
基于属性主题分割的评论短文本词向量构建优化算法
2016-05-04 02:53李志宇周小平
中文信息学报 2016年5期
李志宇,梁 循,周小平
(中国人民大学 信息学院,北京 100872)
基于属性主题分割的评论短文本词向量构建优化算法
李志宇,梁 循,周小平
(中国人民大学 信息学院,北京 100872)
从词向量的训练模式入手,研究了基于语料语句分割(BWP)算法,分隔符分割(BSP)算法以及属性主题分割(BTP)算法三种分割情况下的词向量训练结果的优劣。研究发现,由于评论短文本的自身特征,传统的无分割(NP)训练方法,在词向量训练结果的准确率和相似度等方面与BWP算法、BSP算法以及BTP算法具有明显的差异。通过对0.7亿条评论短文本进行词向量构建实验对比后发现,该文所提出的BTP算法在同义词(属性词)测试任务上获得的结果是最佳的,因此BTP算法对于优化评论短文本词向量的训练,评论短文本属性词的抽取以及情感倾向分析等在内的,以词向量为基础的应用研究工作具有较为重要的实践意义。同时,该文在超大规模评论语料集上构建的词向量(开源)对于其他商品评论文本分析的应用任务具有较好可用性。
在线评论;短文本;词向量;相似度计算
1 引言
随着社会化商务的发展,在线评论已经成为了消费者进行网络购物的重要参考决策因素之一[1-2],同时也成为了包括计算机科学、管理科学以及情报分析等领域研究者在内的重要研究对象之一。通常而言,在线评论包括微博评论、商品评论、点评评论等评论类型,这里我们统称为“评论短文本”。以往关于评论短文本的应用研究主要集中在包括评论效用分析[3]、虚假评论识别[4-5]以及评论观点归纳[6]等方面。然而,这些应用研究往往都基于一个重要的语言模型基础,即统计语言模型。
相对于常规语料而言,如书籍、新闻、论文、维基百科等语料,评论短文本的语言学规范非常弱,省略、转义、缩写等现象非常普遍。如果利用传统的训练或者学习方法对评论短文本进行处理,效果并不理想。但从某种角度上来讲,评论短文本的在文法上的不规范,恰恰是另外一种形式的规范,即评论短文本自身特征的“规范”,由于评论短文本应用的普遍性,因此没有必要非要将评论短文本规约到常规的语料形式上进行处理,反之应该在最大限度上保留评论短文本的语料特征。
对于评论短文本的相关建模主要是从两个角度出发: 第一,利用TF-IDF,点互信息、信息增益等,对评论短文本进行建模,从而分析评论之间的相似度或评论的情感倾向等;第二,通过构建“词向量(词袋法)”,将评论文本词语数值化。但这类建模方式往往需要依赖于情感词典、属性词典等人工构造的相关词典,具有较强的领域性,同时可扩展性较差。
随着自然处理技术的发展,神经网络逐步被引入到相关的文本处理技术中。2013年,谷歌研究团队的开源的Word2vec词向量构建工具[7],引起了词向量应用研究热潮,被称为2013年最为重要的自然语言处理工具之一。随后,Word2vec作为词向量的转换工具被用于包括短文本情感分析[8-10]以及短文本相似度计算[1, 11]等相关自然语言处理任务。虽然Word2vec的应用范围广泛,但是研究者用其建模时,往往直接按照Word2vec的模型配置: 将每一条短文本语料(可能包含若干短句或长句)作为一个整体行进行输入。通常,在Word2vec的参数形式里面只考虑到了输入向量的维度、训练方法以及语料大小对模型造成的影响,却并没有考虑语料的输入形式对Word2vec模型训练结果造成的影响。我们研究发现,不同的评论短文本输入形式会对Word2vec的词向量训练结果造成明显的差异,因此有必要在Word2vec进行词向量训练前考虑输入语料本身的特征,对语料进行预处理后用以提升词向量的训练结果。
