
基于多模板归一化的维吾尔文字母识别算法
2016-05-03 13:03:29李和成
中文信息学报 2016年1期
刘 卫,李和成
(1. 西安电子科技大学 综合业务网理论及关键技术国家重点实验室,陕西 西安 710071;2. 青海师范大学 物理系,青海 西宁 810008)
基于多模板归一化的维吾尔文字母识别算法
刘 卫1,2,李和成2
(1. 西安电子科技大学 综合业务网理论及关键技术国家重点实验室,陕西 西安 710071;2. 青海师范大学 物理系,青海 西宁 810008)
该文针对手写维文字符识别中字符宽高比变化剧烈,单一模板归一化后提取字符特征,不能有效增加异类字符之间的差异性,提出了针对维文字形特点的多模板归一化算法。训练阶段,由多模板归一化字符图像,提取特征并训练对应分类器;识别阶段,用主笔画散度方向作为维文字形参数, 对不同字形选用最优模板进行归一化处理后提取特征,并送入该模板对应的分类器。多模版归一化有效利用了手写维文字符字形特征,克服了单模板归一化时异类维文字符差异减小的不利影响。实验结果表明多模板归一化算法较单模板归一化算法在识别性能上有所提高。
维吾尔文字符;归一化;宽高比;分类器
1 引言
手写字符识别是模式识别的经典问题,并且一直是该领域的研究热点。随着对手写汉字识别的研究取得的众多成果[1],少数民族语言文字识别正成为手写识别新的研究方向。其中,隶属于阿尔泰语系突厥语支的维吾尔文,作为我国重要的少数民族文字,其印刷体和手写识别研究,近年来逐渐受到了更多关注[2-4],其中文献[4] 针对维吾尔文的连体结构,利用投影分离出连体段中的字母,对文本图像进行了切分,并提取外围特征,在印刷体维吾尔文字符的识别中获得了较满意的结果。
脱机手写字符识别中,字符图像的预处理十分重要,归一化字符图像又是识别算法中最基本的一步[5-9]。字符样本的归一化被定义为使样本成为相同规格的模式,以便形成特征向量进行训练与识别。在手写拉丁字符及汉字字符中,对不同类字符,虽然笔画及字体结构会发生较大变化,但不同类别字符的整体字形非常接近,尤其是字符的宽高比变化很小,所以,在字符归一化的过程中,通常采用统一的标准模板。然而对维文字符,虽然其与拉丁字符同属拼音字符,但两者在字形上有很大差异:手写维文字符相连,并且根据字符在文中位置又有不同的书写方式,字符水平方向伸缩变化剧烈,不同类别字符的整体字形差异非常大。如果采用统一模板归一化字符样本,并不能体现出维吾尔文字符的字形特征,不利于字符分类。为克服这一缺陷,许多算法使用隐马尔科夫模型对字符动态建模[10-11],但隐马尔科夫模型参数鲁棒性差,算法复杂度高,而基于维文字符字形的这些特点,一些在字符识别中性能优良的分类器,如人工神经网络,支持向量机,修正二次判别函数等[12]又无法在单模板维文识别中有较好的表现。
