
基于笔画曲率特征的笔迹鉴别方法
2016-05-04 02:43李庆武马云鹏周亮基
中文信息学报 2016年5期
李庆武,马云鹏,周 妍,周亮基
(1. 河海大学 物联网工程学院,江苏 常州 213022 2. 常州市传感网与环境感知重点实验室,江苏 常州 213022)
基于笔画曲率特征的笔迹鉴别方法
李庆武1,2,马云鹏1,周 妍1,2,周亮基1
(1. 河海大学 物联网工程学院,江苏 常州 213022 2. 常州市传感网与环境感知重点实验室,江苏 常州 213022)
现有的手写汉字脱机笔迹鉴别方法存在只能针对特定字符或需要大量样本字符等问题,为此提出一种基于笔画曲率特征的笔迹鉴别方法。首先运用数学形态学对采集的笔迹图像进行预处理,在横、竖、撇、捺四个方向提取具有代表性的笔画骨架,然后对笔画骨架进行圆的重构,提取四个方向笔画圆的曲率作为特征值组成笔迹特征矩,根据待鉴别的笔迹特征矩与数据库中笔迹特征矩向量夹角相似性度量结果对样本做出判断。实验结果表明该文方法对于待鉴别样本字符的内容没有要求,样本字符数量要求低、应用范围广、鲁棒性强。
笔迹鉴别;数学形态学;笔画圆重构;笔画曲率;夹角相似性
1 引言
计算机笔迹鉴别是人体行为特征识别技术的重要组成部分,具有高效、规范、客观等优点,为身份认证与信息保护提供了一种新的方式。
现有的中文脱机笔迹鉴别方法大多针对特定字符,黄海龙提出了一种基于数学形态学的签名真伪鉴别方法[1],该方法利用数学形态学运算提取具有明显方向性特征的笔画,通过笔画的长短、粗细、间隔等信息完成签名样本的鉴别工作,但要求笔迹样本包含的字符内容固定统一。陈睿提出了基于关键词提取的手写汉字文本依存笔迹鉴别技术[2],该方法在任意内容的笔迹样本中寻找特定字符完成笔迹鉴别,实质是将任意字符笔迹的鉴别转化为特定字符笔迹的鉴别,对特定字符样本的依赖导致该方法通用性低、稳定性差。