
产品评论挖掘中特征同义词的识别
2016-05-03 13:02郗亚辉
中文信息学报 2016年4期
郗亚辉
(河北大学 数学与计算机学院,河北 保定 071002)
产品评论挖掘中特征同义词的识别
郗亚辉
(河北大学 数学与计算机学院,河北 保定 071002)
随着电子商务的飞速发展,电子商务网站上的各种产品评论数量也在飞速增长。如何从Web中大量存在的产品评论中挖掘出对消费者和生产厂商都有价值的信息,已经成为一个非常重要的研究领域。在产品评论中,用户往往会用不同的词语描述同一产品特征。识别这些产品特征同义词才能更好地进行观点汇总。该文经过对产品评论的分析,抽取了must-link和can-not-link两类约束,并使用约束层次聚类算法识别产品特征同义词。同时,比较了几种不同产品特征相似度计算方法的结果。实验结果表明,该文的方法在实际产品评论数据集上取得了较好的效果。
产品评论挖掘;产品特征同义词;相似度;约束层次聚类算法
1 引言
飞速发展的Web技术及电子商务正在极大地改变着人们的工作和生活方式。以前,消费者往往根据产品的口碑或者广告来购买产品,很难对不同品牌的同类产品进行较全面的比较。而随着Web技术及电子商务的快速发展,电子商务网站提供了越来越多的产品,越来越多的消费者也开始习惯于通过电子商务网站购买各类产品。为了提高消费者的满意度以及改善消费者的购物体验,电子商务网站大都允许消费者对其购买的产品发表评论。在这些产品评论中,包含了消费者关于产品观点的丰富信息,它们不仅可以帮助消费者全面、综合地了解其他消费者对产品的评价,从而挑选出更适合自己的产品,还可以帮助生产厂商通过评论来了解自己产品的优势以及不足,从而改进产品的设计,获得竞争优势[1-2]。
网络上存在着大量的产品评论,有些热门商品可能包含成千上万的评论。巨大的评论数量使得消费者和生产厂商很难通过人工对产品评论进行分析和处理,获取产品评论中包含的大量有用信息。因此,以获取产品评论中有用信息为目标的非结构化数据挖掘技术——“评论挖掘”,吸引了越来越多的学者的关注。
基于产品特征的观点汇总是产品评论挖掘的任务之一[1]。首先,将产品评论中的产品特征抽取出来;然后,把产品特征对应的观点收集起来并形成基于产品特征的观点汇总。产品特征既包含产品的部件,也包含产品部件的属性。例如,“屏幕”、“屏幕分辨率”都是手机的产品特征。近年来,已经出现了一些基于产品特征的观点汇总系统。Opinion Observer[3]不仅以产品特征为单位汇总了其褒义和贬义的句子,而且以图形的方式对比了不同产品在产品特征上得到的褒义和贬义评价。Red Opal[4]依据用户对产品的评分以及评论中出现的特征计算产品在不同特征上的分值,并在此基础上给出了一个产品推荐系统。
由于人们不同的表达习惯,在产品评论中往往会用不同的词或词组来描述同一个产品特征。例如,手机的“外观”和“外型”指的是同一产品特征。在基于产品特征的观点汇总系统中,产品特征同义词的识别将直接影响汇总的效果[3]。同一产品的评论中往往就包含数百个产品特征,人工标注产品特征同义词将是一项非常耗时的工作,所以需要寻找一种自动的方法来识别产品特征同义词。
《同义词词林》《知网》[5-6]等语义字典可以用来识别产品特征同义词,但是其效果并不理想。因为一些在产品评论中描述同一特征的词或词组,在语义词典中并不是同义词。例如,“外观”和“造型”在手机评论中描述同一特征,但在语义字典中不是同义词。也可以根据产品特征间的分布相似度,用无监督的聚类算法来识别特征同义词。但实验表明,这些方法的效果也不理想。半监督聚类算法中一般以成对约束信息作为先验信息来监督聚类[7]。成对约束信息包含must-link和can-not-link两类约束,分别表示两个点应该属于同一类和属于不同类,这些信息能提高聚类效果。