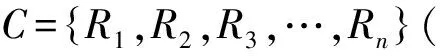
1) 通过对词向量的训练算法中的训练层进行改进,采用不同的训练模型或者不同类型的神经网络,来获得更为精准的词向量模型。
2) 通过在训练算法的输入层对语料进行预处理,提高算法训练的准确率和召回率。
3) 通过对词向量的输出层进行后处理,提升应用接口的准确度。
本文中,我们将集中讨论如何通过第二种方式,即在输入层如何对语料进行预处理来提升词向量模型训练的精度,研究包括基于整句分割模式的预处理模式、基于分隔符分割的预处理模式以及基于属性主题分割的预处理模式对于训练模型的影响。在后面小节中,我们将详细阐述这些方案,并重点论述基于属性主题分割模式的预处理算法。
2 相关研究工作与研究背景
2.1 评论短文本的情感分析与属性提取
短文本(Short Text)是指那些长度较短的文本形式。通常情况下,短文本的字符长度不超过400,例如,Twitter/微博短文本、手机信息短文本、在线评论短文本、BBS回复转帖短文本等[2, 12-13]。由于短文本具有字数少、信息聚合度高以及文本语言不规范等特征,使得针对短文本的分析与研究产生了较大的困难,其中具有代表性的则是针对微博短文本和评论短文本的研究,下面将主要对评论短文本的相关研究进行综述。
随着电子商务的高速发展以及淘宝、京东、大众点评等各类含有评论短文本网站的兴起,评论短文本已经成为消费者在做出购买决策之前的重要参考依据[14]。目前关于评论短文本的研究主要集中在: 评论短文本的效用分析、评论短文本的真实性分析、评论短文本的决策影响分析等。但这些研究内容都会涉及两个主题,即: 评论短文本的情感分析与评论短文本的属性抽取。
评论情感分析主要是对评论的情感倾向进行分析,包含三个层次: 评论对象的属性层次、评论对象的层次以及评论篇章层次。其主要采用的方法是将文本简化为BOW(Bag of Words)的形式,然后借助情感词典对评论短文本的情感倾向进行分析。其中,Word Net等情感词典对于评论短文本的情感分析起到了重要的作用。例如,利用Word Net中词汇之间的相互关系(距离、语义联系等)来判断词语的情感倾向。但这也带来一个重要问题,即: Word Net按照同义词集合组织信息,而同义词语不一定具有相同的褒贬倾向,这将导致对词语情感倾向的估计出现偏差[15]。换句话说,目前评论短文本情感分析存在的主要问题是如何针对评论短文本的特征构建情感词之间的数值联系,即词向量的问题。
评论的属性抽取是评论短文本分析的另外一个重要的研究内容,即如何判断和抽取评论中涉及到的商品属性或称对象属性的相互关系。例如,“衣服手感不错!”和“衣服摸起来不错!”中,词语“手感”和“摸起来”都是同样表达评论者对评价对象(衣服)的质量属性或者感官的判断。因此需要在对评论短文本进行分析时,能够成功地发现和评价这类属性的相互关系。评论短文本属性的抽取对于评论属性情感分析和评论总结都具有重要的作用。
总而言之,评论短文本的分析需要依赖于对评论短文本的形式化(数学化)建模,通常而言,需要在原有文本分析技术的基础上,结合短文本的自身特征进行改进,设计出有效的短文本语言模型的建模方法,以提高应用的效率和准确率。
