
以目标节点为导向的XML关键词查询和排序
2016-05-09 07:07李瑞霞刘仁金周先存
计算机应用与软件 2016年4期
李瑞霞 刘仁金 周先存
以目标节点为导向的XML关键词查询和排序
李瑞霞 刘仁金 周先存
(皖西学院信息工程学院 安徽 六安 237012)
为了准确推断用户的查询意图,提出一个XML关键词查询和排序的方法。该方法首先根据XML文档结构和语义,分别建立标签信息表和文本信息表表示文档的结构和数据,然后通过标签和文本两个指标确定查询关键词和目标节点的相似性得分,给出排序方法。同时给出该方法实现的算法,并通过实验验证了该方法的有效性。实验结果表明,该方法可以更准确地推断用户查询的目标节点。
XML
查询 排序 目标节点
0 引 言
XML因其结构灵活并易于扩展,已成为当前数据表示的主流形式。对于XML的关键词查询也是许多学者的研究热点,借助查询语言XPath、XQery可以进行准确的查询,但要求用户对XML文档结构有所了解,并熟悉其语法,该方法未能广泛应用。针对XML的关键词查询因其简单易用,已成为主要的信息检索方法。XML关键词查询方面有大量的研究工作。文献[1]把XML看作一个树结构,通过计算LCA,专门提出“meer operator”的概念进行查询,其结果类型依赖XML文档的实例。文献[2]要求用户了解XML文档的部分知识实现查询,设计了MLCS算法。2005年文献[3]提出了SLCA的概念并且设计了三种有效的算法实现了一个XKSearch搜索系统。2007年文献[4]基于SLCA,同时结合了“AND”、“OR”操作进行关键字查询。文献[5]提出了XSeek,通过验证查询关键词和XML结构的匹配模式获得返回节点。文献[6,7]利用多个指标识别用户的搜索意图并进行了结果排序,但是该方法没有考虑包含文本节点的叶子节点的作用,因此并不能准确地识别目标节点。对于结果排序方面,2003年文献[8]提出了XRank方法,计算LCAs处理XML关键字相似性查询。该方法返回的结果是XML文档的部分片段。文献[9]返回的是具有语义关系的片段,但是由于该方法要求用户需了解文档的结构,因此该方法有其局限性。文献[10]利用TF-IDF结合文档结构进行异构数据查询及排序。文献[11]利用统计学的思想进行检索结果排序。以上方法都是基于LCA及其变体,并没有从根本上解决用户的搜索意图及结果排序的问题。
在XML关键字查询中准确地识别用户的搜索意图并将最相关的结果进行排序已经成为一个具有挑战性的问题。由于在XML关键词查询结果中包含大量目标节点,导致提供给用户的结果并不能满足其需求,而且可能漏掉相关的结果。本文的目标是要推断符合用户查询意图的目标节点并且返回最相关的结果。该方法中,首先分别构建一个标签信息表用来存储文档的元素和属性节点,一个文本信息表用来存储文档的元素和属性的取值;然后通过检索两个表初步推断目标节点的类型,最后计算目标节点和关键词的相似性得分,并给出结果排序方法。
1 相关工作
在文中XML文档可以用一个带有根节点的标签树表示t=(r,NE,NV)。其中,r表示根节点;NE为元素节点和属性节点的集合;NV代表元素节点和属性节点的取值的集合。根据XML文档所包含的结构和语义信息[12,13],本文作如下定义:
定义1 (标签节点)XML文档中的元素节点和属性节点的总称,存储标签节点相关信息的表称为标签信息表。
定义2 (文本节点)XML文档中的表示元素节点和属性节点的取值,存储文本节点相关信息的表称为文本信息表。
定义3 (前缀路径)XML文档中用前缀路径表示从根节点到当前节点的所经过的路径,用path表示,存储在标签信息表中。
如图1所示,XML文档包含若干节点,其中″dblp″可以看作是根节点,″phdthesis″、″proceedings″等表示文档结构的节点就是标签节点,″title″、″publishing″等为叶子节点,而″280″、″1998″等则表示叶子节点或者属性的取值,也称文本节点。
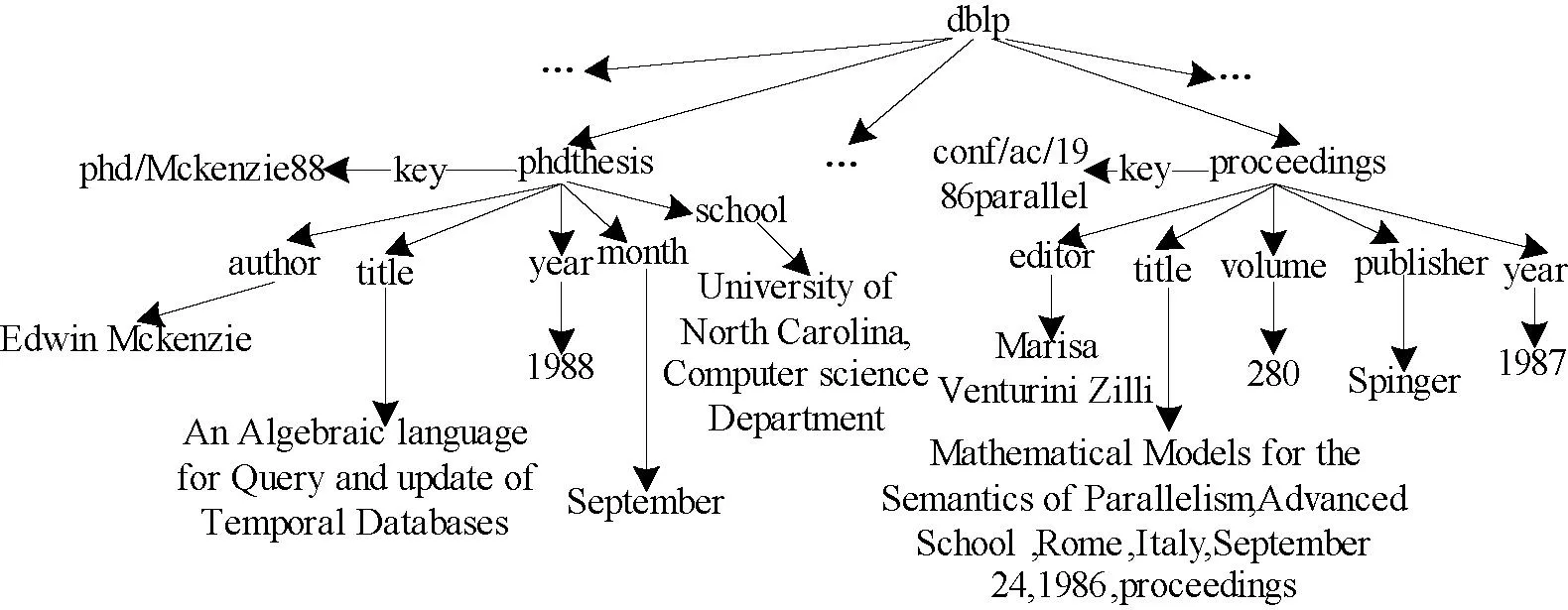
图1 一个XML文档树的例子
2 目标节点推断打分及排序方法
