
基于拓扑特征的纳西东巴文象形文字输入方法研究
2016-05-03 13:02:00王海燕王红军徐小力
中文信息学报 2016年4期
王海燕,王红军,,徐小力
(1. 北京信息科技大学 机电学院,北京 100192;2. 北京信息科技大学 现代测控技术教育部重点实验室,北京 100192)
基于拓扑特征的纳西东巴文象形文字输入方法研究
王海燕1,王红军1,2,徐小力2
(1. 北京信息科技大学 机电学院,北京 100192;2. 北京信息科技大学 现代测控技术教育部重点实验室,北京 100192)
纳西东巴文字是一种比甲骨文还要原始的图画象形文字,该文针对大量纳西经典古籍资料需要录入、整理、分析的需要,设计一种普通用户即可使用的基于拓扑特征的输入方法。首先针对纳西东巴象形文字的1 561个基本字形的五个拓扑特征-块数、孔数、端点数、三叉点数和四叉点数进行了统计和分析,然后基于Java程序结合TTF字库文件进行了测试,证明了该方法可行。统计结果表明,50%以上的纳西东巴象形文字通过这五个特征可以唯一识别,80%以上的东巴文字通过该方法识别时重复数不高于4,人工输入、识别的效率较高,为纳西东巴象形文字的输入方法提供一种新的思路。
纳西;东巴;象形文字;输入方法
1 引言
东巴文是一种兼备表意和表音成分的图画象形文字,其文字形态十分原始,甚至比甲骨文的形态还要原始,属于文字起源的早期形态,是世界上极少数依旧活着的象形文字,被誉为文字的“活化石”[1],被国际学界认为是当今世界上唯一还在使用的象形文字[2]。之所以被称为东巴文,是因为这是纳西族特有的宗教-东巴教的东巴(智者的意思)们所使用的文字,至今仍被在世的东巴祭司使用,用来主持各种仪式、写信、记账等。东巴们使用这种文字记录的经书称为东巴经(图1),2003年纳西族东巴经典古籍被联合国教科文组织列为“世界记忆遗产”(Memory of the World)。
东巴经典古籍内容涉及哲学、历史、宗教、医学、天文、地理、民俗、动植物、军事、文学和艺术等领域,堪称纳西族古代社会的百科全书[3-4]。但是东巴文一般不容易释读,一直被视为“天书”[5],目前只有该领域的专家学者和几个已年逾古稀的老东巴祭司能释读。同时,由于历史原因,大多数东巴经典原始手稿在一个世纪前甚至更早,就被世界上许多著名图书馆和博物馆所收藏,其内容又不被收藏者所了解。因此,针对东巴经典古籍急需抢救的濒危状况,建立了国家社会科学基金重大项目-“世界记忆遗产”东巴经典传承体系数字化国际共享平台建设研究(项目号: 12&ZD234),实现东巴文化资源的信息化传播,并推动东巴传统文化的保护与发展。
2 东巴经典古籍的数字化
古籍数字化就是采用计算机技术,对古籍文献进行加工、处理,制成古籍文献书目数据库和古籍全文数据库,用以揭示古籍文献中所蕴涵的极其丰富的信息资源,从而达到使用和保护古籍的目的[6]。从国内外古籍数字化的实践来看,民族古籍数字化涉及的技术领域非常广泛, 包括三维建模、人工智能、声频、视频技术、语言处理技术、光学字符识别等几十种相关技术。刘洋等利用数字化技术中的虚拟技术较好地解决由于敦煌地域偏远所带来的参观不便,使人们可以免去长途跋涉而欣赏到敦煌的精彩壁画[7]。
