
基于数据场和单次划分的聚类算法
2016-03-24 03:27:24陈天天何熊熊
浙江工业大学学报 2016年1期
关键词:聚类分析
张 霓,陈天天,何熊熊
(浙江工业大学 信息工程学院,浙江 杭州 310023)
基于数据场和单次划分的聚类算法
张霓,陈天天,何熊熊
(浙江工业大学 信息工程学院,浙江 杭州 310023)
摘要:针对现有大部分聚类算法普遍存在聚类质量不高、算法参数依赖性大、聚类类别个数和聚类中心无法准确确定等问题,在此提出了基于数据场和单次划分的聚类算法(DF_SPCA).该算法通过分析数据的分布特征,引入数据场理论,在分析每个数据对象的距离和势值分布图的基础上确定聚类中心.等聚类中心确定后,其余数据点在比自身势值更高的数据点中找到与其距离最小的数据点,将类标与该数据点保持一致,从而实现单次划分.最终算法在多个数据集上进行性能测试,并与其他聚类算法进行比较.实验结果证明:DF_SPCA具有较高的聚类质量,能够有效处理任意形状的簇.
关键词:数据场;数据聚类;势值;聚类分析;势值-距离分布
聚类的目的是根据物理对象或者抽象对象之间的相似性将数据集划分成多个不同的类簇,使形成的同一个类簇中的对象具有较高的相似度,而不同簇中的对象相似度较低[1].聚类技术在文本分析[2]和模式识别[3]等诸多领域[4-7]都有广泛的应用前景,在现有的聚类算法中,基于划分的方法是一种被广泛使用的聚类算法,其基本思想是通过预设聚类数目,然后随机选择聚类中心,通过迭代不断优化目标函数,直至获得最优目标函数时完成聚类.代表算法有K-means[8]和FCM[9]等.这类算法的优点在于简单有效,易于操作,但由于算法需要预设聚类个数,对原始数据聚簇的分布形态有极大的影响,同时算法还存在聚类结果对初始簇类中心选择敏感、对噪声适应性差、不能发现任意形状的簇等缺点.基于密度的方法主要是针对任意形状的簇的发现而提出的,其基本思想是通过预设参数来发现数据密集区域,确定核心点,再利用核心点确定密度相连的对象实现聚类,获得最终的聚类结果.代表算法有DBSCAN[10]和OPTIC[11]等等.这类算法的主要优点是具有良好的可扩展性,能够处理任意形状的簇,对于噪声数据是健壮的,但是聚类结果的优劣对参数的依赖性较强,通常需要经验设定.
有些算法[12-17]将数据场理论与传统聚类算法相结合来实现聚类;文献[13,15]将数据场理论与划分算法K-means,PAM等相结合,利用势分布函数获取初始的聚类中心,提高了聚类质量和收敛速度,但保留了基于划分算法需要预设聚类个数和对离群点敏感的缺点;文献[18]提出了一种基于数据场的密度聚类算法DF_DBSCAN,结合势函数分布改进DBSCAN的聚类过程,提高了聚类准确率,但同时增加了算法的复杂度,且保留了DBSCAN算法对参数敏感性强的缺陷.针对上述问题,在此提出了一种基于数据场和单次划分的聚类算法(DF_SPCA).计算每个数据对象的势值和距离值,作出势值与距离的分布图,根据聚类中心具有较高势值,且被较低势值的其他数据点包围的特性确定聚类中心,无需预设聚簇的个数,同时能够自动聚类中心的位置.等聚类中心确定后,将其余点按到最近邻的更高势值对象的最小距离进行划分,该过程只需单次扫描,不需要迭代运算.实验结果表明:DF_SPCA算法有较好的聚类性能,能够实现对任意形状的簇聚类.
1数据场理论
场的概念是英国物理学家法拉第在1837年第一次提出,用于描述物质粒子之间存在的非接触相互作用.随着场理论的发展,场的概念被抽象描述为一个数学概念,用来描述某个数学函数或物理量在空间中的分布规律.数据场理论[8]借鉴了物理学中场的思想,将其场的描述方法和物质粒子间的相互作用引入到抽象的数据空间中.该理论用势函数来描述数据对象之间多对一的相互关系,克服了传统数据聚类算法中只考虑对象之间一对一作用关系的缺陷,认为空间中任意点的状态是其他所有对象共同作用的结果[18-20].
考虑到高斯分布的普适性以及短程场作用更有利于揭示数据分布的聚簇特性,将数据场势函数[8]定义如下:
定义1已知数据空间Ω⊆Rd上的对象集合D={x1,x2,…,xi,…,xn}及其产生的数据场,则任意对象x∈D的势函数描述为
(1)
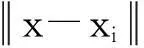
为了分析单数据对象产生的数据场中场强与距离的分布关系,假设mi=1,可得到具体关系如图1所示.