本文根据维文整体字形特点,提出了多模板归一化算法(Multi-Template Normalization,MTN): 1)在训练阶段,用不同规格的模板归一化字符,并训练对应分类器;2)在识别阶段,为避免字符图像的噪声野点对字符宽高比的影响,采用主笔画像素散度主方向作为字形参数,根据样本的字形选择最优模板归一化,送入对应分类器,获得分类结果。算法充分的利用了维文的字形特征,取得了良好的分类效果。
2 维文字符及单模板归一化
维文基于字母拼写,共有字母32个,其中八个元音字母,24个辅音字母。维吾尔文自右向左书写,书写时,它的每一个字母根据其在单词中的所在位置不同,一般分为独立式,前连式,中间式和后连式四种。其中,两个元音字母八种书写形式,五个辅音字母有两种写法,还包括两个复合字符,共有128种不同的字母书写形式,本文算法是对维吾尔文单词切分后的字母进行的,其中单词为新疆师范大学维吾尔族师生书写,为保证切分质量,由维吾尔族师生手工切分为字母,所以识别目标是针对128个不同的字母书写形式,图1是部分维吾尔文字符实例。

图1 部分维文字符
手写识别中,归一化处理是基本的预处理步骤,其作用是将每个输入字符变换成统一大小的规格,在不降低异类间的差异的条件下增强同一类字符的相似性。对汉字及英文字母归一化处理时,由于字符长宽比稳定,往往采用统一的标准模板,即训练样本及测试样本共用一个标准模板,图2中第二行为单模板归一化后的维文图像。

图2 维文字符单模板归一化
3 维文多模板归一化算法
由图1、图2可以看出,维文字母形状并不规则,不同类字符宽高比很不规范,手写字符尤为显著。当采用统一规格模板进行归一化处理时,不仅不能降低维吾尔文字符异类间的差异,反而会缩小异类模式之间的差异性,如用不同的模板对字符进行归一化,则识别性能会有所不同。因此,为使识别效果最佳,应针对不同字形使用不同规格的模板归一化字符图像。
3.1 主笔画散度方向
MTN算法中,需要判断维文字符的整体字形特征。影响手写维文字符整体字形主要有两方面原因:
1) 附加笔画。维文字符笔画较少,字符分为主笔画部分及附加笔画部分,附加笔画虽然像素较少,但游离在主笔画上下,在垂直方向上分布比较随意,使得原字符的宽高比不够稳定,如直接用字符的宽高比来选择归一化模板,受附加笔画影响,无法反映出原字符的形状。
2) 噪声影响。散布在字符周围的噪声野点占位,对字符长宽比判断也产生不利影响。
根据以上两点,维文字符长宽比并不是稳定的字形参数。通过分析维吾尔文字符的结构特征,对主笔画及附加笔画前景点连通域分析表明,维文字符主笔画像素散度方向相对稳定,主笔画像素数量又远大于附加笔画及噪声像素数量,而维文字符字形主要取决于其主笔画像素散度方向,且其不受附加笔画影响。因此,本文采用主笔画像素散度主方向代替字符宽高比作为字形参数。
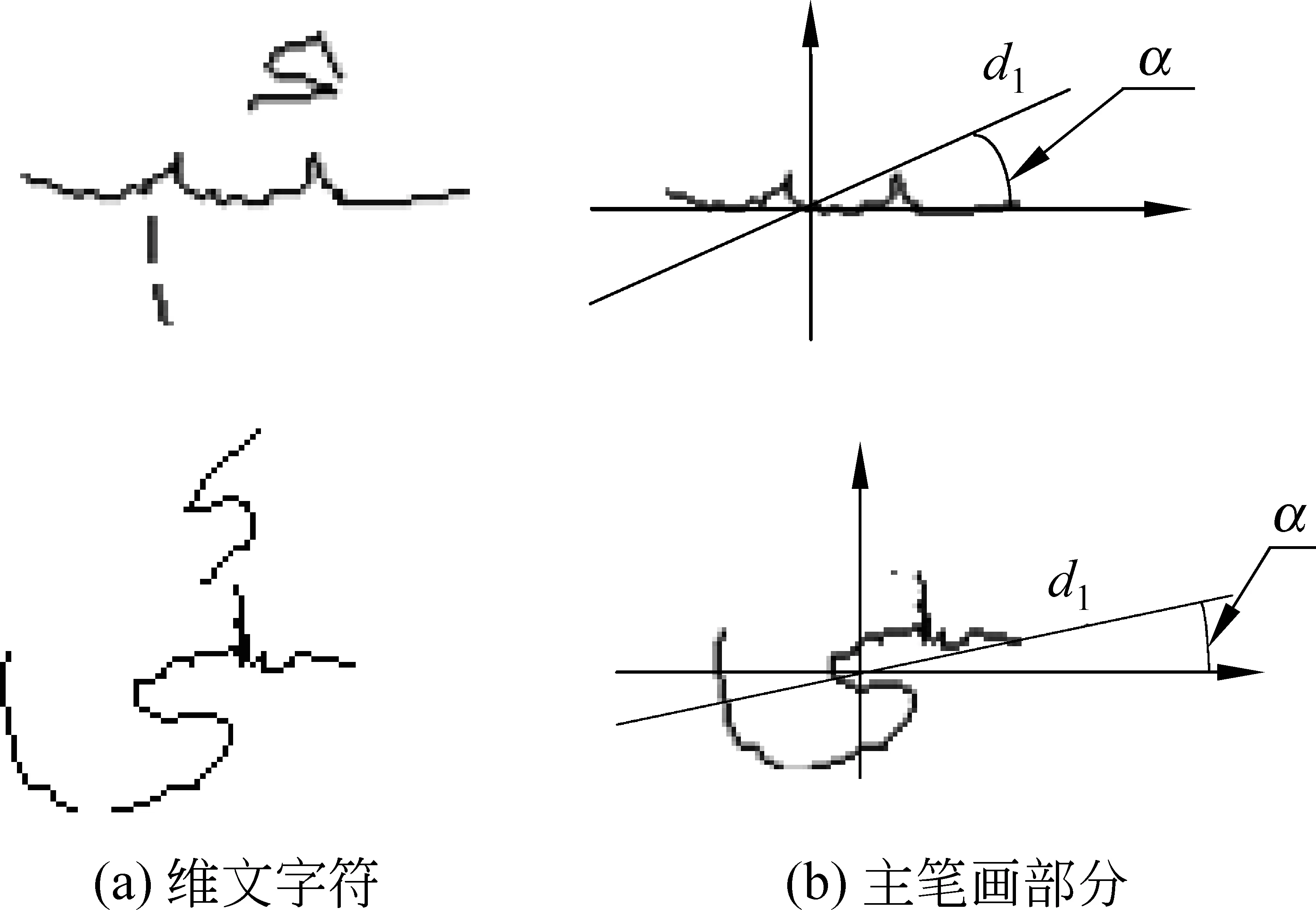
图3 主笔画散度方向
