
C4.5算法在高校计算机等级考试成绩分析中的研究
2016-04-08 00:59:49程代娣安徽警官职业学院安徽合肥230031
淮北师范大学学报(自然科学版) 2016年1期
程代娣(安徽警官职业学院,安徽合肥230031)
C4.5算法在高校计算机等级考试成绩分析中的研究
程代娣
(安徽警官职业学院,安徽合肥230031)
摘要:针对目前高校计算机等级考试持续过低的现状,应用决策树C4.5算法对安徽警官职业学院计算机等级考试成绩数据进行深入分析和研究,对预处理后的数据进行挖掘并建立决策树分类模型,由决策树产生分类规则,找出影响计算机等级成绩潜在的主导因素,从而为进一步提高高校计算机等级考试通过率提供参考依据.
关键词:数据挖掘;决策树;C4.5算法;计算机等级考试;成绩分析
全国计算机等级考试在我院举办多年,教务成绩管理系统中积累了大量的计算机二级考试Access成绩.然而,一直以来这些成绩主要为师生提供查询、统计和排序等功能,无法挖掘出隐含在其背后对教学决策有价值的信息.基于二级通过率普遍过低的现象,迫切需要采用新的数据分析技术对海量的成绩数据进行分析,从中提取隐含的和有价值的资源.文中将决策树C4.5算法引入到计算机等级考试成绩分析中,从顶层进行具体分析,找出影响计算机等级考试成绩潜在的关键因素,为教师指明教学方向和教学重点,从而进一步提高计算机等级考试的通过率.
1 决策树C4.5算法
数据挖掘就是从海量的数据中找出隐含的有价值信息[1].数据挖掘技术是一种新数据分析方法,它既能实现对历史数据进行有效管理和查找,又能实现不同但关联数据之间的隐含关系,并能对海量数据进行深层次的分析和挖掘,利用获取的有价值信息预测将来发展方向,现实更快速和更理性化地做出正确的决策.决策树是数据挖掘主要的算法,应用十分广泛.本文采用C4.5决策树算法,将最终分类结果用图形化树形结构表示出来,并构建IF-THEN模式的分类规则.
1.1C4.5算法原则
采取信息熵原理构建决策树是C4.5算法的关键原则,即通过计算各个属性信息增益率确定分类属性,分类测试属性由全部非类别属性的最大信息增益率来决定[2],自上而下递归地生成决策树子结点分支来构建决策树[3].决策树初型构建、决策树修剪优化和生成IF-THEN分类规则是C4.5算法的主要构建流程.
1.2C4.5算法基本理论方法
信息增益是指期望信息或者信息熵的有效减少量,用来衡量一个属性区分数据样本的能力[4].在树的每个结点上确定当前结点的测试属性的方法是计算具有最大信息增益的属性.
定义1设s个样本集是S,设定类标号属性具有n个不同值,定义n个不同类Ci(i可为1,2,…,n),设定Si是类Ci中样本个数,那么,对于已知给定的样本分类所需的信息熵为[4]:

其中,任意样本Ci的概率是Pi=Si/S.
定义2假定属性B赋予K个不同值{b1,b2,…,bk}.样本集S被属性B分割成k个小子集{S1,S2,…, Sk};其中,S中有这样一些样本被Sj包含:样本在B上具有值bj.假定确定B作为分类测试属性,那么,由包含集合S的结点构建出来的分枝对应于这些子集.设子集Sj中类Ci的样本个数为Sij[4].按照由B划分成子集的熵由以下公式给出:

对于一个给定S样本集的Sj子集,

其中,sj中的样本属于类Ci的概率为
样本集S属性B的信息增益由以下公式得出:

信息增益比例的计算公式为:

