
社会网络链接预测研究方法探析
2016-03-22 05:51:48,
中华医学图书情报杂志 2016年5期
,
“社会网络”是指社会行动者及其之间关系的集合。一个社会网络由多个节点和节点之间的链接组成,其中节点代表个人或其他实体,链接表示他们之间的关系。社会网络通过网络模型刻画社会实体之间的关系,分析社会关系之间的模式和隐含规律,已广泛用于社会学、政治学等多个领域。早期由于数据收集等方面的限制,仅局限于小的团体。在当今大数据时代背景下,社会网络规模庞大,简单的数学知识和原始的人工处理已经不可能对其进行有效的分析[1]。从数据挖掘角度,社会网络分析也被称为链接挖掘[2]。它强调实体之间的相互作用对数据挖掘结果的影响,并扩展了传统数据挖掘中的分类、聚类等任务。
1 链接预测研究内容及意义
链接预测(Link Prediction)是链接挖掘领域中的重要研究方向,是指根据对象或实体的属性以及已有的链接信息预测两个对象或实体之间是否存在链接。它包括两方面的含义:一方面可以理解为识别实际存在但当前网络中并不可见的链接,比如蛋白质相互作用网络、基因调控网络等等;另一方面可理解为基于时刻t的社会网络状态预测t+1时刻将会在网络中增加哪些链接,如在线社交网络、推荐系统等。链接预测拥有广阔的应用前景,如以新浪微博、FaceBook为代表的在线社交网络,通过链接预测,可向用户推荐好友或可能感兴趣的话题。总之,链接预测结果可帮助我们从理论上更好地认识和解释复杂网络演化的机制,有助于网络演化机制的进一步研究。
2 链接预测研究方法及特点
目前,链接预测研究越来越引起人们的关注,计算机领域、物理学领域的学者都提出了各自的方法。下面介绍几种目前链接预测研究中的常用方法。
2.1 基于网络的拓扑结构
将社会网络表示为一个无向图G= 2.1.1 基于邻接点的方法 该方法的核心思想为两个有着共同朋友的人比其他人更有可能成为朋友。对于节点x,用Γ(x)表示x在图G中的近邻。基于上述思想,如果 Γ(x)与 Γ(y)有很大的交集,那么它们在之后产生链接的可能性就会很大。常用的指标有以下几种: (1)公共近邻(Common Neighbors):假设两个节点之间的公共邻接点越多,它们就越相似。这是最为直接的想法,定义为[3]: Sxy=|Γ(x)∩Γ(y)| (2)Jaccard Index:用来描述节点x和y之间拥有相同邻接点的比率,定义为: (3)Adamic/Adar指数:公共近邻和Jaccard系数都是简单的计数,将所有的近邻同等对待,而Adamic/Adar方法考虑了近邻的性质,定义为[4]: 其中k(z)=∣Γ(z)∣,表示节点z的度。 (4)Preferential Attachment(偏好连接、偏好依附):由Barabasi和Albert[5]提出,其核心思想是在真实网络中,新增加的边并不是随机连接的,而是倾向于和具有较大度数的点连接,认为从节点x增加一条边的概率正比于节点x当前的邻接点的数目。定义为: Sxy=k(x)×k(y) Zhou T[6]等在此基础上提出了一种新的相似性测量指标,并认为在链接预测中有更好的表现,即: (5)Resource Allocation(资源配置):定义为: 2.1.2 基于路径的方法 最短距离(Shortest Distance)是基于路径的方法中最简单的方法。两个节点之间的路径越短(除去直接连接的边),则越可能链接。 Katz方法是Katz在研究社会网络时提出一种基于路径的计算节点声望的方法。给予短路径更高的权重,然后将所有的路径加起来,定义为[7]: Local Path也是由Zhou T等人提出的,定义为[8]: S=A2+∈A3 其中∈为参数,A为邻接矩阵,如果节点x和y直接相连,则Axy=1,否则Axy=0。 Liben-Nowell和Kleinberg[9]是最早提出社会网络链接预测模型的学者之一。他们分析了多种基于网络拓扑结构的相似性指标,如最短路径、共同邻居等指标在科学合著网络中的链接预测效果。Zhou T[6]将11种局部算法应用于蛋白质相互作用网络、科学家合著网、美国航空网络等6个实际网络的链接预测中,结果显示最简单的测量指标公共近邻的效果最好,Adamic-Adar指数其次。