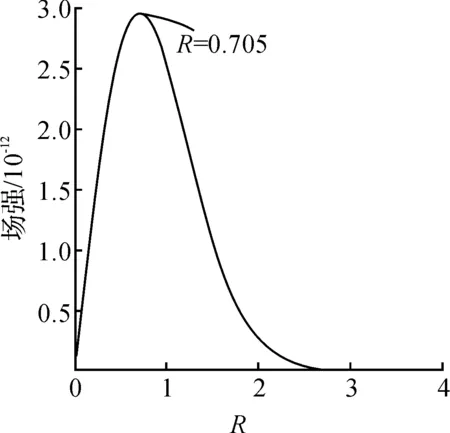
图1 单数据对象数据场中场强与距离的分布关系Fig.1 The distribution of field intensity and distance in the data field of a single data object
当距离数据对象0.705σ时,场强达到了最大值,即以场源对象为中心,半径为0.705σ的球面上存在很强的作用力指向场源对象.而当距场源对象的距离大于R≈2.121σ时,场强函数很快衰减为0,指示着短程场作用.因此,数据空间内的任意对象主要受其R≈2.121σ邻域空间内的数据点影响作用,为了减小计算复杂度,将数据场势函数定义进行修改.
定义2已知数据空间Ω⊆Rd上的对象集合D={x1,x2,…,xi,…,xn}及其产生的数据场,则任意对象x∈D的势函数描述为
(2)
式中p为数据空间内对象x以半径为R≈2.121σ所形成的邻域空间内数据对象的数目.
数据场理论具有较好的刻画数据和反映数据间多对一作用关系的能力,能够对聚类算法获得数据原始聚簇分布有较好的指导作用.
2基于数据场和单次划分的聚类算法
2.1 主要思想
通过结合数据场理论对数据集中的数据对象分析,根据定义2计算每个数据对象的势值,势值越大的数据对象,说明其R≈2.121σ半径内的数据对象越多,且距离该数据对象的距离越近,因此该点很大程度上是该簇类集合的中心.而势值很小的数据对象,说明其R≈2.121σ半径内的数据对象较少,说明该点很可能是游离在外的离群点对象.如图2所示,x和y代表数据对象在二维空间的坐标,而z代表其在空间内的势值强度,可以发现该数据存在4个簇类,且每个簇类的中心位置的势值强度最大,越边缘的数据对象的势值强度越小.另外,簇中心与簇中心的距离较大,而簇内的数据对象到簇中心的距离较小.
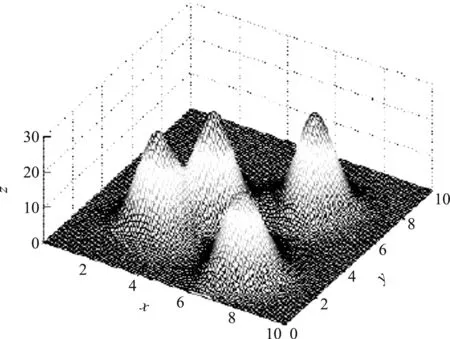
图2 数据场示意图Fig.2 Sketch map of data field
DF_SPCA算法主要基于以下两点规律:
1) 簇类中心被具有较低势值的邻居点包围,且与具有更高势值的其它数据对象有相对较大的距离.
2) 噪声点具有相对较小的势值,且与势值较高的数据对象有相对较大的距离.
对于任意一个数据对象xi,需要计算两个量:数据对象的势值φ(xi)和到具有更高势值的其它点的最小距离δi.数据对象的势值φ(xi)可以根据定义2计算得到.
定义3对于任意数据对象xi,其到具有更高势值的其他数据对象xj的最小距离δi定义为
(3)
式中dij为两个数据对象xi和xj之间的距离.
对于具有最高势值的数据点xi,定义δi为该数据点到数据对象xj的距离的最大值,即δi=maxj(dij).
存在人造样本数据集DataSet1,其数据对象由二维数值属性x和y描述,其数值仅表示数据对象在二维空间中的位置分布,DataSet1数据集在二维空间内的数据分布如图3所示.
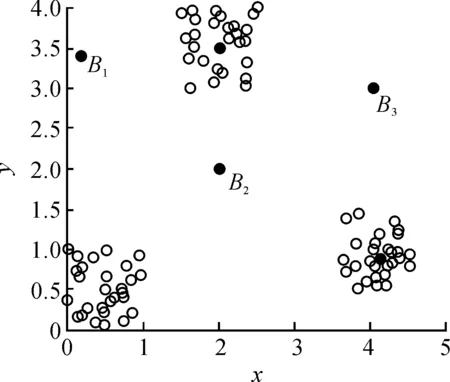
图3 样本DataSet1数据分布图Fig.3 Data distribution map of sample DataSet1
计算样本数据集中每个数据对象xi的势值φ(xi)和到具有更高势值的其他点的最小距离δi,作出φ(xi)和δi的分布图如图4所示.
