
基于多示例多标记学习的手机游戏道具推荐*
2016-03-19 05:46周志华南京大学计算机软件新技术国家重点实验室南京2100232软件新技术与产业化协同创新中心南京210023
计算机与生活 2016年1期
关键词:机器学习
唐 俊,周志华+1.南京大学计算机软件新技术国家重点实验室,南京2100232.软件新技术与产业化协同创新中心,南京210023
* The National Natural Science Foundation of China under Grant No. 61333014(国家自然科学基金).
Received 2015-05,Accepted 2015-08.
CNKI网络优先出版:2015-08-13,http://www.cnki.net/kcms/detail/11.5602.TP.20150813.1552.004.html
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology
1673-9418/2016/10(01)-0103-09
基于多示例多标记学习的手机游戏道具推荐*
唐俊1,2,周志华1,2+
1.南京大学计算机软件新技术国家重点实验室,南京210023
2.软件新技术与产业化协同创新中心,南京210023
* The National Natural Science Foundation of China under Grant No. 61333014(国家自然科学基金).
Received 2015-05,Accepted 2015-08.
CNKI网络优先出版:2015-08-13,http://www.cnki.net/kcms/detail/11.5602.TP.20150813.1552.004.html
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology
1673-9418/2016/10(01)-0103-09
E-mail: fcst@vip.163.com
http://www.ceaj.org
Tel:+86-10-89056056
摘要:手机游戏提供商通过在游戏中销售虚拟道具来获得收益。将游戏玩家日志数据中每个事件描述为一个示例,玩家对多种游戏道具的购买状态表示为多个标记,从而将游戏道具推荐问题抽象为多示例多标记学习问题。在此基础上,将快速多示例多标记学习算法用于手机网络游戏道具推荐,并利用半监督学习提升推荐性能。离线数据集以及实际在线手机网络游戏实验结果表明,基于多示例多标记学习的游戏道具推荐技术带来了游戏营收的显著增长。
关键词:机器学习;多示例多标记学习(MIML);半监督学习;推荐
1 引言