2.2 词向量和Word2vec
语言模型是自然语言处理(Nature Language Processing, NLP)领域的一个重要的基础问题之一,它在句法分析、词性标注、信息检索以及机器翻译等子领域的相关任务中都有重要的作用。在传统语言模型中,统计语言模型具有非常广泛的应用,其核心思想是利用概率来对语言形式进行预测[16]。通常而言,统计语言模型都基于相应的领域语料来进行分析工作。一般的,用以简化统计语言模型的相关方法包括: N-gram模型、马尔科夫模型、条件随机场模型、决策树模型等。
随着深度学习相关研究的逐步深入,神经网络的应用领域逐渐由图像、音频等扩展到了自然语言处理领域,即神经网络语言模型(Neural Network Language Model,NNLM), NNLM可以看作传统统计语言模型的扩展与提升, 并于近年在ACL、COLING等相关顶级会议上取得系列进展。NNLM具有代表意义的系统研究由Bengio于2003年在ANeuralProbabilisticLanguageModel一文中提出[17],在该模型中作者将每一个词汇表示为一个固定维度的浮点向量,即词向量(WordVector)。然而,NNLM中的词向量(记为NWV)和传统统计语言模型中的One-Hot Representation(OHR)有着本质上的差异,主要体现在以下三点。
1) OHR中的向量元素采用0,1表示,词向量中所有的分量只有一个数值为1,其余分量全部为0,而NWV的分量由浮点数构成,其取值为连续值。
2) OHR的向量维数不固定,通常根据词典的大小而发生改变,并且一般较为庞大,容易造成维数灾难[17],而NWV的维度通常根据具体的应用固定在50~1 000左右,具有可接受的时间复杂度。
3) OHR的词向量元素并不包含统计语义或语法信息,通过NNLM的研究发现,NWV通过向量间的相互计算,可以进一步拓展或表达出相应的语义和语法特征。
词向量是NNLM实现后的关键产物,在Bengio的工作之后,出现了一系列关于词向量的实现与构建的相关工作,包括Tomas Mikolov[18-19]、Google的Word2Vec[7]等。其中Google于2013年开源的Word2vec作为重要的词向量训练工具,在情感分析、属性抽取等领域,取得了一系列的应用成果[11, 20-21],同时,词向量训练的好坏对于提升应用成果的性能具有重要的意义。但通常情况下,即使采用相同的Word2vec工具,不同类型或大小的语料库以及不同的向量维度都会对词向量的训练结果好坏造成影响。
因此,本文主要从探讨Word2vec训练词向量的优化方式入手,重点研究了不同的中文语料的预处理策略对于词向量训练结果的优化程度,特别的是对中文评论短文本——这一类重要的自然语言处理语料。本文主要贡献在于: 首先,我们提出基于属性主题分割的短文本评论语料预处理算法,对比实验结果表明,该算法对于改善词向量的训练结果具有明显的提升效果;其次,我们获取了0.7亿条评论短文本数据,通过词向量模型的训练,并优化后得到了具备较高精度的词向量库(开源),该词向量对于其他与在线商品评论相关的(例如,评论情感分析、评论属性抽取等)自然语言处理任务具有重要的参考意义;最后,我们给其他领域关于词向量的训练优化研究提供了一定的参考思路: 即针对特定的处理语料设计相关的预处理策略或许能够显著提升词向量的训练效果。