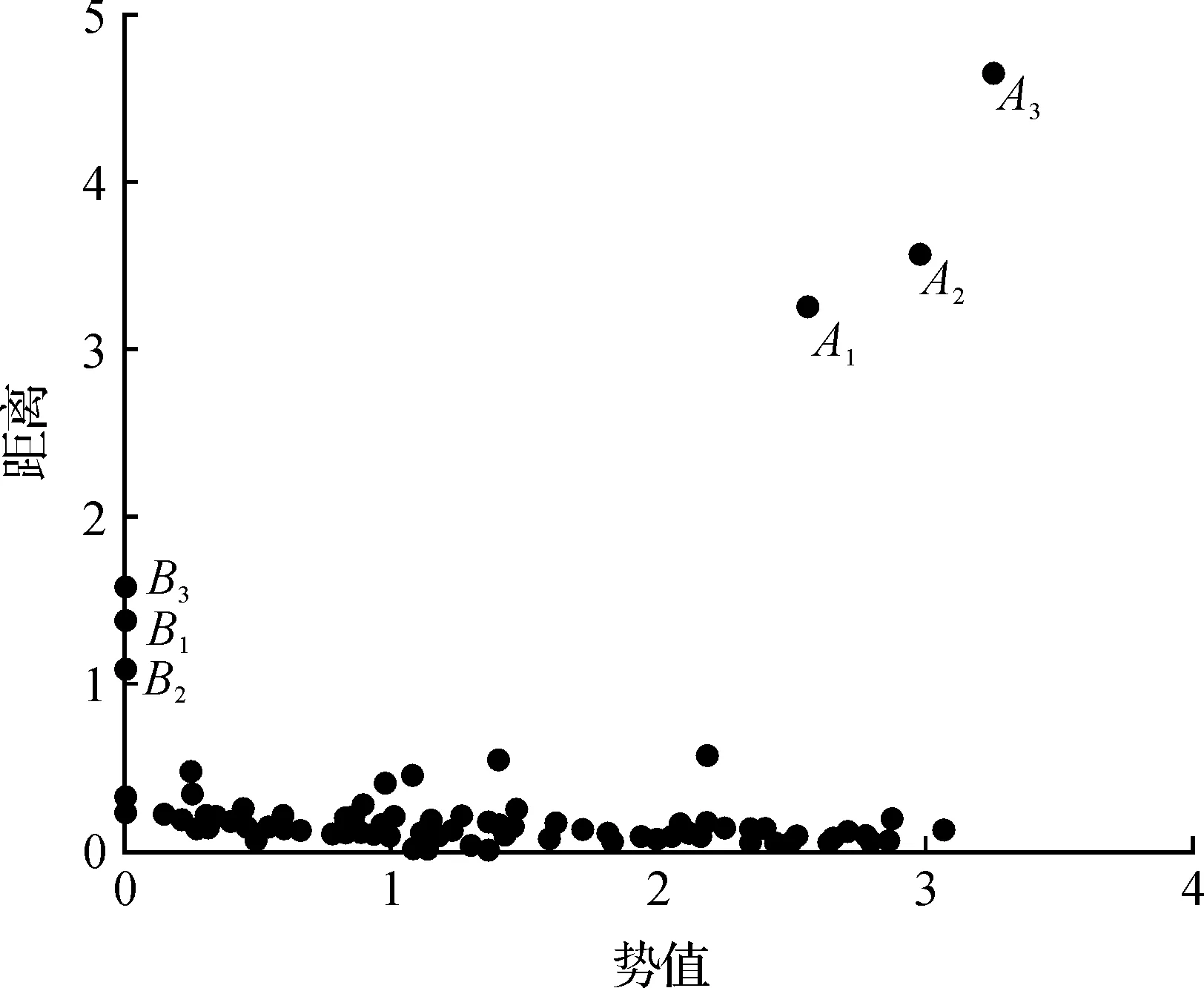
图4 数据对象势值和距离分布图Fig.4 Potential value and distance distribution map of data objects
图3中B1,B2,B3是原始数据分布中的3个簇的簇类中心,其在图4中具有较大的势值φ(xi)和较大的距离δi;A1,A2,A3是远离簇的数据点,即离群点,其在图4中具有较小的势值φ(xi)和较大的距离δi;而其余点均属于某个簇类,具有较小距离δi的性质.
通过分析图4可以确定数据集的簇类中心,等簇类中心确定后,将其余点按到最近邻的更高势值对象的最小距离进行划分,使得当前对象的类别标签与高于当前对象势值的最近邻对象的标签一致,从而对所有对象的类别进行标定.该过程与传统划分算法不同,只需一步完成,不需要迭代计算.
对于噪声点,算法无需用人为设定噪声点阈值截断的方法去除噪声点,而是先算出类别之间的边界,然后找出边界中势值最高的点的势值作为阈值,将此势值阈值记为φb,只保留此类别中大于或等于此势值的点.