本文提出了使用半监督的约束层次聚类算法识别产品特征同义词。首先,利用语义词典和产品评论中存在的先验知识构造了must-link和can-not-link两类约束;然后,利用产品特征在语料中的分布相似度进行约束层次聚类。该算法在产品特征同义词的识别中取得了较好的效果。
2 相关研究
Qiu等[8]提出了双向传播算法,利用情感词和特征词之间、情感词之间、特征词之间的语法依赖模式获取情感词和特征词的抽取模版。通过初始的情感词种子集,利用抽取模版不断迭代来获取新的特征词和情感词。该方法在中等规模的语料上表现良好,但是对于小规模和大规模的语料集其准确率和召回率都不高[9]。为了解决这个问题,Zhang等[9]引入了“no”模式和“整体-部分”模式抽取产品特征,提高了召回率,使用THIS算法对候选产品特征进行排序,提高了准确率。Xi等[10]针对中文产品评论,进一步改进了双向传播算法。
田久乐等[5]充分分析了同义词词林的编码及结构特点,利用词语中义项的编号,根据两个义项的语义距离,计算出义项的相似度,并取两个词语中最大义项相似度作为词语的相似度。在《知网》中每个词的语义由多个义原组成,所有义原根据上下位关系构成一个树状层次结构。刘群等[6]通过计算义原间的路径距离得到相似度,并将两个词各自义原中最大相似度作为两词的相似度。
Lee等[11]将词的上下文表示成空间向量,并用Cosine、Jaccard、Dice等方法计算词的相似度。Turney[12]提出了基于搜索引擎的同义词识别算法PMI-IR,利用互信息来计算两个词的相似度。Higgins[13]在PMI-IR算法的基础上提出了LC_IR算法,要求两词必须完全相邻,并且排除了词的固定搭配和修饰词对互信息计算的影响,提高了准确率。
Carenini等[14]利用领域知识建立了一个产品特征的层次模型,并根据WordNet的同义词集以及距离度量函数计算挖掘到的产品特征与该产品特征层次模型中特征的相似度,然后利用相似度将挖掘到的产品特征映射到特征层次模型。Shi等[15]人工建立了一个产品特征的层次模型,并将相似的产品特征聚集在一起。
Guo等[16]提出了无监督的Multi-LaSA算法对产品特征进行归类。首先,使用LaSA模型将产品特征中的词映射到一系列主题的集合,并根据产品特征中每个词所对应的主题,为所有特征建立潜在主题结构。然后,再次使用LaSA模型,利用产品特征的潜在主题结构以及上下文信息,将所有产品特征划分为特定的类别。Zhai等[17]针对产品特征归类,提出了一种半监督的SC-EM算法。SC-EM算法利用产品评论中特征周围特定窗口中的词构造特征的向量空间,并少量标注出一些特征的类别作为训练集,然后利用基于朴素贝叶斯分类器的半监督EM算法对产品特征进行分类。SC-EM算法在分类过程中,利用了两条先验知识来改善分类效果: 第一,含有相同字的两个产品特征可能是同类特征;第二,同义词的两个产品特征可能是同类特征。杨源等[18]对SC-EM算法进行了改进,充分考虑了产品评论中的情感因素,从语料中抽取出产品特征和情感词的搭配,利用这些搭配对形成二部图,然后用权重标准化SimRank算法[19]计算各个产品特征之间的相似度,并把所得的结果与SC-EM算法中的贝叶斯分类器进行融合,得到了更好的分类结果。