图3(b)是(a)中字符的主笔画部分,字符主笔画前景点集合定义为:
(1)
式(1)中,si=(xi,yi)T是(b)中第i个前景点坐标点对,xi,yi为前景点行列坐标,主笔画像素散度矩阵如式(2)所示:
(2)
(3)
式(2)、式(3)中,Σ是一个2×2的实对称矩阵,其性质是主笔画像素的坐标散度矩阵,λ1,λ2和d1,d2分别是Σ的本征值和对应的本征向量,其中d1,d2相互正交,当对应的特征值λ2<λ1时,特征向量d1与水平坐标轴的夹角α,即为主笔画像素散度主方向,简称为主笔画散度方向,如图3(b)。
3.2 预处理及特征抽取
在对字符归一化及提取特征之前,要对字符图像进行形态学预处理。为防止笔画断裂,首先对二值字符图像进行膨胀,归一化笔画宽度;再用开运算平滑笔画边界;最后根据参考模板归一化字符图像,提取字符轮廓。
为克服笔画边界噪声,通过选择多维网格对边界曲线进行重新采样,如图4所示。将重采样后的字符图像的每个边界像素按图4赋予方向编码值,同时设置与图像相同大小的八个方向模板,每个像素编码后,与编码对应的方向模板中该像素位置被赋值为1,每个边界像素允许分配不同的方向编码,方向模板中未被赋值的位置保持0值。得到八个赋值方向模板后,采用网格提取特征。本文采用m×n的均匀网格划分方向模板,对每个方向模板采用Gauss滤波器进行卷积,每个方向模板的每个网格中心位置卷积值作为一个字符特征,这样获得的维文字符特征向量维数为8×m×n维,得到的原特征向量采用线性判决分析(LinearDiscriminationAnalysis,LDA)降维,最终特征向量为127维,对特征抽取详细过程参见文献[5]。

图4 特征抽取与多维网格重采样
3.3 多模板维文识别算法
单一模板进行训练和识别维文字符时,特征向量来自于唯一的归一化模板,模板选择独立于字符字形,损失了原字符的字形特征,无法针对字符字形选择最优模板,并在随后抽取特征,不能获得最优的识别结果。多模板维文识别充分考虑识别性能与模板选择相关性,根据测试样本的所属字形选择最优模板进行归一化。

图5 维文字符的多模板归一化
图5为维文字符样本经预处理后,由多模板归一化后的图像。为选择最优模板进行归一化,设样本集X按主笔画散度方向α划分为I个子集:X=X1∪X2∪...∪XI;字符归一化模板为:T1,T2,...TJ,对多模板维文字符识别作如下定义:
定义1 设有测试样本x∈Xi,则Pi=P(x∈Xi)为样本空间中x∈Xi的概率。
定义2 模板损失函数:γi,j(Tj,x∈Xi),γi,j表示i类字形采用模板Tj时的分类错误率
定义3 模板期望代价:R(γ)=∑iγi,j(Tj,x∈Xi)Pi
由定义1~3可知,若使R(γ)为最小,则对任意样本∀x∈Xi应选择模板Tj归一化维文字符,使得γi,j(Tj,x∈Xi)为最小,本文中γi,j(Tj,x∈Xi)为样本验证集上的分类错误率。