算法在参数设定上只需要输入影响因子σ的值,其作用在于控制对象间的相互作用力程,因此σ值的选择也变得至关重要.淦文燕等[12,20]通过求解最小势熵的方法确定最优影响因子取值,由于势熵越大,则表明此时产生的数据场越不稳定;势熵越小,则说明此时产生的数据场越稳定.因此,淦文燕等将影响因子的优化问题转化求解最小势熵的问题.DF_SPCA算法借鉴影响因子优化算法来确定影响因子σ的值,进而对σ值进行整定,使得算法对于不同的数据集,能够根据势熵最小化原则确定相应的σ值.
2.2 算法描述
输入:数据集D={x1,x2,…,xi,…,xn},影响因子σ的值.
输出:聚类结果.
步骤1根据式(2,3)计算每个数据对象xi的势值φ(xi)和相应最小距离δi.
步骤2根据每个数据对象xi的势值φ(xi)和相应最小距离δi作出势值和距离分布图,分析势值和距离分布图确定聚类中心.
步骤3等聚类中心确定后,将所有数据对象按势值从大到小排序.
步骤4将排序后的数据对象序列,按次序将这些点按到最近邻的更高势值对象的最小距离进行划分.
步骤5聚类完成,输出聚类结果.
3实验与性能分析
实验操作系统为Windows 7,开发平台为Microsoft Visual C++ 2010.硬件条件:CPU为Intel Core I5 2.6 GHz,内存为4 GB.为了验证新算法DF_SPCA的性能,算法对5个数据集进行测试.Aggregation,Spiral,Flam这3个数据集来自于东芬兰大学(http://cs.joensuu.fi/sipu/datasets/),而其他2个数据集来自UCI数据库,具体信息如表1所示.

表1 5个真实数据集信息
3.1 聚类结果评价
DF_SPCA采用由Huang和Ng[21]提出的聚类准确率作为评价标准:聚类准确率r的定义为
(4)
式中:ai为最终被正确分类的样本数目;k为聚类数;n为数据集中的样本个数.聚类准确率越高,说明算法的聚类质量越高.当聚类准确率为1时,说明算法该数据集上获得的聚类结果是完全正确的.
3.2 实验结果分析
