
基于查询性能预测的鲁棒检索排序研究
2016-05-04 02:43薛源海俞晓明程学旗
中文信息学报 2016年5期
薛源海,俞晓明,刘 悦,关 峰,程学旗
(1. 中国科学院网络数据科学与技术重点实验室,北京 100190;2. 中国科学院 计算技术研究所,北京 100190; 3. 中国科学院大学,北京 100190)
基于查询性能预测的鲁棒检索排序研究
薛源海1,2,3,俞晓明1,2,刘 悦1,2,关 峰1,2,3,程学旗1,2
(1. 中国科学院网络数据科学与技术重点实验室,北京 100190;2. 中国科学院 计算技术研究所,北京 100190; 3. 中国科学院大学,北京 100190)
信息检索技术致力于从海量的信息资源中为用户获取所需的信息。相较于传统的简单模型,近些年来的大量研究工作在提升了检索结果平均质量的同时,往往忽略了鲁棒性的问题,即造成了很多查询的性能下降,导致用户满意度的显著下降。本文提出了一种基于排序学习的查询性能预测方法,针对每一个查询,对多种模型得到的检索结果列表进行预测,将其中预测性能最优的检索结果列表展示给用户。在LETOR的三个标准数据集OHSUMED、MQ2008和MSLR-WEB10K上的一系列对比实验表明,在以经典的BM25模型作为基准的情况下,与当前最好的检索模型之一LambdaMART相比,该方法在提升了检索结果平均质量的同时,显著地减少了性能下降的查询的数量,具备较好的鲁棒性。
查询性能预测;排序学习;鲁棒检索排序
1 引言
我们身处于一个信息爆炸的时代,而信息检索技术正是解决信息爆炸问题最为有效的技术手段之一[1]。各类信息检索模型相继被提出并投入到实际应用中,主要包括向量空间模型、传统概率模型、统计语言模型以及排序学习模型等。与此同时,查询扩展、伪相关反馈以及查询性能预测等技术也大量出现,致力于提高检索结果的质量。然而,对于相对简单的模型或技术来说,日益复杂的方法在提升了检索结果平均质量的同时,往往忽略了检索结果鲁棒性的重要性。
在真实的应用场景中,相对于性能提升的查询,用户对失败的查询更加敏感,更容易记住不好的查询体验。这就要求相较于基准的检索结果,在提升其平均质量的同时,还要尽量避免引入太多额外的风险,即造成其中某些查询的检索结果质量大幅下降。虽然高收益总是不可避免地伴随着高风险,但是各种检索模型之间却具备一定的互补性,本文将基于查询性能预测技术,融合多种检索模型的优势,致力于实现收益与风险之间的优化平衡。
本文组织如下: 第二节分别对检索排序的鲁棒性以及查询性能预测进行了回顾;第三节提出了基于排序学习的查询性能预测方法并阐述了基于该方法实现具有鲁棒性的检索排序算法;第四节介绍了实验环境并对实验结果进行了分析;第五节给出了对本文工作的总结以及未来的研究方向。
2 相关工作
2.1 鲁棒的检索排序
虽然大量致力于提升检索排序结果质量的技术相继被提出,但是相对于简单的基准方法来说,这些研究从总体上看在平均性能上得到了大幅提升的同时,却也引入了额外的风险,即造成某些查询性能的下降甚至是查询失败。检索排序的鲁棒性开始被关注,即相对于某种基准排序,如何在提升平均查询性能的同时,最小化在任意一个查询上产生的风险。