其中分裂信息Spliti(B)定义为:
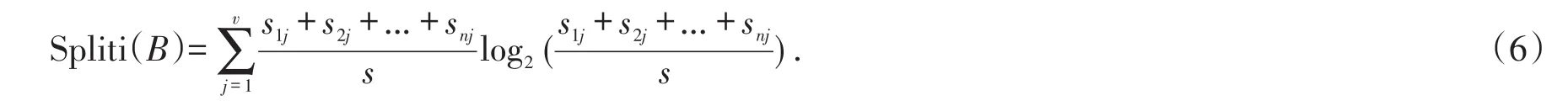
2 C4.5算法在计算机二级考试Access成绩中应用
用C4.5算法分析计算机二级考试Access课程的成绩,找出影响计算机等级成绩潜在的主导因素.
2.1数据收集
本文数据来源于安徽警官职业学院近3年来学生信息,数据由两部分组成,一部分来自教务平台的二级Access成绩表,主要包括学号、姓名、性别、身份证号码、专业和等级考试成绩;另一部分来自学生调查表,包括学号、感兴趣程度、是否按时完成作业、教学效果评价、每周上机时数和是否通过,共采集了550条记录.Access成绩表和学生调查表合成最终的分析数据集,将550条记录数据集分成两个部分:一是训练数据集410条记录,二是测试数据集140条记录.
2.2数据预处理
在现实世界大数据库中,初始数据并不总是完整的,数据预处理可以保证数据挖掘所需数据集的质量.它主要包括数据集成、属性归约、数据清理三个环节.
2.2.1数据集成
将多个不同数据源中的异构数据利用数据约束和完整性方法融合存储到一个完整统一的数据库里.将上述收集来的二级Access成绩表和学生调查表数据通过学号合并成一个表用于数据分析.
2.2.2数据归约
收集的大量分析数据存在很多属性,并不是每个属性都与数据挖掘任务息息相关.数据归约的目的为了获取比原始数据小的属性集,新的数据集不影响数据挖掘结果.主要采取两种方法.一是属性的删除.应选取具有代表性的特征信息,通过二级Access成绩表中可以看出,“学号”“身份证号码”“姓名”和“专业”等属性是多余的,因此必须删除.二是属性的泛化.属性泛化是指把与数据挖掘任务相关的属性从具体的概念值抽象到较高概念层的过程.根据属性泛化原理,泛化合成表中的“等级成绩”,该属性采用百分制,具有不同的取值,可将其泛化为:通过(>=60)和不通过(<60).通过对计算机等级考试成绩的调查和研究,数据进行如下处理:将“是否感兴趣”分为“是”和“否”两类;将“按时完成作业”分为“是”和“否”两类;将“每周上机时数”分为“<4”和“>4”两类;将“教学评价”属性分为“优秀”和“一般”两类;“成绩”分为“通过”和“不通过”两类.
2.3数据清理
在有些情况下,C4.5算法可供使用的数据某些属性的值为空或无法给出,本项目在C4.5算法的基础上提出了两种处理缺少属性值的改进措施.方法一是赋予结点n所对应的训练集中该属性的最常见值;方法二采用忽略元组法,直接丢弃含空缺值的元组.在本案例中采用元组直接忽略方法.经过数据清理,共有400条有效数据记录,10条噪音数据记录.最终形成的样本分布数据如表1[5].

表1 样本分布数据
2.4决策树构建与剪枝
以表1中的训练样本集为例,采用C4.5算法构建决策树:
第1步:计算已知样本分类属性的信息熵.
表1中,样本大小400个,125个为类“通过”的样本大小,275个为类“不通过”的样本大小[5].首先用公式1计算I(S1,S2);

第2步:计算每个属性值所划分的子集信息熵.
(1)属性“是否感兴趣”的子集信息熵的计算.
“是否感兴趣”=“是”,95个数据样本是类“通过”,类“不通过”有10个数据样本,用公式3计算出:

“是否感兴趣”=“否”,有30个样本类“通过”,有265样本是类“不通过”,由公式3计算出:

同理,计算“按时完成作业”属性的子集信息熵.
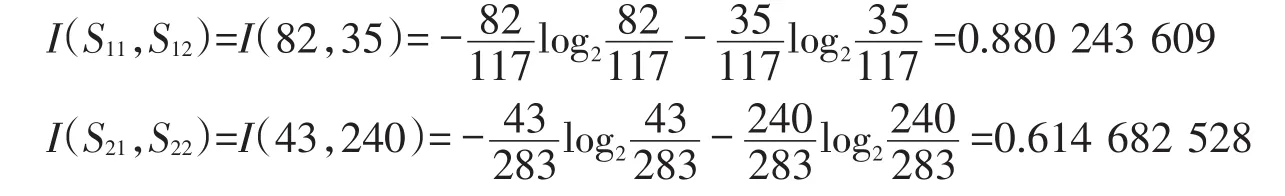
计算“教学评价”属性的子集信息熵.