本项目组第一子课题主要进行东巴经典的数字化信息采集与释读过程数字记录,工作包括对国内外收藏信息进行汇集,召开国际研讨会,与收藏机构签订协议,实现无争议共享,对国内外藏品实施数据采集;按国际惯例对东巴祭司释读过程进行现场记录;本项目的第二子课题主要进行东巴经典象形文的释读、翻译与编目整理的研究,通过开展田野调查,进行书目整理和编目;共同分析各国藏本的存量、来源、时间等;以学术成果为基础进行调研、分类与整理,对现存编目进行审核、整理、修正与充实。

图1 丽江市玉龙纳西族自治县鲁甸乡收集的用象形文字书写的古代东巴经书
通过资料的整理与汇总,并借助计算机和网络技术进行存储,形成包括纳西语、汉语、英语的多语语料库,为信息检索和知识库提供素材,为纳西东巴文字库的建立奠定了基础。但是由于纳西东巴象形文字只有极少数的人能够辨识, 很多原始资料的利
用效率太低,文字的辨识、整理工作非常困难,同时能兼具纳西东巴文知识、现在汉语知识并熟练应用计算机的人非常少,所以建立一种方便快捷的纳西东巴象形文字的输入法非常必要。
3 纳西东巴象形文字拓扑特征统计
通过在丽江研究院调研,目前应用的纳西东巴象形文输入法主要有云龙公司的国际音标输入法和杨晓辉的电子东巴输入法。前者通过输入国际音标,输出对应的纳西文字,后者有两种输入形式: (1)通过输入纳西音标,输出对应的纳西象形文字;(2)通过输入汉字,输出对应的纳西象形文字。 这三种方法需要用户本身对纳西文字比较熟悉,仅仅适用于纳西东巴文专家,而对于国际共享平台来说,不能满足其他文字研究专家、社会研究专家、历史研究专家以及一般用户的需求,因此,需要开发一种更加简易、容易理解及易于结合图像处理的输入方法。
3.1 拓扑特征的提取
纳西象形文字是一种图画文字,不具备现代汉字那样规范的笔画和顺序,跟甲骨文类似,表现出线条图的特征,因此可以引用图论中图的概念,把纳西象形文字抽象为图论中的平面无向图来处理,提取其拓扑特征作为识别的依据,初步提取的拓扑特征有: 块数、孔数、端点数、叉点数四种,说明如下:
(1) 块数: 即图论中的连通分支,即块的个数;
(2) 孔数: 即图论汇总的内网孔数;
(3) 端点数: 即图论中度数等于1的顶点,对应于字符中线条的末端;
(4) 叉点数: 即图论中度数大于2的顶点,对应于线条的交点,包括三叉点、四叉点、五叉点等。因为是试验性的研究,故目前仅测试了三叉点和四叉点。
纳西古籍中象形文字的变体较多,即同一个字有多种不同的书写形式,目前统计了1 561个基本字形的拓扑特征,同时为了简化输入工作量,将以上四种特征数大于9的统一标记为9,得到的统计特征如表1所示。
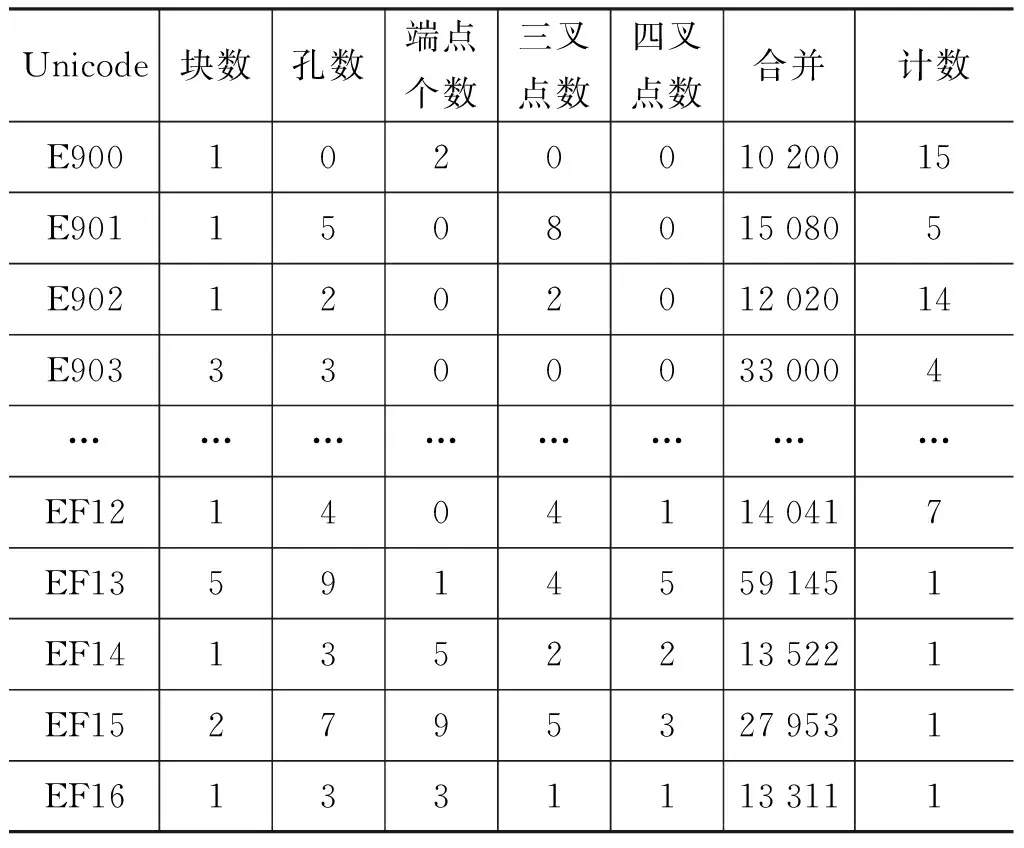
表1 纳西象形文字基本字体拓扑特征统计
3.2 识别统计
对纳西象形文字的基本字体进行拓扑特征统计后,测试其识别效率,步骤如下。
(1) 单独记录所有的纳西骨架字体中的特征数,如: 块数,孔数,端点个数,三叉点数,四叉点数;