为不同的查询建立个性化的模型是有效控制风险的途径之一。文献[2]基于K近邻的方法,针对每一个查询,使用训练集中与其最相近的邻居进行训练,得到查询独立的排序函数。文献[3]使用聚类的方法,通过分而治之的策略训练得到查询独立的排序模型。文献[4]将查询分类,对于不同种类的查询,分别使用不同的损失函数进行优化训练,也取得了不错的效果。
一些研究工作针对adhoc检索提出了具备风险意识的排序算法,文献[5]和文献[6]对检索排序的不确定性等因素进行了分析建模,以达到控制检索风险的目的。面向多目标优化的排序学习算法也相继被提出,文献[7]提出了同时考虑文档新鲜度以及相关性的多目标排序学习算法,文献[8]则是将传统的相关性指标NDCG作为主要优化目标,将通过点击数据获得的伪相关反馈作为次要优化目标进行训练学习,文献[9]提出了一种能够刻画检索性能与鲁棒性之间平衡的指标,将该指标应用到排序学习算法中,在取得较好的平均性能的同时,减少了查询失败的数量。
本文将从另一个角度出发,使用排序学习算法对多种检索模型得到的结果列表进行相对性能好坏的预测,并根据预测结果得到平均性能好且具备鲁棒性的检索排序结果。
2.2 查询性能预测
不同的用户给出的不同查询的检索结果质量,往往具有很大的差异性。查询性能预测技术致力于在缺乏相关性标注的情况下,对某一查询返回的检索结果质量进行估计。目前,针对查询性能预测技术的研究大致可分为两类: 基于检索前的方法(Pre-retrieval predictors)和基于检索后的方法(Post-retrieval predictors)。
基于检索前的方法完全不关心检索返回的结果列表,而仅仅对查询本身进行分析,同时利用待检索数据集的统计信息进行估计。这些方法主要着眼于一个查询到底具备多强的区分力,其是否足够将待检索数据集中的相关文档以及不相关文档区分开来。利用查询词项的逆文档频率(IDF)进行预测是该类方法的主流策略,它们分别尝试了使用查询词项IDF的平均值、标准方差以及某种变形来预测查询的性能[10-12]。这些方法虽然都具有一定的效果,但均无法较好地对查询性能进行预测。
基于检索后的方法在上述方法的基础上,进一步对检索返回的结果列表进行了分析,包括返回的结果列表中各文档间的相关关系以及其与整个文档集之间的关系等。文献[13]基于查询和整个文档集两个语言模型之间的KL距离,提出了Clarity score的方法,是早期成功预测了查询性能的方法之一。文献[14]等很多工作是其优化后的版本。文献[15]提出了一种基于决策树的预测方法,其简单易实施,却非常依赖于有限的训练数据集。文献[16]提出了一个新的概念Robustness score,用于度量检索返回文档集列表的稳定性,实验验证了加入噪音后,检索结果列表的稳定性与查询的性能有着很强的相关性。文献[17]提出了WIG的统计量,并利用检索返回结果与整个文档集之间的状态差异来估计查询的性能,取得了不错的效果。文献[18]提出了基于CTS的预测方法,其刻画了用户查询主题在检索结果中的覆盖度,覆盖度越高,则说明该查询的检索结果质量越高。近年来的一些研究也表明,利用检索结果列表的文档得分可以有效地进行查询性能预测,如文献[19]使用检索结果列表文档得分的标准方差进行了较成功的查询性能预测。文献[20]则讨论了在多检索结果列表融合场景下的查询性能预测问题。
