
用半分布式汇流结构改善新安江模型参数外推能力研究
2016-03-23 00:28王加虎徐秀丽习雪飞
中国农村水利水电 2016年6期
王加虎,袁 莹,李 丽,徐秀丽,习雪飞
(河海大学水文水资源学院,南京 210098)
利用水文模型对无历史实测径流资料的地区(本文简称无资料地区)进行水文预报是一个富有挑战性的问题[1],多年来,众多学者从模型参数的空间规律性出发,研究现有的水文模型在无资料地区的应用,如:周研来等[2]利用VIC(Variable Infiltration Capacity Macroscale Hydrologic Model)模型,采用了多元回归方法建立了参数移用公式,并用来推求无资料地区的水文模型参数;再如柴晓玲等[3]研究了IHACRES模型在无资料地区径流模拟中的应用,对模型进行参数优选之后移用于其他流域,并将该模型模拟结果与三水源新安江模型模拟结果进行对比。
在众多水文模型当中,TOPMODEL(TOPography based hydrological MODEL)、SCS(Soil Conservation Service)等模型由于其设计、结构和参数等遥感数据有关,学者认为这类模型更容易应用到无资料地区、并不断用实践去加以证实。如胡彩虹等[4]将TOPMODEL模型应用在无资料的半湿润半干旱地区,得到了比较满意的结果;再如甘衍军等[5]依据土地利用、土壤类型等遥感数据确定SCS模型参数,根据流域降水资料对东西汊湖集水域不同时段的径流量进行了模拟,并采用径流系数法对SCS产流模型的模拟精度进行了验证,得到了可靠的模拟结果。
新安江模型是具有世界影响力的中国本土水文模型,在有资料的湿润、半湿润地区得到了广泛的应用。姚成[6]等利用参数移植方法开展嵌套式流域无资料情况下的水文模拟研究,发现新安江模型的产流参数移植精度较高、汇流参数的移植精度相对较低。究其原因是洪水汇流参数随下垫面状况、流域地理特征量的差异而不同,因此洪水汇流参数就不能像产流参数一样在相似流域直接移植使用。针对上述情况,本文借鉴半分布式水文模型的汇流计算思路,利用数字高程模型提取流域特征、计算出流域的时段单位线,并据此修改新安江模型的汇流计算模块,进而提高了新安江模型在无资料地区的参数外推能力,详述如下。
1 产流结构