在与内容无关的计算机笔迹鉴别方面,李昕提出了一种基于微结构特征的多种文本无关笔迹鉴别方法[3],该方法利用局部微结构在整幅图像中的概率分布函数来表征笔迹风格特性,可以适应不同文种的笔迹鉴别,鉴别准确率高,但对于笔迹样本字符的数量与版式有较高的要求。鄢煜尘提出了基于特征融合的脱机中文笔迹鉴别方法[4],该方法分离出单个字符中与内容无关的笔迹特征,通过特征融合的方式得到整份笔迹的特征向量,再进行分类鉴别,对笔迹样本字符数量要求低,但是鉴别准确率较低。总而言之,在与内容无关的计算机中文笔迹鉴别领域,如何降低鉴别方法对笔迹样本的依赖,同时提高鉴别正确率是亟待解决的难题。
本文提出基于笔画曲率特征的笔迹鉴别方法,通过四个方向笔画骨架的曲率特征对笔迹样本进行鉴别,对于待鉴别样本字符的内容没有要求,字符数量要求低、应用范围广、鲁棒性强。
2 笔迹鉴别方法
本文中的笔迹样本图像均为黑色签字笔在白纸上书写的随机字符,由500万像素自对焦高拍仪录入计算机,图像格式为Jpeg。基于笔画曲率特征的笔迹鉴别方法的流程图如图1所示,分为笔画骨架提取、笔画特征提取、生成笔迹特征矩、相似性度量几个步骤。
2.1 笔画骨架提取
采集待鉴别笔迹样本中的字符生成十幅样本图像,这里设高拍仪采集的每幅样本图像区域包含三个连续字符(不同的样本图像包含的字符不相同),原始单幅笔迹样本图像如图2(a)所示。
首先对于彩色笔迹样本图像2(a)进行灰度化与二值化处理,再利用快速细化算法对笔迹样本图像进行细化处理,快速细化算法运用数学形态学对目标进行逐层剥取,快速提取字符骨架[5],完成快速细化处理的字符骨架图像如图2(b)所示。
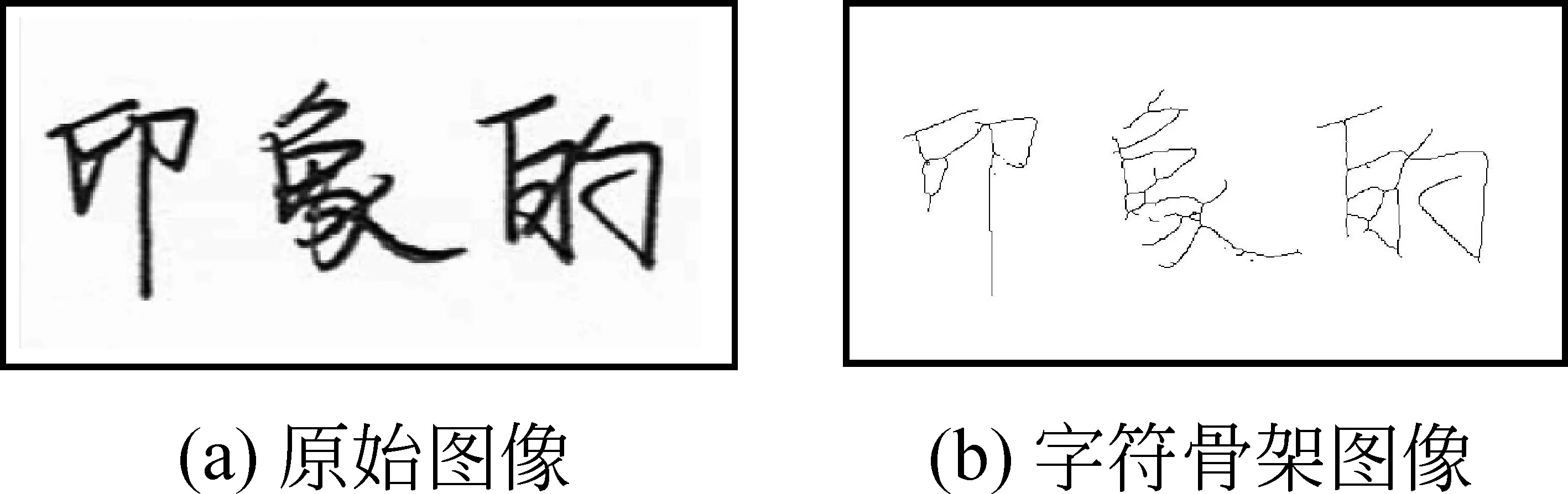
图2 字符骨架提取
将细化后的二值样本图像2(b)进行取反,为了提高特征的显著性,再将样本字符由单像素点排列的字符骨架图像膨胀为三像素点并行排列的字符图像,完成膨胀处理后的样本图像如图3(a)所示。