上述的查询性能预测研究,多是着眼于预测查询结果质量的绝对好坏,而本文将针对同一查询,对不同检索结果列表质量的相对好坏程度进行预测,最终致力于得到具有更好鲁棒性的检索排序算法。
3 基于查询性能预测的鲁棒检索排序算法
在真实的信息检索应用场景中,无论是用户本身以及提交的查询,还是其最终的信息需求,往往都存在着极大的多样性和不确定性,这是导致单一检索排序模型难以具备较好的鲁棒性的主要原因之一。
以往的研究大多致力于提升查询集检索结果的平均质量,而忽略了鲁棒性的问题,结果导致大量查询的检索结果质量得到了提升,也确实提升了整个查询集检索结果的平均质量,但不可避免的以部分查询的检索结果质量下降甚至是大幅下降作为代价。以应用最为广泛的BM25模型和排序学习算法LambdaMART为例,在三个标准数据集OHSUMED、MQ2008和MSLR-WEB10K上的测试结果如图1所示。显而易见,以BM25为基准,LambdaMART虽然大幅提升了检索结果的平均质量,但在三个数据集上,均造成了大量查询的检索结果质量下降,甚至于有10%左右的查询结果质量下降幅度超过25%。既然LambdaMART在部分查询上的表现不如BM25,那么在这些查询上,其他检索模型的表现又如何呢?本文引入了布尔模型、向量空间模型以及语言模型等,测试结果如图2所示。
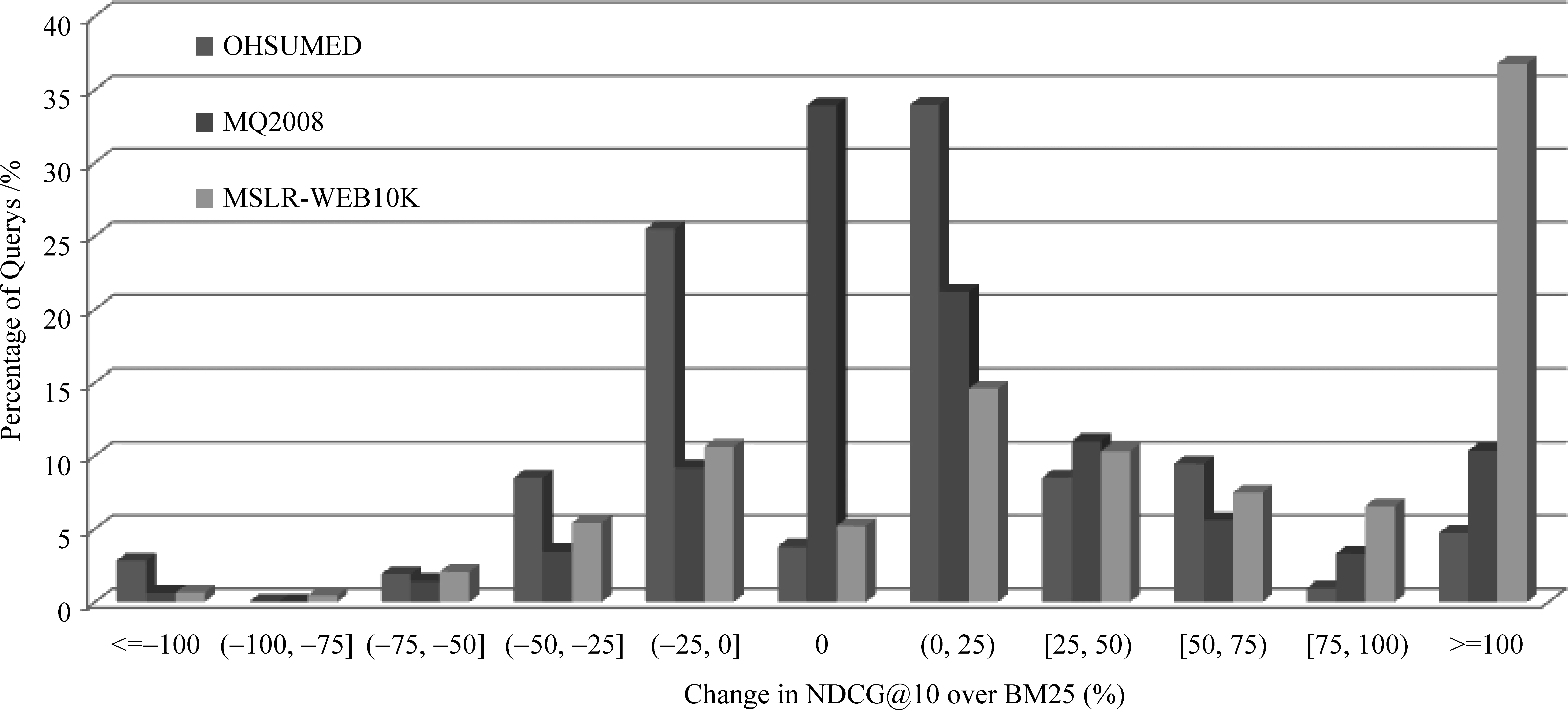
图1 基于BM25,LambdaMART的鲁棒性问题
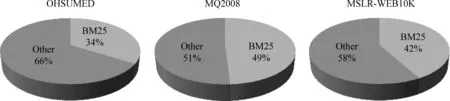
图2 在LambdaMART不如BM25的查询上,表现最好的模型分布
本文的目标是,给定一组基准的检索结果列表,构造一组新的检索结果列表,使其相对于基准结果来说,平均性能有所提升的同时,避免在任意一个单独的查询上,性能有大幅下降。而从图2中可以看到,在LambdaMART的表现不如BM25的查询中均有至少50%以上的查询,存在比BM25表现更好的模型。针对同一个待检索文档集以及同一组查询,不同检索模型的表现各不相同且各种模型之间存在一定的互补性。于是本文提出了基于查询性能预测的鲁棒检索排序算法,择优录用不同模型的检索结果,预期在不明显影响平均性能的同时,显著减少性能下降的查询数,提高最终检索结果的鲁棒性。其具体流程如下:
1) 针对已标注的每一个查询,使用多种检索模型得到多个结果列表;
2) 使用给定的评价指标对各个结果列表的性能打分并从小到大排序,构造基于(查询—结果列表)对的特征向量,并以排序序号对其进行性能等级标注,得到训练集;
3) 在训练集上使用排序学习算法训练得到用于预测结果列表性能的排序模型;
4) 对于新的未标注查询,使用多种检索模型得到多个候选结果列表,然后利用学习得到的排序模型对其进行排序,选择排序最靠前的结果列表作为最终结果列表。
本节接下来将分别从基础符号定义、基于(查询-结果列表)对的特征向量构造以及性能预测模型的学习三个方面进行详细阐述。
3.1 基础符号定义
1) 查询集大小为n,记为Q= {q1,q2, …,qn};
2) 文档集大小为N,记为D= {d1,d2, …,dN};