经典的新安江流域三水源的水文模型结构如图1所示[7]。图1中输入的有两个量,分别为降雨量P以及水面蒸发能力EM,输出的也是两个量,分别为流域的蒸散发量E以及流域的出口断面流量Q。方框外面的是在新安江模型中遇到的模型参数,方框里面的是状态变量。模型由4部分构成,第一部分为蒸散发计算,第二部分为产流量计算,第三部分为水源划分,第四部分为汇流计算。本文研究保留模型的前3个结构,只对第四部分的汇流结构做改进,参见图1中的虚线部分结构。
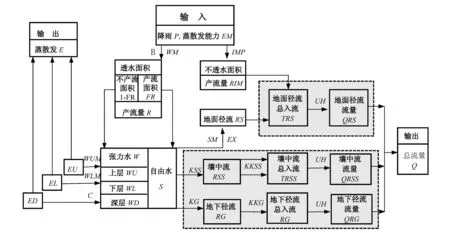
图1 新安江流域水文模型(阴影框内为本次的改进对象)Fig.1 Xin'anjiang model(research within the shadow box)
2 汇流结构
在分布式水文模型中,常利用数字高程模型(DEM)将流域划分为若干规则格网,每个格网单元不妨称为“栅格”。利用常用的流域特征提取方法[8],可以得到每个栅格到达出口(通常是水文站)的路径长L,如图2所示
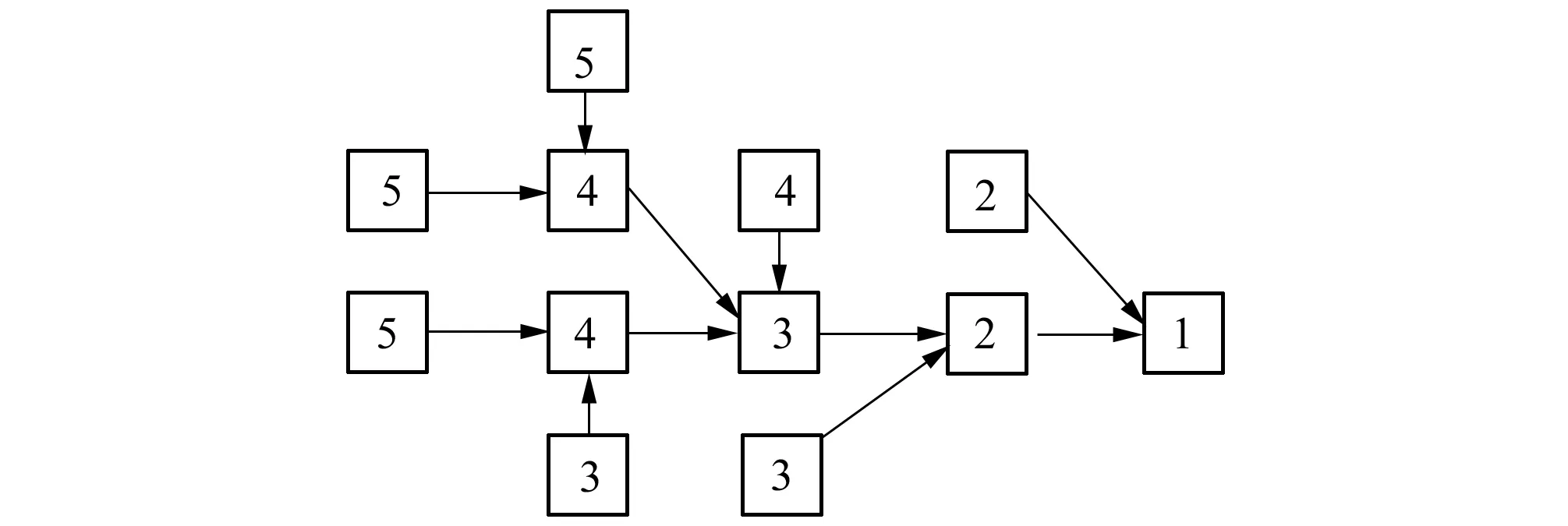
图2 流域栅格化及路径长计算示意图Fig.2 Schematic diagram of basin rasterization and runoff flow
本文对新安江模型的汇流结构进行改进,利用DEM数值,得到每个栅格与出口栅格的高差dH,进而计算出这个栅格与出口之间的平均坡度S。根据流域的平均坡度,可以通过计算得到该栅格汇流到出口的平均速度,计算公式如下:
V=CkS1/2
(1)
式中:V是水流速度,m/s;S是坡面流平均坡度;k是坡面流速度常数,可以根据地表覆被的类型确定,如表1所示;C是一个调整系数,需要由实测资料率定。
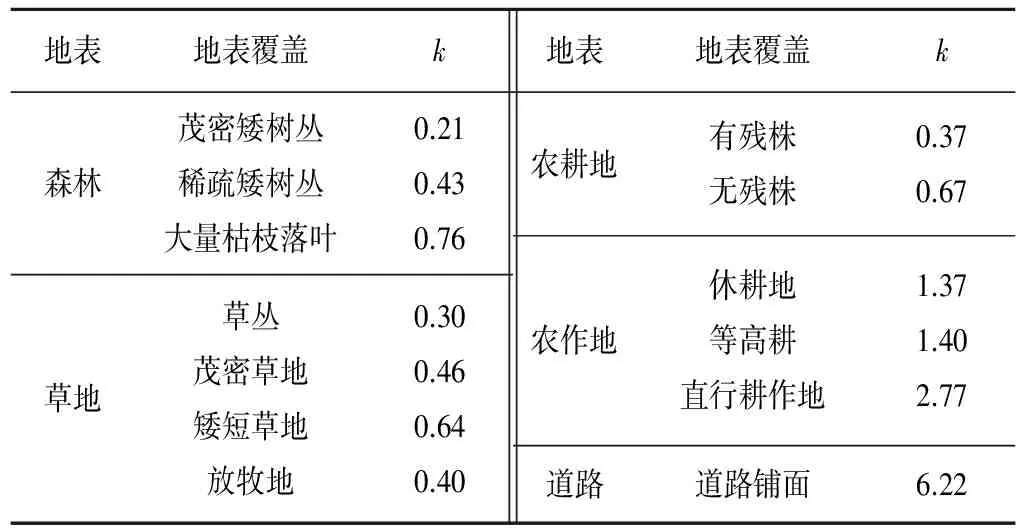
表1 坡地流速度常数k(SCS,1986年) m/sTab.1 The constant k of slope flow rate (SCS, 1986)
以地表水为例,按照水文模型常用的各水源汇流符合线性叠加原理的假定,在流域上不同栅格的自由水(产流和分水源计算的结果)会沿着各自的路径、以不同的流速先后到达出口断面,在出口对所有先后到达的各个栅格水量,按照指定的时段累加,就形成了地表水汇流时段单位线。利用该单位线对产流和分水源模块计算出的水量过程进行卷积计算,就得到了地表水源的汇流计算结果。
为了和三水源新安江模型相匹配,本文使用了3层上述汇流结构,不同水源的汇流速度不同,具体体现在速度公式中的系数C,对应的系数C由实测资料率定,C地表>C壤中>C地下。
3 参数外推能力验证
3.1 目标站的选择