他们提出的资源配置指标与Adamic-Adar 指数相类似,效果比公共近邻的还好,尤其是对于平均度数较高的网络。Lü[10]等人对比了公共近邻、Katz 指数、Local Path 3个指标在链接预测时的准确度及其计算复杂度。实验表明,公共近邻的计算复杂度最低,但因信息不充足,准确度较低。另外,Katz指数为全局算法,精确度较高,同时计算复杂度也很高。而Local Path是一个很好的权衡,既可以得到相对较高的准确度又不会有很高的时间复杂度。 在利用节点相似性进行链接预测时,对于含权网络的算法的研究还很少。通常我们都认为权重较大的链接在预测中起重要作用,但Lü[11]等人给出了公共近邻、Adamic-Adar指数和资源配置的含权表达式,并将其应用在3个实际网络的预测中,发现权重较小的链路反而起到了更关键的作用。Murata和Moriyasu[12]在公共近邻、 Adamic-Adar指数和偏好连接的基础上,提出了3种加权的相似性指标。 基于网络拓扑结构的预测方法计算相对简单。由于复杂网络的稀疏性等特点,计算时要充分考虑算法的时间及空间复杂性。同时,基于网络拓扑结构方法忽略了节点自身的一些社会属性,导致准确性不高。 其基本思想是如果两个节点拥有的共同特征越多,则认为它们越相似。如两个人具有相同的年龄、学历、职业、兴趣等,则认为他们很像[13]。Getoor[14]等人认为,实体的属性与实体之间的关系有一定的联系,如有共同兴趣或爱好的人更容易成为朋友。在目前的研究中,基于节点属性的方法主要有分类算法和马尔可夫链两类。 2.2.1 分类算法 链接预测问题经常被看作是一个简单的二元分类问题:对于可能有链接存在的两个节点Vi,Vj,,预测lij是1还是0。根据当前网络的连接关系,抽取关系特征集,利用分类算法来分析训练数据集并构造分类器,即链接预测模型,训练后的分类器即可对未知的链接关系进行预测[15]。Hasan[16]等人将最短路径等拓扑学特征、关键词匹配数量等属性作为合著网中每对节点的特征集,用支持向量机、决策树、k最近邻分类法及朴素贝叶斯等分类算法进行了预测。Pavlov[17]从科学家合著网中抽取出公共近邻、最短路径、Jaccard系数等属性作为每对节点的特征向量,通过支持向量机、决策树等分类器进行预测。Guns[18]构建了非洲、中东和南亚3个城市疟疾和肺结核研究领域的加权合著网络,运用机器学习方法发现潜在合作。Naoki Shibata[19]抽取引文网络的结构特征,共同邻居、Jaccard系数、中间中心度以及文献本身的语义特征和属性特征(如被引频次、自引),利用支持向量机构造分类器,对引文网络的节点之间的链接进行预测。 基于分类的链接预测引入分类器,综合多个特征,并利用先验知识训练样本进行预测,显著提高了预测的准确率[15]。抽取一些特征向量构造分类器的难点也在于特征值的正确选取。此外,该方法只能预测网络中已有节点之间产生链接的可能性,未考虑到随时间推移而新增的节点。 2.2.2 马尔可夫链预测方法 马尔可夫预测是应用随机过程中马尔可夫链的理论和方法,研究分析有关现象的变化规律并借此对未来进行预测的一种方法,是根据事件目前的状况预测其在将来各个时刻(或时期)的变动状况的一种预测方法。马尔可夫链模型具有随机性、无后效性及不过分依赖历史数据等特点。与其他统计方法(回归分析、时间序列等)的不同之处在于它无需从各个复杂的预测因子中寻找其相互规律以满足应用马尔科夫链进行分析预测的条件,而只需考虑事件本身历史状况的演变特点,通过计算状态转移概率从而预测内部状态的变化,故马尔可夫链模型在预测中具有广泛的实用性。 Zhu[20-21]等运用马尔可夫链对自适应网站的用户浏览路径进行了预测。Bestavros[22]和Sarukkai[23]使用马尔可夫模型预测用户在某确定时间内可能链接的网页。 利用节点属性信息虽然可大大提高链接预测的准确性,但也存在很多问题。如由于隐私和其他方面的原因,信息往往很难获取,而且对于一些在线社交网络,用户注册时填写信息的真实性和完整性不高,即便获得相关信息也难于确定其准确性。 