多模板手写维文字识别算方法分为训练与识别两个部分,图6为MTN算法训练与识别过程,分别描述如下:
在训练阶段,所有训练样本不分字形,按不同的参考模板T1,T2,...TJ分别进行归一化及预处理后,进行特征提取,用每一种归一化模板对应的特征向量训练对应分类器g1,g2,...gJ,如图6(a)。

图6 训练和识别过程
图6(b)为MTN算法识别过程,设有任意待识别字符x,则MTN识别过程步骤如下:
步骤1 根据3.1中主笔画散度方向α,判断字符字形x∈Xi;
步骤2 根据定义2中模板损失函数,选择使γi,j(Tj,x∈Xi)最小的模板Tj对字符进行归一化,并提取字符特征;
步骤3 将在步骤2中获得的字符x特征,送入由模板Tj对应训练出的分类器gj,得到最终识别结果,此时,在整个测试集上得到模板期望代价最小。
4 分类器设计
训练集中的字符,分别采用不同的模板进行归一化,抽取特征后,得到对应不同模板的特征集。这些特征集被分别用于训练分类器,本文采用基于概率距离的三种分类器做比较。

3) 修正的二次判别函数(ModifyQuadraticDiscriminationFunction,MQDF):
(4)
以上三种分类器的判别准则为: 当g(x)为最小时,x被判别为第i类。
5 实验结果及分析
本文所采用的维文数据集由新疆师范大学收集,原数据为维吾尔文手写单词,经手工切分后共128类字符,每类有样本105个,全部由维族师生书写,移动平台采样。
表1中选择模板数量J=3,对其规格定义如下: 设维文字符归一化模板的宽高比为r。r=2为模板T1,r=0.5为模板T2,r=1为模板T3。将手写测试字符按照3.1节定义的主笔画散度方向,划分为三类,即I=3。α≥60°时为肥字母,α≤30°时为瘦字母,30°<α<60°时为正字母。
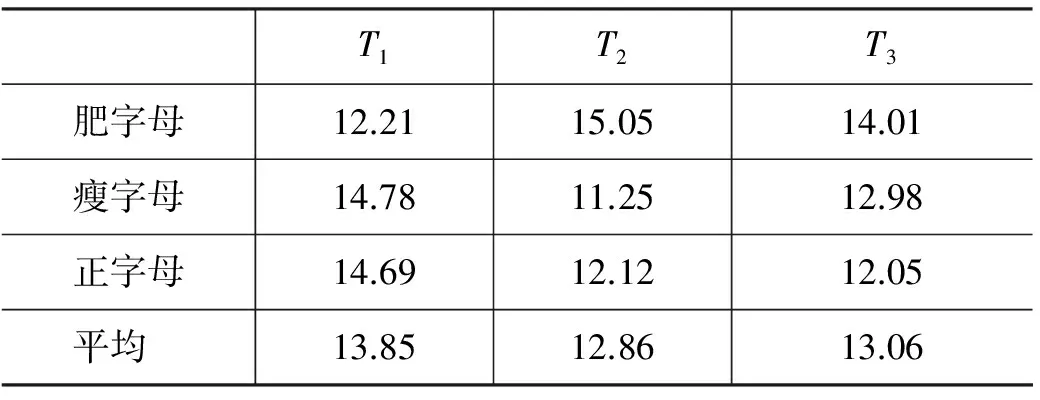
表1 各手写字形采用不同模板错误率/%
表1为使用NN分类器,在验证集上比较不同字形采用不同规格模板归一化时的识别率。由于不同字形在样本集中所占比率不同, 表1中最后一行是平均错误率,按各字形在验证集中的所占比率加权平均。由表1各个模板的错误率可见,采用单模板归一化,不同规格的模板对识别结果有较为明显的影响,并且,不同的字形对归一化模板比较敏感,如,当肥字母依照T3模板归一化时,错误率较高,而采用T1模板时错误率较低,瘦字母与正字母有相似的情况。所以,单模板归一化会破坏字形特征,减少分属不同字形字符类别间的差异性,分类错误率较高。因此,字形是维文字符的重要特征,对不同的待识别字符,应该采用不同的模板,可以获得优于单模板归一化的识别性能。
表2中,手写字符集按60%,20%,20%被分为训练集、验证集与测试集三部分。其中,验证集用于判断不同字形Xi的最优归一化模板Tj,即对在3.1中x∈Xi,在验证集上选择Tj,使得损失函数γi,j(Tj,x∈Xi)为最小。