黑龙江省是水文学界公认的新安江模型适用地区之一,为了检验参数外推后对目标站洪水的模拟效果,选择了资料条件较好的南岔站作为目标站。南岔站位于黑龙江省伊春市南岔区,是汤旺河下游右岸一级支流西南岔河出口控制站,属国家二类精度站,集水面积2 582 km2,断面以上河长106 km,至河口的距离15 km,流域平均坡降0.695%,河底平均坡降0.420%,河系形状略呈扇形。河宽80~180 m,总落差410 m。地貌属小兴安岭山地,多丘陵和高山。
3.2 参证站的确定
按照李正最等[9]介绍的相似特征指标的灰色关联度分析方法,逐一分析目标站附近的30个有长系列实测水文资料的站点,首先根据影响径流的主要因素、流域的实际特征及解决问题的目的,建立了3大类11个水文相似性评价指标体系,具体为年平均降雨量、6月平均降雨量、7月平均降雨量、8月平均降雨量、9月平均降雨量、流域面积、主河道长、河道纵坡、形状系数、土地利用及地质条件;然后根据选定的水文相似指标,通过使用Channel Network Tool-I(简称CNT-I)软件包[10]对研究区域进行数字化,提取各个小流域的各项相似特征值数值,其中地质条件为定性指标;根据相应的相似特征值数值可以计算得到流域的特征指标的关联系数;一般来说特征指标的关联度越大,则参证流域与设计流域的关联度越大,其相似程度也越大,因此最后选定带岭站作为率定参数的参证站。
带岭站是西南岔河上游左岸一级支流永翠河出口控制站,位于黑龙江省伊春市带岭区。流域呈西北东南走向,地势北高南低。地貌属小兴安岭山地,流域内山峦起伏,沟谷纵横,河网发育,森林茂密,植被良好,多分布针阔混交林,地下水丰富。断面以上河长61 km,至河口的距离为5.7 km,集水面积为677 km2。流域平均坡降1.18%,河底平均坡降0.771%,流域形状为树枝形。
3.3 流域特征提取
为了减少流域特征提取给研究结果带来的不确定性,本文使用Channel Network Tool-I(简称CNT-I)软件包提取流域特征。CNT-I是河海大学郝振纯教授等开发的提取流域特征信息的通用软件包,在复合信息(复合了自然水系位置的DEM)的控制下按照D8法来提取出与自然水系相匹配的流域特征信息,在洼地和平原区有更好的表现。该软件主要包括栅格河道矢量化、数字水系生成、流域特征提取等功能。所适用的资料包括:黑龙江省二十五万分之一的天然水系图和美国地球物理数据中心1999年发布的全球陆地1 km基础高程(Global Land One-kilometer Base Elevation, GLOBE)数据,GLOBE数据按照经纬网描述高程的空间分布,其空间分辨率为30″(准1 km)。实际使用时,每个栅格的面积和边长都根据栅格中心点的纬度做了简单校正。
