
基于K均值聚类分析的流域洪水实时分类修正
2016-03-22 06:54李月玉周建奕蒋汝成云南省水利水电勘测设计研究院昆明6500云南农业大学建筑工程学院昆明6500
中国农村水利水电 2016年12期
李月玉,周建奕,蒋汝成,周 密(.云南省水利水电勘测设计研究院,昆明 6500;.云南农业大学建筑工程学院,昆明 6500)
随着社会经济的不断发展,及时准确的实时洪水预报对确保水库安全,有效减轻下游洪水威胁和灾害,实现整个流域的防洪安全有重要的现实意义。但是由于观测资料误差、流域水文规律变化、流域水文模型简化等问题,使得实时洪水预报系统存在着较多的误差[1-3]。传统的洪水预报误差修正(如:误差自回归法、最小二乘法和卡尔曼滤波算法等[4-7])主要运用当前的水情信息,对历史上的水情信息利用不够充分,这不仅减少了信息来源量,也浪费了大量历史信息,同时对预报的精度亦会有一定影响[8]。近年来,对历史水文信息的数据挖掘尤其是对洪水分类的研究取得了很大进展[9]。在对预报误差的分析中,常会发现许多洪水的误差是十分相似的,例如,对于前期土壤含水量较高,降雨范围高度集中,降雨强度大大超过平均情况的这类型降雨,如果模型仍按平均情况处理,则会使地面径流估计偏小,汇集速度过慢,使洪峰估计偏小。而对于前期比较干旱,降雨范围大,但降雨强度比较温和的这类降雨则正好相反。
本文结合沿渡河流域,采用最为经典,应用也极为广泛的K均值聚类分析方法对历史洪水进行聚类[10,11],在新安江三水源模型的基础上对不同聚类的洪水分别进行参数率定,在实时洪水预报误差修正中根据实时的降雨和洪水信息逐时段判断实时洪水所属类别,然后根据判别结果采用对应类的模型参数进行模型计算,利用计算所得流量值对初始预报值进行修正,从而将历史信息运用到误差修正中,很大程度上减小了模型参数带来的误差,提高了预报精度。
1 研究方法
1.1 K均值聚类分析方法
K均值聚类分析方法通过方差分析来筛选最优的分类数,即定义一个F统计量,平均组间平方和与平均组内平方和之比,数值越大说明该特征的组内关系越紧密,而组间关系越离散,分类相对也就更为合理。将试验中变化的因素称为因子,因子在试验中所取的不同状态称为水平,构建数学模型为:
F=[SSA/(K-1)][SSE/(n-K)]
(1)

(2)
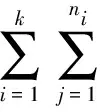
(3)
式中:K为水平数;ni为第i个水平下的样本容量;SSA、SSE分别为组间、组内离差平方和。
1.2 流域洪水实时分类修正方法