(2) 将特征数合成一个字符串,如E900的块数目为1,空数为0,端点个数为2,三叉点和四叉点个数都为0,则合并字符串为: “10200”;
(3) 统计不同特征组合字符串的重复数量。比如统计特征字符串“10200”的个数为15,表明具有同样特征的纳西文字共有15个;而符合特征字符串“59145”的纳西文字仅有1个。
得到的识别统计表如表2所示, 得到的统计直方图如图2所示。可以看出,有一半以上的东巴字通过五个拓扑特征可以唯一定位,有80%以上的东巴字通过这五个特征进行定位时重复数仅有四个,94.3%的东巴字用这五个特征数进行定位时重复数不高于10。
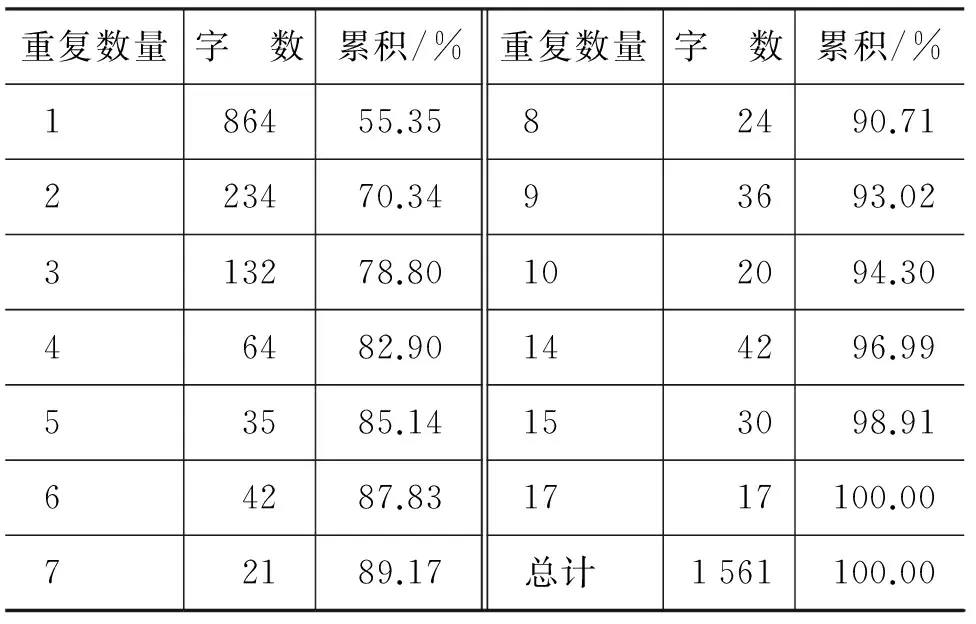
表2 纳西象形文字识别统计表
4 纳西象形文字的显示
得到纳西象形文字的拓扑特征后,可以写入统计数据库,然后再结合字库文件进行显示。曲线轮廓纳西象形文字库一般采用TrueType字库结构,这种字库文件由文件首、文件描述表、目录表和描述表四大部分组成。文字读取采用多级映射字库访问机制,即当用户使用TTF (TrueType Font)纳西文字时,只需给出该纳西文字的机内码,TTF解释器便查找cmap表得到该纳西文字在loca表中的文字字模序号,再从loca表中获得对应纳西文轮廓数据的存放地址,再从glyf中读出轮廓数据。
因此,基于拓扑特征的纳西象形文字输入方法可以总结为:
(1) 基础: 建立基于纳西象形文字拓扑特征的统计数据库;

(3) 输出: 通过客户端读取用户的输入,在数据库查找匹配拓扑特征的纳西象形文字,然后输出到客户端;
(4) 选择: 用户根据需求确定需要输出的纳西象形文字。

图3 从符合特征124**的11个选择中确定“”
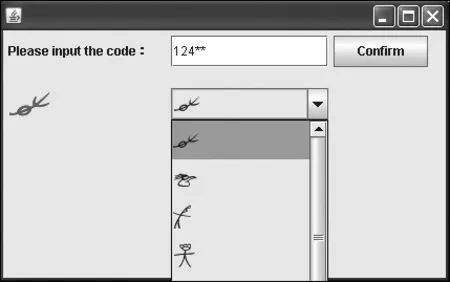
图4 符合特征1240*的唯一纳西象形文字“”
5 结论
纳西东巴象形文字对于民族文化和人类文化的传承有非常重要的作用,其输入方法是国际共享平台中非常关键的一步。因为东巴文字不为一般用户所认识,目前只有该领域的为数不多的专家学者和几个已年逾古稀的老东巴祭司能够释读。针对大量
的东巴古籍需要进行录入、整理、统计分析的现状,在音标输入法、对应汉字输入法之外设计一种新的输入方法,即根据纳西象形文字的拓扑特征进行识别,针对1 561个东巴象形文字的五个拓扑特征(块数、孔数、端点数、三叉点数、四叉点数)进行统计,然后结合TTF字库文件利用Java程序进行文字的录入和显示,为东巴象形文字的输入提供一种新的思路。
东巴象形文字的变体较多,文章仅统计了基本字形,随着研究的深入,需要增加更多扩展字形的统计信息;同时,对于拓扑特征的优化选择及配置,需要进一步的试验,以提高输入效率和识别效率。
致谢 感谢国家重大社科基金对于本研究的支持,感谢丽江东巴文化研究院对本研究工作的支持。
[1] 林向萧. 关于“东巴文是什么文字”的再探讨 [J]. 云南民族学院学报, 2002, 19(5): 83-89.