汉字的笔画主要有横、竖、撇、捺,依据数学形态学的基本运算和结构元素在数学形态学运算中的作用,选取0°方向的线性结构元素对笔迹图像进行闭合运算,即提取了笔画横,以此类推,运用90°、45°、135°方向的线性结构元素对笔迹图像进行闭合运算,分别对应提取了笔迹图像的笔画竖、笔画撇、笔画捺。
结构元素是数学形态学运算的基本要素,结构元素的不同直接决定了分析和处理图像的集合信息不同,小尺寸的结构元素对图像的细节比较敏感,而大尺寸的结构元素对图像的轮廓比较敏感。提取笔迹图像中的笔画时,由于笔画是线性结构,所以本文方法选取结构元素为直线型。根据对手写汉字字符笔画长度与曲率的分析,结构元素的长度选取六至十个像素点较为合适,由于手写字符中笔画方向并不满足绝对的横平竖直,例如,笔画横往往与水平方向存在一定的夹角,选取小尺寸的结构元素具有很好的包容性,但结构元素尺寸较小时,会大幅降低笔画提取的有效性,所以要求结构元素具有包容性的同时,也需保证一定的有效性,本文选取结构元素长度为八个像素点,可以满足上述要求[1]。
针对已完成膨胀处理的图像3(a),运用闭合运算提取单方向笔画,选取结构元素为直线形,长度为八个像素点,再分别选取0°、90°、45°、135°四个方向(分别对应提取汉字横、竖、撇、捺四个方向笔画)进行闭合运算。笔迹单方向笔画提取运算过程如式(1)所示,其中Iout为单方向笔画图像,Iin为输入图像,Si是长度为8,与水平分别成0°、90°、45°、135°的四种方向线形结构元素。
Iout=Iin·Si
(1)
以撇方向笔画提取示例,以选取结构元素为直线型,长度为八个像素点,角度为45°为例,对3(a)进行闭合运算,完成闭合运算后的图像如图3(b)所示。提取出连通域面积最大的笔画作为笔迹样本图像中最具代表性的单方向笔画,如图3(c)所示。再对取反后的单方向笔画进行快速细化处理,处理后的笔画图像如图3(d)所示。本文的笔迹鉴别方法特征提取目标为字符横、竖、撇、捺四个方向的笔画,因此不必考虑原始样本笔迹图像中字符的数量、内容、版式等因素[6-7]。