数据集Aggregation、数据集Spiral、数据集Flame均为二维数据,其中包含各种形状的簇.算法对这3个数据集进行测试,其得到的势值与距离分布图和相应聚类结果展示如图5,6所示.
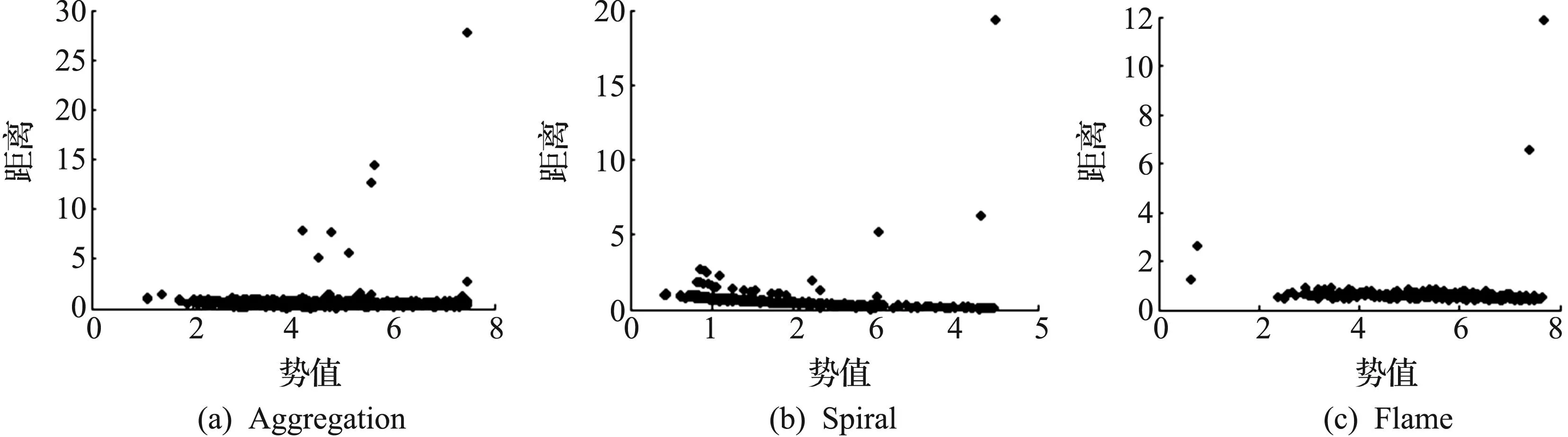
图5 3个数据集的势值和距离分布图Fig.5 Potential value and distance distribution map of the three data sets
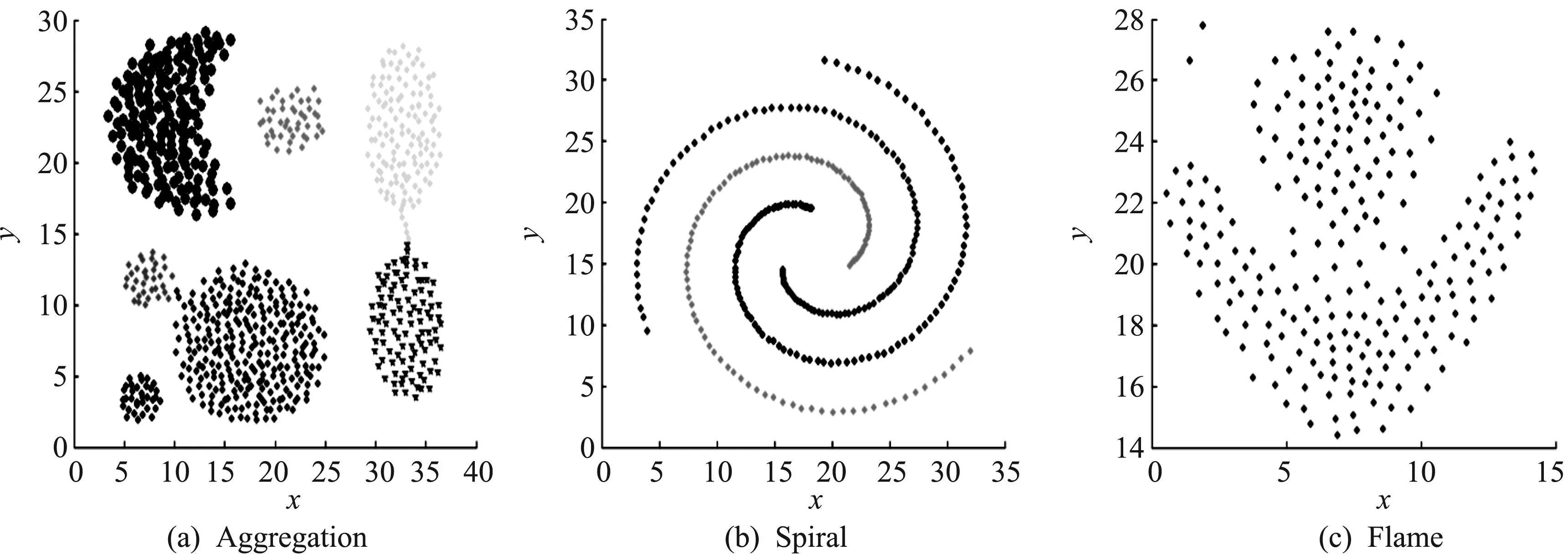
图6 3个数据集的聚类结果分布图Fig.6 Clustering result distribution map of the three data sets
对于数据集Aggregation、数据集Spiral、数据集Flame,算法均能够得到聚类准确率100%的聚类结果.实验结果表明:算法对任意形状和变密度的簇进行聚类,均能获得较高的聚类质量.
算法对UCI数据库数据进行测试,首先对Iris数据进行实验.Iris数据集包含150个数据集,每个数据对象由4个属性值描述,数据集分为3个类:Iris-Setosa,Iris-Versicolour和Iris-Virginica.并在此说明,所有的数据集中,类属性只用来评估算法的聚类结果,不参与聚类过程.图7给出了算法在Iris数据上得到的势值与距离分布图,其对应的σ为0.213.
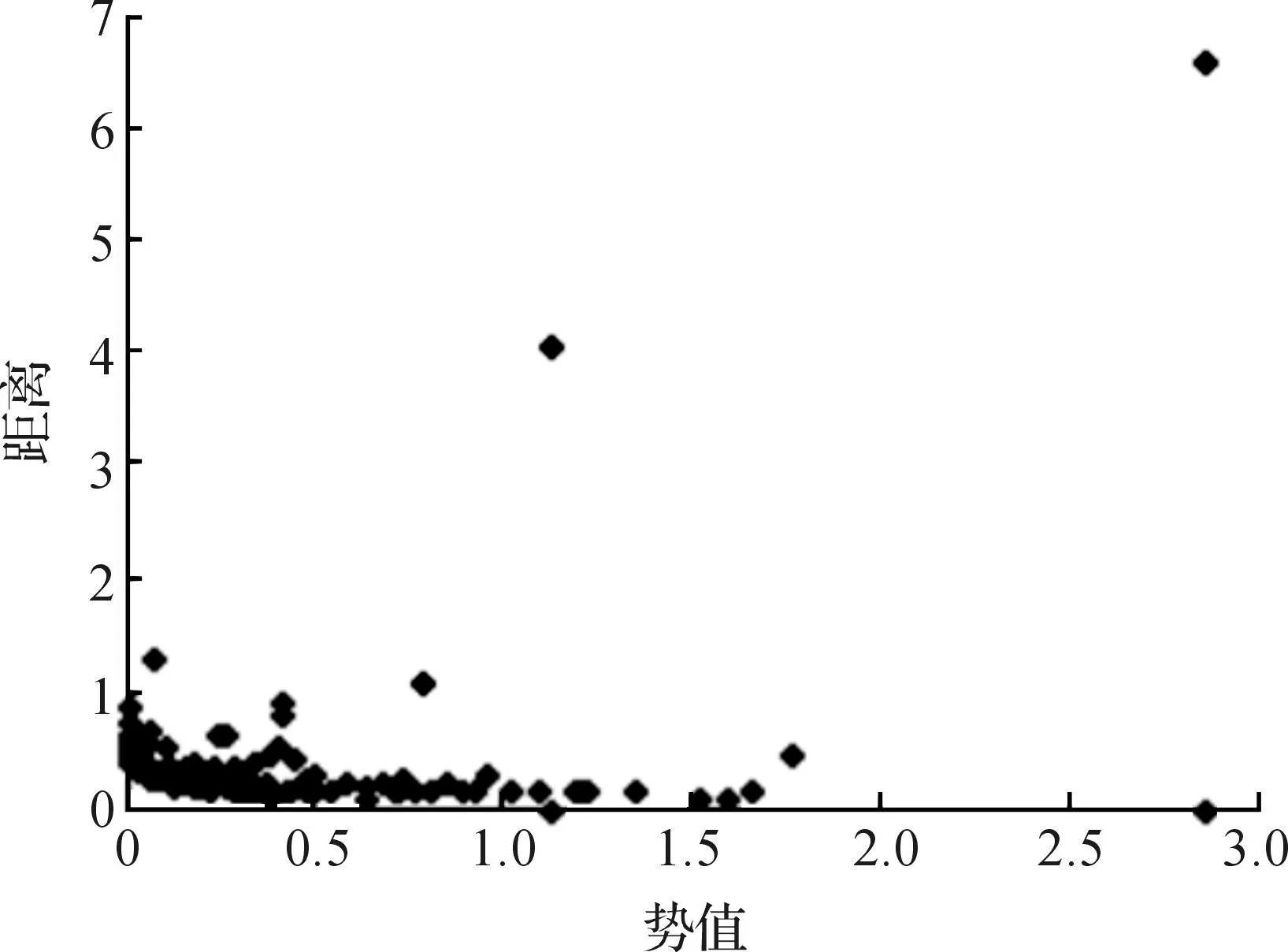
图7 Iris数据的势值与距离分布图Fig.7 Potential value and distance distribution map of Iris data set
DF_SPCA算法、K-means算法、DBSCAN算法、DF_DBSCAN算法[18]在Iris数据集上的聚类准确率r如表2所示.

表2 4种算法在Iris数据集上的聚类准确率r