3) 检索模型集大小为m,记为Model= {M1,M2, …,Mm},基准模型Mbase∈Model;
4) 针对查询qi,检索模型Mj得到的结果列表包含K个文档,记为Lij= {d1,d2, …,dK};
5) 基于(qi-dj)对的特征向量为FQDij,基于(qi-Lij)对的特征向量为FQLij。
3.2 基于(查询-结果列表)对的特征向量构造
本文使用检索结果列表中的文档所对应的基于(查询-文档)对的特征向量FQD构造基于(查询-结果列表)对的特征向量FQL,其中FQD由Y个特征组成,记为{f1,f2, …,fY}。本文主要尝试了两大类构造方法: 基于组合的方法和基于融合的方法。
3.2.1 基于组合的方法
基于组合的方法最为直接简单,即将检索结果列表中各文档所对应的FQDk直接顺序拼接得到FQL,则基于组合的方法(Combination)构造的FQL如式(1)所示。
(1)
由此构造得到的FQL所包含的特征维数将是FQD的K倍。
3.2.2 基于融合的方法
与基于组合的方法不同,基于融合的方法则不会造成特征维数的增长。该方法通过将检索结果列表中的K个文档所对应的FQDk进行线性加权得到FQL,则基于融合的方法构造的FQL如式(2)所示。
(2)
其中,FQDk为在该列表中排在第k位的文档所对应的FQD,而Wk为其权重。由此构造得到的FQL与FQD具有相同特征维数,且各个特征之间一一对应。
本文将尝试使用三种函数对权重Wk进行计算,它们分别如式(3)~式(5)所示。
• 反比例函数(Inverse):
(3)
• 余弦函数(Cosine):
(4)
• 三角形函数(Triangle):
(5)
其中,K为检索结果列表的大小,即包含的文档数,k∈[1, K]。
3.3 性能预测模型的学习
本文选择基于list-wise的排序学习算法LambdaMART[21]训练性能预测模型,提出了名为风险规避值的性能预测评价指标作为其优化目标。
3.3.1FQL的性能等级(Ground truth)标注
本文使用NDCG@10作为检索结果的性能评价指标。给定查询q及其候选结果列表集List= {L1,L2, …,Lm},分别对各列表进行打分,记为P(Li),按照P(Li)将其从小到大排序,再按照Li所处的位置对其进行性能等级(Ground truth)标注,记为G(Li),如式(6)所示。
(6)
3.3.2 风险规避值(Risk-Averse)
给定查询q及其候选结果列表的排序RankList={L1,L2, …,Lm},记该结果列表排序的风险规避值为RA(q,RankList),计算公式如式(7)所示。
(7)
其中,α的取值范围为[0, 1),β的取值范围为(1, ∞)。使用LambdaMART,以RA(q,RankList)最大化为优化目标,训练学习得到性能预测模型。最终使用该模型对用户提交的查询的多个候选结果列表进行排序,以预测性能最优的那个结果列表作为最终呈现给用户的结果列表。
4 实验结果
4.1 测试数据集
本文在LETOR[22]的三个标准数据集上进行了一系列的实验。这些数据集在大小和内容上各有不同,均是被研究者广泛使用的公开数据集。它们都被预先分为了五组,各组中都包含了对应的训练集、验证集以及测试集,可以方便地进行五折交叉验证。各数据集的相关信息如表1所示。