图3 单方向笔画骨架提取
2.2 笔画特征提取
对于只包含单方向笔画骨架的图像,可以发现稳定的单方向细化笔画都是一段类圆弧的曲线,其曲率特征是稳定的。对四个方向笔画进行圆重构,提取曲率特征组合生成笔画特征矩阵,在反映个人笔迹特征的同时,也保证了特征的独特性[8-9]。以撇方向为例,在3(c)图像中的撇方向笔画骨架图像上选取二等分三个点进行圆的重构,其过程为:
(1) 从上到下,从左到右依次扫描图像上各点(x,y),若当前点为黑色点时,再判断该点周围八个点像素值的和M(设黑色点像素值为1,白色点像素值为0),设T为提取点的标识,T=1时提取该标识点坐标,当像素值P(x,y)=1时,计算该点的T值如式(2)所示。
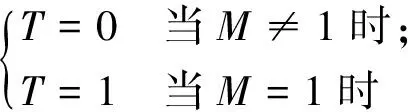
(2)
(2) 经过第一步可以提取弧线的两个端点A(x0,y0),B(x1,y1),连接A、B两点,得到线段L0,过的L0中点作直线L0的垂线L1,取L1与弧线的交点C(x2,y2),则A、B、C就是使弧线二等分的三个点。
得到A、B、C三点后,进行圆的重构并计算撇方向圆的半径,将半径长度r的倒数c作为可以反映撇方向笔画特征的特征值保存至笔画特征数据组,曲率c的计算过程如式(3)所示,其中,l1、l2、l3分别为三角形ABC的三个边长,p为三角形半周长。
(3)
通过以上运算可以计算单笔画方向圆的曲率,选取笔画骨架二等分三个点可尽量避免笔画骨架上相邻三点共线的情况,当出现三点共线时,曲率c的值为0。实验结果表明,不同个体的笔迹在单方向笔画骨架重构圆时,其曲率的差异是非常明显的。对竖方向笔画图像、撇方向笔画图像、捺方向笔画图像依次进行同样的处理,分别保存对应的单方向笔画特征值,依次对十幅样本图像作以上步骤循环处理,得到每幅笔迹样本图像的笔画特征值[10]。
2.3 生成笔迹特征矩
