
基于基尼系数的n-grams特征约简加权算法
2016-04-06 01:34张金美舒希勇
淮阴工学院学报 2016年1期
关键词:支持向量机
张金美,舒希勇
(1.淮安信息职业技术学院 江苏省电子产品装备制造工程技术研究开发中心,江苏 淮安 223003;
2.淮安信息职业技术学院 机电工程系,江苏 淮安 223003)
基于基尼系数的n-grams特征约简加权算法
张金美1,舒希勇2
(1.淮安信息职业技术学院 江苏省电子产品装备制造工程技术研究开发中心,江苏 淮安 223003;
2.淮安信息职业技术学院 机电工程系,江苏 淮安 223003)
摘要:目前,关于n-grams特征加权的计算方法大多是基于其出现频率进行设计的。这类加权计算方式存在一定的问题:n-grams特征是由多个词汇构造而成,由于其出现频率取决于多个词汇,即多个词汇的出现概率取交集,故经常造成出现频率过小而无法得到满意的加权效果。另外,构成n-grams特征的词汇中可能存在一部分与分类无关,传统方法无法对n-grams特征做进一步处理。为了对n-grams特征更好地加权并做进一步处理,利用基尼系数和洛伦茨曲线对n-grams特征内的词汇进行约简和加权,最终得到对n-grams特征的加权结果。通过支持向量机中的实验结果表明,经过基尼系数约简和加权后的n-grams特征在分类结果上要优于TF(Term Frequency)等加权方法,验证了算法的有效性。
关键词:n-grams特征;基尼指数;洛伦茨曲线;支持向量机
0引言
n-grams特征作为文本特征的一类,由于其具有无需分词、携带语义等优秀特性,近几年越来越多地用于文本分类[1-2]、自然语言处理[3]和情感分析[4-5]等领域,不仅如此,n-grams特征的特性甚至可以迁移到图像处理中。尽管n-grams特征具有诸多其他特征所不具备的优秀特性,但其自身也存在许多难以克服的缺陷限制其广泛应用。为了克服n-grams特征的不足,国内外学者提出了多种提高n-grams特征质量的方法。尚文倩等[6]提出基于类子空间的文本特征选择算法,利用主成分分析(PCA,Principe Component Analysis)和类子空间对特征进行提取,达到减少特征维度的目的。吕震宇[7]利用改进的互信息方法对特征进行维度约简。余小军[8]采用了一种同义词合并的方法来进行特征加权及选择。也有学者将遗传算法与特征选择进行结合,但由于遗传算法自身容易过早收敛,结果并不理想。还有一种基于OWA算子的文本特征选择算法,OWA即有序加权平均(OWA,Ordered-Weighted Average),该算法结合了信息增益、卡方、文本频率和互信息等多种方法对特征进行加权,效果较好,但由于结合了多种加权方法,选择效率较低。上述提到的方法均没有完全解决本文提到的n-grams特征缺陷,有些仅能适用于一些特定情况下的特殊文本。通过对基尼指数和洛伦茨曲线的研究,本文给出基于基尼指数的n-grams特征约简和加权算法,并在搜狗中文文本语料库中进行了实验验证。
1洛伦茨曲线和基尼系数
为了研究社会财富分配不平等问题,1905 年,美国统计学家洛伦茨提出了著名的洛伦茨曲(Lurenzcurve)。对于图1 中洛伦茨曲线上任一点(x%, y%),它的含义是从贫到富排列,前x%的人口累计总收入占社会总收入的比例是y%。绝对平均线表示社会总收入在全体居民中绝对平均分配时的收入分配曲线y=x;绝对不公平线是社会所有收入被唯一占据时的收入分配曲线,是一条垂直于x 轴的直线。洛伦茨曲线一般位于绝对平均线与绝对不公平线之间。 图1中a的面积越小,收入分配越平等。