由于洪水现象十分复杂,变化频繁,不同类型的洪水具有不同的产汇流规律,如果采用一组水文预报模型参数对全流域洪水进行预报,必然存在很大的预报误差。根据这一产生误差的原因,本文建立了基于K均值聚类分析的流域洪水实时分类修正方法,依据输入的实时降雨及洪水信息,通过计算洪水特征指标到各类中心点的欧式距离对洪水进行实时快速在线分类,然后根据面临时刻洪水的所属类别在模型参数库中选择相应类别的模型参数,最后利用选取的水文预报模型参数进行模型计算,并利用计算出的流量值对初始预报值进行修正。实时洪水分类修正流程如图1所示。

图1 实时洪水分类修正流程图Fig.1 Flow chart for classified correction of real-time flood forecasting
2 实例应用
本文以沿渡河流域34场洪水为例进行基于K均值聚类分析的流域洪水实时分类修正方法的研究,其中1981-1986年之间的30场洪水用于分类,1987年的4场洪水用于预报检验。
2.1 洪水特征指标的选取
聚类前需选择洪水指标,选择原则为:①对洪水发生过程有显著影响的特征因子。②在洪水发生前能获取这些指标的数值,这样方能在实际预报中使用[12]。故本文选择前3天累积降雨量P3 d、前10天累积降雨量P10 d、雨期最大雨强Imax、雨型系数β、雨期累积降雨量P总、起涨流量Q0共6个洪水特征指标。为消除不同指标间的量纲差异,需对数据进行标准化处理,标准化后的数据见表1,分类结果见表2。
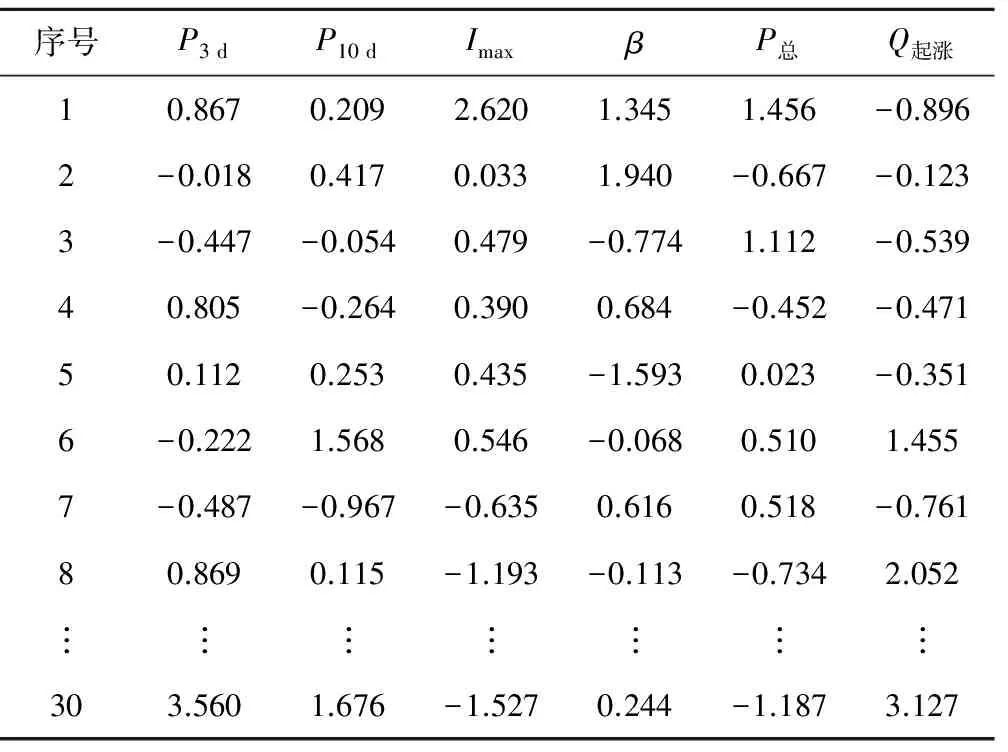
表1 洪水特征指标标准化成果表Tab.1 Standardized characteristic index of selected floods

表2 选取的30场洪水的分类结果Tab.2 Flood clusters results
为进一步验证分类的合理性,对四类洪水的洪水特征值进行统计,结果见表3。由表可看出,各类洪水在洪峰流量、平均降雨量以及平均径流深上都有明显的差异,这说明将历史洪水分为四类能很好地对洪水特征进行区别。
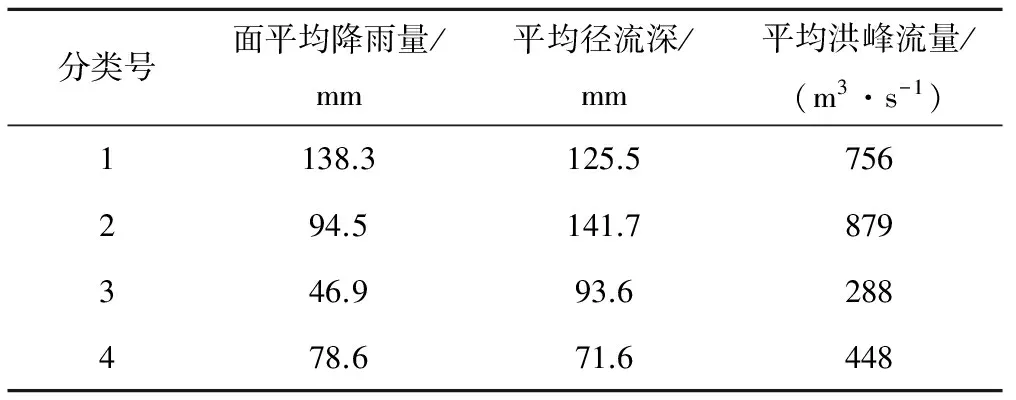
表3 分类洪水的特征Tab.3 Classification characteristics of four types of flood
2.2 模型参数的分类率定
根据表2的聚类分析结果,结合各类洪水的洪水特征,对每一类洪水分别率定一组新安江模型参数[13]。分类后的模型参数率定结果见表4。表中K、WM、WUM、WLM、B、C均为新安江模型的产流参数,分别为蒸发折算系数、流域平均蓄水容量、流域上层蓄水容量、流域下层蓄水容量、流域蓄水容量分布曲线指数、流域蒸发扩散系数;SM、EX、KI、KG为新安江模型的分水源参数,分别为流域自由水平均蓄水容量、流域自由水分布曲线指数、壤中流出流系数、地下水出流系数;CS、CI、CG、KE、XE均为新安江模型的汇流参数,分别为地面线性水库汇流系数、壤中流线性水库汇流系数、地下水线性水库汇流系数、马斯京根法河段传播时间、马斯京根法流量比重系数。