本文提出的方法在笔迹鉴别过程中,要求的最小的字符数量为30个,由于对字符的内容没有任何要求,所以难免会出现点、横折、竖勾误识成撇、捺等现象。当误识别现象发生时,提取笔画的曲率数据大小会出现大幅变化,从而降低鉴别成功率。
针对此类现象,本文提出了笔迹特征矩阵的生成方法,流程如图4所示,主要为对同一笔迹作者采集30个待鉴别笔迹字符,再将30个待鉴别笔迹字符均分成十幅样本图像,每幅样本图像包含三个字符,提取特征的目标为三个字符中连通域面积最大的四个方向笔画,从而保证特征的显著性,提取每幅样本图像的四个方向的曲率特征后,对每个单方向所有样本图像特征数据进行处理,剔除每个单方向数值大小突变的异常数据后,分别取横、竖、撇、捺四个方向的归一化曲率均值作为该方向的笔迹特征值,按顺序保存至相应笔迹作者的1*4笔迹特征矩[11]。
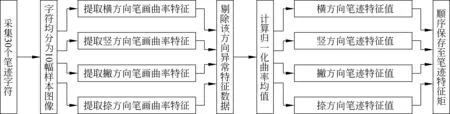
图4 笔迹特征矩生成流程图
其中四个方向笔迹特征值的计算包括剔除单方向笔画异常特征数据及计算归一化曲率均值,其过程是先将十幅笔迹样本图像单方向的笔画特征值汇集组成该方向的笔画特征数据组,将处于单方向笔画特征数据组极大端和数据组极小端的数据剔除,取数据组中段均值数据作为该方向笔画的最终特征值,依次取得四个方向的最终特征值后,组成笔迹特征矩阵,将笔迹特征矩阵的值归一化至-1到1之间,再将笔迹特征矩阵保存至相似性度量模块[12]。该方法流程如图5所示,其中n的数值(1、2、3、4)依次代表笔画方向横、竖、撇、捺。
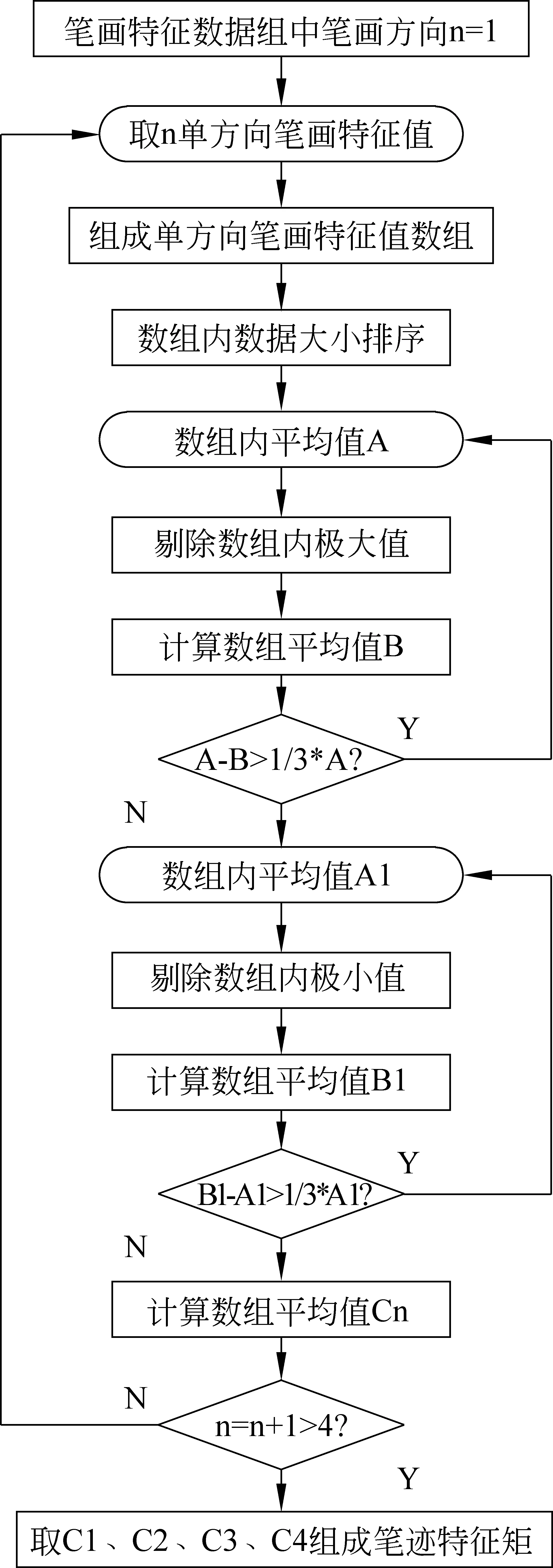
图5 笔迹特征值计算方法流程图
单幅实验样本图像的三个字符中不包含某个方向笔画时,就会出现点、横折、竖勾误识成撇、捺等现象,通过对十幅样本图像某方向笔画特征数据进行处理,剔除异常的特征数据后再计算均值作为该方向的笔迹特征值,也就是间接地删除了不包含该方向笔画的样本图像,降低了误识现象发生的几率,提高了本文方法的鲁棒性[13]。