图1 洛伦茨曲线
1912 年,意大利经济学家基尼根据洛伦茨曲线提出基尼系数。图1中,设洛伦茨曲线和绝对平均线之间的面积为a,洛伦茨曲线与绝对不公平线和x 轴围成的图形面积为b,基尼系数计算公式如下:
(1)
洛伦茨曲线与绝对平均线之间的面积a 越小,收入分配越趋于平等,洛伦茨曲线的弧度越小,基尼系数也越小。 n-grams特征内的词汇是否具有类别区分度,主要取决于它在各个类别的分布情况。高质量的词汇在每个类中的分布是不均衡的,这样才能体现其在分类中的作用,而在每个类中平均分布的特征则无法对类别进行区分,即属于分类无关词汇,这样的词汇混入n-grams特征中会影响其训练出来的分类器的效果。
2基于基尼系数的n-grams特征约简及加权
2.1n-grams特征约简
由于n-grams特征是由文本中多个连续词汇构成的,为了保证n-grams中的词汇均与分类高度相关,利用基尼系数来衡量词汇在类别中的分布情况,以此来判断其是否应该被约简。用于计算词汇分布的公式如下:
(2)
其中,Wi为每个类别中所包含的文本数量,Yi为每个类别的文本包含该特征词汇的数量占全部类别中该特征出现数量的比例,Vi为Yi从i=1到i的累计数,例如Vi=Y1+Y2+……+Yi。通过式(1)的计算即可得到n-grams特征内词汇对分类贡献的加权值。若weight越大,则分布越不均匀,对分类的贡献越大;若weight越小,则分布越均匀,对分类的贡献越小,应予以约简。
在约简时不能直接将n-grams中weight值较小的词汇直接删除,因为n-grams特征是由多个词汇连续组成的整体,所以在约简时只能从其两边约简,而不能约简中间的词汇,造成n-grams特征语义和语序的不连续。
为避免上述情况的发生,设计n-grams特征约简方法如下:
第一步,计算n-grams中每个词汇word1、word2……wordn的weight值得到weight1、weight2……weightn;第二步,按照从两边到中间的顺序,对weight值小于阈值δ的词汇,按照从两边到中间方式对其进行删减。若两边词汇的weight值不小于δ,则此n-grams特征无法约简,若两边词汇的weight值小于δ,则对小于δ的词汇进行约简;第三步,对约简后的(n-k)-grams(2>k>1)特征继续从两边的word1和wordn约简,直到该特征两边的词汇不再有词汇大于δ。
2.2n-grams特征加权
在对n-grams特征进行加权时,通过对n-grams中每个词汇的weight值求和,得到该n-grams的加权值,如式(2)所示。

(3)
其中k为经过约简后的n-grams特征所剩的词汇数量,n-grams最终的加权值即为word1到wordk的weight计算之和。
3实验结果及分析
本文以搜狗中文新闻语料库作为实验语料,SVM(Support Vector Machine,支持向量机)作为分类器,对TF(Term Frequency,特征频率)、逆文本类别指数、互信息和本文方法在n-grams中的加权效果进行对比,SVM中衡量特征加权效果的因素包括准确率、召回率和F值。图2~4是对2-grams特征的加权方法为TF、TF-IDF、互信息和基于基尼系数时的准确率、召回率和F值。

