
文献知识网络的节点度变化对领域热点的影响
2016-03-25 10:58:10,,,,
中华医学图书情报杂志 2016年11期
,,, ,
文献是科研工作者获取科学假设与跟踪领域进展的重要途径,从大量文献集中识别出前沿热点对科学研究具有重要的理论和实践意义。科技情报工作的基础就是要抓住前沿热点,掌握前沿发展的动态,密切跟踪研究进展,但前沿热点的定义并没有科研人员一致公认的标准[1]。领域热点存在两个最主要的特征:一是相关领域近年的文献集呈现出的热点主题,二是围绕热点主题使未来短期内能形成大量新的研究内容。目前各个学科领域的科研人员提出了很多热点主题的识别方法,以便领域专家总结未来短期内的研究方向,但研究内容的预测及对预测结果的评价仍是一个开放的问题。
要从已有文献中获得新的研究内容,首先需要从文献集中发现隐含的联系以形成科学假设。越来越多的文献挖掘研究尝试从文献集构建关联知识网络,以便进一步深入地挖掘新的关联知识[2],而网络的拓扑特征会在一定程度上影响网络的演化发展[3]。因此,本文主要基于文献的知识发现模型,从关联知识网络的特征变化预测领域热点,并通过1种评价预测结果的方法验证其可预测性。
1 研究设计
基于文献的知识发现(Literature-based Discovery, LBD)通过潜在的关联挖掘推断出新的科学假设。如果有两类文献集As和Cs,其中As讨论了概念A和概念B之间的关系,而Cs讨论了概念C和概念B之间的关系,但是没有任何文献讨论概念A和概念C的关系,那么A与C之间通过B存在某种关系,这就可能是一个新的科学发现[4-5]。根据文献知识发现理论模型,如果基于近期文献集,从概念A能够推断出较多的新假设,那么概念A很可能是近期文献集呈现出的某个热点主题,能衍生出大量新的研究内容。
1.1 关联建模
利用图对关联知识建模,是目前相关领域最常用的方法。通常一个简单的无向无权网络,可记为G=(V ,E),其中集合 V 称为节点集,V={V1,V2,…,Vn},集合E称为边集,E={e1,e2,…,em},任意一条边对应一个节点的二元组:ex=(Vi,Vj),E是V×V的一个子集。本文将文献集中的内容相关性转化为基于关联信息存在的图结构数据模型,即根据文献中的概念实体及其关联信息,对文献中所蕴含的知识进行网络结构化,构建文献关联知识网络。在关联知识网络G=(V, E) 中,节点集V 是各种从生物医学文献中提取而来的实体的集合,如基因、蛋白质、化合物或疾病等,边集E 是实体之间的关联集合。关联知识网络把文献集中的知识以网络形式表示出来,这既表示出知识之间的联系,也过滤了冗余知识,为发现对象间的隐含关系提供了方便。本文基于句子共现提取实体关联[6],用以进行测试分析,基本过程如下。