2.4 相似性度量
夹角余弦相似性度量可以用在任何维度的向量比较中,尤其在高维正空间中尤为频繁。其主要优点为可以将多个特征值组成特征组向量,在高维空间中快速计算向量之间相似度,并且可根据实际情况,改变向量元素的权重系数,得到更加准确的相似度,适合特征矩阵的相似性判别。
针对本文提出的笔迹鉴别算法,设由待鉴别笔迹特征矩组成的向量可表示为F=(x10,x11,x12,x13),数据库中预先存储笔迹作者的笔迹特征矩组成的向量为λ=(x20,x21,x22,x23),其中xij为单方向笔迹特征值,角标i的数值代表笔迹特征矩的性质,角标j的取值依次代表笔画方向横、竖、撇、捺。设K为待鉴别的笔迹与数据库中对应的笔迹相似度,则定义K为式(4)。
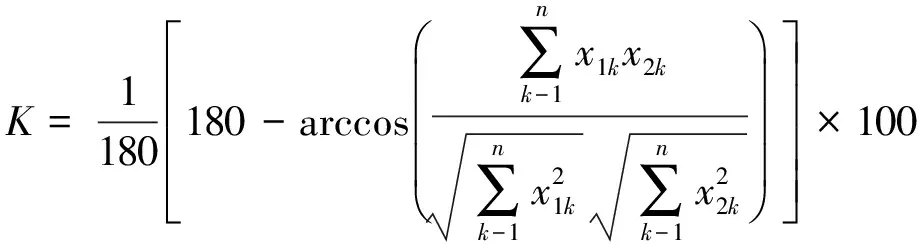
(4)
本文提出的鉴别方法对样本笔迹字符的形态尺寸没有要求。笔迹特征是在同一笔迹样本图像中提取的横、竖、撇、捺四个方向特征值组合的特征矩阵向量的方向,采用夹角余弦相似性度量法可以有效避免笔迹字符的形态尺寸带来的影响。
3 笔迹鉴别实验结果
本文选取了100个人建立手写文本库,其中每个人有两份笔迹样本,每份样本字符数量为450个,对版式、尺寸、内容均无要求。将每个人两篇笔迹中的一篇作为参考笔迹,另一篇作为查询笔迹。在笔迹数据库中,每篇查询笔迹都与所有参考笔迹进行比较,获取它们之间的相似度,通过对相似度数值进行排序,可以得到相似度数值最大的参考笔迹,该参考笔迹的作者即认为是查询笔迹的书写者[14-15]。
随机抽取十个人的查询笔迹a0~j0与参考笔迹a1~j1,按照本文方法对笔迹样本进行相应的处理,再对本文选取的实验方法及过程进行模拟,实验结果统计表如表1所示,可以看出,采用本文提出的鉴别方法进行笔迹鉴别时,首选正确率较高。
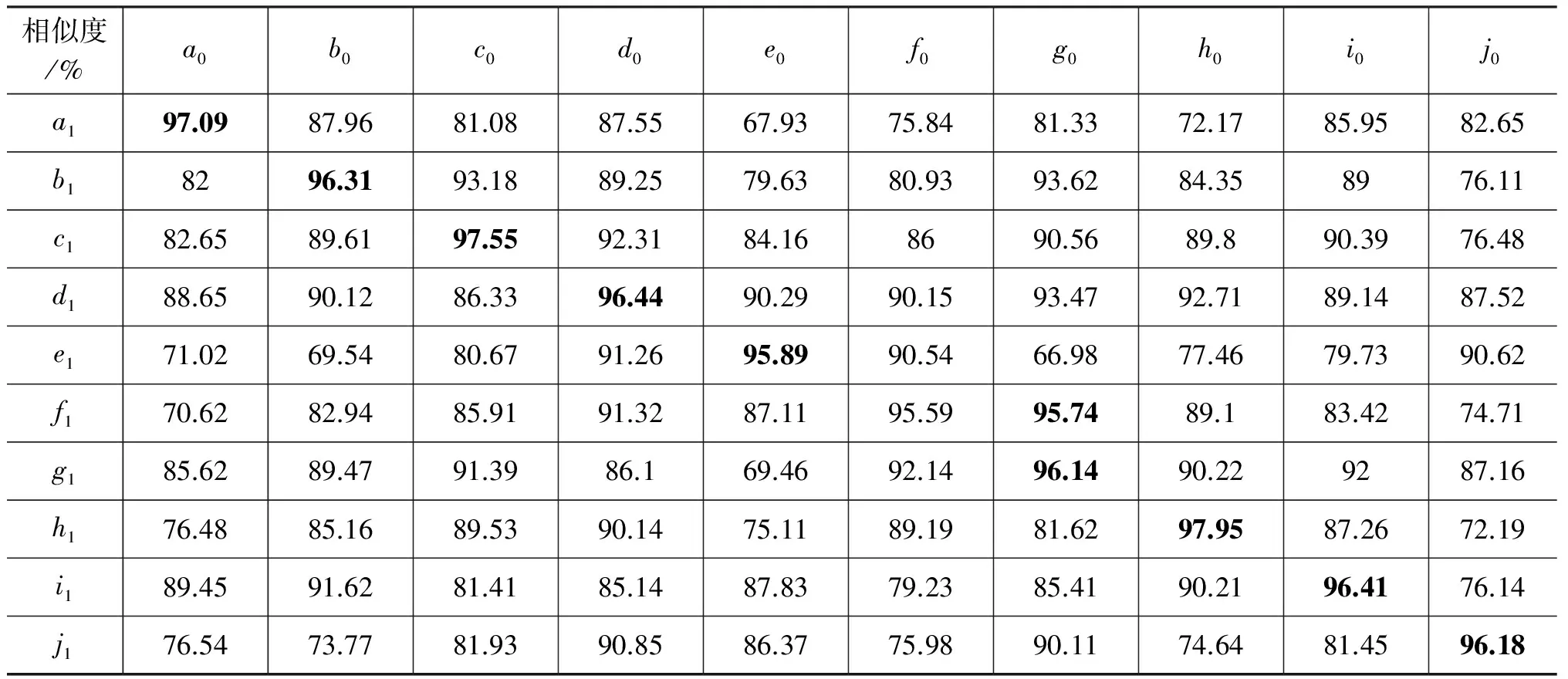