表2中的聚类结果表明:DF_SPCA算法的聚类准确率比K-means和DBSCAN分别高出了11.5%和26.67%,与DF_DBSCAN算法相当,因此DF_SPCA算法和DF_DBSCAN算法在Iris数据集上均能够获得较好的聚类质量.
Breast-Cancer(乳腺癌)数据集最早由Wisconsin州立医院大学提供,含有699个数据对象,分为2个类:恶性肿瘤(Malignant)和良性肿瘤(Benign).每个数据对象由9个数值属性描述.图8给出了DF_SPCA算法在Breast数据上得到的势值与距离分布图,其对应的σ为6.824.
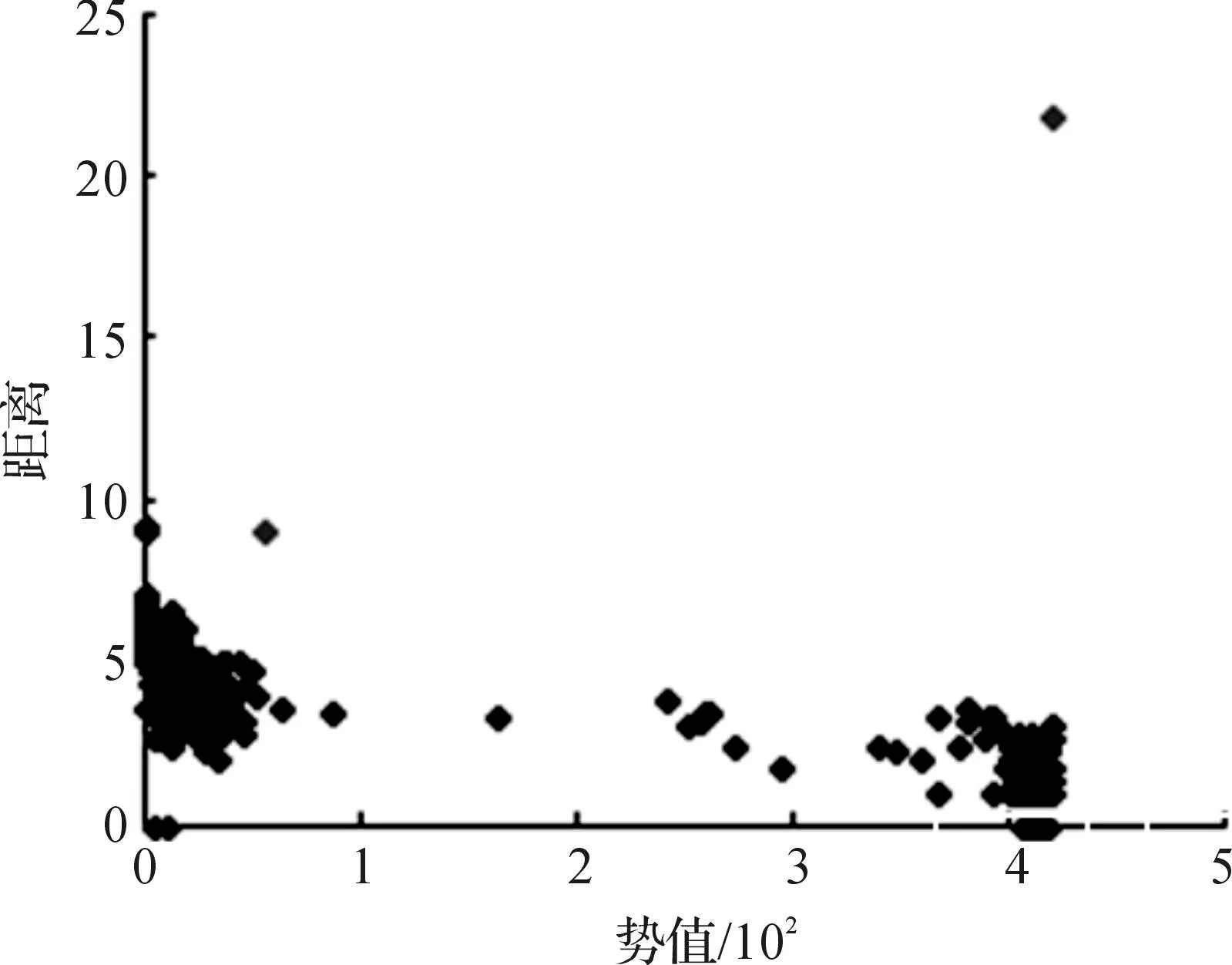
图8 Breast数据的势值与距离分布图Fig.8 Potential value and distance distribution map of Breast data set
DF_SPCA算法、K-means算法、DBSCAN算法、DF_DBSCAN算法在Breast数据集上的聚类准确率r如表3所示.
表34种算法在Breast数据集上的聚类准确率r
Table 3Clustering accuracy of four algorithms on Breast data set

算法K-meansDBSCANDF_DBSCANDF_SPCAr0.92800.65520.91560.9380
表3中的聚类结果表明:DF_SPCA算法的聚类准确率比K-means、DBSCAN和DF_DBSCAN分别高出了1%,28.28%和2.24%.因此DF_SPCA算法的性能更好.
算法在不同数据集的实验结果表明:DF_SPCA算法与其他算法相比,能够取得更好的聚类准确率,因此算法的性能更好.
3.3 算法复杂度分析
假设聚类对象数据集规模是n个数据(样本),则DF_SPCA算法的时间复杂性主要由计算每个数据对象的势值与距离构成的,该过程的计算复杂度分别为O(n2),等聚类中心确定后,算法只需经过一次划分就能完成聚类,其计算复杂度为O(n-k),其中k为确定的聚类中心数目.