3 拆分词嵌入的评论短文本分割模式
3.1 基于完整句的分割模式(Based on Whole for Partition, BWP)
完整句子是指以句号、感叹号、省略号、问号以及分号分割后组成的句子形式[22-23]。通常情况下,我们认为一个句子的结束是一种观点、态度和说明内容的结束。对于评论短文本而言,一条评论通常包含几个带有完整句分隔符的句子,这些句子表达的观点既有可能相似,也有可能不同。换句话说,这些句子之间既有可能存在逻辑之间的联系性,也有可能是相互独立的。因此,当这些句子在语法上或观点上是相互独立,甚至截然相反时,如果将这些句子作为一个整体输入,用以词向量的训练,将会给训练模型带来较大的误差。
基于完整句的分割模式是指利用以句号、感叹号、省略号、问号以及分号作为完整句的指示分割符,对一条评论中的句子进行拆分。同时考虑到评论文本的统计信息(表1),当不含完整句分隔符的评论语句的连续字符长度达到23时,我们将进行人工截断,自动将该句划分为一个整句。
3.2 基于分隔符的分割模式(Based on Separator for Partition, BSP)
相比于传统的文本语料,评论短文本在句点符号的使用上更加的随意,内容上也更加丰富和自由,包括含有各种表情符号、缩写、拼写错误以及不规范的断句符等。如图1所示,该图为淘宝商城某商品评论页面的截图。可以看到,对于评 论 短 文 本 而言,其观点句通常在一个分隔符之内进行表达,并且长度更“短”,同时在语法规范上也表现得尤为不足。
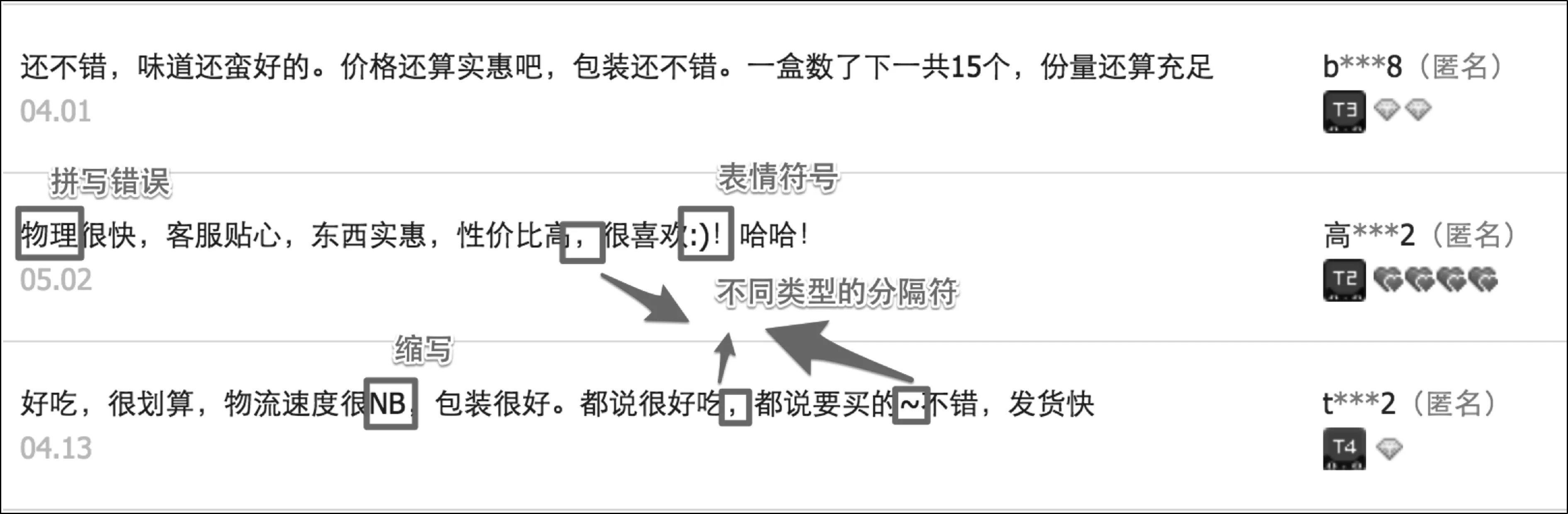
图1 评论短文本案例截图
如图2所示,对于评论“宝贝做工不错,物流速度马马虎虎!客服态度很好!”而言,这是一种典型的评论短文本的出现方式,即: 观点句1+观点句2+…+观点句n。但观点句之间很有可能存在修饰词不兼容(即观点句1的修饰词不能用于观点句2的情况)以及观点句情感极性相反的情况。 如果采用前文所述的BWP分割方式,由于消费者撰写评论时使用符号的不规范,极有可能造成不同的意义、类型和观点的语句被分割到同一个训练语句中,从而增大模型训练的误差。因此,这也就是我们在实验对照中使用第二种分割方法,即分隔符分割法。
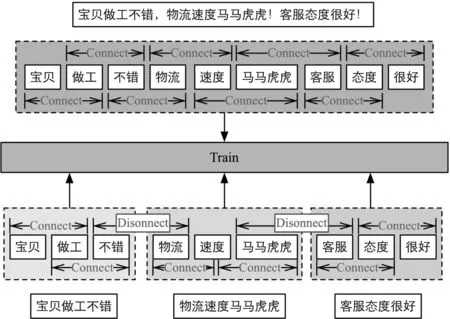
图2 基于分隔符分割模式与原始非分割方法的对比例图
基于分隔符分割的策略,目的是将这些观点句利用分隔符进行拆分。通常而言,评论短文本中的分隔符包括: (。)、(,)、(;)、(、)、(空格)、(!)、(~)、(#)、(…)、(*)、(: )、(-)、(?)、(“)、(”)、(+),、(-)以及(常见表情符号)等,同时,如果以上符号在评论短文本中存在西文格式,将同样认为是评论文本分隔符。
3.3 基于属性主题的分割模式(Based on Topic for Partition, BTP)
在研究中我们发现,虽然基于BSP分割能够将含有不同修饰符和不同属性观点的评论语句进行分割,以保证训练算法在这类评论上的稳定性,但BSP分割法却无法对评论中存在相互联系的,甚至是同类的评论语句进行合并。因此,在BSP的基础上,我们提出了基于属性主题的分割算法。