表1 相似性度量实验结果
与文献[2]、文献[3]、文献[4]中的方法进行比较,分别对现有的三种方法进行测试,其中笔迹作者判断方法与本文相同。初始测试笔迹样本的字符数量都为450个,测试过程中规律性减少字符数量(每次15个),当鉴别正确率发生突变时(设定阈值为3%),即认为当前笔迹样本字符数量即为该种方法要求的最小字符数量,实验结果如表2所示。
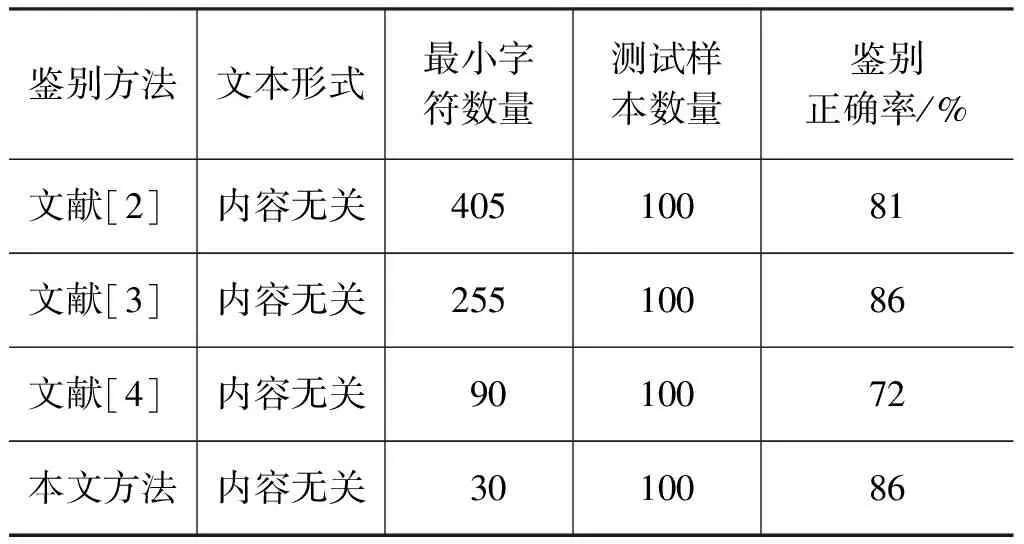
表2 多种方法笔迹鉴别结果
4 总结与分析
本文以中文字符的结构与形态为出发点,提取中文字符笔画的特征,为与内容无关的计算机中文笔迹鉴别提供了新的思路和方法。该方法特征主要是拆分提取手写字符横、竖、撇、捺四个方向的笔画骨架,并取其笔画骨架特征数据组中段均值作为此方向的笔迹特征值组成笔迹特征矩,再进行相似性度量。与现有的笔迹鉴别方法相比,本文提出的基于笔画骨架曲率检测的笔迹鉴别方法降低了对笔迹样本字符数量与形态版式的依赖,且有较高的鉴别正确率。
[1] 黄海龙, 王宏, 李微. 一种基于数学形态学的签名真伪鉴别方法[J]. 东北大学学报(自然科学版), 2011, 32(6): 854-858.
[2] 陈睿, 唐雁. 基于关键词提取的手写汉字文本依存笔迹鉴别技术[J]. 四川大学学报(自然科学版), 2013, 50(4): 720-727.
[3] 李昕, 丁晓青, 彭良瑞. 一种基于微结构特征的多文种文本无关笔迹鉴别方法 [J]. 自动化学报, 2009, 35(9): 1199-1208.
[4] 鄢煜尘, 陈庆虎, 袁凤, 等. 基于特征融合的脱机中文笔迹鉴别[J]. 模式识别与人工智能, 2010, 23(2): 203-209.
[5] 梅园, 孙怀江, 夏德深. 一种基于改进后模板的图像快速细化算法[J]. 中国图象图形学报, 2006, 11(9): 1306-1310.