半监督聚类算法允许利用一些先验知识来限制或指导聚类算法,从而提高聚类效果[20-22]。成对约束是一种常用的先验知识表示形式。Wagstaff和Cardie[20-21]提出了must-link和can-not-link两类约束,must-link约束表示两个点应该属于同一类别,而can-not-link约束表示两个点不应属于同一类别。Klein等[7]进一步扩展了must-link约束,认为不仅两个满足must-link约束的点应该属于同一类别,而且这两个点邻近的点也更倾向于属于同一类别。Zhai等[23]根据对产品评论的大量分析,进一步扩展了产品特征归类的约束规则: 含有相同字的两个产品特征可能是同类特征,在同一句子中出现的产品特征可能不是同类特征;然后,根据这两种规则构造了must-link和can-not-link约束,并利用半监督的LDA算法对产品特征进行聚类。
3 算法描述
本文提出了半监督的层次聚类算法来识别产品特征同义词。针对中文产品评论,首先抽取了产品特征及其情感词;其次,对每个产品特征抽取其上下文词汇构造相应的特征向量,并根据特征向量计算产品特征间的相似度;再次,利用语义词典和产品评论中存在的先验知识构造了must-link和can-not-link两类约束来指导产品特征同义词的聚类过程;最后,使用半监督的层次聚类算法完成产品特征同义词的识别。
3.1 产品特征及其情感词的获取
产品特征及其情感的抽取是产品评论挖掘的基本工作之一,很多学者提出了各种算法来完成这项工作[1-3,8-10]。本文利用双向传播算法[10]完成产品特征及其情感词的抽取工作。双向传播算法利用情感词和产品特征之间的语法依赖模式抽取产品特征及其情感词,不需要标注大量的训练数据,只需要一部分情感词种子就可以完成抽取任务。
3.2 上下文词汇抽取
为了计算产品特征间的相似度,需要为每一个产品特征构造相应的特征向量。产品特征的特征向量由其上下文中的词汇构成,本文采用了两种上下文的抽取方式。
基于窗口的上下文抽取: 将产品评论中所有包含产品特征Fi的句子抽取出来形成集合Si,然后遍历集合Si,把每个句子中产品特征Fi周围特定窗口[-t,t]中的词抽取出来,去掉停用词后形成Fi的特征向量vi。本文根据实验,将窗口大小t设为3。例如,在包含产品特征“屏幕”的句子“手机屏幕的分辨率非常高”中,抽取的上下文为“手机,分辨率,高”,其中“的”和“非常”由于是停用词而被去掉。
基于挖掘结果的上下文抽取: 双向传播算法利用产品特征和情感词间的句法依赖抽取产品特征及其情感词;将挖掘结果中产品特征Fi周围特定窗口中的动词和名词,以及Fi对应的情感词抽取出来,形成其特征向量vi。
3.3 相似度计算
3.3.1 语义词典相似度
《同义词词林扩展版》[24]是哈尔滨工业大学信息检索实验室编制的一部同义类词典,按照树状层次结构把所有收录的词组织在一起,将词分成大、中、小三类。每个小类中都包含若干行,同一行的词语词义相同或有很强的相关性。本文利用《同义词词林扩展版》来进行产品特征同义词的判别。
知网(HowNet) 是一个以汉语和英语词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。每个词的语义由多个义原组成,所有义原根据上下位关系构成一个树状层次结构。本文利用文献[6]中的算法来计算产品特征间的相似度。
3.3.2 余弦相似度
在产品评论中,描述同一产品特征的特征同义词往往具有相似的上下文。例如,“屏幕”和“触摸屏”都经常和“分辨率”、“清晰”等词汇共同出现。基于语义词典的相似度并没有利用产品评论中特征的上下文信息。将产品特征周围的词表示成向量空间中的特征向量,使用词的TF-IDF值作为其向量中的权重,可以用余弦相似度计算两个产品特征的相似度如式(1)所示。