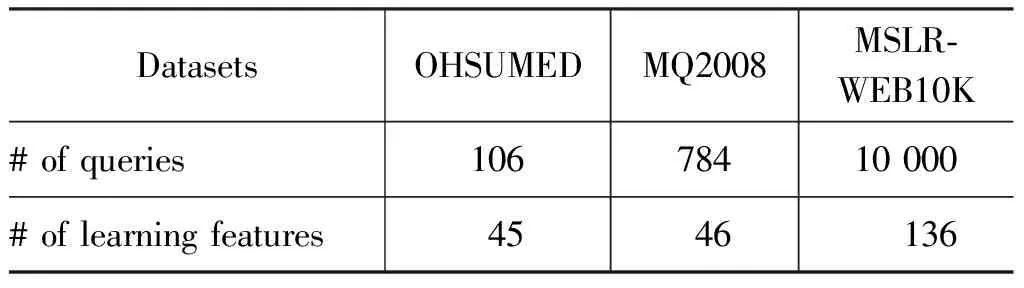
表1 测试数据集概况
本文使用到的检索模型包含TF-IDF、布尔模型、向量空间模型、BM25、LMIR.ABS、LMIR.DIR、LMIR.JM以及LambdaMART,其中,除了LambdaMART,其余模型均直接使用数据集中对应的特征值对候选文档进行排序。本文实验中在各数据集上所使用的检索模型集以及其中各模型所对应的特征号如表2所示。
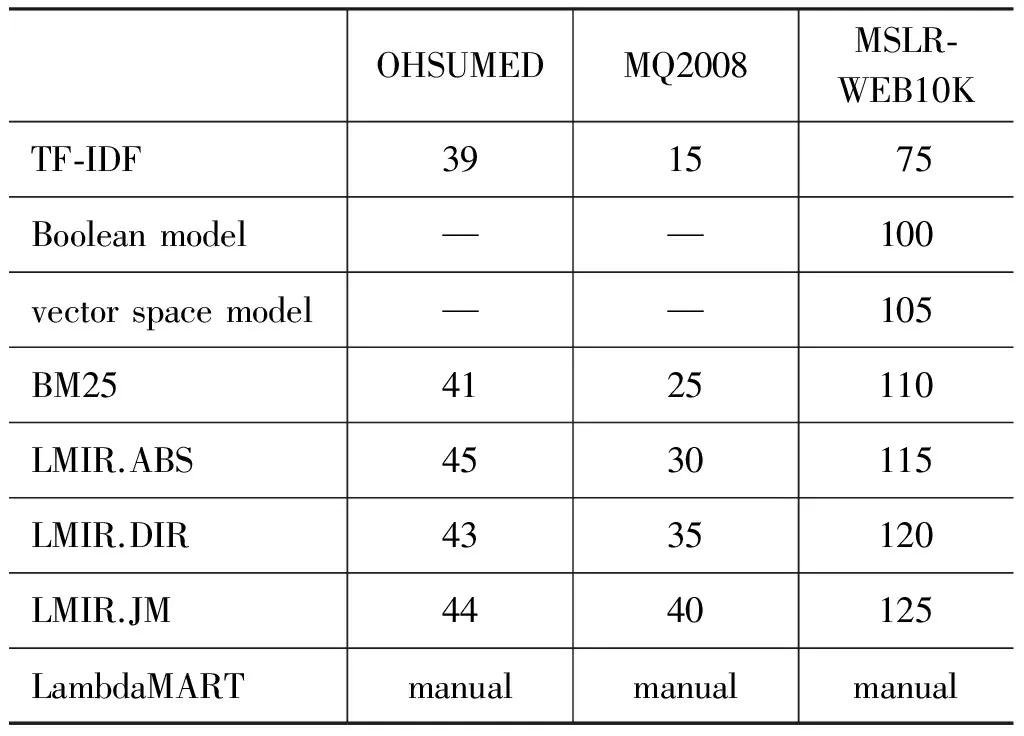
表2 各测试数据集上使用的模型集及其中各模型对应的特征号
注: “—”表示未使用;LambdaMART的参数通过网格搜索和在验证集上的结果进行最优设定。
4.2 实验结果概要
本文使用当前应用广泛的排序学习模型之一LambdaMART作为参照,考察相对于BM25模型,上述提出的鲁棒排序算法在平均性能以及鲁棒性方面的表现。本文使用NDCG@10作为检索结果的相关性评价指标,以BM25模型作为基准的排序模型。鲁棒排序算法分别使用四种基于(查询-结果列表)对的特征向量构造方法,在OHSUMED,MQ2008以及MSLR-WEB10K三个标准数据集上进行了实验,其中各参数通过网格搜索和在验证集上的结果进行最优设定。实验结果概要如表3所示,其中“# of Losses”指相对于BM25模型,性能下降的查询数,数目减少超过5%的结果被加粗显示。
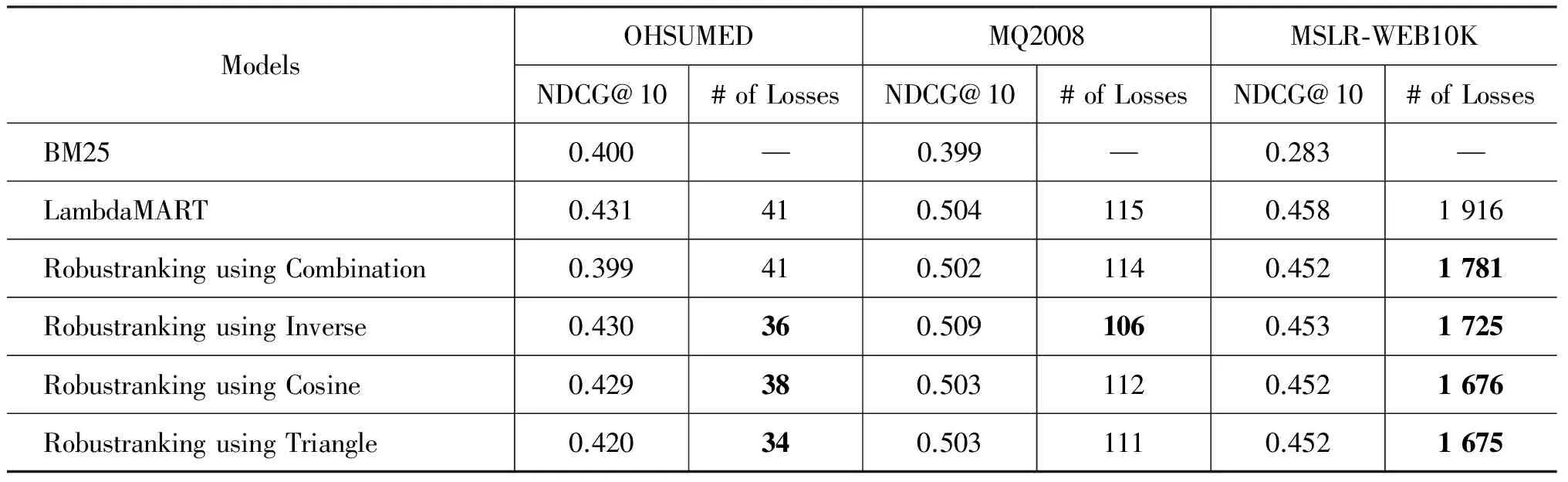
表3 鲁棒排序算法与LambdaMART模型在不同数据集上的对比
可以看到,在三个数据集上,相较于LambdaMART,通过鲁棒排序算法得到的结果,均显著地减少了性能下降的查询数,与此同时,平均性能仅略微下降,与预期相符。四种特征向量构造方法在各个数据集上各有优劣,但总体效果都非常不错,这也验证了该算法的有效性,其对特征向量的构造方法并不特别敏感。值得注意的是,当使用基于反比例函数的融合方法时,不仅是显著减少了性能下降的查询数,而且平均性能在OHSUMED上与LambdaMART基本持平,在MQ2008上甚至比LambdaMART还有了进一步的提升。
4.3 性能下降的查询的性能下降幅度分布
同样是性能下降,但下降幅度的大小对于用户体验来说也是至关重要的,性能的大幅下降往往是用户不可接受的。以MSLR-WEB10K为例,将性能下降的查询按照下降幅度分为五个区间进行统计,结果如图3所示。
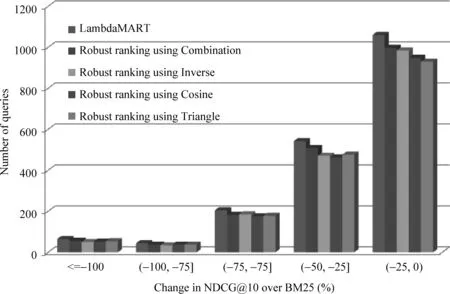
图3 LambdaMART与鲁棒排序算法在MSLR-WEB10K上的性能下降查询的下降幅度分布
显而易见,无论使用哪种特征向量的构造方法,在任何一个性能下降幅度区间内,鲁棒排序算法的结果均要明显优于LambdaMART,各区间内的查询数均大幅减少,具备更好的鲁棒性。
4.4 对查询失败的控制