[6] 柯晶, 乔谊正. 联机中文签名鉴定的一种局部弹性匹配方法[J]. 中文信息学报, 1998, 12(1): 57-63.
[7] 刘成林, 戴汝为. 笔迹鉴别的字符予处理与匹配[J]. 中文信息学报, 1996, 10(3): 50-57.
[8] Zamora Martínez F, FrinkenV, Espana Boquera S, et al. Neural network language models for off-line handwriting recognition[J]. Pattern Recognition, 2014, 47(4): 1642-1652.
[9] 张韦煜, 卡米力, 木依丁. 基于边缘笔画特征结构的维吾尔笔迹鉴别[J]. 计算机应用, 2012, 32(06): 1594-1597.
[10] Schomaker L, Bulacu M. Automatic writer identification using connected-component contours and edge-based features of uppercase western script[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(6): 787-798.
[11] 热依曼, 吐尔逊, 吾守尔, 等. 一种维吾尔语联机手写识别系统[J]. 中文信息学报, 2014, 28(3): 112-115.
[12] 芮挺, 沈春林, 丁健, 等. 独立分量重建模型的手写数字字符识别[J]. 计算机辅助设计与图形学学报, 2005, 17(3): 455-455.
[13] Ferrerma, Alonso J B, Travieso C M. Offline geometric parameters for automatic signature verification using fixed-point arithmetic[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(6): 993-997.
[14] 黄雅平, 罗四维, 陈恩义. 基于独立分量分析的笔迹识别[J]. 中文信息学报, 2003, 17(4): 52-58.
[15] 刘成林, 刘迎建, 戴汝为. 基于多通道分解与匹配的笔迹鉴别研究[J]. 自动化学报.1997, 23(1): 56-62.
Method of Writer Identification Based on Curvature of Strokes
LI Qingwu1,2,MA Yunpeng1,ZHOU Yan1,2,ZHOU Liangji1
(1. College of Internet of Things Engineering, HoHai University, Changzhou, Jiangsu 213022, China 2. Changzhou Key Laboratory of Sensor Networks and Environmental Sensing, Changzhou,Jiangsu 213022, China)
The popular offline writer identification methods for handwritten Chinese characters usually work on some specific characters and demand a huge number of training samples. In this paper, a writer identification method based on curvature detection of skeletal stroke is proposed. Firstly, images of handwritten characters are preprocessed by mathematical morphology, and the representative skeletal strokes are extracted in the four directions of horizontal, vertical, left-falling and right-falling. Then, the circle reconstruction is applied to the extracted skeletal strokes, and the curvatures of the stroke circle in four directions are selected to form the handwriting features. Finally, the characters are identified according to the angular similarity. Experimental results show that the proposed algorithm makes no restrictions on the content of the character to be identified and requires less training samples.
writer identification; mathematical morphology; reconstruct the circle of strokes; curvature of strokes; similarity between angles

李庆武(1964—),博士,教授,博士生导师,主要研究领域为智能感知与图像处理。E⁃mail:li_qingwu@163.com马云鹏(1993—),博士研究生,主要研究领域为数字图像处理。E⁃mail:1102203011@qq.com周妍(1982—),博士研究生,讲师,主要研究领域为数字图像处理。E⁃mail:strangeryan@163.com
1003-0077(2016)05-0209-06
2015-10-25 定稿日期: 2016-04-25
国家自然科学基金(41306089);江苏省产学研前瞻性联合研究项目(BY2014041)
TP394.1
DOI
猜你喜欢
少儿科技(2021年3期)2021-01-20
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
职工法律天地(2018年10期)2018-01-22
北京航空航天大学学报(2017年4期)2017-11-23
中成药(2017年3期)2017-05-17
中国司法鉴定(2015年4期)2015-02-28
中国医学科学院学报(2014年6期)2014-03-11