(1)
3.3.3 加权SimRank相似度
产品特征和其上下文中的词汇可以形成一张二部图(如图1所示),左边是产品特征,右边是产品特征的上下文词汇,由上下文词汇指向产品特征形成了图中的有向边。
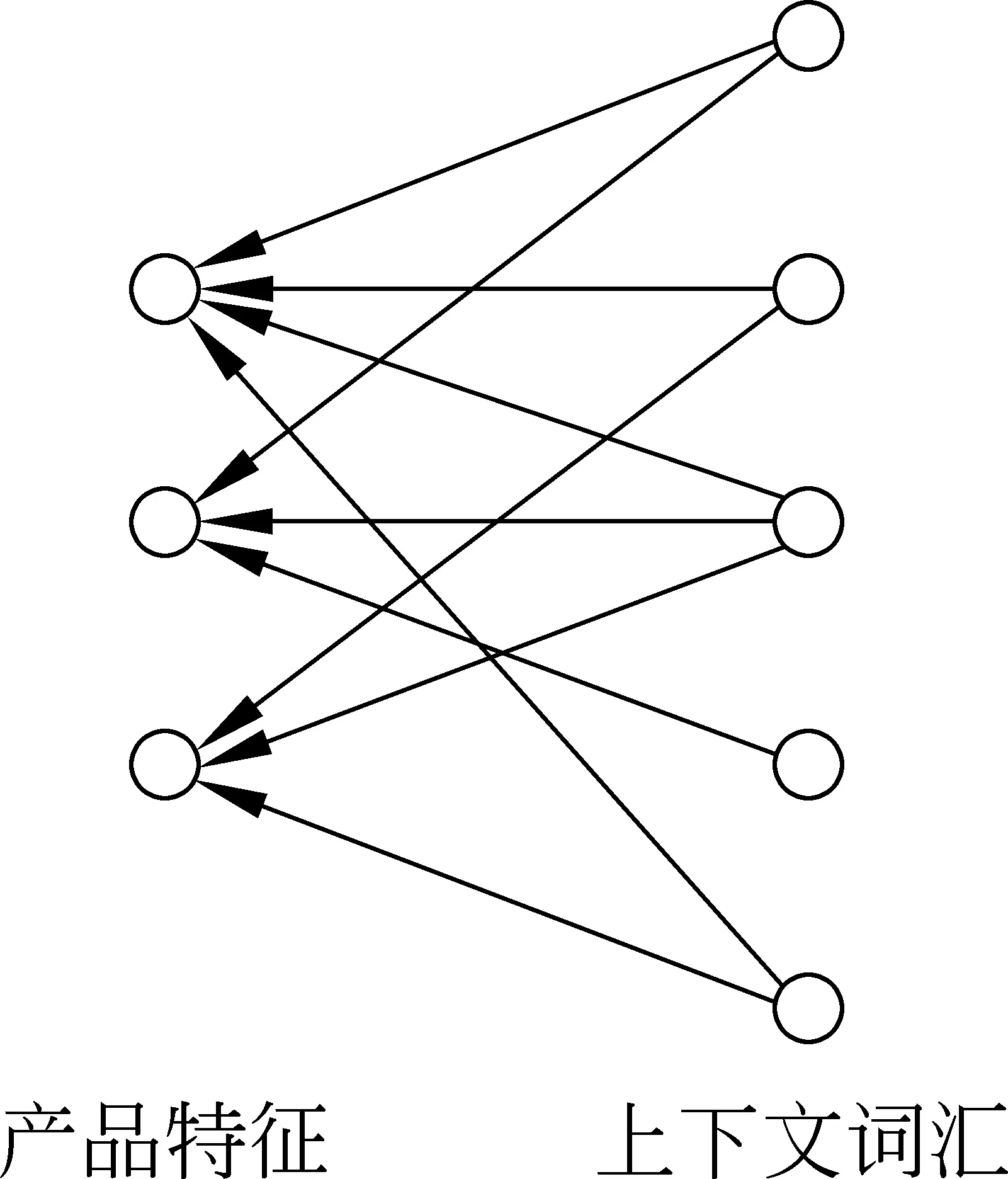
图1 产品特征及其上下文词汇形成的二部图
SimRank算法[26]是由Jeh等人提出的结构相似度算法,利用图的结构信息来计算对象的相似度。其思想是: 与相似节点相连的结点相似。产品特征同义词往往具有相似的上下文词汇,因此可以利用SimRank算法来计算产品特征的相似度。SimRank算法的计算公式如式(2)所示。
(2)
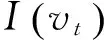
SimRank在计算节点间相似度的时候仅利用了有向图的结构信息,而没有考虑有向边的权重。也就是说没有利用产品特征上下文中不同词汇的权重信息。本文采用了马云龙等人[19]提出的权重标准化SimRank算法(NormalizedWeightSimRank)计算产品特征的相似度。
NWS算法首先对图中每个节点的入边权重进行标准化,使之对于任意节点vt均满足式(3)。
(3)
NWS算法的计算公式如式(4)和式(5)所示。
(4)
(5)
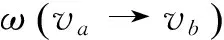
(6)
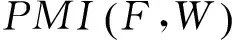
3.4 约束条件
约束聚类能利用约束信息指导聚类过程,但聚类性能的提升很大程度上依赖于约束的选取。为了对产品特征同义词聚类,本文抽取了must-link和can-not-link两类约束。经过对语料中大量产品特征的分析,我们发现了两个规则: 首先,用户往往用一个词组表达多个产品特征。例如,在句子“屏幕分辨率很高”中,词组“屏幕分辨率”描述了“屏幕”和“分辨率”两个产品特征。但同一词组中出现的多个产品特征一般具有上下位关系,不是同义词。其次,用户经常在一个句子中评论多个产品特征。例如,“屏幕清晰,电池耐用。”但句子中相邻两个特征一般不是同义词。同时我们利用了语义字典《同义词词林扩展版》中的同义词联系,抽取出如下的约束。
Must-link约束: 如果两个产品特征在语义字典中是同义词,那么它们属于同一类。
Can-not-link约束1: 如果两个产品特征出现在同一产品特征词组中,那么它们不属于同一类。
Can-not-link约束2: 如果两个产品特征在句子中相邻,那么它们不属于同一类。
3.5 约束层次聚类
以must-link和can-not-link成对约束形式表示的聚类算法是一种典型的约束聚类算法,能有效地提高聚类效果[20-22]。对聚类算法添加约束条件后,能使聚类结果满足所有约束条件,但却没有深入挖掘这些约束条件的隐含信息[7]。例如,图2(a)为原始数据,图2(b)中双线相连的两点表示满足must-link约束的点,图2(b)和图2(c)的聚类结果都满足所有约束条件,但图2(c)的聚类结果更好。因为这两对must-link约束隐性地改变了其周围点的相互关系,不仅两个must-link约束的点应属于同一聚类中,和这两个点非常邻近的点也应该属于同一聚类。同样,can-not-link约束也有类似的性质。

图2 添加两个must-link约束的聚类结果
3.5.1 实施和传递约束