若某一个查询,当使用基准检索模型所得到的结果列表时,能够获取到相关文档(性能指标非零),而使用当前新的结果列表时,无法获取到相关文档(性能指标为零),则本文称该查询失败。在真实的应用场景中,查询失败对于用户来说往往是不可接受的,有极大的可能性将导致用户的流失,所以,对查询失败的控制是极为重要的。依旧以MSLR-WEB10K为例,LambdaMART与鲁棒排序算法的查询失败数对比如表4所示,鲁棒排序算法在对查询失败的控制上显著优于LambdaMART,将查询失败数减少了超过10%。

表4 LambdaMART与鲁棒排序算法在MSLR-WEB10K上的查询失败数对比
5 总结与展望
本文对信息检索系统的鲁棒性进行了研究,通过利用多种检索模型的互补性,提出了一种基于查询性能预测的鲁棒排序算法并在LETOR的3个标准数据集上进行了实验验证与分析。实验结果表明,与LambdaMART相比,本文提出的方法能够在几乎不影响平均性能的同时,大幅提升鲁棒性,特别是使得查询失败的概率显著减小,更能适应实际应用的需求。
在今后的工作中,希望能够提出更多有用的基于(查询-结果列表)对的特征,进一步优化查询性能预测方法以及最终的结果选择策略。此外,如何更好地将平均性能以及鲁棒性进行统一的综合评价也是未来的研究方向。
[1] Baeza Yates R, Ribeiro Neto B. Modern information retrieval[M]. New York: ACM press, 1999.
[2] Geng X, Liu T Y, Qin T, et al. Query dependent ranking using k-nearest neighbor[C]//Proceedings of the 31st annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 2008: 115-122.
[3] Bian J, Li X, Li F, et al. Ranking specialization for web search: a divide-and-conquer approach by using topical RankSVM[C]//Proceedings of the 19th international conference on World wide web. ACM, 2010: 131-140.
[4] Bian J, Liu T Y, Qin T, et al. Ranking with query-dependent loss for web search[C]//Proceedings of the third ACM international conference on Web search and data mining. ACM, 2010: 141-150.
[5] Wang J, Zhu J. Portfolio theory of information retrieval[C]//Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval. ACM, 2009: 115-122.