关键词查询的目标是从XML文档集中找到与给定关键词最相关的文档或片段。本文提出的方法利用匹配XML文档的标签和文本两个指标来识别目标节点,进而综合两个指标的相似性得分,最后给出了排序方法。主要分为如下几个步骤:
(1) 为了在查询过程中能够识别用户查询目标是标签还是文本,对XML文档分别建立标签信息表和文本信息表;
(2) 对于一个给定的查询,利用两个指标进行匹配确定目标节点类型;
(3) 利用对数函数和概率函数计算查询关键词和标签的相似性找到相关的目标节点;
(4) 计算包含文本节点的叶子节点和查询关键字之间的相似性,进一步识别目标节点;
(5) 通过综合两个指标的相似性得分,对查询结果进行排序。
下面分别介绍各个步骤的实现方法。
2.1 两个指标
在文献[6,7]中提到了频率表,但是没有确定查询关键字是结构节点还是文本节点,所以导致查询变得更复杂。为了克服该问题,本文提出的方法确定了两个指标,即标签和文本。对于某特定的XML文档,标签信息表存储了相应的标签信息(标签名tsn,标签在目标节点及其子树中出现的次数ft,目标节点的前缀路径path)。同样,文本信息表里存储了相应的文本节点信息(文本值d,包含该文本节点的叶子节点的标签名tln,该文本节点在叶子节点中出现的次数fd)。由此看出,文本信息表里也包含了叶子节点的信息,所以两个表共享XML文档的信息。为了简化查询过程,本文分别对标签和文本来处理。
2.2 确定目标节点的类型
对于一个给定的XML查询,首先在标签信息表里查找匹配的关键词,如果查找成功,则该查询的目标是标签记为Kt,同时可以从标签信息表获得标签名tsn,标签在目标节点及其子树中出现的次数ft,目标节点的前缀路径path等信息;否则就从文本信息表里查找,如果匹配成功,则该查询的目标是文本信息记为Kd,包含该文本的叶子节点tln可以从该表获得,而该叶子节点的其他信息ft,和path则从标签信息表获得。
2.3 相似性得分
XML关键词查询中,关键词可能在标签或者文本中出现一次或者一次以上,若找到一个以上的匹配结果,则需要找到最优的目标节点。因此本文借助对数函数和统计学的思想,计算检索关键词和目标节点的相似性得分如下:
(1)
式中,k表示某查询q中的某个关键词,Tt表示标签信息里的标签,D表示文本信息里的文本值,f(tk)表示在每个前缀路径上标签和关键词匹配的次数,f(td)表示关键词匹配的文本值在叶子节点中出现的次数,f(tk,td)表示在查询中标签和文本值结合的次数,rf是[0,1]之间的衰减因子,d(T)表示XML文档中目标节点的所在的层次,rfd(T)的作用是为了减少多层次嵌套带来的影响。
从式(1)分析可以看出,该相似性得分并没有考虑文本节点及其所在的叶子节点的作用,因此通过下面的处理进一步查找最优的目标节点。
在文本信息表中查找匹配的文本,进而可以找到包含该文本值的叶子节点,因此我们借助标签信息表选择节点所在的前缀路径上出现次数最多的节点作为目标节点。通过如下的方法计算前缀路径上找到的目标节点和查询关键词之间的相似性。
(2)
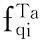
于是,最后的目标节点和查询关键词相似性得分可以通过下式表示:
Similarity Score=Mscore+S(X)
(3)
由此可以看出,相似性函数综合了标签和文本两个指标进行匹配,从而可以获得最优的目标节点。
2.4 排 序
通常,我们认为和查询关键词相似性得分较高的节点应该是最相关的结果,应该优先呈现给用户。因此,本文通过如下的方法确定最终目标节点。
G=Max{Mscore+S(x)}
(4)
下式表示目标节点的排序方法:
(5)
3 主要实现算法和实验结果分析
3.1 主要实现算法