聚类算法通常需要维护一个数据集中实例间的距离矩阵。针对给出的must-link和can-not-link成对约束,按照如下基本原则更新距离矩阵。
原则1: 如果一个实例对属于must-link约束集合,那么应该使这两个实例之间的距离尽可能近。
原则2: 如果一个实例对属于can-not-link约束集合,那么应该使这两个实例之间的距离尽可能远。
为了进一步利用约束条件所包含的隐性信息,按照如下的两个传播原则更新距离矩阵,以传播约束的信息。
原则3: 如果两个实例属于must-link约束集合,那么与这两个实例距离相近的实例间的距离也应该很近,如图3所示。
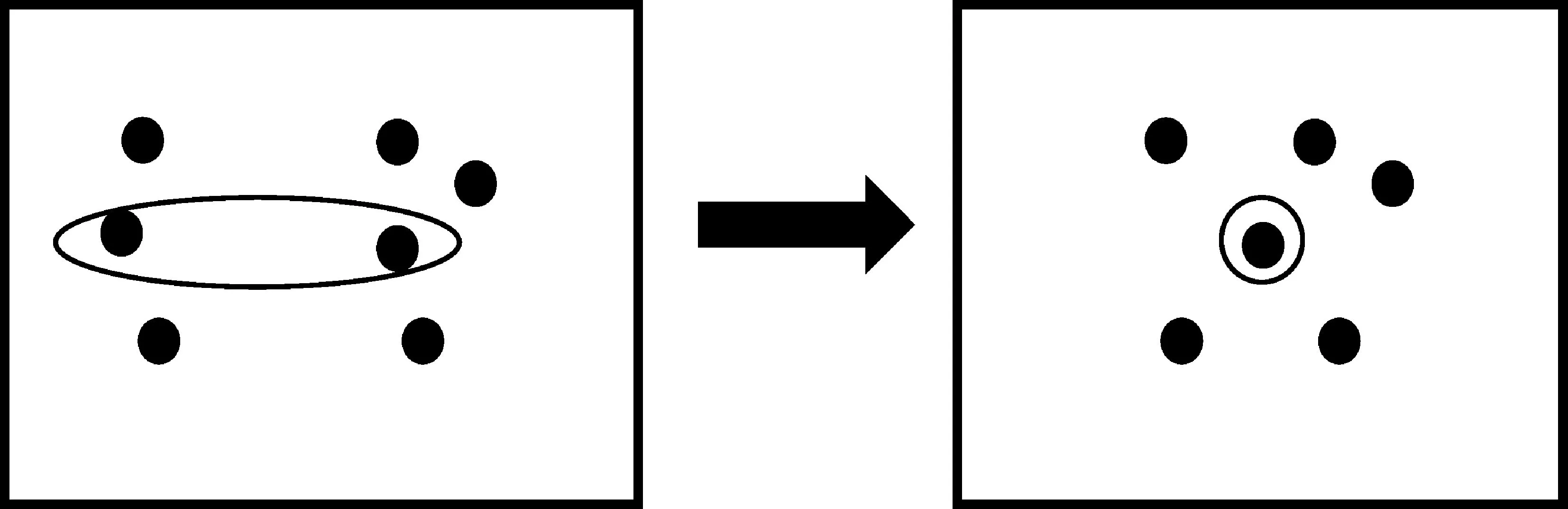
图3 must-link约束对实例间距离的影响
原则4: 如果两个实例属于can-not-link约束集合,那么与这两个实例距离相近的实例间的距离也应该很远,如图4所示。
3.5.2Must-link约束
对于must-link约束的实例,需要减小部分实例间的距离。将距离矩阵对应到一张图,矩阵的值作为图上点之间的距离。首先,将must-link约束集合中实例间的距离设为0;然后,减小那些经过两个must-link约束点的路径上点之间的距离。如图5所示,A与C的距离为2,B与C的距离为2,由于B和C满足must-link约束,所以将B和C的距离设为0,A和C之间有路径A→B→C,而A到B的距离为1,所以A到C的距离更新为其最短路径1。
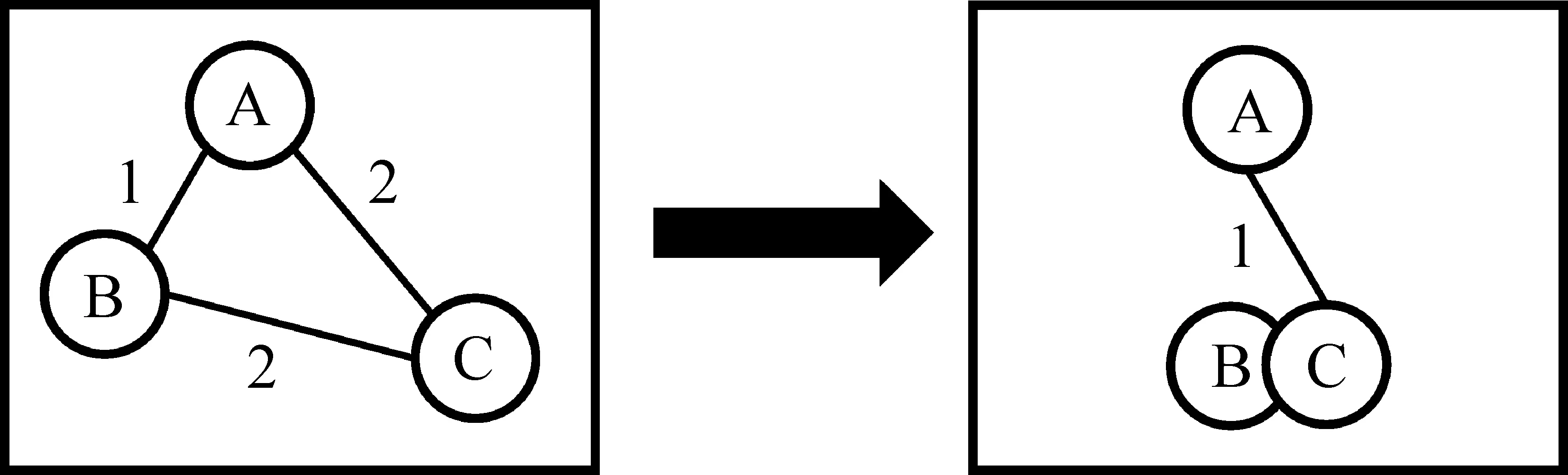
图5 距离更新示例
可以看出,更新距离矩阵的过程就是找出所以经过must-link约束点的路径,并将路径上点之间的距离改为最短路径。可以通过多源最短路径算法来解决这个问题,这里我们使用如下所示的修正Floyd-Warshall算法来更新距离矩阵的值。
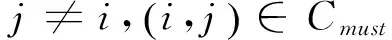

3.5.3Can-not-link约束
对于can-not-link约束的实例,需要增大其实例间的距离。如果同时利用must-link约束和can-not-link约束的传播原则更新距离矩阵,时间复杂度太大。因此,我们处理can-not-link约束时,只将其相关实例的距离设为极大值。但在聚类算法中,选择两个类中实例间的最大距离作为两个类的距离,从而隐式地满足了can-not-link约束的传播原则。
3.5.4 聚类算法
本文使用加入must-link约束和can-not-link约束的凝聚层次聚类算法来识别产品特征同义词,其具体算法如下:
Input:Distance MatrixD, ConstraintsC
Output:Cluster
Function:
1. for (i,j)∈Cmust
2.Dij,Dji= 0
3.I=i: ∃j≠i,(i,j)∈Cmust
4. fork∈I, fori∈{1:n},forj∈{1:n}
5.Dij= min(Dij,Dik+Dkj)
6. for (i,j)∈Ccannot
7.Dij,Dji= ∞
8.Cluster= {cifor each pointi}
9. distancesd(ci,cj) =Dij
10.while |Cluster| > 1
11. choose closest (c1,c2) = argminc1 ,c2∈Clusterd(c1,c2)
12. mergc1andc2intocnewinCluster
13. forci∈Cluster
