
排序的常用方法及其改进
2016-03-24 02:43:58胡佳
现代计算机 2016年8期
胡佳
(南昌师范学院数学与计算机科学系,南昌 330000)
排序的常用方法及其改进
胡佳
(南昌师范学院数学与计算机科学系,南昌 330000)
介绍几种常用的排序方法及其改进,有简单的直接插入排序和改进的希尔排序;有简单的交换气泡排序以及改进的快速排序;还有单向扫描的改进的气泡排序。每种排序都给出它的主要思想,排序的主要过程和代码,改进的算法给出时效的分析。
排序;改进;时效分析
0 引言
在日常生活中我们有很多需要排序的工作,假如是少量的数据进行排序,那我们在可以通过肉眼来判断和安放数据,但是如果数据量很大的时候,用日常的方法就难以排放数据,这时候我们可以给计算机一个算法,让计算机来给大批量的数据进行排序。
C语言程序设计课程教学中,我们就学习过排序算法中的一种冒泡排序,实际上还有很多种排序的方法,它们的稳定性和效率都不一样。这部分内容我们是方在数据结构课程中介绍。这里我们首先给排序下一个定义,对于n个结点组成的线性表(a0,a1,…,an-1),按照结点中某个字段的值的递增或递减的次序,对列表中的各个结点进行重新排列的过程,我们可以称为排序。排序的方法分为内部排序和外部排序两大类。内部排序指得是排序的整个时间段所有的结点都存放在内存,调整待排序的结点的位置也是在内存;外部排序指的是排序期间,有大部分的结点存放在外存,排序的过程需要借助内存来调整存放在外存正在等待排序的结点。
假设数据结点A0,A1,…,An-1的关键字的值依次是key0,key1,…,keyn-1。这里数据结点都是线性结构,在实际应用中可以用数组来实现。因此数据结点的排序的过程就是为了确定关键字下标排列的过程,即tag[0],tag[1],…tag[n-1](0<=tag[i]<=n-1,0<=i<=n-1),0<=i<= n-1,当i≠j时,tag[i]≠tag[j]),所以当关键字相等时,数据结点通过某种排序方法排序后,数据结点的先后次序依然不变。即keytag[i]=keytag[j](tag[i]
1 排序问题的简单算法和改进算法

首先看简单的插入排序,它是稳定的,不仅适用于线性表的顺序存储,而且适用于线性表的链式存储。这里我们用顺序存储的数组来实现直接插入,它的算法思想很简单,就是先将原始数据结点的第一个结点元素看成一个有序的序列,然后依次取原始数据结点序列的第二个、第三个依次插入,直到插入最后一个数据结点为止。
以下是实现功能模块的源代码:

该算法的基本操作是两个数据结点之间的比较,排序经过了n-1次的插入,在每轮的插入过程中要进行n-x次的比较,x表示的是第几轮的插入。整个排序的过程需要最多需要经过∑_1^(n-1)x次的比较,即n(n-1)/2,比较次数最少的为n-1,这种排序适用于数据结点个数比较少的情况。