本文首先解析XML文档,抽取文档中元素或者属性节点的标签名tsn、该节点的前缀路径path、文本节点的前缀路径path、节点值d、标签在目标节点及其子树中出现的次数ft、包含该文本节点的叶子节点的标签名tln以及该文本节点在叶子节点中出现的次数fd等信息,进而获得标签和文本信息,构建标签信息表的的方法命名为tag_info table。构建文本信息表的方法命名为data_info table,另外一个存储前缀路径信息的方法命名为path_info table。其中的空间复杂度为O(Nsn),而Nsn则和XML文档中标签节点和文本节点的数量高度相关。主算法见算法1,分别包括三个程序:首先,通过get_IndexInfo获得关键词匹配标签和包含了文本的叶子节点的信息;对于每个前缀路径,程序get_MutualScore计算匹配的标签和叶子节点的综合相似性得分;最后,程序get_SimilarityScore计算出叶子节点和查询关键词的相似性,从而通过排序的方法得到目标节点。
算法1 关键词查询中的目标节点计算方法
输入:包含了n个关键词的查询Q
1 get_IndexInfo(query keywords)
2 get_MutualScore(keyword match)
3 get_SimilarityScore(data keywords)
算法2检索标签信息表和文本信息表确定检索目标是标签还是文本,同时获得检索到的标签名、出现次数等信息。程序Get_IndexInfo检查标签信息表中是否包含查询关键词,同时,通过调用dataExist检查文本信息表中是否包含查询关键词(1-5行)。然后,对于每个标签关键词kt调用了getFromTaginfo得到关键词匹配的标签节点相关信息,存储于taglist和slist(6-10行)。同样,对于文本关键词调用getFromDatainfo得到包含该节点的叶子节点的相关信息,并存储于datalist和slist。
算法2 Get_IndexInfo(query)
input: Query Q containing n keywords
1 for each keyword ki ∈Query do
2 if taglist(ki)= true then
3 { kiis a tag keyword}
4 else if dataExist(ki) = true then
5 { kiis a data keyword}
6 for each tag keyword∈Query do
7 rs = getFromTaginfo (tki)
8 while ( rs.next)
9 result = tsn+ft+path
10 taglist(result); slist(result)
11 for each data keyword∈Query do
12 rs=getFromDatainfo(ai)
13 while (rs.next)
14 result = tln+fti十path
15 datalist (result); slist (result)
16 return slist0:
对于一个查询Q,若包含了n个关键词,则算法2的时间复杂度最坏的情况可以表示为O(n+nt×kmt+nd×kmd),n表示查询关键词的数量,nt和kmt分别代表标签节点和可以匹配的标签关键词的数量;同样,nd和kmd表示文本节点和可以匹配的叶子节点的数量。
算法3综合标签和文本两个方面得到目标节点和关键词之间的相似性得分。
算法3 Get_MutualScore(query,keyword match)
1 for each keyword matching tag ∈ Query do
2 f(tk) =getTagFrequency (query)
3 for each keyword matching data value ∈ Query do
4 f(td)=getDataFrequency(query)
5 Based on combination of tag and data in query, assign a value to cvalue
6 for each result ∈ slist() do
7 Splitpath from slist(); tagpath(path)
8 Based on cvalue. Construct queryStringqueries(queryString)
9 for (each queryString ∈ queries()) do