提取出的栅格河网如图3所示。从图3中可以看出,目标站和参证站都是南岔河上的水文站点、属于上下游嵌套关系。
3.4 建模及其他资料
模型程序用C#开发,计算时段长1 h,预热期30 d。降雨资料取自黑龙江省水文局的历史数据库,选用带岭站、寒月林场、碧水林场、朝阳林场、南列林场5站雨量资料。蒸发资料采用多年月平均值。植被数据采用中国国家自然地图集中的中国植被区划图。
3.5 验证方法
(1)模型建立之后,在参证站选择10场次洪,包括带岭站建站以来最大洪水1968-07-26、洪峰流量802 m3/s、重现期相当于50年一遇,率定出一组方案参数。
(2)为了避免人为调参对结果的影响,采用SCE-UA算法率定模型参数[11]。SCE-UA算法的基本思路是将基于确定性的复合形搜索技术和自然界的生物竞争进化原理相结合。算法的关键部分分为竞争的复合形进化算法(CCE)。在CCE中,每个复合形的顶点都是潜在的父辈,都有可能参与产生下一代群体的计算。随机方式在构建子复合形的应用,使得在可行域的搜索更加彻底。
(3)率定出的主要参数如表2所示。率定结果中:洪峰流量按照20%许可误差衡量合格率60%;洪水总量按照20%许可误差合格率80%;峰现时刻误差绝对值(因为峰现时刻有正有负)的平均值为1.6 h;确定性系数的平均值为0.82。

表2 参数率定结果Tab.2 The situation of parameter calibration
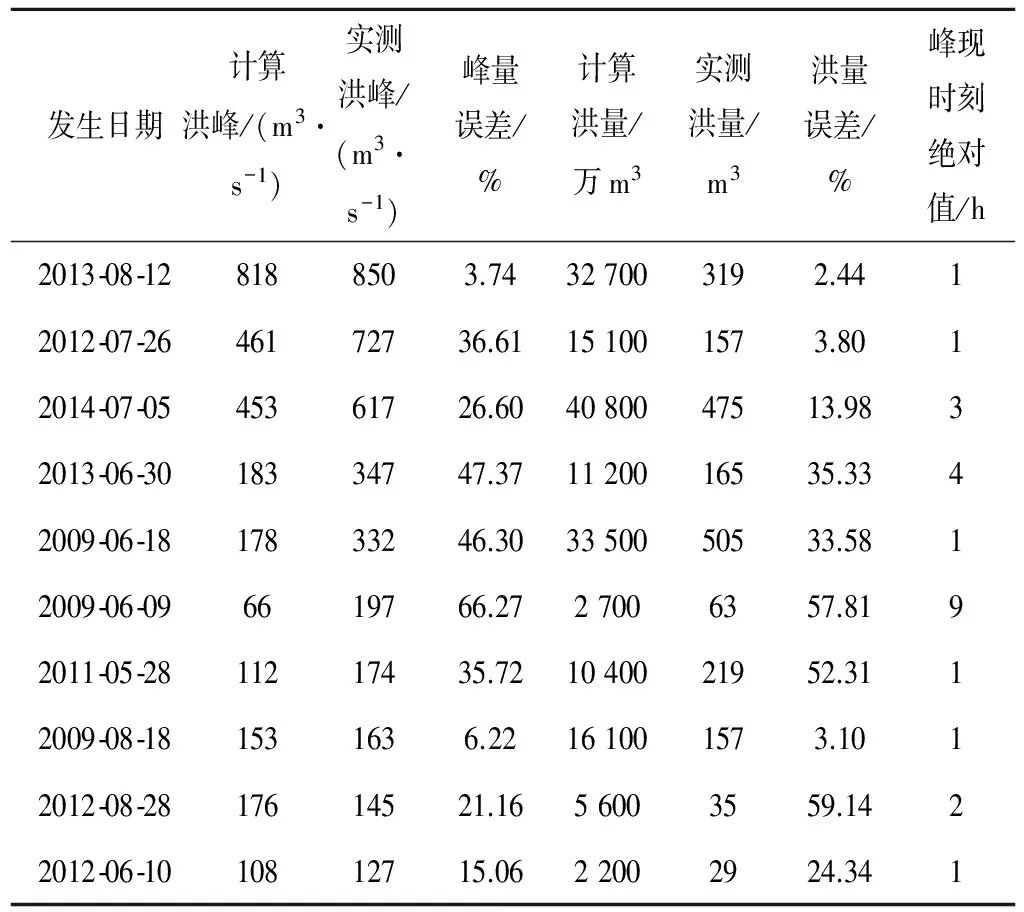
(4)在目标站选择10场次洪,用参证站率定好的产汇流参数、和目标站的实测降雨,模拟出目标站的洪水过程,并与实测值相比较。洪峰流量按照20%许可误差衡量合格率30%;洪水总量按照20%许可误差合格率50%;峰现时刻误差绝对值的平均值为2.4h;确定性系数的平均值为0.70(见表3)。
(5)目标站的验证结果表明,新安江产流模型加上改进的汇流结构,参数在空间上具备一定的外推能力。
4 对照试验
为了研究新汇流方法的实用性和参数外推能力的改善,特设计了对照试验:即以经典的新安江模型产汇流结构建立算例、用参证站的10场次洪率定出参数、移用到目标站上。结果中:峰量拟合的合格率为10%(改进方案为30%);洪水总量拟合的合格率为40%(改进方案为50%);峰现时刻误差绝对值的平均值为5.7 h(改进方案为2);确定性系数的平均值小于0(改进方案为0.70)。