识别出句子的实体NP(Noun Phrase)及其位置。如果在同一个句子中得到的实体按其在句子中的顺序依次为NP1、NP2、NP3,则得到关联(NP1,NP2),(NP1,NP3),(NP2,NP3)。如文献标题(PMID: 20856896):β1-syntrophin modulation by miR-222 in mdx mice. 提取得到实体及其位置的列表为:[(β1-syntrophin modulation, 1),(miR-222, 4),(mdx mouse, 6)]
进一步得到关联:(β1-syntrophin modulation, miR-222 ),(β1-syntrophin modulation , mdx mouse),( miR-222, mdx mouse)
将两个实体首次共现的时间(年份),作为关系的T属性。
1.2 热点建模
给定关联知识网络G=(V,E),对于任意节点v∈V,定义其节点度的增长率为:
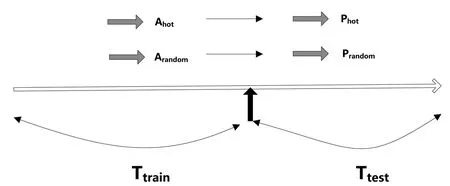
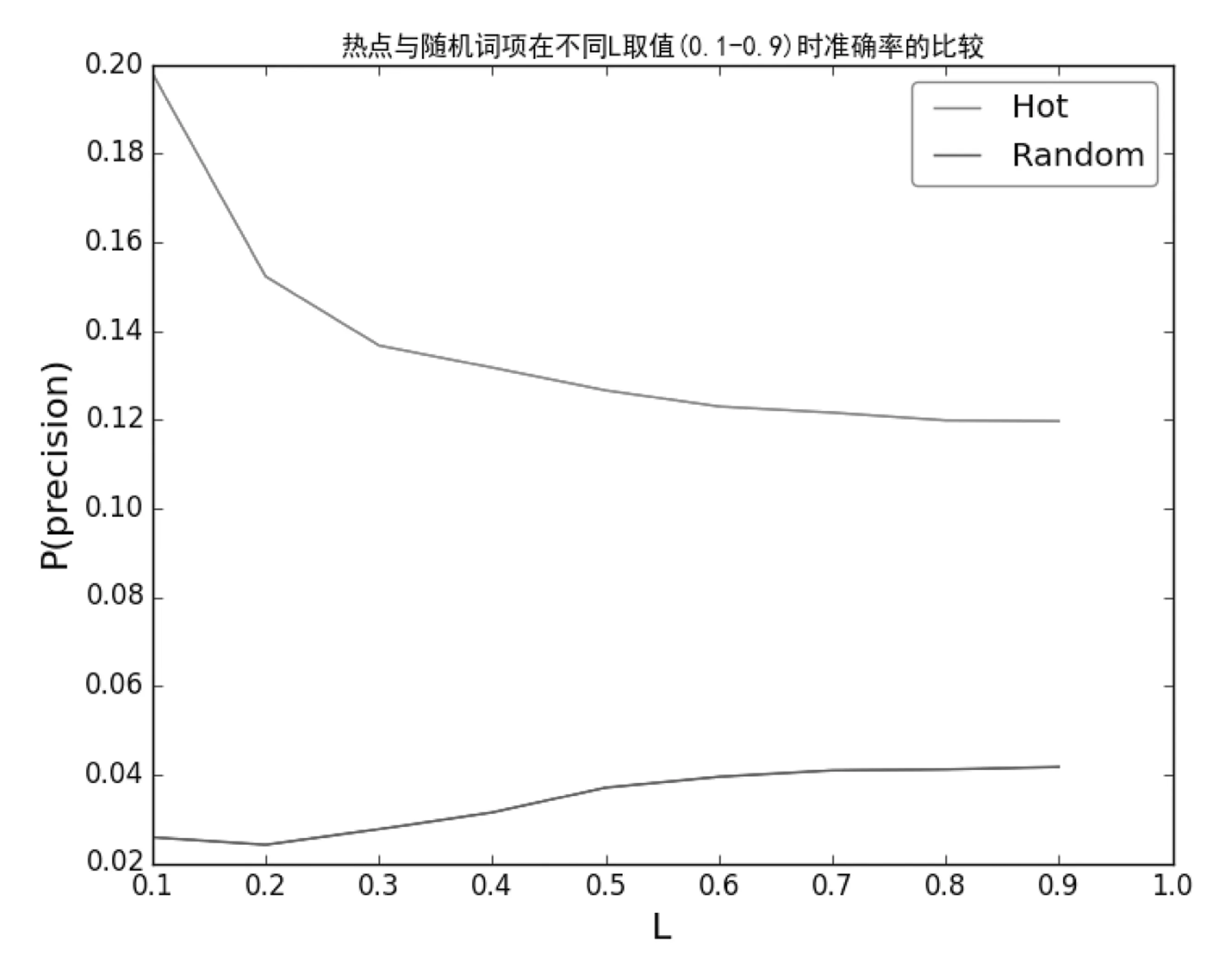
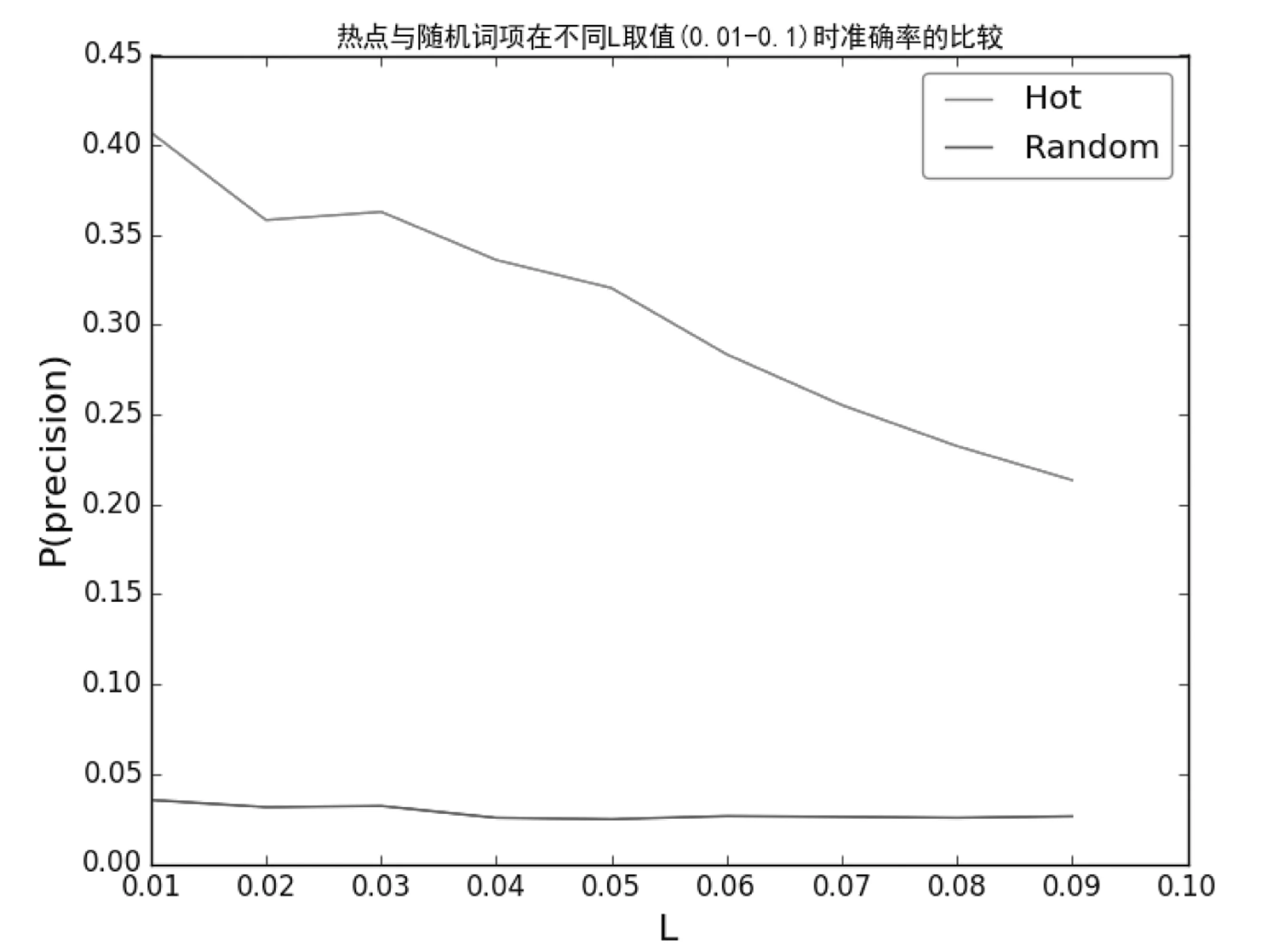
其中dT为T时节点的度,即T时节点的所有关联数量,且T1 综合来看,笔者更倾向于第一种浪形的划分。因为从时间和大周期结构的角度来看,时间不支持走一轮完整的12345浪了。 文献知识发现的实施主要包括3个重要部分,分别是概念实体A、B和C的识别、关联的抽取以及间接关联的相关度计算,用户输入概念A,计算A-B-C之间的关联强度获得按关联强度由大到小的有序列表[7]。对于一个文献知识发现系统来说,返回的候选结果的数量比较大时,排在前面的结果通常是用户最关心的。因此,给定每一个A-B-C间接关联,计算其(A-B-C)的一个分值SAC,利用SAC对所有候选结果集从大到小排序之后,在有序的结果列表中,确保排序靠前的多是全局关联强度较好的结果,即只关注于分值最高的前L条关系链(A-B-C)的准确度P(Precision),P越大效果越好。 1.3.1 准确率P的计算 给定测试文献数据集,将文献数据集按时间分成训练集Ttrain和测试集Ttest,分别建立训练网络G1=(N1,E1)和测试网络G2=(N2,E2)。从N1中随机选择m个词作为种子词项集A,其中A取训练网络与测试网络中共同拥有的词项,即A∈N1∩N2。 