表4 新安江模型参数分类率定结果Tab.4 Parameter estimation for Xin'anjiang model based on flood classification
2.3 实时洪水分类修正
针对1987年的4场洪水,计算其每个时段各指标到各类中心点(各指标平均值构成的6维向量)的欧式距离,逐时段判断实际洪水所属类别,选择其对应的模型参数进行模型计算,然后利用计算值对初始预报值进行修正,其修正效果评定以及与未经修正的传统预报结果的分析比较见表5。

表5 沿渡河流域洪水分类修正方案与传统预报分析比较表Tab.5 Comparison of classified correction method with traditional prediction method for real-time flood forecasting in Yandu River basin
以沿渡河“19870719”和“19870823”两场洪水为例,说明本文提出的方法进行洪水分类实时修正的详细过程,两场洪水初始特征指标值见表6。为了避免因线条过多造成图形繁琐不易辨析,在图2、图3中仅绘出了依据1个时段、2个时段降雨及洪水信息,采用传统方法预报的洪水过程,以及分类实时修正后的流量过程。对“19870719”这场洪水进行实时修正预报的具体过程如下。

表6 “19870719”、“19870823”两场洪水初始特征指标值Tab.6 Initial characteristic index of two selected floods

图2 “19870719”洪水的实测、修正前后的放大的洪峰流量过程线Fig.2 Comparisons among measured data, peak discharge prediction before and after the correction of Flood 19870719
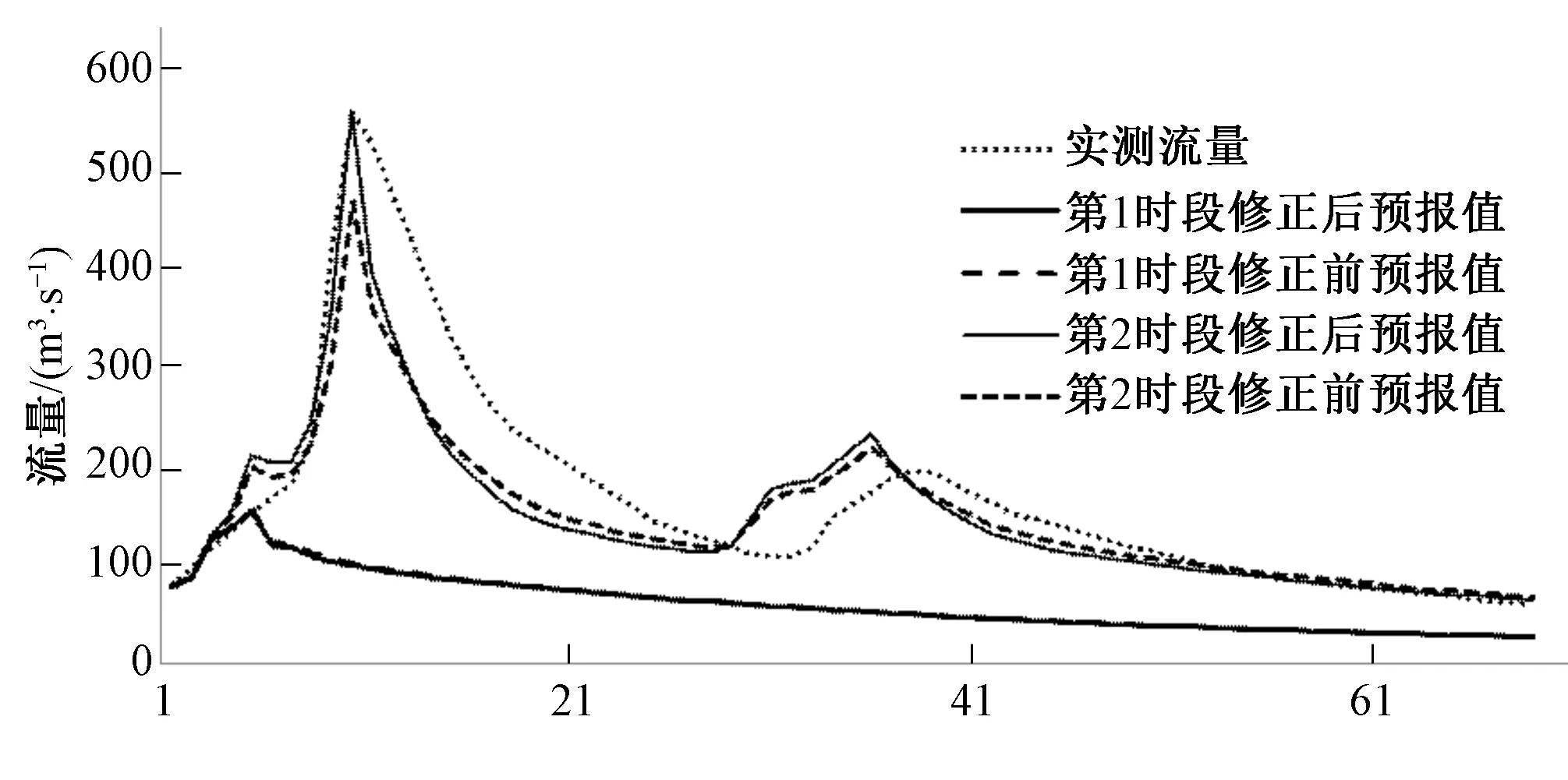
图3 “19870823”洪水的实测、修正前后的放大的洪峰流量过程线Fig.3 Comparisons among measured data, peak discharge prediction before and after the correction of Flood 19870823
(1)首先根据本场洪水初始状态及第1个时段降水及洪水信息判断实际洪水所属类别为第三类,然后选择第三类洪水对应的模型参数进行模型计算;
(2)根据初始状态及第1、第2个时段的降水及洪水信息判断实际洪水所属类别为第一类,则选择第一类洪水对应的模型参数对第二时段的预报值进行实时修正;