[6] Zhu J, Wang J, Cox I J, et al. Risky business: modeling and exploiting uncertainty in information retrieval[C]//Proceedings of the 32nd international ACM SIGIR conference on research and development in information retrieval. ACM, 2009: 99-106.
[7] Dai N,Shokouhi M, Davison B D. Learning to rank for freshness and relevance[C]//Proceedings of the 34th International ACM SIGIR conference on Research and development in Information Retrieval. ACM, 2011: 95-104.
[8] Svore K M, Volkovs M N, Burges C J C. Learning to rank with multiple objective functions[C]//Proceedings of the 20th international conference on World wide web. ACM, 2011: 367-376.
[9] Wang L, Bennett P N, Collins-Thompson K. Robust ranking models via risk-sensitive optimization[C]//Proceedings of the 35th international ACM SIGIR conference on research and development in information retrieval. ACM, 2012: 761-770.
[10] Tomlinson S. Robust, web and terabyte retrieval with HummingbirdSearchServertm at TREC 2004[C]//Proceedings of the 13th Text Retrieval Conference.2004.
[11] He B,Ounis I. Inferring query performance using pre-retrieval predictors[C]//Proceedings of String processing and information retrieval. Springer Berlin Heidelberg, 2004: 43-54.
[12] Plachouras V, He B, Ounis I. University of Glasgow at TREC 2004: Experiments in Web, Robust, and Terabyte Tracks with Terrier[C]//Proceedings of the 13th Text Retrieval Conference.2004.