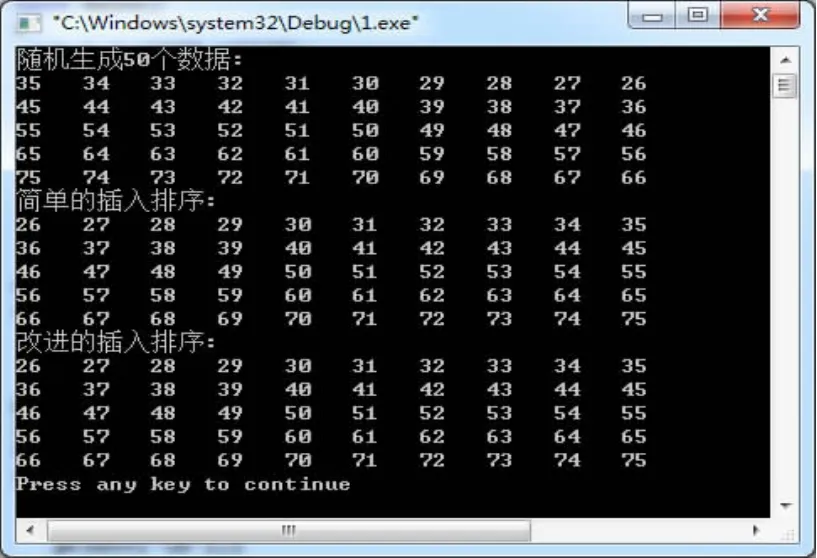
简单直接的插入排序只是比较相邻的两个数据结点,一次比较仅仅把数据结点移动一个位置而已。如果要对位置相隔较远的数据结点进行比较,并且使得结点在比较以后能够一次跨越较大的距离,这就需要把数据结点中值较小的结点尽快的往前移动,值较大的尽量快地往后进行移动,以此来提高排序的速度。这就需要对简单的插入排序进行改进。改进的思想如下:首先以dis1为步长,并且dis1>0&&dis1 接着在每组中进行简单的插入排序。然后以dis2为步长,并且dis2>0&&dis2 由于步长的不断减少,数据结点越来越有序,因而数据结点的比较次数和移动次数也越来越少。这里步长序列的选取并无定论,但是我们可以知道这种排序的总比较次数和总移动次数要比简单选择排序少很多,且它是一种不稳定的排序。以下是实现功能模块的源代码: 改进的排序时效分析很难,关键码的比较次数与记录移动次数依赖于步长因子序列的选取,当分组较多时,组内元素较少;一趟中直接插入排序元素少,循环次数就少;当分组较少时,组内元素增多,但已接近有序,循环次数并不增加。因此,希尔排序的时间复杂性在O(nlog2n)和O(n2)之间。 现在我们将随机生成50个整数,然后对上面的算法进行检验,检验代码如下: 验证的结果如图1所示。 图1 我们将看一种冒泡排序的改进,这种冒泡排序只允许从前向后扫描,它的改进算法思想为,在从前往后一轮比较以后,记录下最后往下调的数据结点的位置,若这个数据结点的位置是tag,那么下一遍的范围在0-tag,假如某轮没有交换的数据结点,那么整个排序就结束。所以整个排序有可能少于n-1轮,这就大大的提高的排序的效率,以下是实现功能代码。 现在我们将随机生成50个整数,然后对上面的算法进行检验,检验代码如下: 验证的结果如图2所示。 图2 我们首先选中一个数据结点X,把它作为标杆,然后从区间两端向中间进行比较和交换,使得X前面的数据结点都比X小,而X后面的数据结点都不比X小,然后我们把X放在前后两部分的分界处,这样就可以将整个区间分成两个子区间。按照这样方法一直做下去,直到区间为空位置,这时的序列就变成了有序的序列集合。它实际上是一种改进了的交换排序。以下是实现功能模块的源代码: 从空间复杂性看,改进的排序是递归的,每层递归调用时的指针和参数均要用栈来存放,,存储开销在理想情况下为O(log2n),在最坏情况下为O(n)。 从时间复杂性看,在n个记录的排序表中,一次划分平均有小于或等于n次关键码比较,时间复杂性为O(n)。理想情况下,每次划分,正好将分成两个等长的子序列,则需要的排序趟数为小于或等于log2n,故时间性能为O(nlog2n)。 最坏情况下,每次划分,只得到一个子序列,时间复杂性为O(n2)。 通常情况上,快速排序被认为在同数量级(O(nlog2n))的内排序方法中平均性能最好的。 这种改进的排序是一个不稳定的排序方法。 以上介绍了主要介绍了几种常用的排序方法及其改进,有简单的直接插入排序和改进的希尔排序;有单向扫描的改进的冒泡排序;有双向扫描的改进的交换排序。每种排序都给出它的主要思想,排序的主要过程和代码,以及时效的分析,希望对大家日常生活中的排序应用有所帮助。 [1]胡佳.高职高专《数据结构》课程教学改革探析[J].江西教育学院学报,2012(6). [2]胡佳.几种典型关联规则算法的分析与比较[J].现代计算机(专业版),2011. Common Methods of Sorting and Its Improvement HU Jia (Department of Math and Computer Science,Nanchang Normal University,Nanchang 330000) Introduces several commonly used methods and their improvements,there are simple direct insertion sort and improved shell sort;there are a simple exchange bubble sort and improved quick sort;there is the improved bubble sort which scans for one way.Gives the main idea of each sort,main process and code,and the time analysis of improved algorithm. Sort;Improvement;Time Analysis 1007-1423(2016)08-0061-05 10.3969/j.issn.1007-1423.2016.08.013 2015-12-24 2016-02-28 2013年江西省高等学校教学改革研究课题、2014年江西省社会科学规划项目 胡佳(1982-),南昌新建人,硕士讲师研究方向为计算机教育和数据挖掘







2 结语
猜你喜欢
海外文摘·文学版(2022年4期)2022-04-14 21:55:16成都信息工程大学学报(2021年5期)2021-12-30 06:25:30当代音乐(2018年3期)2018-05-14 18:46:07数学物理学报(2018年1期)2018-03-26 08:16:42河北科技大学学报(2015年5期)2015-03-11 16:16:37电测与仪表(2014年2期)2014-04-04 09:04:00电子设计工程(2014年12期)2014-02-27 11:58:23电力自动化设备(2013年11期)2013-09-18 02:55:16儿童时代·快乐苗苗(2012年8期)2012-04-29 00:44:03儿童时代·快乐苗苗(2012年7期)2012-04-29 00:44:03