网络游戏是随着电子计算机和互联网的发展与普及而进入人们日常生活中的一项廉价娱乐活动。网络游戏玩家通过输入输出设备在计算机模拟出的虚拟世界中与虚拟世界环境及其他玩家进行互动来获得休闲娱乐体验。玩家在游戏中不但能够通过被动接受满足画面、音乐、剧情等方面的感官需求,还能够主动参与互动,在虚拟世界中获得多种平时难以获得的体验。游戏总是以其独特的表现形式丰富着人们的内心世界,故也被认为是第九项艺术[1]。游戏的艺术性丰富了玩家的内心世界,而游戏的商业性则为游戏开发者带来收益。网络游戏的收费模式主要有两种:点卡收费和道具收费。点卡收费是传统的收费方式,按照玩家登录游戏的时长计费,时间越长费用越高。而道具收费是指玩家免费在游戏中进行基本娱乐活动,只有在需要增值服务道具时才进行付费。道具收费模式由于其“免费游戏,增值收费”的特点受到广大玩家的欢迎,因此也被绝大多数网络游戏所采用。随着手机等移动计算设备的普及,手机网络游戏也流行起来。由于移动互联网随时随地的特性,人们接触网络游戏的门槛大大降低,使得手机网络游戏玩家群体呈业余化趋势。业余玩家们不再投入大量时间成为游戏专家,因此需要更好地引导他们去体验网络游戏世界。手机网络游戏玩家群体的“业余化”特性是将推荐系统应用到游戏道具销售上的主要原因。
推荐系统是对于搜索引擎的补充。在这个信息过载时代,当信息消费者们无法用准确的关键字来描述自己的需求时,推荐系统可以自动为他们提供想要的信息。推荐系统如今已经广泛地应用在很多互联网产品中,如购物网站淘宝、亚马逊,社交网站Facebook,在线视频网站Netflix、YouTube、Hulu等。应用在这些互联网产品中的推荐系统大多采用了基于用户行为数据的协同过滤推荐算法。算法利用user-item矩阵中隐含的用户关联、物品关联以及用户物品关联这3类信息来进行推荐[2-3]。推荐系统的目标一般有两种:一种是给出用户对于物品的具体评分;另一种则只需对某个用户给出一个包含n个物品的推荐列表,即Top-n推荐。对于第一种推荐目标,评价准则一般采用均方根误差(root mean square error,RMSE),而对于Top-n推荐,评价准则主要采用准确率(precision)和召回率(recall)。这两种目标显然是不一致的,往往在Top-n推荐中采用一些简单的算法就能获得更好的效果,而无需采用要求给出具体评分的推荐算法[4]。基于物品或者基于用户的协同过滤算法是简单而有效的推荐算法[5-6]。而隐语义模型(latent factor model,LFM)类算法在利用user-item矩阵信息时,自然地假设存在“隐语义(latent factor)”,将user-item矩阵分解为user-latent矩阵和item-latent矩阵[7-8]。这样一来,用户和物品都可以与某个隐语义概念建立联系,认知心理学中的“典型性”概念可以为该假设提供一些理论依据[9]。当矩阵数据并不稀疏时,LFM的效果是非常好的。当矩阵数据比较稀疏时,将相似度矩阵分解为多个低秩矩阵的积往往可以获得很好的Top-n推荐效果[10-11]。
用户行为数据一般以日志形式存在,由一系列事件组成,每条事件记录一个用户行为。在利用用户行为数据进行物品推荐时,事件又可被分为显性事件与隐性事件。显性事件记录了用户的具体购买行为,直接反映用户对物品的喜好;而所有非显性事件都被归为隐性事件。