一般基于划分的聚类算法,如k-means算法,其时间复杂度是O(tkn),通常基于层次和基于密度聚类算法,如DBSCAN算法,其时间复杂度为O(n2),其中t为迭代次数,k为聚类个数,n为数据对象个数.DF_DBSCAN算法的时间复杂度与DBSCAN算法相似.从以上理论分析可知:相比于基于划分聚类算法,DF_SPCA算法复杂度要高,但与基于层次和基于密度的聚类算法相当,主要消耗在计算每个数据对象的势值和距离的过程中,但是其优势在于无需确定聚类个数,并能自动确定聚类中心和对于任意形态分布的数据集均能得到较满意的聚类结果,因此可以在一定程度上弥补其时间复杂度较高的缺陷.
4结论
笔者提出了一种基于数据场和单次划分的聚类算法(DF_SPCA),引入数据场理论,使其具有反映数据间多对一作用关系的优势,进一步计算每个数据对象的势值和相应的距离.通过分析每个数据对象的势值和距离分布确定簇类中心,得到的聚类结果更加符合数据的原始分布,使能获得较好的聚类质量,实验验证了本算法的可行性和有效性.DF_SPCA算法的惟一参数σ值采用势熵最优算法选取,使得算法具有一定的自适应性,同时算法不需要预先设定聚类个数,能够自动确定聚类中心,并且能够处理任意形状的簇和离群点.下一步的研究重点是使用DF_SPCA算法对混合属性数据实现高质量的聚类,进一步探讨如何对混合属性数据进行高效聚类.
参考文献:
[1]HAN J, KAMBER M. Data mining concepts and techniques[M]. San Francisco: Morgan Kaufmann,2001.
[2]ZHANG W, YOSHIDA T, TANG X J, et al. Text clustering using frequent item sets[J]. Knowledge-based systems,2011,23(5):379-388.
[3]HAN J, KAMBER M, PEI J. Data mining concepts and techniques[M]. 3th ed. San Francisco: Elsevier,2011.