在训练网络G1中,以种子集A中的节点为起点提取其间接节点,得到间接节点集C,计算所有关系链(A-Btrain-C)的一个分值SAC,对结果集C按SAC值从大到小排序,取有序结果集CSorted中前L个词项,得到CSorted_TopL={c1,c2,…cL}。 在测试网络G2中,以种子节点集A中的节点为起点提取其直接关联节点,得到关联节点集Btest。 计算有序结果集CSorted前L个词项集CSorted_TopL的准确率P: 其中CSorted_TopL∩Btest指CSorted_TopL和Btest的交集,即共同拥有的词项,|CSorted_TopL∩Btest|为交集的节点数量,|Btest|指Btest集的节点数量。 为了验证热点的可预测性,在Ttrain时期的训练集筛选近3年关联增长率最大的前N个词项作为热点词项集Ahot,同时随机选取N个词项作为随机词项集Arandom,分别作为种子词项集,基于Ttest时期的测试集,计算与比较两种情况下的准确率Phot与Prandom。如果Phot显著大于Prandom,说明Ahot词项一定程度上表达了短期内的热点主题,如图1所示。 图1 利用热点词项与随机词项预测新关联的 1.3.3 A-B-C间接关联SAC的计算 目前已有多种指标用于评价A-B-C三者之间的关联性[8]。本文选择常用的绝对词频(Absolute Word Frequency,AWF)来计算A-B-C之间的潜在关联性SAC,以辅助计算与比较准确率Phot与Prandom,具体如下。 SAC=min(w(A,B),w(B,C)) 其中,w(A,B)与w(B,C)分别为A与B、B与C的共现次数。 以关键词“miRNA or MicroRNA”从PubMed中检索得到51 118条结果,取标题数据,将数据集按时间分成训练集和测试集,分别建立训练网络G1=(N1,E1)和测试网络G2=(N2,E2)。以2012年为分开点,2013-2015年的文献数据作为Ttest测试集,2010-2012年作为训练集Ttrain。从训练集中随机选取50个关键词作为种子词项Arandom,同时给定T2=2012,T1=2010,从训练集中选取50个近3年增长率最大的节点作为热点节点Ahot。 取 L=0.1,0.2,0.3,…,1,即取有序结果集Csorted前10%、20%、10%、20%、30%、40%、50%、60%、70%、80%、90%、100%的词项时,计算热点词项与随机词项的准确率P的结果如图2所示。 