手机网络游戏中的玩家行为数据与一般互联网产品的用户行为数据相比,有以下3个特点:(1)玩家行为数据中包含大量事件上下文。普通互联网产品的事件一般仅包括用户ID、用户行为ID和时间戳等内容。网络游戏的事件不仅包含上述内容,还包括事件发生环境、前置事件、后续事件等事件上下文信息。(2)玩家行为数据中包含丰富的隐性事件。玩家在游戏虚拟世界中会留下大量与道具购买非直接相关的隐性事件记录。(3)玩家行为数据中游戏道具数量有限。一款互联网产品中物品数量成千上万,而一款网络游戏中的虚拟道具数量一般为几十或几百。
由于传统的协同过滤算法主要利用user-item矩阵进行推荐,将其应用在手机网络游戏道具推荐系统中会遇到以下两个问题:(1)user-item矩阵中没有事件上下文。一般为了能在推荐系统中利用事件上下文信息,只能通过人工添加相关的固定规则给推荐系统施加影响[5]。(2)user-item矩阵中不包含隐性事件信息。玩家只能通过显性事件信息来描述,而大量隐性事件信息无法得到利用。
多示例多标记学习(multi-instance multi-label learning,MIML)[12]是近年来提出的一种新型机器学习框架。在该框架中,一个对象用多个示例描述,对象可以同时拥有多个类别标记,如图1所示[13]。该框架对处理具有多义性的数据对象尤为适用,例如在图像标注任务中,图像的不同区域可以表示为不同的示例(即一个特征向量),一幅图像可以同时划归多个类别;在文本分类任务中,不同的章节、段落可以表示为不同的示例,一个文档可以同时属于多个类别。MIML已被成功应用于图像文本分类[13-14]、基因图像标注[15]、视频标注[16]、生态保护[17]等任务中。本文将游戏玩家日志数据中每个事件作为一个示例,玩家对于游戏道具的购买状态作为标记,从而用多示例多标记学习框架来描述手机网络游戏道具推荐问题。在此基础上,本文通过快速多示例多标记学习算法进行道具推荐,并加入半监督学习以获得更好的推荐性能。该算法不仅在离线数据集上进行实验,还在实际手机网络游戏中进行在线实验。两部分实验结果都表明基于多示例多标记学习的游戏道具推荐技术给游戏营收带来了显著增长。
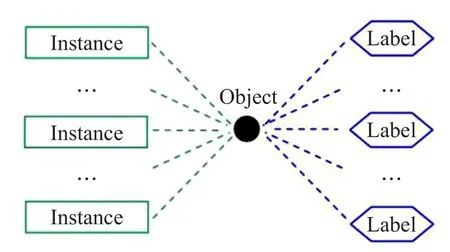
Fig.1 Multi-instance multi-label learning图1 多示例多标记学习
本文组织结构如下:第2章介绍手机游戏道具推荐任务,并将其抽象为MIML问题;第3章提出co-MIMLfast算法;第4章给出基准数据上的实验结果;第5章给出手机在线游戏实验结果;第6章是结束语。
2 任务描述
图2展示了游戏日志数据的产生过程。当ID为111的玩家在沙漠地图坐标为(12,14)的地点进行了一次攻击动作时,一条记录该事件的数据便被存入游戏日志中。

Fig.2 Generation of game log data图2 游戏日志数据的产生
显然该事件是一个隐性事件。该隐性事件仅仅描述了玩家进行的一次攻击动作,但它仍然可能隐藏了玩家对于某件游戏道具的偏好信息。例如,该游戏中有一件名为“诸葛神弩”的武器道具,只要购买了该道具,玩家就可以极大提高自己角色的战斗力,从而轻松击败很多强大敌人。当某玩家在游戏中对某个敌人进行了一次攻击动作,却只对敌人造成少量伤害时,该玩家就很有可能对“诸葛神弩”这件武器道具产生兴趣。从图3中可以看到,当“攻击”和“造成伤害”两个隐性事件连续发生时,由于造成伤害的值仅为5,于是这位ID为111的玩家就有可能为了提升自己攻击造成的伤害程度,想要购买“诸葛神弩”这件道具。当然,在实际玩家行为数据中包含了更多更复杂的隐性事件与游戏道具之间的关联。