计算“每周上机学时”属性的子集信息熵.
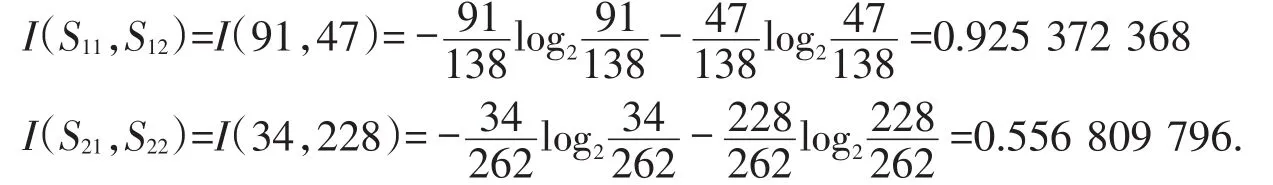
第3步:计算所有属性信息期望.
根据公式2,4个属性期望信息计算如下:

第4步:计算所有属性信息增益.
根据公式4,4个属性信息增益计算如下:

第5步:每个属性的分裂信息计算.
根据公式6,4个属性的分裂信息计算如下:

第6步:每个属性的信息增益率计算.
根据公式5,4个属性信息熵计算如下:
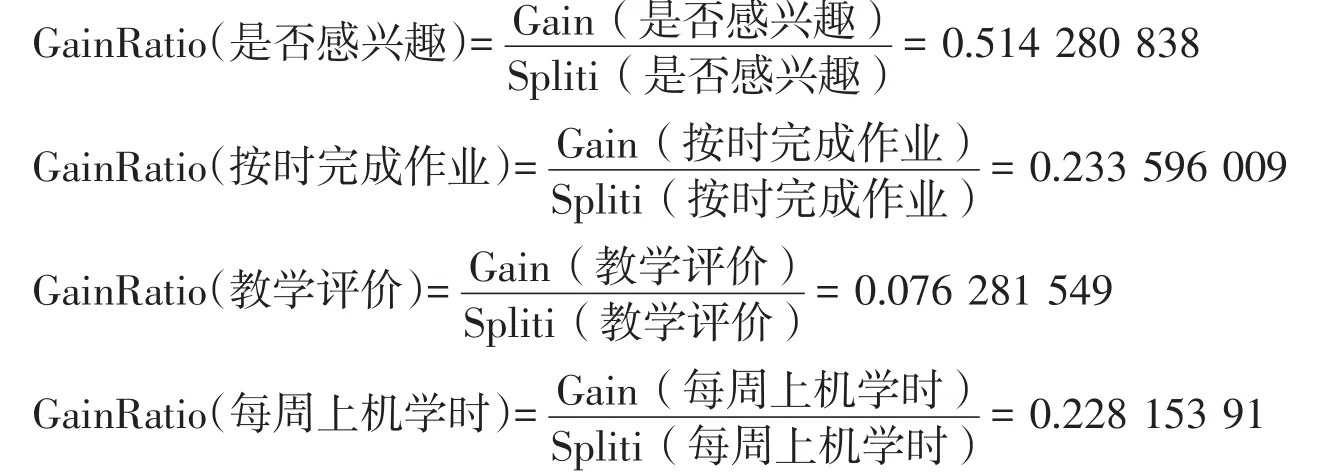
第7步:确定决策树的根结点.
由上面的计算结果和C4.5算法原理可知,分类测试属性确定为“是否感兴趣”.同时建立该决策树根结点,属性标记“是否感兴趣”,对于每个测试属性所取的值,分别引出一个相应分支,其他样本属性也按照这种方法来划分和构建[5].
第8步:按照上面的方法进一步划分分枝结点,为了防止训练数据过度和减低训练时间,对于过小比例的数据可忽略,在这里我们采用事后修剪法对决策树进行修剪,最后形成的一棵成绩决策树,如图1所示.