10 d = getCombinedFrequency (queryString)
11 f(tk,td) + = d
12 msum = lg(f(tk,td)/lg(f(tk)*f(td))
13 mscore = Msum*rdepth(T)
14 mlist(path, mscore)
15 retum mlist0:
算法4检索文本信息表,进一步计算了文本节点所在的叶子节点和查询之间的相似性,结合算法3进行了最终相似性得分的计算,并给出了排序的方法。
算法4 Get_similarityScore(data keyword)
1 for each datakeywords E Query do
2 rs = getFromData _info(dki)
3 while ( rs.next)
4 result = d +fd+tln+ id
5 dsimilar(result)
6 for each result ∈dsimilar() do
7 Get tag with biggest frequency; ltag= tln+fd+id
8 stag(ltag)
9 for each ltag ∈ stag do
10 rs = caIIReferences(id)
11 while (rs.next)
12 Get frequency fdGet path of ltag from path_info
13 for each data ∈ mlist do
14 if path in mList =poth from path_info then
15 Get mscore from mList
16 f=fd
17 S(x) =f + Lg(f)
18 SimilarityScore = mscore +S(x) ;
19 Grading = Max(SimilarityScore)
20 retum SimilarityScore
通过分析可以看出,在本方法中标签信息表最坏的空间复杂度为O(Nsn),文本信息表最坏的空间复杂度为O(D×Nln)。在Xreal中频率表最快空间复杂度为O(K×N),式中K表示不同的关键词的数量,N表示节点类型的数量,因此本文的空间复杂度比Xreal降低了。
3.2 实验分析
我们利用Java语言实现了基于前述算法的一个推断目标节点的XML关键词检索原形系统。对比算法选择了Xreal,测试数据集使用实际的DBLP数据集(127 MB),实验平台是Intel 2.8 GHz Pentium D 处理器,1 GB RAM,Windows 7操作系统。测试选取了70篇文档。表1表示其中10组数据的测试结果,对比结果表明本文提出的方法能更准确的推断用户的查询意图。图2对比了二者的查全率和查准率。图2中(a)和(b)横坐标代表测试的7组数据,纵坐标分别代表每组数据的查全率和查准率。由图2 可见,本文提出的方法效果更优。

表1 DBLP数据集上的测试结果

图2 DBLP上的检索性能
4 结 语
本文提出了XML关键词查询中推断目标节点的方法。首先构建了标签信息表和文本信息表用来存储XML文件的元素节点和文本节点,通过分别匹配两个表识别查询目标是标签还是文本,以此解决查询关键词二义性的问题。然后借鉴对数函数和概率函数的思想分别对标签信息和文本信息计算得到综合相似性得分,最后对得分结果进行排序。给出了该方法实现的主要算法,并通过实验验证了该方法的可行性。结果表明,利用该方法可以得到理想的检索目标。今后将进一步优化算法,并结合其中的语义进行研究[14,15],以期能得到更好的结果。
[1] Schmidt A,Kersten M,Windhouwer M.Querying XML documents made easy:Nearest concept queries[C]//Proceedings of the 17th International Conference on Data Engineering (ICDE),Heidelberg,April 2-4,2001,IEEE Computer Society,2001.