游戏提供商只能从游戏日志数据中直接观察到某位玩家在某段时间内经历的事件,以及他购买的游戏道具信息,却难以观察到事件与道具购买状态之间的直接关联信息(当然一些显而易见的简单关联信息可以通过观察获得),即难以获知是哪些事件导致了玩家对某道具的购买。事件与道具购买状态之间的关联信息显然是构建道具推荐系统的基础。将每个事件作为一个示例,每个道具的购买状态作为一个类别标记,就可以用机器学习的方法来构建推荐系统。若用传统的单示例机器学习算法进行推荐,必须给每一个示例(事件)指定一个标记(道具购买状态)作为训练样本。这样获得的训练样本显然具有极大噪音,因为该标记(道具购买状态)很可能并非由该示例(事件)“触发”。然而,这个情景用MIML来描述却非常自然。用游戏日志数据中玩家经历的事件信息来构建“多示例”,而游戏日志数据中玩家的道具购买情况来构建“多标记”,则多示例多标记模型描述了一位经历了多个事件的玩家的所有道具购买状态。这样一来,尽管没有事件与道具购买状态之间的直接关联信息,也可以利用事件信息来给玩家进行道具推荐。
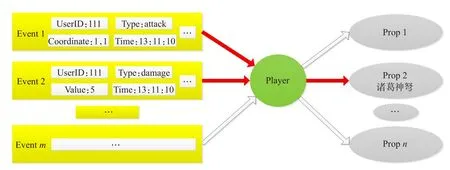
Fig.3 Relationship between latent events and props图3 隐性事件与道具的关联
3 解决方案
在手机网络游戏运营过程中,每位玩家每天都会产生大量日志数据。为了充分利用这些日志数据获得更好的推荐性能,用于游戏道具推荐的MIML算法需要能够进行快速处理。另一方面,手机网络游戏玩家群体中存在大量免费玩家,他们的行为数据显然没有标记。将这些数据的标记都当作负标记处理,就默认了这些玩家对于所有游戏道具都不感兴趣,很有可能给推荐模型的训练带来负面影响。而将这些数据的标记当作未标记处理,则有可能获得更好的效果。因此用于游戏道具推荐的MIML算法需要能够有效利用未标记样本。
为了满足快速计算和有效利用未标记样本的需求,给出co-MIMLfast算法。
算法1 co-MIMLfast算法
输入:标记数据L,未标记数据U,迭代轮数r。
训练:
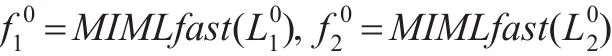
3. for i=1:r
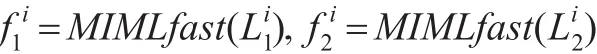
9. end for
测试:对于测试样本Xtest,它的标记是(Xtest)与(Xtest)的交集
算法1是MIMLfast算法[18]与协同训练(co-training)[19]的结合,两个基模型分别由MIMLfast算法学习获得,并在每一轮协同训练过程中交换各自的预测样本进行学习。MIMLfast算法满足计算速度快的要求,能够用于大规模数据,是目前最快速的MIML算法。而且MIMLfast的优化目标是最小化排序错误(ranking error),与Top-n推荐问题的目标非常贴近。协同训练是一种基于异议的半监督学习算法[20-21]。与产生式模型、S3VM(semi-supervised support vector machine)、图模型等几类半监督学习算法相比,它是一种“元学习算法”,可以与任何基学习模型进行结合,只需外加一个交互标记样本的过程即可进行半监督学习。本文已经确定使用MIMLfast算法进行MIML模型的训练,因此利用协同训练进行改造最为直接。