图1 计算机二级成绩决策树
2.5提取分类规则
可用IF-THEN分类规则从根结点、分支到叶子结点进行表述,生成可理解的分类规则如下:
IF是否感兴趣=“是”AND按时完成作业=“是”AND每周上机学时>4THEN成绩=“通过”
IF是否感兴趣=“是”AND按时完成作业=“是”AND每周上机学时<4THEN成绩=“不通过”
IF感兴趣=“是”AND按时完成作业=“否”AND每周上机学时>4 AND教学评价=“优秀”THEN成绩=“通过”
IF是否感兴趣=“是”AND按时完成作业=“否”AND每周上机学时>4 AND教学评价=“一般”THEN成绩=“不通过”
IF是否感兴趣=“是”AND按时完成作业=“否”AND每周上机学时<4”THEN成绩=“不通过”
IF是否感兴趣=“否”AND按时完成作业=“是”AND教学评价=“优秀”AND每周上机学时>4 THEN成绩=“通过”
IF是否感兴趣=“否”AND按时完成作业=“是”AND教学评价=“优秀”AND每周上机学时<4 THEN成绩=“不通过”
IF是否感兴趣=“否”AND按时完成作业=“是”AND教学评价=“一般”THEN成绩=“不通过”
IF是否感兴趣=“否”AND按时完成作业=“否”THEN成绩=“不通过”.
2.6结论分析
通过对计算机等级考试成绩决策树的分析,得出以下结论:是否感兴趣、按时完成作业、每周上机学时、教学评价分别在不同程度上影响计算机等级考试成绩,其中学习兴趣影响最大.要提高计算机等级考试的通过率,首先要激发学生的学习兴趣,其次要按时完成作业,第三要加强上机实践练习时数,最后要教师提高教学水平和方法.
3 结束语
文中分析了数据挖掘技术C4.5算法,并应用C4.5算法对计算机二级考试成绩进行了深层次分析,构建决策树,挖掘出影响计算机等级成绩潜在的主导因素,及时反馈到教师教学和学生学习中,为高校计算机等级考试改革提供有利的数据支持,从而进一步提高计算机等级考试的通过率.
参考文献:
[1]苗苗苗.数据挖掘中海量数据处理算法的研究与实现[D].西安:西安建筑科技大学,2012.
[2]吕瑞雪.基于决策树的中学生成绩挖掘与分析[D].呼和浩特:内蒙古大学,2010.
[3]罗后平.数据挖掘在市场营销中的应用[J].商业研究,2003(23):139-140.
[4]纪希禹.数据挖掘技术应用实例[M]北京:机械工业出版社,2009:34-36.
[5]程代娣.决策树在高职院校毕业生就业工作中应用研究[D].合肥:安徽大学,2010.
Research on the Application of Algorithm C4.5 in the Analysis of College Students′Score of Computer Rank Examination
CHENG Daidi
(Anhui Vocational College of Police Officers,230031,Hefei,Anhui,China)
Abstract:This paper,adopting decision tree algorithm,focuses on analyzing and researching students′com⁃puter rank examination scores from Anhui Vocational College of Police Officers.It aims at finding out the dominant factors that affect the results of computer rank examination and offering effective and supportive da⁃ta for educational department and teachers with the purpose of improving teaching quality of the college,by applying algorithm C4.5 to mine the data preprocessed and to build classification model of decision tree to develop classification rules.
Key words:data mining;decision tree;algorithm C4.5;computer rank examination;the analysis of students′score
作者简介:程代娣(1978-),女,安徽宣城人,硕士,讲师,研究方向:数据库技术与网站开发.
基金项目:2015年度安徽省高等学校自然科学研究项目(12219zrkx2015B04)
收稿日期:2015-11-02
中图分类号:TP 318
文献标识码:A
文章编号:2095-0691(2016)01-0012-05
猜你喜欢
东坡赤壁诗词(2022年4期)2022-10-30 12:18:17
中华养生保健(2020年10期)2021-01-18 06:45:28
含能材料(2021年1期)2021-01-10 08:34:34
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
工业设计(2016年8期)2016-04-16 02:43:24
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
家教世界·创新阅读(2014年2期)2014-02-19 18:26:46