[2] Li Y,Yu C,Jagadish H V.Schema-free XQuery[C]//Proceedings of the 30th International Conference on Very Large Data Bases(VLDB),Toronto,August 30-September 3,2004,Morgan Kaufmann Press,2004.
[3] Xu Y,Papakonstantinou Y.Efficient keyword search for smallest LCAs in XML databases[C]//Proceedings of the ACM SIGMOD International Conference on Management of Data (SIGMOD),Baltimore,June 13-16,2005,ACM Press,2005.
[4] Sun C,Chan C Y,Goenka A K.Multiway SLCA-based keyword search in XML data[C]//Williamson C L eds: Proceedings of the 16th International Conference on World Wide Web(WWW),Banff,May 8-12,2007,ACM Press,2007.
[5] Liu Z,Chen Y.Identifying meaningful return information for XML keyword search[C]//Proceedings of the ACM SIGMOD International Conference on Management of Data(SIGMOD),Beijing,June 11-14,2007,ACM Press,2007.
[6] Bao Z,Ling T W,Chen B,et al.Effective XML keyword search with relevance oriented ranking[C]//Proceedings of the 25th International Conference on Data Engineering(ICDE), Shanghai, March 29 - April 2,2009,IEEE Press,2009.
[7] Bao Z,Lu J,Ling T W.XReal:AN interactive XML keyword searching[C]//Proceedings of the 19th ACM Conference on Information and Knowledge Management(CIKM),Tronto,October 26-30,2010,ACM Press,2010.
[8] Guo L,Shao F,Botev C,et al.XRANK:Ranked keyword search over XML documents[C]//Proceedings of the 2003 ACM SIGMOD Conference on Management of Data,California,June 9-12,2003,ACM Press,2003.
[9] Cohen S,Mamou J,Kanza Y Sagiv.XSEarch: A semantic search engine for XML[C]//Proceedings of the 29th International Conference on Very Large Data Bases(VLDB),Berlin,September 9-12,2003,Morgan Kaufmann Press,2003.
[10] Li G,Ooi B C,Feng J,et al.EA SE:An effective 3-in-l keyword search method for unstructured,semi-structured and structured data[C]//Proceedings of the International Conference on Management of Data(SIGMOD),Vancouver,June 9-12,2008,ACM Press,2008.
[11] Termehchy A,Winslett M.Using structural information in XML keyword search effectively[J].ACM Trans on Database System(TODS),2011,36(1):1-35.
[12] 郭文琪,陈群,娄颖.一种推断XML关键字检索目标节点的方法[J].计算机工程,2012,38(8):41-49.
[13] 张欣毅.XML简明教程[M].北京:清华大学出版社,2009:46-55.
[14] 黄瑞,史忠植.一种新的Web异构语义信息搜索方法[J].计算机研究与发展,2008,45(8):1338-1345.
[15] 李瑞霞,苏守宝,周先存.一种基于语义相关度的XML关键字查询排序方法[J].吉林大学学报:理学版,2013,51(6):1118-1122.
TARGET NODE-ORIENTED XML KEYWORD QUERY AND RANKING
Li Ruixia Liu Renjin Zhou Xiancun
(SchoolofInformationEngineering,WestAnhuiUniversity,Lu’an237012,Anhui,China)
In order to accurately conclude user’s query intent, we proposed an XML keyword query and ranking method. First, according to the structure and semantics of XML document, the method sets up tag_info table and text_info table respectively to represent the document structure and data, then determines the score of similarity between querying keywords and target node by two indicators of label and text, and gives the sorting approach as well as the algorithm to implement the method. Finally, we verified the effectiveness of the method through experiment; experimental results showed that the proposed method could more accurately conclude the target node of users query.
XML
2014-08-24。国家自然科学基金青年基金项目(6130 3209);安徽省高等学校省级自然科学研究重点项目(KJ2013A255)。李瑞霞,副教授,主研领域:智能数据挖掘及应用。刘仁金,教授。周先存,副教授。
TP301
A
10.3969/j.issn.1000-386x.2016.04.008
query Sorting Target node
猜你喜欢
数学物理学报(2022年5期)2022-10-09
客联(2022年3期)2022-05-31
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
中国新闻周刊(2021年26期)2021-07-27
河北画报(2020年8期)2020-10-27
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
信息安全研究(2016年4期)2016-12-01
浙江大学学报(工学版)(2016年2期)2016-06-05