图2 2-grams中4种加权方法的准确率
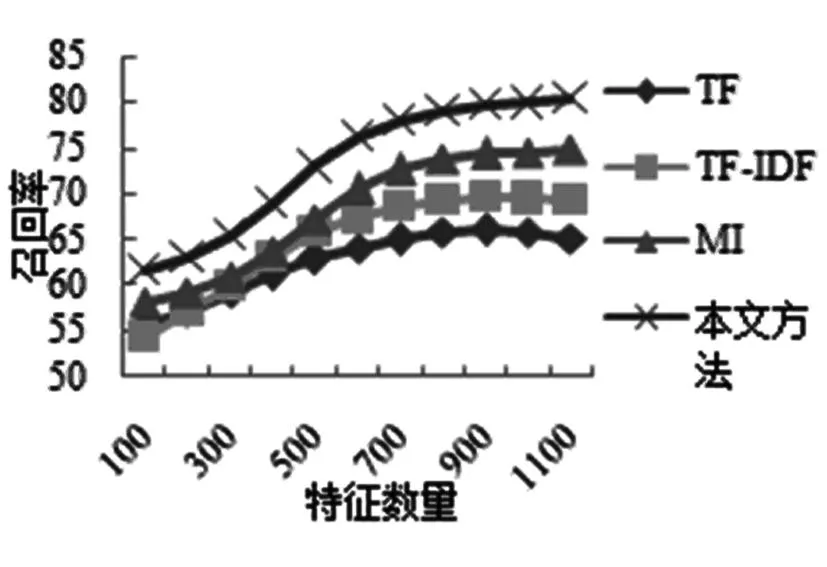
图3 2-grams中4种加权方法的召回率

图4 2-grams中4种加权方法的F值
由于本文提出的基于基尼系数的特征约简加权算法对2-grams特征进行了约简操作,分类效果好于互信息加权。
图5~7是对3-grams特征的加权方法为TF、TF-IDF、互信息和基于基尼系数时的准确率、召回率和F值。本文提出的基于基尼系数的特征约简加权则明显好于互信息加权。

图5 3-grams中4种加权方法的准确率
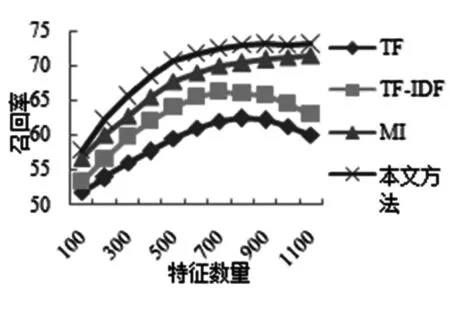
图6 3-grams中4种加权方法的召回率

图7 3-grams中4种加权方法的F值
图8~10是对4-grams特征的加权方法为TF、TF-IDF、互信息和基于基尼系数时的准确率、召回率和F值。经过本文方法加权后的4-grams特征在特征数量超过600后仍然稳中有升,取得了较好的效果。