如图3所示,BTP算法在BSP的基础上,考虑了一条评论中,被分隔符分割的评论句子之间的在主题上的相互联系。采用BSP对评论文本进行预处理后,利用词向量训练算法进行训练,得到初始的词向量模型,然后利用该初始词向量模型对BSP分割进行重构,合并属性主题相关的句子,在保证不同类型观点句得到有效分割的同时,保证了同类型观点句的关联性,具体算法流程如算法1所示。
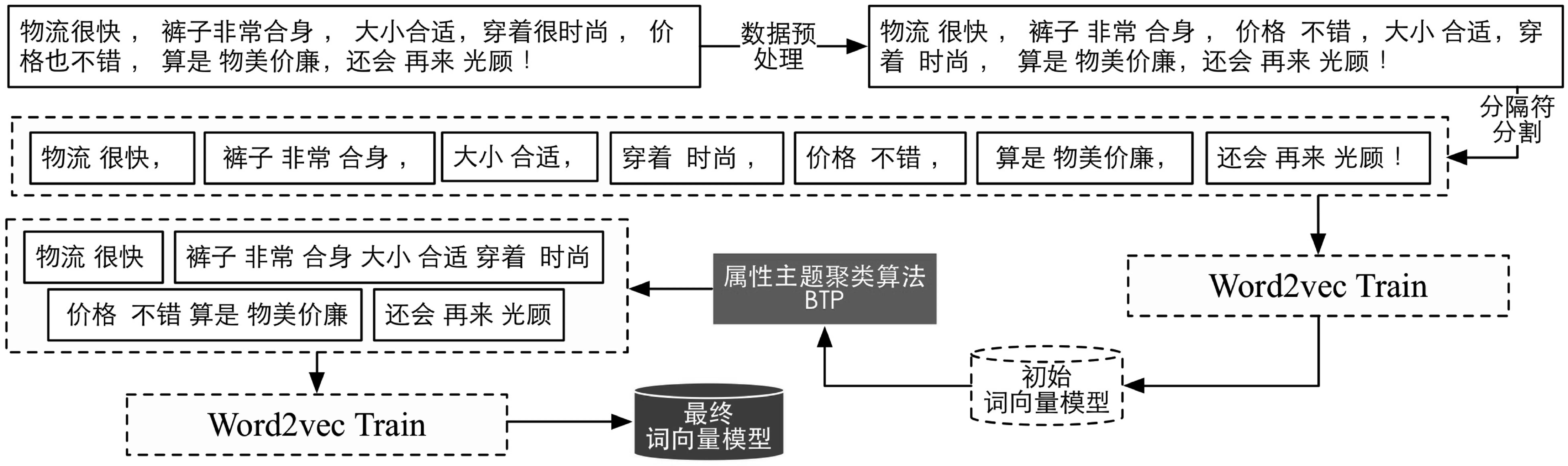
图3 基于属性主题的词嵌入分割模型
算法1的核心思想: 首先通过分隔符对评论进行整体拆分,然后利用BSP训练得到的词向量来计算相邻的每个最短分割候选句之间的属性相关度。其中,一条最短分割候选句的属性特征由短句中的名词词向量(或者数个名词词向量的均值)替代,如果候选短句不包含名词,则用形容词替代。最后,接着使用类似层次聚类的方式,对最短候选句进行逐项合并,直至满足退出要求,然后返回分割结果进行BTP模型的词向量训练。

算法1:基于属性主题切割的词嵌入训练算法(BTP)输入:Ms=Wx,Vx(){},C=R1,R2,R3,…,Ri{},Ri=P1,P2,P3,…,Pj{},Pj=W1,W2,W3,…,Wx{}/∗Ms:基于分隔(S)符切割训练的词向量结果,Wx为词语,Vx为该词语对应的词向量;C:已经经过预处理的评论语料库;Ri:对于每一条已处理评论,由j个分隔句组成;Pj:对于每个分隔句,由x个词语组成;∗/输出:MT={(Wx,Vx)} /∗基于属性主题(T)切割训练的词向量结果∗/1 forRiinCdo:2 Sentence=[],Vector=[]/∗初始化分割结果,词向量临查询结果列表∗/3 m=0,n=0/∗始化指针∗/4 forPjinRido:5 forWxinPjdo:6 ifWxisNounthen:7 Vector[m][n]=WxfindvecMs()[]/∗查询该词对应MS模型中对应的向量∗/8 n+=19 else:10 Continue11 end12 Sentence[m]=Pj/∗将查询得到的词对应的分隔句存入结果列表∗/13 m+=114 end

15 while Merge[index]inMerge>0.5&&Len(Merge)>3do:/∗只要已被处理的分隔句矩阵中存在任一两行的属性主题相似性的概率大于0.5,同时剩下有待被合并的行数大于3组,则合并计算继续进行∗/16forindex1=0;index1+=1;index1
4 实验数据
4.1 数据描述
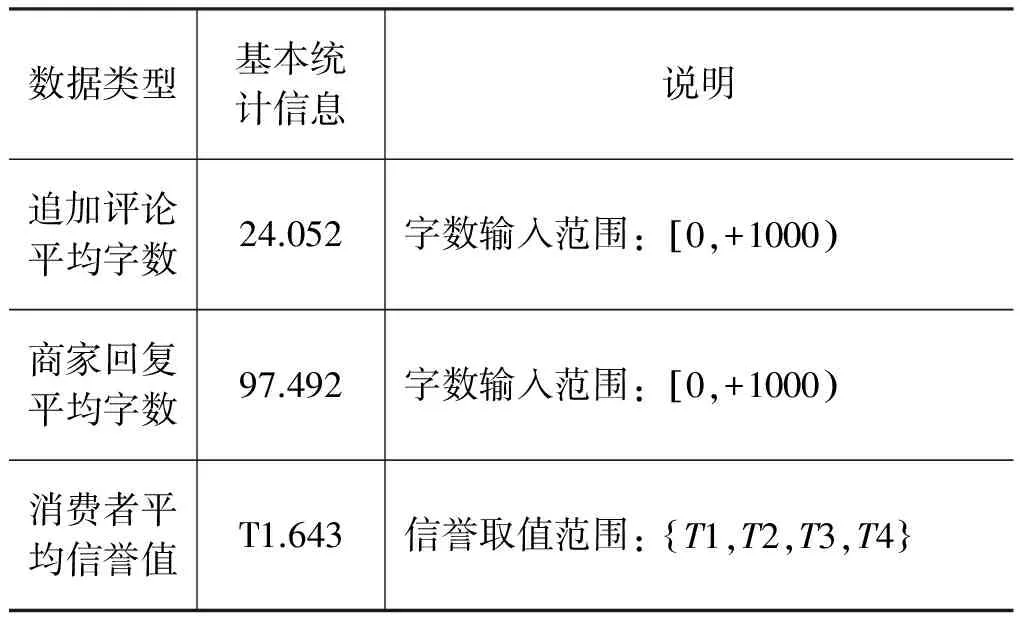
本文的实验数据集来自天猫商城的评论短文本数据,主要字段包括: 商品ID、评论者昵称、初次评论内容、初次评论时间、追加评论内容、追加评论时间、评论相对位置、评论者信誉、评论商品ID、评论商家ID以及商家回复。其中文本内容包括消费者的初次评论数据、追加评论数据以及商家的回复数据三个部分,总计评论数目为72 152 543条,约40GB。主要涉及领域包含: 服装、食品、美妆、母婴、数码、箱包、家电、运户,共计八大领域的82个子领域。数据集的相关基本统计信息如表1所示。

表1 数据集基本信息
续表
4.2 数据清洗
由于数据量巨大,因此数据清洗是本次实验的重要工作之一。本次实验过程中,为了提高数据的读取和操作性能,我们将评论数据存储在当前流行的非结构化数据库之一的Mongodb[24]中,其性能为普通SQL数据库性能的十倍以上,大大地缩短了实验的时间消耗。其中,数据清洗的核心步骤包括重复评论/无关评论的删除、分词、停用词的删除以及繁简体的合并操作。