[2] X L Xu, G X, H J Wang, et al. Construction of an International IT-Driven Sharing Platform for Inheriting and Communication of Dongba Manuscripts [J]. Applied Mechanics & Materials, 2014, 610: 760-763.
[3] 白庚胜. 白庚胜纳西学论集 [M]. 北京: 民族出版社, 2008.
[4] Zheng Liping. The Living Hieroglyphs, The Picture and Characters of Naxi Dongba [J]. Art and Design, 2009, 12: 311-313.
[5] Nishida Tatsuo. The Living Hieroglyph-Naxi Nationality’s Culture [M]. Japan Public Books.1996.
[6] 牛惠萍, 张琳. 对我国古籍数字化相关问题的研究 [J]. 当代图书馆, 2006, 85(1): 39-42.
[7] Liu Yang, Lu Dongming, Diao Changyu, et al. Dunhuang 284 Cave Multimedia Integrated Virtual Exhibit [J]. Journal of Computer-aided Design & Computer Graphics, 2004, 16(11): 1528-1534.
Research on Input Method of Naxi Dongba Hieroglyphs Based on Topological Characteristics
WANG Haiyan1, WANG Hongjun1,2, XU Xiaoli2
(1. School of Electromechanical Engineering, Beijing Information Science and Technology University, Beijing 100192, China;2. Key Lab of Modern Measurement & Control Technology (BISTU), Ministry of Education,Beijing Information Science and Technology Univerity, Beijing 100192, China)
Naxi Dongba characters are a kind of pictographs that is even more primitive than Oracle pictographs. As there is a large number of ancient Naxi classical books are needed to be protected and input into the computer system, an input method based on the topological characteristics of Dongba characters is designed for ordinary users. Firstly, the five basic topological features including number of blocks, number of holes, end points counts, three-connection-points counts and four-connection-points counts of 1,561 Naxi Dongba characters are after statistics and recorded. After that, this method is tested by a Java-based program combined with TTF font file and it proves that the method is feasible. Statistics show that more than 50% of Dongba pictographs can be identified uniquely through these five characteristics and more than 80% of them can be identified by this method with no more than 4 repetitions. It provides a new way to input Naxi Dongba hieroglyphs with the manual input and with high efficiency of identification.
Naxi; Dongba; hieroglyphs; input method

王海燕(1979-),硕士,讲师,主要研究领域为系统优化、信息化。E-mail:asmylady@163.com王红军(1966-),博士,教授,主要研究领域为信息化、故障诊断等。E-mail:wanghj86@163.com徐小力(1951-),博士,教授,博士生导师,主要研究领域为光机电信息及数字化网络化技术。E-mail:xuxiaoli@bistu.edu.cn
1003-0077(2016)04-0106-04
2014-02-17 定稿日期: 2015-06-09
国家社科基金(12&ZD234)
TP391
A
猜你喜欢
云南档案(2021年1期)2021-04-08 11:01:14
云南档案(2021年1期)2021-04-08 11:01:12
奇闻怪事(2020年12期)2020-12-21 03:57:51
大连民族大学学报(2020年2期)2020-06-16 03:12:46
民族古籍研究(2018年1期)2018-05-21 00:40:22
读者(2017年2期)2016-12-26 10:15:36
——纳西琵琶
民族音乐(2016年2期)2016-07-05 11:36:32
民族音乐(2016年3期)2016-06-05 11:33:39
中国西部(2016年1期)2016-03-16 07:56:10
西南学林(2013年1期)2013-11-22 07:19:30