(3)按照前述步骤继续下去直到本场洪水结束,如图2(“19870719”)。计算结果显示“19870719”这场洪水实测洪峰流量值为819(m3/s),修正前的预报值为1 106(m3/s),修正后的值为935(m3/s)。按照同样的方法对“19870823”这场洪水进行实时分类修正,其计算结果显示其实测洪峰值为556(m3/s),修正前的预报值为465(m3/s),修正后的值557(m3/s),如图3(“19870823”)所示。通过比较可知本文介绍的实时洪水分类修正方法能有效的提高洪水在洪峰部分的预报精度。
从图2可知修正前的洪峰流量值要明显的大于实测的流量值,而从图3又可以看出洪峰流量的实测值明显大于修正前的预报值。这是因为传统的洪水预报方法通过率定一组水文模型参数来寻求流域径流形成的一般性或平均化规律,未能根据实际降雨和洪水信息实时地考虑洪水情况。因此在遇到特殊大洪水或者小洪水的时候,传统的预报值往往出现偏小或者偏大的情况。本文针对这一问题,根据实时的雨情和洪水信息,选择合理的模型参数进行实时修正,提高了流域洪水预报的精度,尤其是对洪峰流量的预报精度的改善更为显著。因此,利用基于K均值聚类分析进行流域洪水实时分类修正的方法是提高整个流域洪水预报精度的有效方法。
3 结 语
洪水预报的主要目的是为水库及库区下游提供防洪调度服务,因此,如何预报得到准确的洪峰流量和峰现时间是实际生产中最为关注的问题[14]。在洪水预报误差分析中,常会发现许多相同类型的洪水会有相似的误差特性。例如,台风或雷暴雨型洪水,都是由于降雨范围高度集中,降雨强度大大超过平均情况,而模型仍按平均情况处理,自然就会使产流估计偏小,汇集速度过慢,使洪峰估计偏小。那么不同场次的这种类型洪水,引起误差的因素都是高强度和高集中,具有相似性。本文提出的基于K均值聚类分析进行流域洪水实时分类修正的方法弥补了传统预报方法历时信息量利用不足,以及遇到特殊情形时会出现较大误差的缺点,同时也避免了自回归法在洪峰附近修正效果不佳的问题,从而提高了流域洪水预报精度,尤其是洪峰流量的预报精度。
□
[1] 葛守西.一般线性汇流模型实时预报方法的初步探讨[J].水利学报, 1985,(4):1-9.
[2] 瞿思敏,包为民.实时洪水预报综合修正方法初探[J].水科学进展, 2003,14(2):167-172.
[3] 瞿思敏,包为民,石 朋,等.AR模式误差修正方程参数抗差估计[J].河海大学学报, 2003,31(5):497-500.
[4] 何少华.递推最小二乘与误差自回归联合实时校正方法[J].水电能源科学,1996,(2):78-83.
[5] Fortescue T R, Kershenbaum L S,Yolsue B E. Implementation of Self-turning Regulators with Variable Forgetting Factors [J]. Automatica, 1981,17(6):831-835.
