-05-29