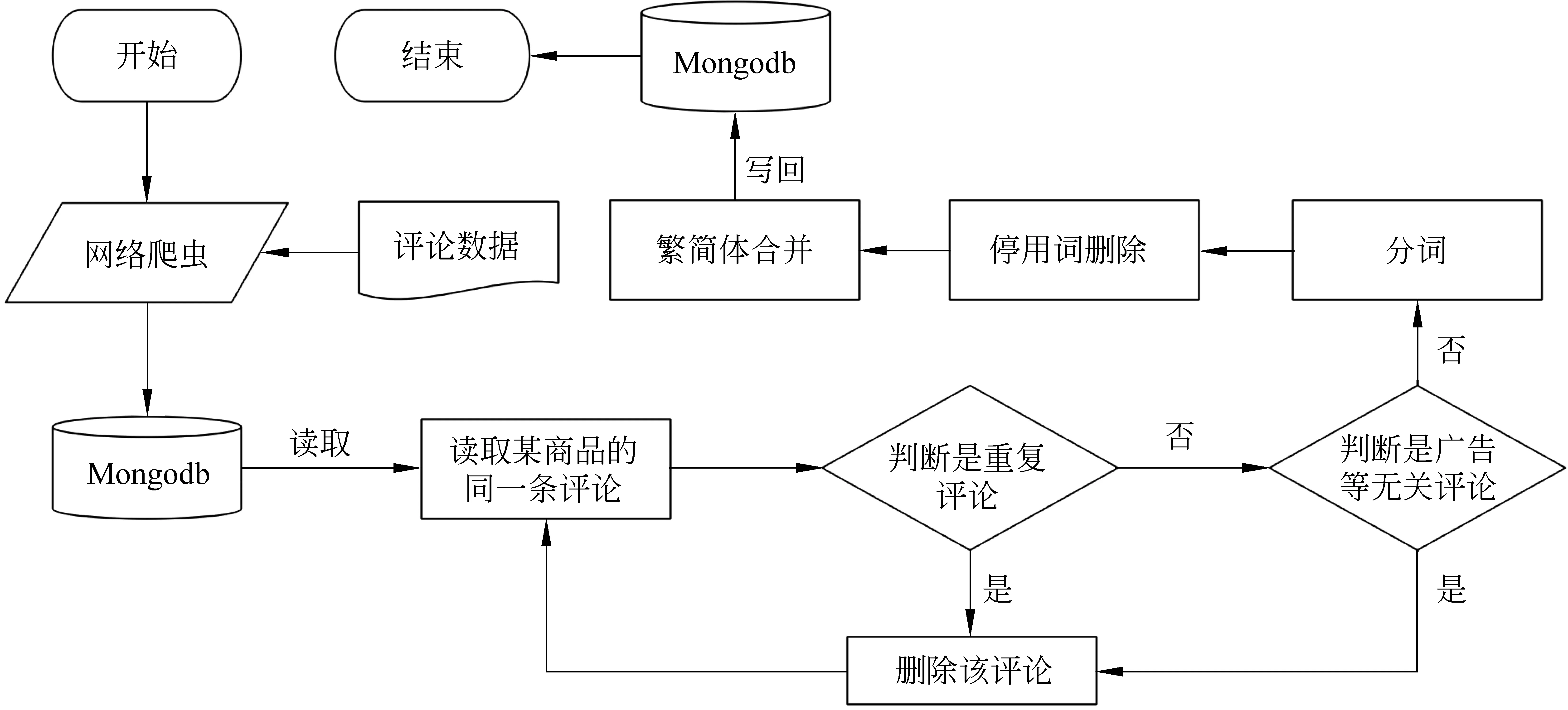
图4 数据清洗流程图
5 实验与分析
5.1 性能评估
5.1.1 标准测试集
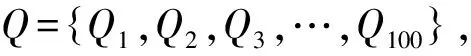
5.1.2 评价指标
在信息检索,模式识别,机器翻译等领域,有两类最为常用的算法评价指标,即: 准确率(Precision Rate)和召回率(Recall Rate)。本文将参考准确率和召回率的评价方式,构建模型的评价指标,为便于说明,做出如下假设:
• 评价指标1: 平均相似度(S)
对于标准测试词对St中的查询词Qi,用其相似词构建评价词对为:
(1)
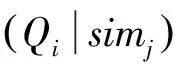
(2)
• 评价指标2: 平均召回率
标准测试词对集S=(Qi|{sim1,sim2,sim3,…,simn}),查询词Qi在模型X中的前n个最相似结果为:T=(Qi|{Tsim1,Tsim2,Tsim3,…,Tsimn}),那么对于查询词Qi,模型X的召回率如式(3)所示。
(3)
(4)
5.2 结果分析
为了验证和对比实验结果,本文的实验基于MAC OS X 10.10.4操作系统,Intel Core i7 4850Q 处理器(四核八线程),16GB内存,512GB SSD存储系统,并采用Python语言进行实现。由于Word2vec的基础模型包含Skip-Gram以及CBOW两类,因此本文所有对比实验同时在这两种类型的基础模型上进行,具体的原始训练模型介绍可以参见Word2Vec的源码及其相关论文,此处不再详述。最后,本实验针对不同的词向量的维度从50~500之间逐渐递增选取,增加纵向对比实验。
5.2.1 时间效率对比分析
如图5所示,通过对比发现,Skip-gram模型的处理时间对于不同大小的词向量维度的敏感度较大,随着词向量维度的增加,NP_Skip以及BSP_Skip模型的时间消耗增长幅度均大于CBOW模型的增长幅度。而NP模型与BSP模型在Skip-gram以及CBOW模型上的时间效率表现存在相互交叉的情况,因此并没有表现出明显的差异。考虑到无论是NP_Skip模型、NP_CBOW模型、BSP_Skip模型还是BSP_CBOW模型的单机训练时间均在[2,5]小时之间,因此,其实际意义上的时间开销(已经是0.7亿条评论大数据)均在可接受的范围内,所以并没有必要在时间效率上对上述模型进行不同的区分和优劣对比。
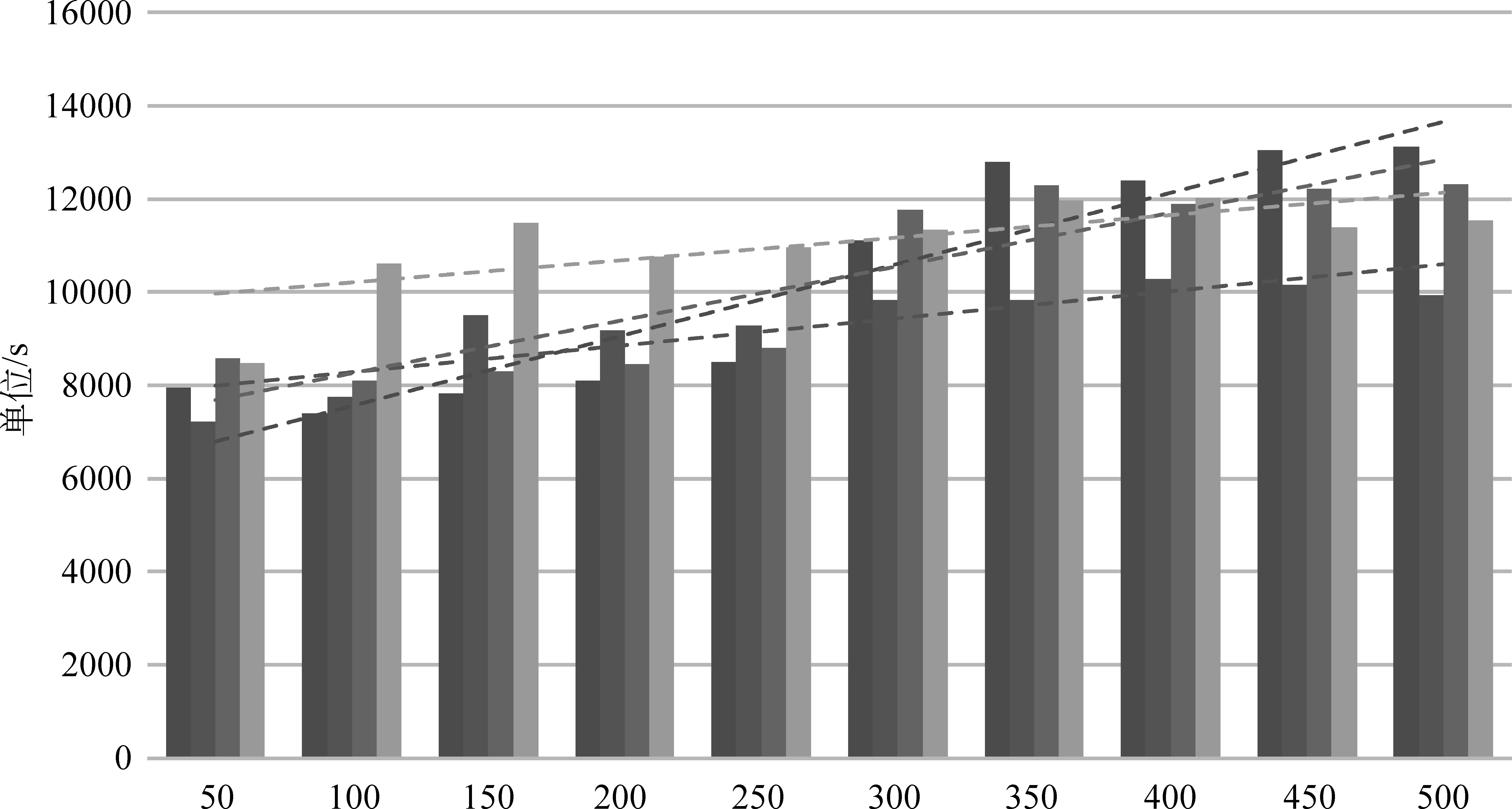
图5 BSP算法与原始训练算法基于不同词向量维度的时间效率对比
5.2.2 评价指标对比分析
• 平均召回率(R)
如表2所示,以直线下划线作为该模型的最好成绩,对比BTP模型与NP模型,在Skip_gram+Herarchical softmax(SGH)和CBOW+Herarchical softmax(CBH)实验上的平均召回率分别提升了23%和17%,其中,SGH_NP,CBH_NP最大召回率分别小于SGH_BTP,CBH_BTP的最小召回率,由此可以看出BTP语料预处理策略对于提升Word2vec训练结果的召回率具有显著效果。同时,我们可以发现,由于短评论语料通常字符数较小,并且断句符存在大量的不规范使用情况。因此,从NP模型到BWP模型的提升效果(2.3%,0.3%)远不如BWP模型到BSP模型的提升效果(12.3%,9.9%)以及BSP到BTP的提升效果(8.4%,7.6%)。