14.d(ci,cnew) = max(d(ci,c1),
d(ci,c2))
4 结果分析
4.1 实验数据
本文的产品评论数据都取自一些电子商务网站以及评论网站。网络上存在着大量的电子商务网站以及评论网站,经过分析我们选择了亚马逊、京东商城、中关村在线、it168这四个典型的网站作为我们评论数据的来源。电子产品是网络上评论数量最多的一类产品,本文选择了以上网站中的手机、数码相机这两种典型电子产品的评论来构造实验用的评论数据集。首先,将数据集中所有评论切分为句子,并用哈尔滨工业大学自然语言处理平台进行词性标注和语法分析,表1给出了数据集中评论和句子的数量;然后,用双向传播算法抽取产品特征及其情感词,并手工标注产品特征同义词。

表1 实验数据集
4.2 评价标准

(7)

(8)
其中,a表示在C和P中都属于同一类的样本对个数;b表示在C中属于同一类,但在P中不属于同一类的样本对个数;c表示在C中不属于同一类,但在P中属于同一类的样本对个数;d表示在C和P中都不属于同一类的样本对个数。
4.3 实验结果
本文使用了几种产品特征相似度的计算方法,包括: 基于《同义词词林扩展版》的同义词识别;基于《知网》的相似度[6];基于产品特征上下文信息的TF-IDF余弦相似度和加权SimRank相似度。表2对比了基于这几种相似度计算方法的层次聚类结果。
从表2的结果中可以看出,使用《同义词词林扩展版》识别产品特征同义词可以获得较好的效果。其他几种相似度计算方法中,基于产品特征上下文信息的TF-IDF余弦相似度效果最好。利用《同义词词林扩展版》能够准确地识别产品特征同义词,但很多产品特征同义词并不在其中。例如,“屏幕”和“触屏”在《同义词词林扩展版》中不是同义词,但是产品特征同义词。因此需要结合产品特征上下文信息识别这些同义词。基于《知网》的相似度考虑了词的义原的上下位关系,有些具有很大相似度的词并不是同义词,例如,“电池”和“键盘”的相似度很大,因此该方法效果并不好。在产品评论中, 描述同一产品特征的特征同义词往往具有相似的上下文, 因
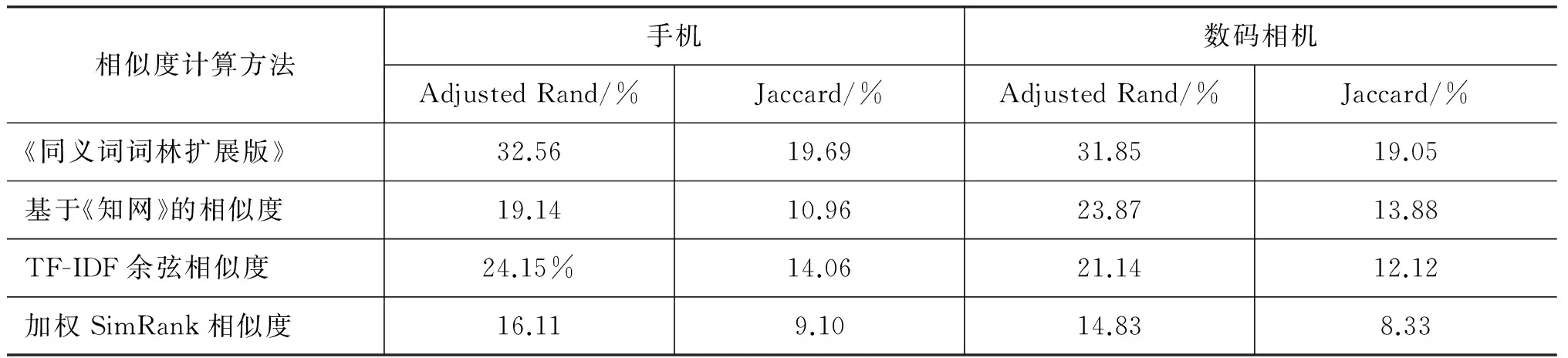
表2 不同相似度计算方法的层次聚类结果
此可以通过产品特征的上下文信息识别产品特征同义词。在产品评论语料上,TF-IDF余弦相似度表现的比加权SimRank相似度更好。仅靠上下文信息,产品特征同义词识别的效果也不理想,因为有些经常出现的特征搭配具有相似的上下文,但它们并不是同义词。例如,“摄像头”和“分辨率”经常在一起搭配出现,因此具有相似的上下文。
本文采用了两种上下文的抽取方式: 基于窗口的上下文抽取和基于挖掘结果的上下文抽取。表3对比了使用TF-IDF余弦相似度时这两种上下文抽取方式的效果。从实验结果可以看出基于窗口的上下文抽取方式效果更好。其主要原因是双向传播算法使用情感词和产品特征之间的语法依赖模式抽取产品特征及其情感词,由于自然语言处理技术的限制,产品特征和情感词的准确率和召回率都不是很高,因此影响了特征向量的构建及相似度计算。

表3 不同上下文抽取方式的聚类结果
约束聚类可以利用一些约束规则指导聚类算法,从而提高聚类效果。我们基于窗口上下文抽取的TF-IDF余弦相似度作为产品特征间相似度的计算方法,并使用3.4节中的约束条件指导聚类过程,其结果如表4所示。
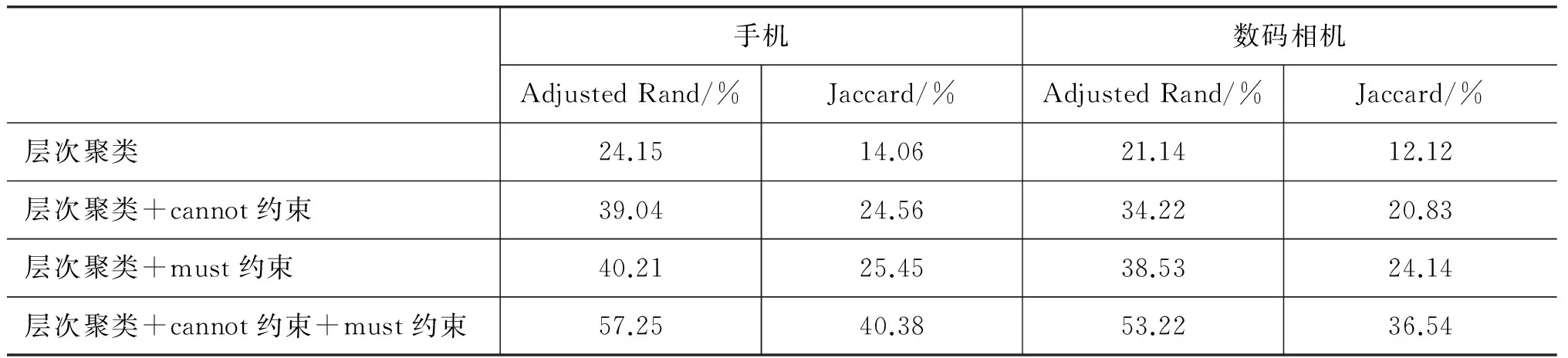
表4 约束聚类结果