定义模板数J=3,字形种类I=3,模板与字形的选取方式与表1实验相同。由表2可以看出,三种分类器中多模板归一化识别率普遍好于单模板归一化,这是因为每类字符都具有自身的字形特点,分属于不同的字形Xi,MTN算法充分利用了不同字符的字形特征,选择最优模板,获得优于单模板的识别性能。


表2 单模板与多模板归一化识别率/%
由表2同时可以看出,NN分类器表现出优于其他两类分类器性能,原因是NN分类器不依赖于模型参数,对样本在空间中的分布有较强的适应性,是一种较强的分类器。而其他两类分类器以样本高斯分布作为前提,对样本分布的假设并不一定附和样本在空间中的实际分布情况。
MTN算法中,参考模板数J的选择是开放的,可以提供更多的模板用于测试对不同字形归一化后识别性能的影响,表3是不同模板数量下,采用最近邻分类器(NN),MTN算法性能的比较。

表3 不同模板数量对应错误率/%
表3中,第一列为单模板错误率(模板T2),其余为不同模板数量下,MTN算法识别性能,模板数量J的增加有利于对模板作出更优的选择,使识别性能提高,但当J≥3时,对识别性能影响却很小,这是因为,字形特征在三类形状差别大的模板中表现出了比较强的异类分辨率,而相近形状的模板对算法性能的贡献接近,而且,因为模板的更细划分,导致验证集各字形数量减少,使模板代价可靠性下降。本文MTN算法中,模板数J=3,当模板宽高比为r时,规格分别为:r=2,r=0.5,r=1,字符归一化时选用线性插值算法,对每个模板,特征抽取时的网格密度分别为4×8、8×4和4×8,则原始特征维数4×8×8,经LDA降维后为127维。采用NN分类器分类,MTN算法最终识别率为88.17%。
6 结束语
手写字符识别中,预处理起到相当重要的作用,往往对分类性能有决定性的影响,本文提出的MTN维文识别算法,充分考虑维文字符字形的多样性,用主笔画散度方向判断字形,利用多模板代替单模板,对不同字形选用代价最优模板归一化。与单模板归一化算法比较,MTN算法易于实现,原理清晰,充分利用异类字符在多模板归一化后,由其字形的不同,而产生了不同的分辨率,在所属分类器上取得了良好的实验结果。
[1] 赵继印,郑蕊蕊,吴宝春,李敏. 脱机手写体汉字识别综述[J]. 电子学报, 2010, 38(2): 405-414.
[2]UbulK,HamdullA,AysaA,RaxidinA,MahmutR.ResearchonUyghurOff-lineHandwriting-basedWriterIdentification[C]//Proceedingsofthe9thInternationalConferenceonSignalProcessing.Beijing:IEEE,2008: 1656-1659.
[3] 袁保社,吾守尔·斯拉木. 一种手写维吾尔文字母识别算法[J]. 计算机工程,2010, 36(2): 186-188.