[13] Cronen Townsend S, Zhou Y, Croft W B. Predicting query performance[C]//Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 2002: 299-306.
[14] Hauff C, Murdock V, Baeza Yates R. Improved query difficulty prediction for the web[C]//Proceedings of the 17th ACM conference on Information and knowledge management. ACM, 2008: 439-448.
[15] Yom Tov E, Fine S, Carmel D, et al. Learning to estimate query difficulty: including applications to missing content detection and distributed information retrieval[C]//Proceedings of the 28th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 2005: 512-519.
[16] Zhou Y, Croft W B. Ranking robustness: a novel framework to predict query performance[C]//Proceedings of the 15th ACM international conference on information and knowledge management. ACM, 2006: 567-574.
[17] Zhou Y, Croft W B. Query performance prediction in web search environments[C]//Proceedings of the 30th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 2007: 543-550.
[18] Lang H, Wang B, Jones G, et al. Query performance prediction for information retrieval based on covering topic score[J]. Journal of Computer Science and technology, 2008, 23(4): 590-601.
[19] Cummins R. Predicting query performance directly from score distributions[M]. Information Retrieval Technology. Springer Berlin Heidelberg, 2011: 315-326.
[20] Markovits G, Shtok A, Kurland O, et al. Predicting query performance for fusion-based retrieval[C]//Proceedings of the 21st ACM international conference on information and knowledge management. ACM, 2012: 813-822.
[21] Wu Q, Burges C J C,Svore K M, et al. Adapting boosting for information retrieval measures[J]. Information Retrieval, 2010, 13(3): 254-270.
[22] Microsoft Research. LETOR[EB/OL]. http://research.microsoft.com/en-us/um/beijing/projects/letor/.
Robust Ranking via Query Performance Prediction
XUE Yuanhai1,2,3, YU Xiaoming1,2, LIU Yue1,2, GUAN Feng1,2,3, CHENG Xueqi1,2
(1. Key Laboratory of Network Data Science and Technology, Chinese Academy of Sciences, Beijing 100190,China; 2. Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190,China; 3. University of Chinese Academy of Sciences, Beijing 100190,China)
The main purpose of information retrieval technology is satisfying users information needs by using massive amounts of information recource. Recent years, many techniques increase average effectiveness relative to traditional simple model while they often ignore the robustness issue. Users satisfaction will be significantly hurt because of degraded results of many queries. A query performance prediction method based on learning to rank is proposed to obtain robust ranking results. For each query, the performance of multiple ranking results generated by different models are predicted and the best one is shown to the user. A series of experiments are conducted on three standard LETOR benchmark datasets which are OHSUMED, MQ2008 and MSLR-WEB10K. The results show that, compared to one of the state-of-the-art models named LambdaMART, the ranking results obtained this way significantly reduced the number of queries whose performance are hurt with respect to BM25 model while improving the nearly same degree of everage effectiveness.
query performance prediction; learning to rank; robust ranking

薛源海(1987—),博士,主要研究领域为信息检索和数据挖掘。E⁃mail:xueyuanhai@software.ict.ac.cn俞晓明(1977—),博士,高级工程师,主要研究领域为信息检索和大数据。E⁃mail:yuxiaoming@software.ict.ac.cn刘悦(1971—),博士,副研究员,主要研究领域为信息检索和数据挖掘。E⁃mail:liuyue@ict.ac.cn
1003-0077(2016)05-0169-07
2015-11-15 定稿日期: 2016-04-20
国家自然科学基金(61232010,61173008);国家“863”高技术研究发展计划(2012AA011003,2013AA01A213);国家“973”重点基础研究发展规划(2012CB316303,2013CB329602);国家科技部“十一五”科技计划(2012BAH39B02,2012BAH46B04)
猜你喜欢
名家名作(2021年4期)2021-05-12
小学生学习指导(中年级)(2021年4期)2021-04-27
科技研究·理论版(2021年22期)2021-04-18
课堂内外(初中版)(2020年5期)2020-06-19
科普童话·学霸日记(2020年1期)2020-05-08
农业机械学报(2020年2期)2020-03-09
中华建设(2019年7期)2019-08-27
小天使·一年级语数英综合(2019年2期)2019-01-10
电脑知识与技术(2016年28期)2016-12-21
中学生数理化·中考版(2015年10期)2015-09-10