[4]IAMON N, BOONGOEN T, GARRETT S, et al. A link-based cluster ensemble approach for categorical data clustering[J]. IEEE knowledge and data engineering,2012,24(3):413-425.
[5]龙胜春,傅佳琪,尧丽君.改进型K-Means算法在肠癌病理图像分割中的应用[J].浙江工业大学学报,2014,42(5):581-585.
[6]高雪,谢仪,候红卫.基于多指标面板数据的改进的聚类方法及应用[J].浙江工业大学学报,2014,42(4):468-472.
[7]肖刚,吴利群,张元鸣,等.一种基于协作频度聚类的Web服务信任评估方法[J].浙江工业大学学报,2014,42(4):393-399.
[8]淦文燕,李德毅.基于核密度估计的层次聚类算法[J].系统仿真学报,2004,16(2):302-306.
[9]余建桥,张帆.基于数据场改进的PAM聚类算法[J].计算机科学,2005,32(1):165-168.
[10]王海军,邓羽,王丽,等.基于数据场的C均值聚类方法研究[J].武汉大学学报(信息科学版),2009,34(5):626-629.
[11]李学,苗夺谦,冯琴荣.基于数据场的粗糙聚类算法[J].计算机科学,2009,36(2):203-206.
[12]李春芳,刘连忠,陆震.基于数据场的概率神经网络算法[J].电子学报,2011,39(8):1739-1745.
[13]JI Z X, SUN Q S, XIA D S. A modified possibilistic fuzzy c-means clustering algorithm for bias field estimation and segmentation of brain MR image[J]. Computerized medical imaging and graphics,2011,35(5):383-397.
[14]BERGET I, MEVIK H B, NAES T. New modifications and applications of fuzzy C-means methodology[J]. Computational statistics & data analysis,2008,52(5):2403-2418.
[15]ESTER M, KRIEGEL P H, SANDER J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise[C]// Proceedings of the National Conferences on Aritificial Intelligence. Stockholm: Stockholm University,1998:226-231.
[16]DAVE R N, BHASWAN K. Adaptive fuzzy c-shells clustering and detection of ellipses[J]. IEEE transactions on neural network,1992,3(5):643-662.
[17]ANKERST M, BREUNIG M, KRIEGEL H P, et al. OPTICS: ordering points to identify the clustering structure[J]. ACM sigmod record,1999,28(2):49-60.
[18]杨静,高嘉伟,梁吉业,等.基于数据场的改进DBSCAN聚类[J].计算机科学与探索,2012,6(10):903-911.
[19]李德毅,杜鹢.不确定性人工智能[M].北京:国防工业出版社,2005.
[20]淦文燕,李德毅,王建民.一种基于数据场的层次聚类方法[J].电子学报,2006,34(2):258-262.
[21]HUANG Z. Clustering large data sets with mixed numeric and categorical values[C]// In the first Pacific-Asia Conference on Knowledge Discovery and Data Mining. Singapore: World Scientific Publishing,1997:21-34.
(责任编辑:刘岩)
A single partition clustering algorithm based on data field
ZHANG Ni, CHEN Tiantian, HE Xiongxiong
(College of Information Engineering, Zhejiang University of Technology, Hangzhou 310023, China)
Abstract:Most existed clustering algorithms have problems such as low clustering quality, parameter sensitivity, and difficulty in determining cluster centers and number of clusters. In this paper, a single partition clustering algorithm based on data field (DF_SPCA) is proposed to solve the problems. Firstly, through analyzing the distribution of the data, the data field theory is introduced. Base on analysis of each data object distance and force distribution, the cluster center is determined Then the rest data point will find out the nearestt point from the data points with higher potential value and keep in same cluster with it. Finally, the proposed method is tested on a series of data sets and the results show that DF_SPCA algorithm has a better clustering quality and can deal with clusters of arbitrary shape.
Keywords:data field; data clustering; potential value; cluster analysis; potential value and distance distribution
中图分类号:TP39
文献标志码:A
文章编号:1006-4303(2016)01-0052-06
作者简介:张霓(1970—),女,浙江杭州人,副教授,硕士生导师,研究方向为医疗信息系统和移动机器人,E-mail:zn@zjut.edu.cn
基金项目:国家自然科学基金资助项目(61473262)
收稿日期:2015-06-19
猜你喜欢
软件导刊(2016年11期)2016-12-22 21:36:40
科技创新导报(2016年21期)2016-12-17 13:19:49
对外经贸(2016年8期)2016-12-13 03:56:53
价值工程(2016年31期)2016-12-03 22:21:20
数学学习与研究(2016年19期)2016-11-22 11:38:21
商场现代化(2016年26期)2016-11-21 22:21:20
商情(2016年39期)2016-11-21 08:45:54
新媒体研究(2016年19期)2016-11-18 19:48:34
大经贸(2016年9期)2016-11-16 16:16:46
中国市场(2016年33期)2016-10-18 12:16:58