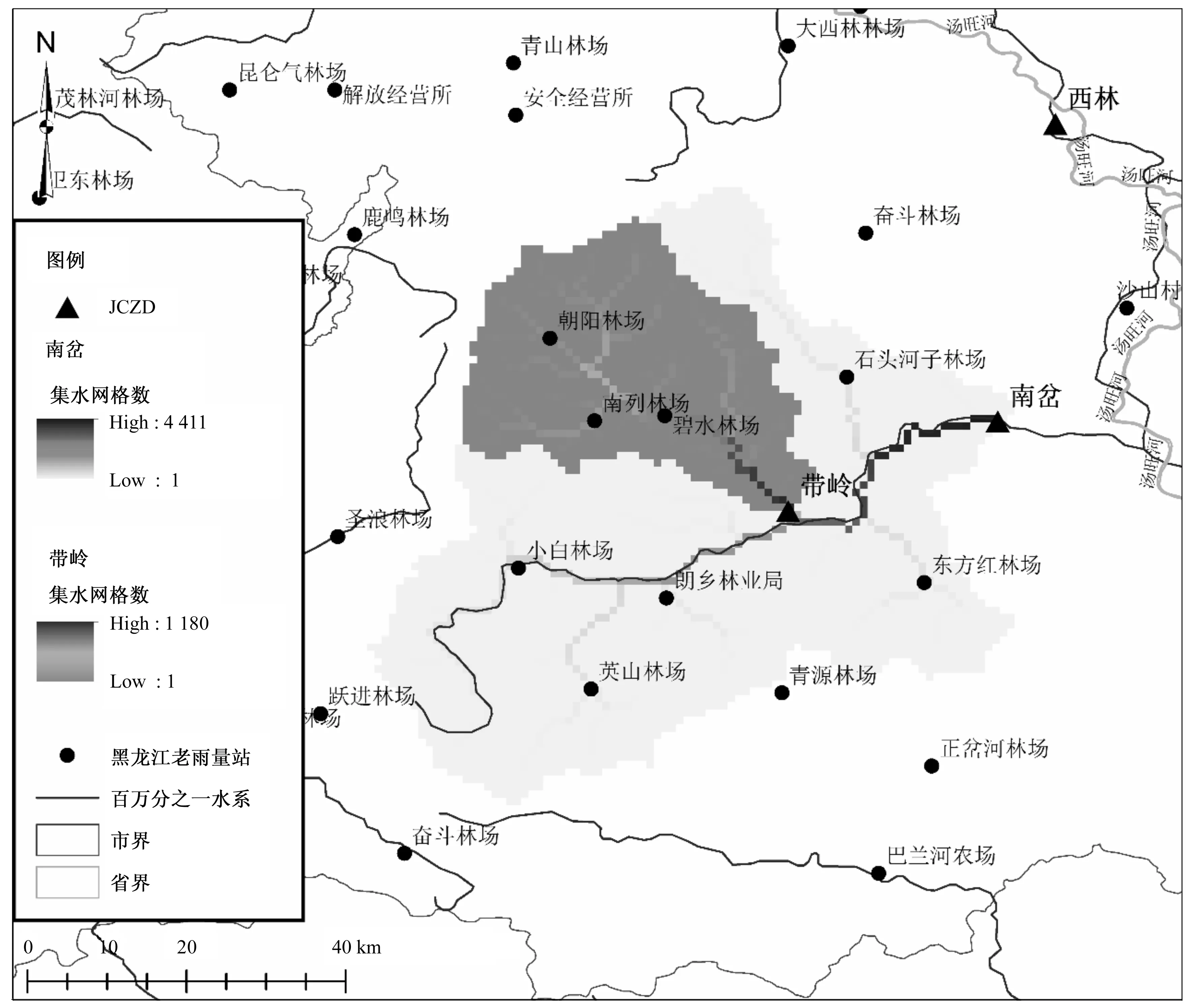
图3 目标站和参证站栅格河网Fig.3 Raster river network of target area and reference station
发生日期计算洪峰/(m3·s-1)实测洪峰/(m3·s-1)峰量误差/%计算洪量/万m3实测洪量/m3洪量误差/%峰现时刻绝对值/h201308128188503.74327003192.4412012072646172736.61151001573.8012014070545361726.604080047513.9832013063018334747.371120016535.3342009061817833246.303350050533.581200906096619766.2727006357.8192011052811217435.721040021952.311200908181531636.22161001573.1012012082817614521.1656003559.1422012061010812715.0622002924.341
对照试验表明:相对于经典结构而言,改进汇流结构的新安江模型,参数外推后的拟合效果有了很大改善,尤其是峰量、峰现时刻和确定性系数的提高最为明显。
5 结 语
本文学习分析了前人的研究结果,尝试引入基于地形和流域特征的时段单位线方法、替换新安江模型的汇流结构,旨在提高模型在无资料地区的参数外推能力。
研究虚拟了一个无实测径流资料的目标站,利用选择无资料地区相似流域时使用较为广泛的灰色关联度分析方法确定了用于率定参数的参证站,避免了站点选择上的人为偏好;利用参证站的10场次洪率定了模型参数,利用率定好的参数和目标站的实测降水,模拟了目标站的10场次洪,并与目标站的实测洪水过程比较。结果表明,搭配新汇流结构的新安江模型,其参数在空间上具备一定的外推能力。
研究利用经典的新安江模型,重复了上述步骤,结果表明:拥有新汇流结构的新安江模型,参数外推之后在洪峰和过程模拟上表现更好。