图2 L=0.1,0.2,… ,1.0时热点词项与随机 进一步取靠前的区间,取 L=0.01,0.02,0.03,…,0.1,即取有序结果集Csorted前1%、2%、3%、4%、5%、6%、7%、8%、9%、10%的词项时,计算准确率P的结果如图3所示。 图3 L=0.01,0.02,…,0.1时热点词项与随机词项的准确率P的比较 综合图2、图3的测试结果可以发现,基于文献知识发现模型,对结果集进行关联置优排序,利用热点词项计算得到的准确率Phot显著高于由随机词项获得的准确率Prandom。这一方面说通过筛选节点度增长率大的词项,可以获得更多的新关联,即度增长率大的节点在短期内能衍生出较多的新研究内容;另一方面说明,能够在未来短期内形成的大量新关联都与节点度快速增长的词项密切相关。因此,节点度快速增长的词项在一定程度上能够表达相关领域近期的热点主题,即文献知识网络的节点度变化对领域热点具有一定的预测作用。 面对大数据时代知识获取的需求与挑战,基于文献的知识发现研究对完成从文献到知识的转化具有重要作用,已成为医学情报分析与辅助科研的一种重要理论与方法。基于文献的知识发现是一个启发式的过程,如何保证在已有的文献集中,筛选出更多更有效的潜在关联,仍是该领域研究的热点问题之一。 本文基于文献知识发现模型,探讨了文献知识网络中节点度变化对近期热点的预测性,测试实验显示度增长率大的节点在未来形成新关联的准确率显著大于一般节点,表明节点度变化对领域热点具有一定预测性。在实际科研过程中,不同时期、不同领域都存在相应的热点内容,准确地识别领域前沿热点是进行情报跟踪的基础。如果在文献知识发现具体实施过程中的种子概念实体取自于热点主题,可以显著提升知识发现准确率和筛选效率,辅助科研人员获得更多的科学假设。1.3 评价方法
2 数据实验
2.1 数据准备
2.2 结果与讨论
3 总结
猜你喜欢
加油站服务指南(2022年6期)2022-07-28 06:07:02
当代陕西(2019年15期)2019-09-02 01:52:00
车迷(2019年10期)2019-06-24 05:43:28
哲学评论(2018年1期)2018-09-14 02:34:18
快乐语文(2018年7期)2018-05-25 02:32:00
学苑创造·A版(2018年11期)2018-02-01 06:29:20
读者(2017年5期)2017-02-15 18:04:18
中国记者(2014年6期)2014-03-01 01:39:53
上海理工大学学报(社会科学版)(2011年4期)2011-09-26 11:01:32
大家(2011年9期)2011-08-15 00:45:37