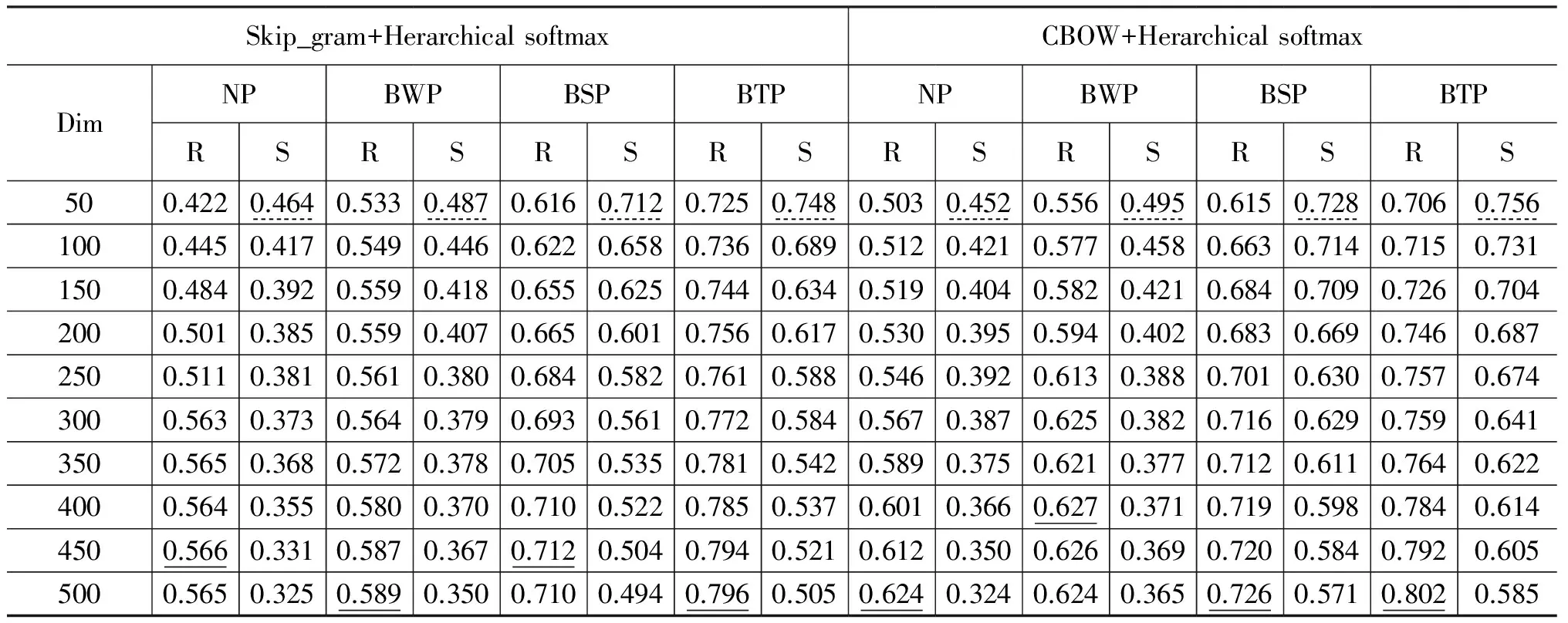
表2 模型实验结果对比
• 平均相似度(S)
由于不同的向量维度数会导致向量的分散程度不同: 一般的,向量维数越大,在总词语数目固定的情况下,同义(属性)词间的分散程度越大,相似度越小(纵向)。因此平均相似度只能作为词向量训练好坏的一个相对参照指标,即: 作横向对比。以表2中波浪下划线标注的50维度上的结果为例,对于召回相同的词语,其相似度越高,表示同义词(属性词)之间的稳定性越高,因此在不同的环境下其应用的可拓展性也就越高。从表 2中可以看到,无论是对于Skip_gram模型还是CBOW模型,在不同词向量维度上,BTP模型的稳定性都是最高的,但相对于BSP预处理模型来说,BTP模型的提升程度却并不十分明显,因此如果在不考虑召回率的情况下,可以任选BTP或者BSP模型作为评论语料的预处理策略。
5.2.3 查询样例对比分析
为了能够对原始模型(NP)和BTP优化后模型产生的词向量的结果产生一个具体的认识和对比,我们选取了两个具有代表性的词汇“EMS”(属性词)以及“差评”(形容词,观点词),查询了它们在NP词向量(200维)以及BTP词向量(200维)中的前20个最相似的结果,如表 3和表 4所示。
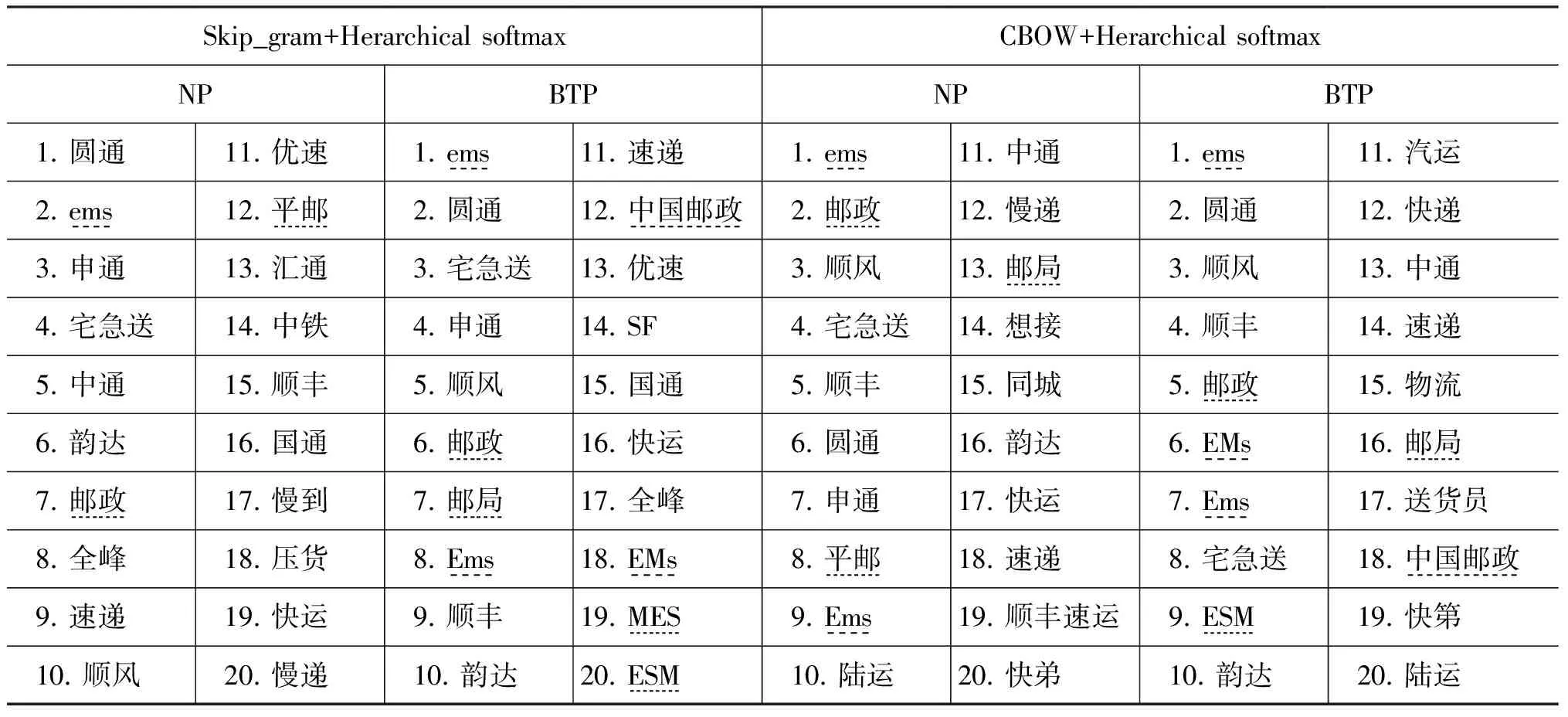
表3 查询词“EMS”在NP模型和BTP模型上的对比结果
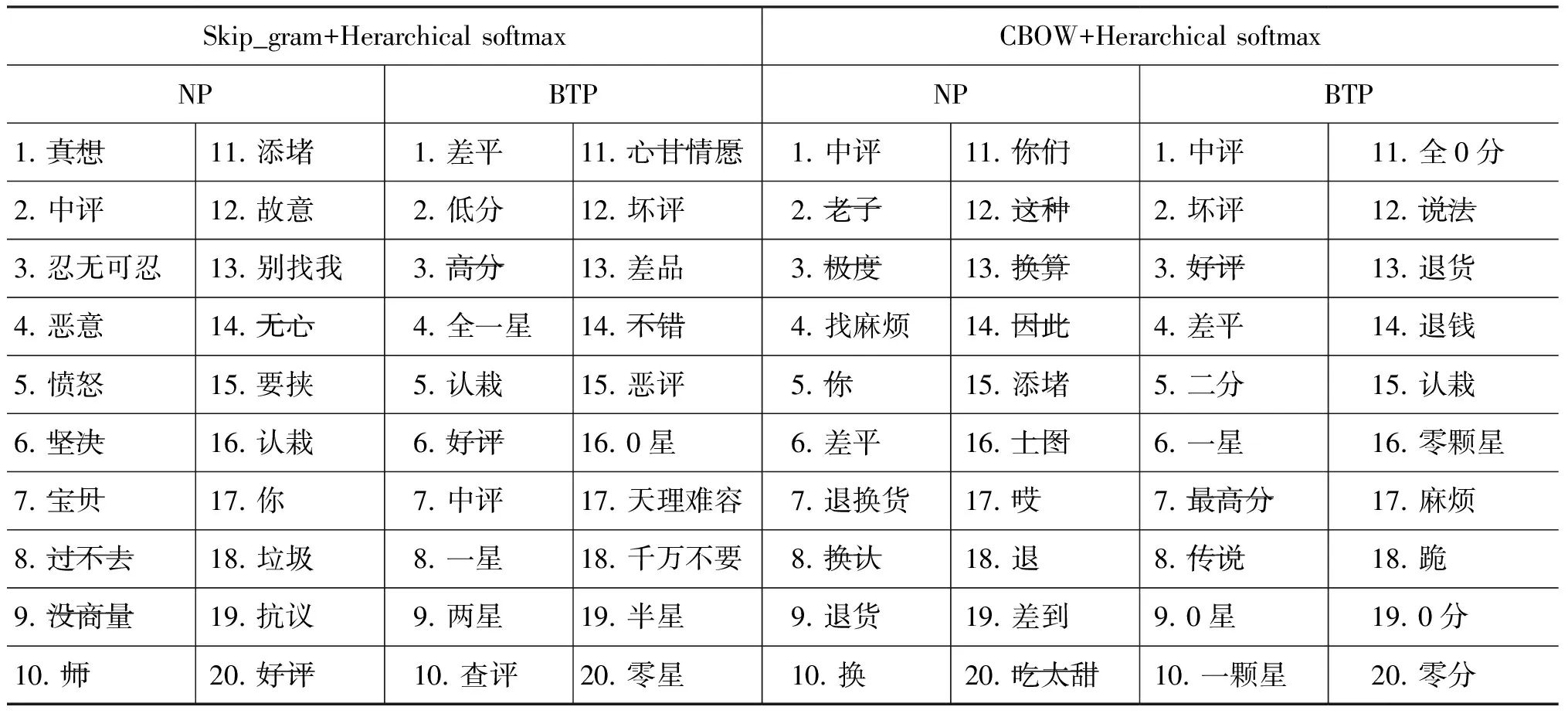
表4 查询词“差评”在NP模型和BTP模型上的对比结果
通过表3可以发现: BTP模型的预处理策略能够有效的发现属性词的相似词及其变异,甚至是错误的拼写词。例如,SGH_BTP模型中的“ESM、MES”(误输入)、“ems、EMs”(大小写变形)等。同时可以发现,BTP模型的属性词召回率明显高于NP模型。通过表4可以发现: BTP模型对于同义词的召回率同样较好,而NP模型中甚至出现了较多将查询词的被修饰词判定为相似词的情况,例如,真想(差评),坚决(差评)等。但同时也需要看到,对于NP模型和BTP模型都出现了查询词的反义词被判定为相似词的情况,这种误判需要在后续的研究中进一步优化。
6 结论
Word2vec词向量训练的优化问题不仅仅需要考虑训练算法的内部结构,对于不同类型的训练语料的预处理同样值得思考。本文针对评论短文本在Word2vec词向量训练中存在的问题,结合评论短文本的自身特征提出了基于属性主题分割的语料预处理算法BTP。基于0.7亿条大规模评论短文本的实验表明,BTP算法的预处理策略对于提升词向量模型的训练结果具有显著意义。本文针对评论短文本的大规模词向量训练结果对于其他关于包括评论短文本情感分析、评论短文本属性特征提取(聚类)等的应用都具有较大的参考意义。
[1] Yuan Y, He L, Peng L, et al. A New Study Based on Word2vec and Cluster for Document Categorization[J]. Journal of Computational Information Systems, 2014, 10: 9301-9308.