图8 4-grams中4种加权方法的准确率

图9 4-grams中4种加权方法的召回率
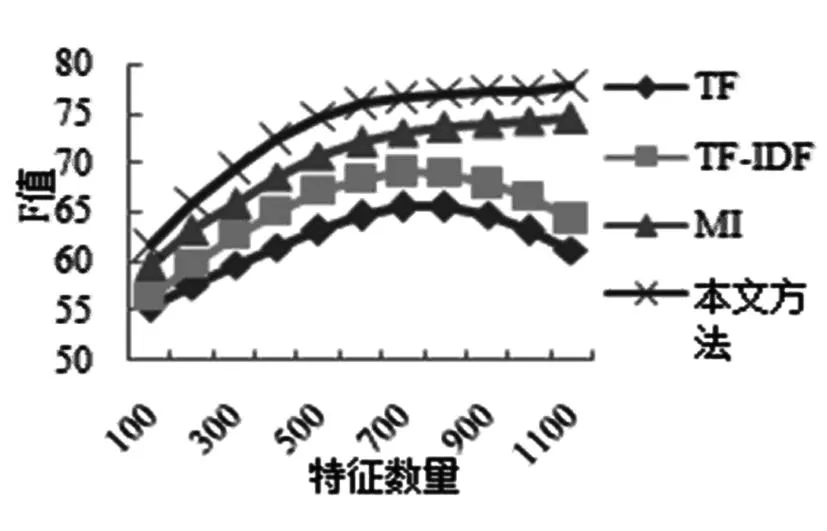
图10 4-grams中4种加权方法的F值
4结论
本文针对n-grams特征在进行文本分类时存在的内部冗余和加权困难的问题,提出了利用经济学中的基尼系数对n-grams特征中的词汇进行分类相关性衡量,最终得到n-grams特征的加权结果,避免了使用TF加权时由于出现频率小而造成的加权不足问题。实验结果表明,本文提出的基于多指标融合的n-grams特征约简及加权方法对n-grams特征的处理结果和加权效果均明显优于常用的TF加权方法。
参考文献:
[1] ZAKI T,ES-SAADY Y,MAMMASS D,et al. A hybrid method n-grams-TFIDF with radial basis for indexing and classification of Arabic document[J].International Journal of Software Engineering and Its Applications,2014,8(2):127-144.
[2] VELASQUEZ F,STAMATATOS E, GELBUKH A,et al.Syntactic dependency-based n-grams as classification features[J].Lecture Note in Computer Science,2013,7630:1-11.
[3] SIDOROV G,VELASQUEZ F,STAMATAOS E,et al.Syntactic n-grams as machine learning features for natural language processing[J].Expert Systems with Applications,2014,41(3):853-860.
[4] 周法国.基于发现特征子空间模型的文本分类算法[J].计算机应用研究,2009,26(10):3712-3734.
[5] 高鸿业.西方经济学(微观部分)[M]. 北京:中国人民大学出版社,2001.
[6] 尚文倩, 黄厚宽, 刘玉玲,等.文本分类中基于基尼指数的特征选择算法研究[J].计算机研究与发展,2006,43(10):1688- 1694.
[7] 吕震宇.基于类信息的文本特征选择与加权算法研究[J].计算机工程与应用,2008,20:145-147.
[8] 余小军.基于N-Gram文本特征提取的改进算法[J].现代计算机:专业版,2012,418(34):3-7.
(责任编辑:尹晓琦)
N-grams Features Reduction and Weighting Based on Gini Coefficient
ZHANG Jin-mei1,SHU Xi-yong2
(1.The Engineering Technology Research and Development Center of Electronic Products EquipmentManufacturing of Jiangsu Province,Huaian College of Information Technology,Huai'an Jiangsu 223003,China;2.Department of Mechanical and Electrical Engineering,Huaian College of Information Technology,Huai'an Jiangsu 223003,China)
Abstract:At present, the calculation method of n-grams feature weighting is based on the frequency or occurrence frequency. However, there are some problems in this kind of weighting method. Firstly, the n-grams features are constructed by multiple words. Because of the occurrence frequency of a number of words, it often could not yield a satisfied result caused by a small number of frequency. Secondly, there may be a part of vocabulary of n-grams characteristics, which is not related to the classification, and the traditional method could not do the further processing of n-grams features. In order to make the n-grams feature better and do further processing, the Gini coefficient and the Lorenz curve were used to reduce the vocabulary within the n-grams feature, and finally the weighted results of n-grams features were obtained. In the support vector machine, the experimental results showed that the proposed method was better than the Term (Frequency TF) and the feature in the classification results of the n-grams feature.
Key words:n-grams feature; Gini coefficient; Lorenz curve; SVM
中图分类号:TP391
文献标识码:A
文章编号:1009-7961(2016)01-0025-04
作者简介:张金美(1980-),女,辽宁阜新人,讲师,硕士,主要从事无线通信及控制工程技术研究。
收稿日期:2015-11-03
猜你喜欢
现代电子技术(2016年23期)2017-01-12
现代电子技术(2016年23期)2017-01-12
无线互联科技(2016年13期)2017-01-10
中国水运(2016年11期)2017-01-04
软件导刊(2016年11期)2016-12-22
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
价值工程(2016年29期)2016-11-14
科学与财富(2016年28期)2016-10-14
考试周刊(2016年53期)2016-07-15