[4] 哈力木拉提,阿孜古丽. 多字体印刷维吾尔文字符识别系统的研究与开发[J]. 计算机学报,2004, 27(11): 1480-1484.
[5]Cheng-LinLiu,KazukiNakashima,HiroshiSako,etal.Handwrittendigitrecognition:investigationofnormalizationandfeatureexractiontechniques[J].PatternRecognition. 2004, 37(11): 265-279.
[6] 孙光民,李岩,王鹏,等. 用于神经网络手写字符识别的自适应归一化处理方法[J]. 模式识别与人工智能,2005, 18(3): 268-272.
[7]deOliveiraJ.J.Jr,VelosoL.R,deCarvalhoJ.M.Interpolation/decimationschemeappliedtosizenormalizationofcharactersimages[C]//Proceedingsofthe15thInternationalConferencePatternRecognition.Barcelona:IEEE,2000:577-580.
[8] 门光福,潘晨,柳长青. 基于弹性网格的西夏文字识别[J]. 中文信息学报,2011, 25(9): 109-113.
[9] 柳长青. 基于LevelSet方法的西夏字轮廓提取[J]. 中文信息学报,2009, 23 (4): 71-76.
[10]SabriA.MahmoudandSamehM.Awaida.Recognitonofoff-lineHandwrittenArabic[J].TheArabianJournalforScienceandEngineering. 2009, 34(2): 429-455.
[11]MohamadRA,Likforman-SulemL,MokbelC.CombiningSlanted-FrameClassifiersforImprovedHMM-BasedArabicHandwritingRecognition[J].IEEETransactionsonPatternAnalysisandMachineIntelligence. 2009, 31(7): 1165-1177.
[12]LorigoLM,GovindarajuV.Off-lineArabicHandwritingRecognition:ASurvey[J].IEEETransactionsonPatternAnalysisandMachineIntelligence. 2006, 28(5): 712-724.
[13]KimuraF,TakashinaK,TsuruokaS,etal.ModifiedQuadraticDiscriminateFunctionsandtheApplicationtoChineseCharacterRecognition[J].IEEETransactionsonPatternAnalysisandMachineIntelligence. 1987, 9(7): 149-153.
Uighur Character Recognition Based on Multi-template Normalization
LIU Wei1,2, LI Hecheng2
(1. State Key Lab. of Integrated Service Networks, Xidian University, Xi’an, Shaanxi 710071, China; 2. Physics Department of Qinghai Normal University, Xining, Qinghai 810008, China)
Since the hand-written Uyghur characters can be dramatically changed in its aspect ratio, a single template normalization can not effectively increase the differences of characters in different classes. This paper proposes a multi-template normalization algorithm to deal with the shape characteristic of Uighur characters. In the training stage, features of characters are extracted with multi-template normalization for the training of different classifier. In the recognition stage, the divergence direction of main strokes is chosen to decide the best template, and then the features of normalized characters are extracted for the corresponding classifier. The experiment results show that the multi-template normalization algorithm has better recognition performance than the single template baselines.
Ugihur characters;normalization;aspect ratio;classifiers

刘卫(1975-),博士研究生,副教授,主要研究领域为模式识别,机器学习。E⁃mail:liuwei@qhnu.edu.cn李和成(1972-),博士,教授,主要研究领域为智能优化算法。E⁃mail:lihecheng@qhnu.edu.cn
1003-0077(2016)01-0156-06
2014-05-08 定稿日期: 2014-12-23
国家自然科学基金(61463045);青海省自然科学基金(2013-z-937Q)
TP391
A
猜你喜欢
学苑创造·A版(2024年5期)2024-06-10 21:55:57
故事作文·低年级(2021年12期)2021-12-21 23:04:39
作文成功之路·小学版(2020年7期)2020-08-24 08:19:18
书香两岸(2020年3期)2020-06-29 12:33:45
电子制作(2018年18期)2018-11-14 01:48:08
计算机工程与应用(2018年19期)2018-10-16 05:50:10
北方文学(2017年36期)2018-01-18 13:10:40
新疆大学学报(自然科学版)(中英文)(2014年1期)2014-11-02 08:36:38
民族古籍研究(2014年0期)2014-10-27 08:24:53
民族古籍研究(2012年0期)2012-10-27 08:20:41