协同训练一开始应用于多视图的数据,后来被证明只要两个基分类器不同(掌握不同知识),就可以以未标记样本为载体来互相学习传递知识,并学习未标记的样本[19,22]。算法1中利用Bootstrap方法训练掌握不同知识的基分类器。另外,算子MIMLfast(⋅)指利用MIMLfast算法在训练集上训练MIML模型。下面简单介绍MIMLfast算法的训练过程。
MIMLfast算法为了在优化过程中利用不同标记之间的联系,先通过一个矩阵W0将原来的特征向量x映射到另一个空间里。这个空间对于各个标记是共享的,因而这个样本在标记l上的分类模型为:

由于W0和wl是通过交替优化进行的,不同标记之间的联系信息就可以通过W0保存下来。为了应对MIML模型通常面临复杂语义的情形,MIMLfast为每个标记l设计了子概念类。以标记“苹果”为例,拥有这个标记的对象既有可能是一个水果,也有可能是一部手机,那么描述这两种对象的特征向量可能就差别很大。子概念类的设计能够让示例与标记更好地拟合。令每个标记的子概念类数目为K,则有:
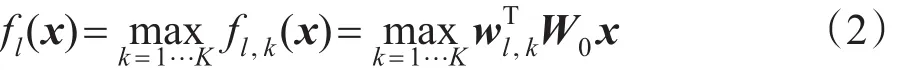
其中,wl,k对应了标记l的第k个子概念类的模型。在拥有了示例层面的模型后,需要建立以包为输入的模型。MIMLfast中采用取最大值的方法定义包在标记l上的模型为:

有了对于包X在标记l上的模型,则定义这个模型的优化目标排序错误ε如下:
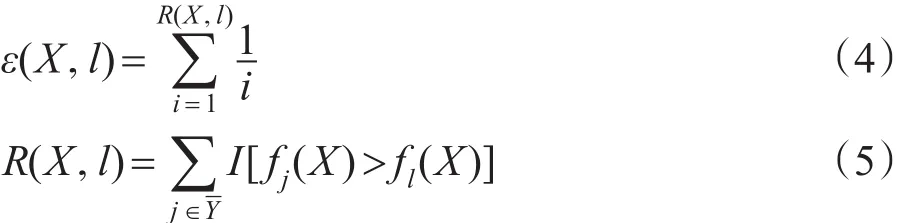
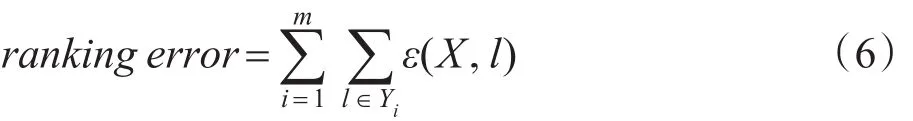
只要最小化ranking error,就能获得一个好的多示例多标记推荐模型。对于这个非凸优化问题的求解,MIMLfast还采用了一些特别的优化技巧,详情请参见文献[18]。
4 基准测试
基准测试在常用的MIML数据集上进行,包括Letter Carroll[17]、Letter Frost[17]、MSRC V2[23]、Reuters[14]、Bird Song[17]和Scene[13],它们的基本信息见表1。
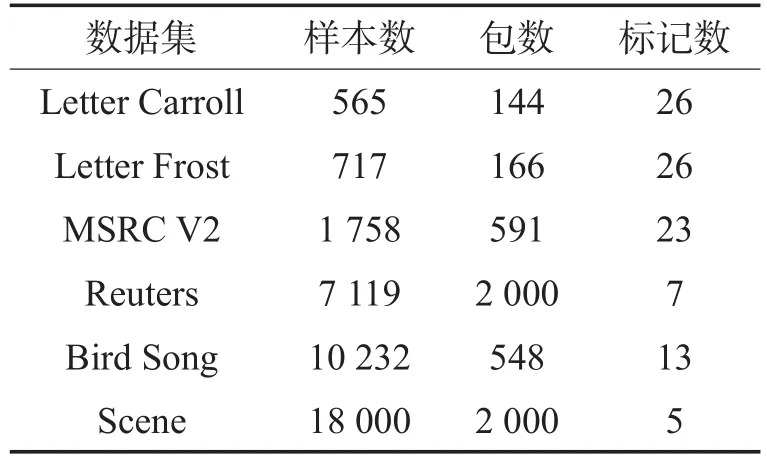
Table 1 Popular MIML data sets表1 常用的MIML数据集