[6] Fread D L, Ming J, Kalman A. Filter Enhanced Real Time Dynamic Flood Routine Model[C]∥Proceedings of XXV Congress of Int.Assoc. For Hydrau. Res. Tokyo,1993.
[7] 宋星原.河道洪水实时预报方法研究[D].武汉:武汉水利电力大学, 1995.
[8] 包为民.洪水预报信息利用问题研究与讨论[J]. 水文, 2006,26(2):102-104.
[9] 万新宇,包为民,荆艳东,等.基于主成分分析的洪水相似性研究[J].水电能源科学, 2007,25(5):36-39.
[10] Kanungo T, Mount D M, Netanyahu N S, et al. A Local Search Approximation algorithm for k-means clustering [J]. Computational Geometry, 2004,28(2/3):89-112.
[11] Elkan C. Using the Triangle Inequality to Accelerate k-means[C]∥ /Proceedings of the Twentieth International Conference on Machine Learning (ICML-2003). Menlo Park: AAAI Press, 2003:147-153.
[12] 包为民.水文预报[M].3版. 北京:中国水利水电出版社,2006.
[13] 王佩兰,赵人俊. 新安江模型(三水源)参数的客观优选方法[J]. 河海大学学报, 1989,17(4):65-69.
[14] 李鸿雁,刘寒冰,苑希民,等. 人工神经网络峰值识别理论及其在洪水预报中的应用[J]. 水利学报, 2002,6(6):15-20.
猜你喜欢
Journal of Palaeogeography(2022年1期)2022-03-25
快乐语文(2021年35期)2022-01-18
法律方法(2019年4期)2019-11-16
娃娃乐园·综合智能(2019年6期)2019-07-10
幼儿100(2019年14期)2019-04-30
天津诗人(2017年2期)2017-11-29
摄影之友(影像视觉)(2017年1期)2017-07-18
环球时报(2017-06-14)2017-06-14
现代工业经济和信息化(2016年22期)2016-08-23
少儿科学周刊·儿童版(2015年7期)2015-11-24