从结果中可知: 首先,所有的约束层次聚类都比原始层次聚类效果好,证明了约束聚类在产品特征同义词识别中的有效性;其次,单独使用must-link约束和can-not-link约束都能改善聚类的效果,证明了这两类约束规则的有效性;最后,相对于单独使用这两类约束,联合使用must-link约束和can-not-link约束能较大改善聚类效果,证明了同时使用这两类约束的必要性。
5 结论和进一步的工作
在基于产品特征的观点汇总系统中,产品特征同义词的识别将直接影响汇总的效果。本文抽取了must-link和can-not-link两类约束,并在此基础上提出了约束层次聚类算法来识别产品特征同义词,并对比了几种不同产品特征相似度计算方法的效果。在两种电子产品评论语料集上验证了我们方法的有效性。下一步我们将探索更多的约束规则、相似度计算方法和聚类算法以提高产品特征同义词识别的效果。
[1] M Hu, B Liu. Mining and summarizing customer reviews[C], Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA: ACM Press, 2004:168-177.
[2] A M Popescu, O Etzioni. Extracting product features and opinions from review[C]//Proceedings of the Human Language Technology Conference and the Conference on Empirical Methods in Natural Language Processing. Stroudsburg, USA :Association for Computational Linguistics, 2005:339-346.
[3] B Liu, M Hu, J Cheng. Opinion Observer: Analyzing and Comparing Opinions on the Web[C]//Proceedings of WWW. Chiba,Japan:ACM Press, 2005:342-351.
[4] C Scaffidi, K Bierhoff, E Chang. Red Opal: Product-Feature Scoring from Reviews[C]//Proceedings of 8th ACM Conference on Electronic Commerce. New York, USA:ACM Press,2007:182-191 .
[5] 田久乐, 赵蔚. 基于同义词词林的词语相似度计算方法[J]. 吉林大学学报(信息科学版), 2010,28(6):602-608.
[6] 刘群, 李素建. 基于《知网》的词汇语义相似度计算[J]. 中文计算语言学, 2002,7(2):59-76.
[7] D Klein, S D Kamvar, C D Manning. From instance level constraints to space-level constraints: making the most of prior knowledge in data clustering[C]//Proceedings of the 19th International Conference on Machine Learning .San Francisco, USA:Morgan Kaufmann Publishers,2002:307-314.