统计关系学习又称为概率逻辑学习。它是将概率推理模型和逻辑、关系模式结合起来,利用数据间的依赖关系以求得到更高的预测或分类的准确度。现已提出似然关系模型、贝叶斯逻辑程序模型、关系马尔可夫模型等有关统计关系学习方面的模型。 Popsecul[24]利用一种结构化的逻辑回归模型对科技文献的引证关系进行预测,这种模型可以利用关系特征来预测链接的存在。关系特征的定义是由数据库查询引入的,作者显示了如何搜索关系特征空间。Taskar[25-26]等在链接预测领域上应用关系马尔可夫网RMN(Relational Markov Networks)框架,在整个连接图上定义了一个联合概率模型,关系马尔可夫网算法在子图结构上定义了概率模式。在大学网页和社会网两个关系数据集上进行试验的结果表明,运用RMN的集体分类方法和链接标签上的子图模式比扁(Flat)数据分类在预测精度上有显著的提高。 基于概率模型的算法利用节点、链接的历史关系信息,能够发掘网络中潜在的各种关联,准确性较好。但是由于多数人们感兴趣的数据集是稀疏的,因此链接预测构造统计模型的一个难点在于链接的先验概率往往很低,模型建立的复杂度往往比较高[27-28]。 随着互联网和电子商务技术快速发展,推荐系统应运而生。协同过滤技术是目前研究最多、应用最广也是最为成功的推荐技术之一。通过参考与用户具有相似兴趣或需求的其他用户的选择对当前用户进行推荐的基本思想为“和我兴趣爱好相似的人喜欢这样东西,那我也会喜欢这样东西”。Huang[29-30]等人以一个在线书店为例,在协同过滤算法中引入社会网络链接预测研究中的6种基于网络拓扑结构的相似性指标,并对结果进行了比较,发现Katz index的效果最好,其次是偏好链接、公共近邻和Adamic/Adar指数。协同过滤算法中同样存在网络稀疏性问题。 科学知识网络的结构与演化一直都是情报学领域所关心的核心问题之一[31]。为了描绘科学知识结构,我们从文章、作者、主题、期刊等不同角度解释某研究领域的结构及其发展状态。但利用社会网络分析方法对科学知识网络的研究目前尚且处于“描述”阶段,如通过聚类等方法描述某一领域研究热点。在信息、知识大爆炸的今天,仅仅“描述”并不能够满足人们的需求,而是要做到如何“预测”。如果我们能够对知识网络进行很好的预测,就能在一定程度上把握学科未来的发展方向。链接预测研究作为数据挖掘领域的一个新的研究方向,主要集中在复杂网络、计算机、物理学等研究领域。本文总结了目前链接预测研究的常用方法,总体来看,基于节点属性的方法准确率相对较高,但属性信息不容易获取;基于网络拓扑结构的方法相对容易些。对于实际中的网络,都存在网络稀疏性的问题,导致算法的复杂性大大增加。 在生物医学领域,生物数据迅速增长,但仍有很多生物信息,如蛋白质相互作用信息等还未被发现。通过链接预测技术对生物信息网络进行预测,可以避免盲目预测所有链接,能指导实验,节省时间及开销。在图书情报学领域,有学者利用分类算法对合著网络进行链接预测研究,并且近年来有成为热点的趋势。图书情报学的链接预测研究虽然尚处于初步应用性阶段,但通过对科研合著网、引文网络等进行链接预测研究,可以为科研合作、管理决策等提供依据[32]。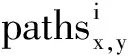
2.2 基于网络节点的属性
2.3 统计关系学习方法
2.4 协同过滤(Collaborative Filtering)算法
3 总结
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
国际眼科杂志(2021年9期)2021-09-15 03:24:42
装备制造技术(2020年2期)2020-12-14 03:09:16
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
数学理论与应用(2016年3期)2016-05-17 04:50:14
中国卫生(2015年12期)2015-11-10 05:13:34
核科学与工程(2015年3期)2015-09-26 11:58:25