本文选择的参证站和目标站,同属黑龙江省汤旺河上的南岔河流域且是上下游嵌套关系,两站的洪水过程线本身具备一定的关联性,这应该是本次参数移用实验能够成功的一个重要因素。在黑龙江及其他各省中小河流预警预报建设过程中,大量的新建站(相当于本文的目标站)需要做预报方案,这些站点与具备实测资料的老水文站(相当于本文的参 证站)差异更大,彼种条件下的参数外推还需要进一步深入研究。
□
[1] 谈 戈,夏 军,李 新.无资料地区水文预报研究的方法与出路[J]. 冰川冻土,2004,26(2):192-196.
[2] 周研来,郭生练,郭家力,等.VIC模型参数的地区分布规律及在无资料流域的移用[J]. 水资源研究,2012,1(3):56-63.
[3] 柴晓玲,郭生练,彭定志,等.IHACRES模型在无资料地区径流模拟中的应用研究[J]. 水文,2006,26(2):31-33.
[4] 胡彩虹,郭生练,熊立华,等.TOPMODEL模型在无DEM资料地区的应用[J].人民黄河, 2005,27(6):23-25.
[5] 甘衍军,李 兰,杨梦斐.SCS模型在无资料地区产流计算中的应用[J].人民黄河, 2010,32(5):30-31.
[6] 姚 成,章玉霞,李致家,等.无资料地区水文模拟及相似性分析[J].河海大学学报(自然科学版),2012,41(2):109-113.
[7] 包为民.水文预报[M].北京:中国水利水电出版社,2009:143-167.
[8] 李 丽,郝振纯.基于DEM的流域特征提取综述[J].地球科学进展,2003,18(2):251-256.
[9] 李正最.参证流域灰色相似选择[J].四川水利,1995,16(2):35-39.
[10] 郝振纯,王加虎,李 丽,等.Channel Network Tool-Ⅰ的原理与功能[J]. 水文,2005,25(2):15-19.
[11] 唐运忆,栾成梅.SCE-UA算法在新安江模型及TOPMODEL参数优化应用中的研究[J].水文,2007,27(6):33-35.
猜你喜欢
科技创新与应用(2021年31期)2021-11-09
中北大学学报(自然科学版)(2020年4期)2020-07-13
时代文学·上半月(2019年6期)2019-12-13
照相机(2017年10期)2017-11-22
中国资源综合利用(2016年6期)2016-01-22
中国资源综合利用(2016年3期)2016-01-22
智能建筑电气技术(2015年5期)2015-12-10
雷达与对抗(2015年3期)2015-12-09
太阳能(2015年7期)2015-04-12
弹箭与制导学报(2015年1期)2015-03-11