[8] G Qiu, B Liu, J Bu, et al. Chen. Expanding domain sentiment lexicon through double propagation. Proceedings of the 21st International Joint Conference on Artificial Intelligence. Pasadena, USA:AAAI Press,2009:1199-1204.
[9] L Zhang, B Liu, S H Lim, et al. Extracting and ranking product features in opinion documents [C]//Proceedings of the 23rd International Conference on Computational Linguistics . Beijing, China : Association for Computational Linguistics,2010: 1462-1470.
[10] Y Xi. Extracting Product Features from Chinese Product Reviews [J]. Journal of Multimedia, 2013,8(6):647-654.
[11] L Lee.Measures of Distributional Similarity[C]//Proceedings of the 37th annual meeting of the Association for Computational Linguistics on Computational Linguistics. Maryland, USA: Association for Computational Linguistics,1999:25-32.
[12] P D Turney. Mining the Web for Synonyms: PMI-IR versus LSA on TOEFL[C]//Proceedings of the 12th European Conference on Machine Learning. Freiburg, Germany: Springer-Verlag,2001:491-502.
[13] D Higgins. Which statistics reflect semantics? rethinking synonymy and word similarity[C]//Proceedings of the International Conference on Linguistic Evidence. Tübingen,Germany: Walter de Gruyter,2004:265-284.
[14] G Carenini, R T Ng, E Zwart. Extracting Knowledge from Evaluative Text[C]//Proceedings of the 3rd International Conference on Knowledge Capture. New York, USA: ACM Press, 2005:11-18.
[15] B Shi, K Chang. Mining Chinese Review[C]//Proceedings of the 6rd International Conference on Data Mining. Washington, USA:IEEE Computer Society, 2006:585-589.
[16] H Guo, H Zhu, Z Guo, et al. Product feature categorization with multilevel latent semantic association[C]//Proceedings of the 18th ACM conference on Information and knowledge management. Hong Kong: ACM Press, 2009:1087-1096.
[17] Z Zhai, B Liu, H Xu, et al. Grouping Product Features Using Semi-Supervised Learning with Soft-Constraints[C]//Proceedings of the 23rd International Conference on Computational Linguistics. Beijing, China:Association for Computational Linguistics, 2010:1272-1280.
[18] 杨源,马云龙,林鸿飞. 评论挖掘中产品属性归类问题研究[J]. 中文信息学报. 2012, 26(3):104-108.
[19] Y L Ma, H F Lin, S Jin. A Revised SimRank Approach for Query Expansion[C]//Proceedings of the 6th Asia Information Retrieval Societies Conference. Taipei: Springer-Verlag, 2010:564-575.
[20] K Wagstaff, C Cardie. Clustering with Instance-level Constraints[C]//Proceedings of the Seventeenth International Conference on Machine Learning. Stanford, USA: AAAI Press,2000: 1103-1110.
[21] K Wagstaff, C Cardie, S Rogers, et al. Constrained k-means Clustering with Background Knowledge [C]//Proceedings of the Eighteenth International Conference on Machine Learning. Williamstown, USA: AAAI Press,2001: 577-584.
[22] S Basu, A Banerjee, R Mooney. Active Semi-supervision for Pairwise Constrained Clustering[C]//Proceedings of the SIAM International Conference on Data Mining. Lake Buena Vista, USA:SIAM,2004:333-344.
[23] Z Zhai, B Liu, H Xu, et al. Constrained LDA for Grouping Product Features in Opinion Mining. Proceedings of the 15th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining. Shenzhen, China: Springer-Verlag,2011:448-459.
[24] 同义词词林(扩展版),哈尔滨工业大学信息检索研究室:http://ir.hit.edu.cn/[EB/OL].
[25] 知网, 董振东:http://www.keenage.com/[EB/OL].
[26] G Jeh, J Widom. SimRank: A Measure of Structural-Context Similarity[C]//Proceedings of the 8thACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Edmonton, Canada: ACM Press, 2002:538-543.
Recognizing the Feature Synonyms in Product Review
XI Yahui
(College of Mathematics and Computer Science, HeBei University, Baoding, Hebei 071002, China)
With the great development of e-commerce, the product review mining has recently received a lot of attention. In product reviews, people often use different words and phrases to describe the same product feature, which are necessary to be recognized as synonyms for effective opinion summary. In this paper, we first calculate the similarity of product features. Then the must-link and cannot-link constraints are exacted based on the analysis of product reviews. Finally, the constrained hierarchical clustering algorithm and the extracted constraints are applied to recognize product feature synonyms. Experiments on diverse real-life datasets show promising results.
product review mining; product feature synonyms; similarity; constrained hierarchical clustering algorithm

郗亚辉(1977-),男,副教授,主要研究领域为文本挖掘、信息检索。E-mail:xiyahui@hbu.edu.cn
1003-0077(2016)04-0150-09
2014-10-27 定稿日期: 2015-04-30
国家自然科学基金(61170039)
TP391
A
猜你喜欢
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
小学阅读指南·低年级版(2017年1期)2017-03-13
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
人生十六七(2015年6期)2015-02-28
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
计算机辅助工程(2012年5期)2012-11-21