[2] 张剑峰, 夏云庆, 姚建民. 微博文本处理研究综述[J]. 中文信息学报, 2012, 26(4): 21-27.
[3] 杨铭, 祁巍, 闫相斌, 等. 在线商品评论的效用分析研究[J]. 管理科学学报, 2012, 15(5): 65-75.
[4] 陈燕方, 李志宇. 基于评论产品属性情感倾向评估的虚假评论识别研究[J]. 现代图书情报技术, 2014, 9: 81-90.
[5] 任亚峰, 尹兰, 姬东鸿. 基于语言结构和情感极性的虚假评论识别[J]. 计算机科学与探索, 2014, 8(3): 313-320.
[6] Pang B, Lee L. Opinion mining and sentiment analysis[J]. Foundations and trends in information retrieval, 2008, 2: 1-135.
[7] Mikolov T. Word2vec project[CP].2013, https://code.google.com/p/word2vec/.
[8] Xue B, Fu C, Shaobin Z. A Study on Sentiment Computing and Classification of Sina Weibo with Word2vec[C]//Proceedings of the 2014 IEEE International Congress on, 2014: 358-363.
[9] Tang D, Wei F, Yang N, et al. Learning sentiment-specific word embedding for twitter sentiment classification[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, 2014: 1555-1565.
[10] Godin F, Vandersmissen B, Jalalvand A, et al. Alleviating Manual Feature Engineering for Part-of-Speech Tagging of Twitter Microposts using Distributed Word Representations[C]//Proceedings of NIPS 2014Workshop on Modern Machine Learning and Natural Language Processing (NIPS 2014), 2014: 1-5.
[11] Ghiyasian B, Guo Y F. Sentiment Analysis Using SemiSupervised Recursive Autoencoders and Support Vector Machines[EB/OL],Stanford.edu,2014: 1-5.
[12] 张林, 钱冠群, 樊卫国, 等. 轻型评论的情感分析研究[J]. 软件学报, 2014, 12: 2790-2807.
[13] 周泓, 刘金岭, 王新功. 基于短文本信息流的回顾式话题识别模型[J]. 中文信息学报, 2015, 291: 015.
[14] 郑小平. 在线评论对网络消费者购买决策影响的实证研究[D].中国人民大学硕士学位论文,2008.
[15] 张紫琼, 叶强, 李一军. 互联网商品评论情感分析研究综述[J]. 管理科学学报, 2010, 13(6): 84-96.
[16] 邢永康, 马少平. 统计语言模型综述[J]. 计算机科学, 2003, 30(9): 22-26.
[17] Bengio Y, Ducharme R, Vincent P, et al. A neural probabilistic language model[J]. The Journal of Machine Learning Research, 2003, 3: 1137-1155.
[18] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]//Proceedings of the Advances in Neural Information Processing Systems, 2013: 3111-3119.
[19] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space. arXiv preprint arXiv: 1301.3781[DBOL], 2013: 1-16.
[20] Zhang W, Xu W, Chen G, et al. A Feature Extraction Method Based on Word Embedding for Word Similarity Computing[C]//Proceedings of the Natural Language Processing and Chinese Computing, 2014: 160-167.
[21] Iyyer M, Enns P, Boyd-Graber J, et al. Political ideology detection using recursive neural networks[C]//Proceedings of the Association for Computational Linguistics, 2014: 1-11.
[22] 黄建传. 汉语标点句统计分析[D]. 北京语言大学硕士学位论文, 2008.
[23] 何玉. 基于核心词扩展的文本分类[D]. 华中科技大学硕士学位论文, 2006.
[24] Banker K. MongoDB in action[M]. Manning Publications, 2011.
Improving the Word2vec on Short Text by Topic: Partition
LI Zhiyu, LIANG Xun, ZHOU Xiaopin
(School of Information,Renmin University of China, Beijing 100872,China)
We propose a method for Word2vec training on the short review textsby a partition according to the topic. We examine three kinds of partition methods, i.e. Based on Whole-review (BWP), Based on sentence-Separator (BSP) and Based on Topic(BTP), to improve the result of Word2vec training. Our findings suggest that there is a big difference on accuracy and similarity rates between the None Partition Model (NP) and BWP, BSP, BTP, due to the characteristic of the review short text. Experiment on various models and vector dimensions demonstrate that the result of word vector trained by Word2vec model has been greatly enhanced by BTP.
online review; short text; word vector; similarity calculation

李志宇(1991—),博士研究生,主要研究领域为自然语言处理,网络结构嵌入,社会网络分析。E⁃mail:zhiyulee@ruc.edu.cn梁循(1965—),通信作者,博士生导师,教授,主要研究领域为社会计算,机器学习。E⁃mail:xliang@ruc.eud.cn周小平(1985—),博士研究生,主要研究领域为社会网络分析,网络隐私保护。E⁃mail:zhouxiaoping@bucea.edu.cn
1003-0077(2016)05-0101-10
2015-06-03 定稿日期: 2015-10-15
国家自然科学基金(71531012、71271211);京东商城电子商务研究项目(413313012);北京市自然科学基金(4132067);中国人民大学品牌计划(10XNI029);中国人民大学2015年度拔尖创新人才培育资助计划成果
TP
A
猜你喜欢
温州大学学报(自然科学版)(2022年2期)2022-05-30
通信技术(2021年12期)2022-01-25
潍坊学院学报(2020年2期)2021-01-18
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
制导与引信(2017年3期)2017-11-02
海军航空大学学报(2015年4期)2015-02-27
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
阅读与作文(英语高中版)(2013年12期)2013-12-11