该实验主要用于验证co-MIMLfast算法的有效性。对于每个数据集,每次随机选取其中9/10的数据作为训练数据,其余1/10的数据作为测试数据,协同训练的迭代轮数r=5。最终的实验结果是重复随机选取30次后的平均结果。实验中标记数据与未标记数据的比例为2∶1。实验结果采用MIML中常用的5个评价准则,分别是Hamming Loss、One-Error、Coverage、Ranking Loss和Average Precision,其定义请参见文献[24]。需要说明的是,为了实验结果更加直观,对表中的覆盖率进行了归一化处理。除了基本的MIMLfast算法,MIMLfast with self-training算法也被用来进行对比。Self-training作为一种最简单的半监督学习算法,是一个很好的对比参照。
从表2中可以看出,co-MIMLfast的实验结果在6个常用MIML数据集上相比MIMLfast的结果都有大幅提升(加粗数据表示,根据显著水平为0.05的成对双侧t检验,相对于MIMLfast的性能提升具有显著性),显示出半监督学习的有效性。当然,两个分类器的集成也给实验效果的提升带来了不少帮助。另外,One-Error和Ranking Loss是需要重点关注的评价指标。因为在Top-n推荐问题中,Ranking Loss直接反映了模型的好坏,而One-Error恰好是Top-1推荐的错误率。在这两个评价指标上,co-MIMLfast显著地提高了模型性能。
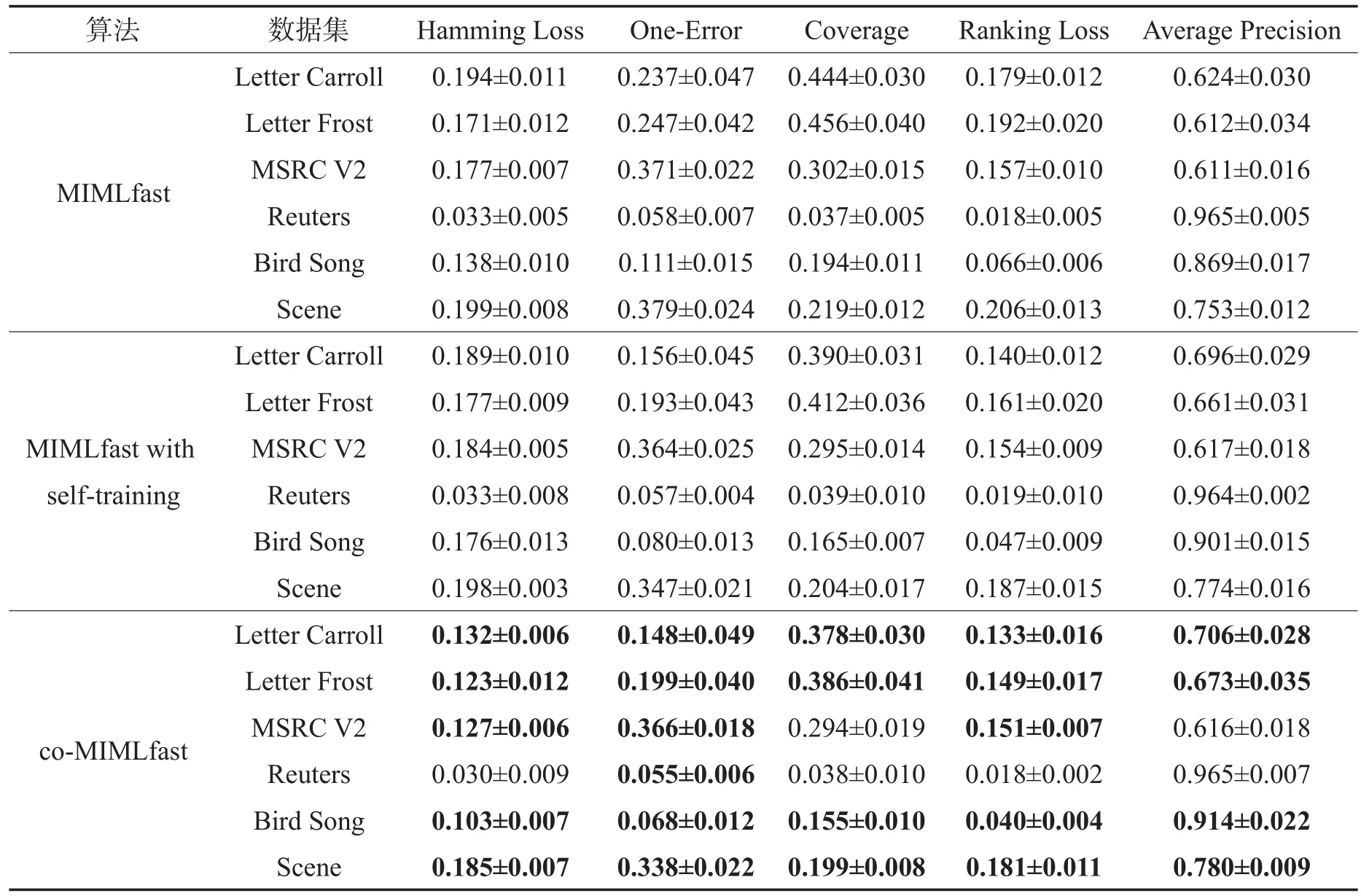
Table 2 Benchmark test results表2 基准测试结果
5 手机网络游戏实验
真实游戏数据实验首先在3个手机网络游戏的离线数据集上,对比co-MIMLfast算法与各种常用协同过滤算法的推荐效果。数据集的基本信息见表3。
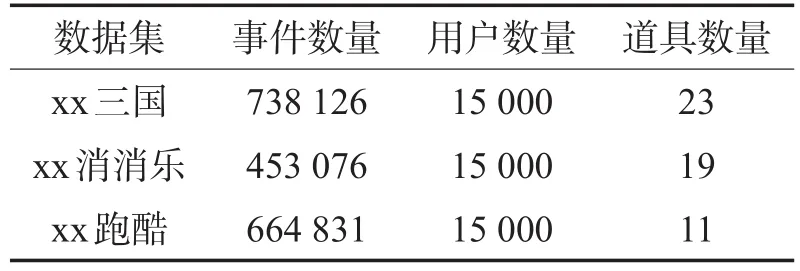
Table 3 Online game data sets表3 网络游戏数据集
与基准测试部分一样,对于每个数据集,每次随机选取其中9/10的标记数据作为训练数据,其余1/10的标记数据作为测试数据,协同训练的迭代轮数r=5。标记数据占整个数据集的2/3,剩下的未标记数据只在co-MIMLfast算法中才会利用到。最终的实验结果是重复随机选取30次后的平均结果。这里使用的评价准则很简单,就是与网络游戏道具推荐系统产品收益直接相关联的Top-n推荐准确率。推荐算法方面,常用的随机推荐(Random)、最热门推荐(Most-popular)、基于用户的协同过滤(User-CF)、基于物品的协同过滤(Item-CF)和隐语义模型(LFM)都被用来与co-MIMLfast进行对比。其中,LFM是目前在非稀疏数据集上表现最好的推荐算法,而User-CF 与Item-CF也因为其简单有效的特性被应用在很多互联网产品中。关于这些算法的详情,请参见文献[2]。需要特别指出的是,无论是各种协同过滤算法还是co-MIMLfast算法,在实现时有非常多的具体细节可以修改或添加,这些固定规则的改动有可能大大影响算法在某些具体数据集上的表现。本文只考虑它们的基本算法。从表4中可以看出,co-MIMLfast算法在3个手机网络游戏数据集合上都表现出了比较明显的优势。这得益于它利用了更多的数据来训练模型:更多的事件上下文信息、更多的隐性事件信息以及更多的未标记信息。更多的事件上下文和隐性事件信息可以让用户相似度矩阵的构建更为精准,而未标记信息则使得对于用户分布的估计更为准确。
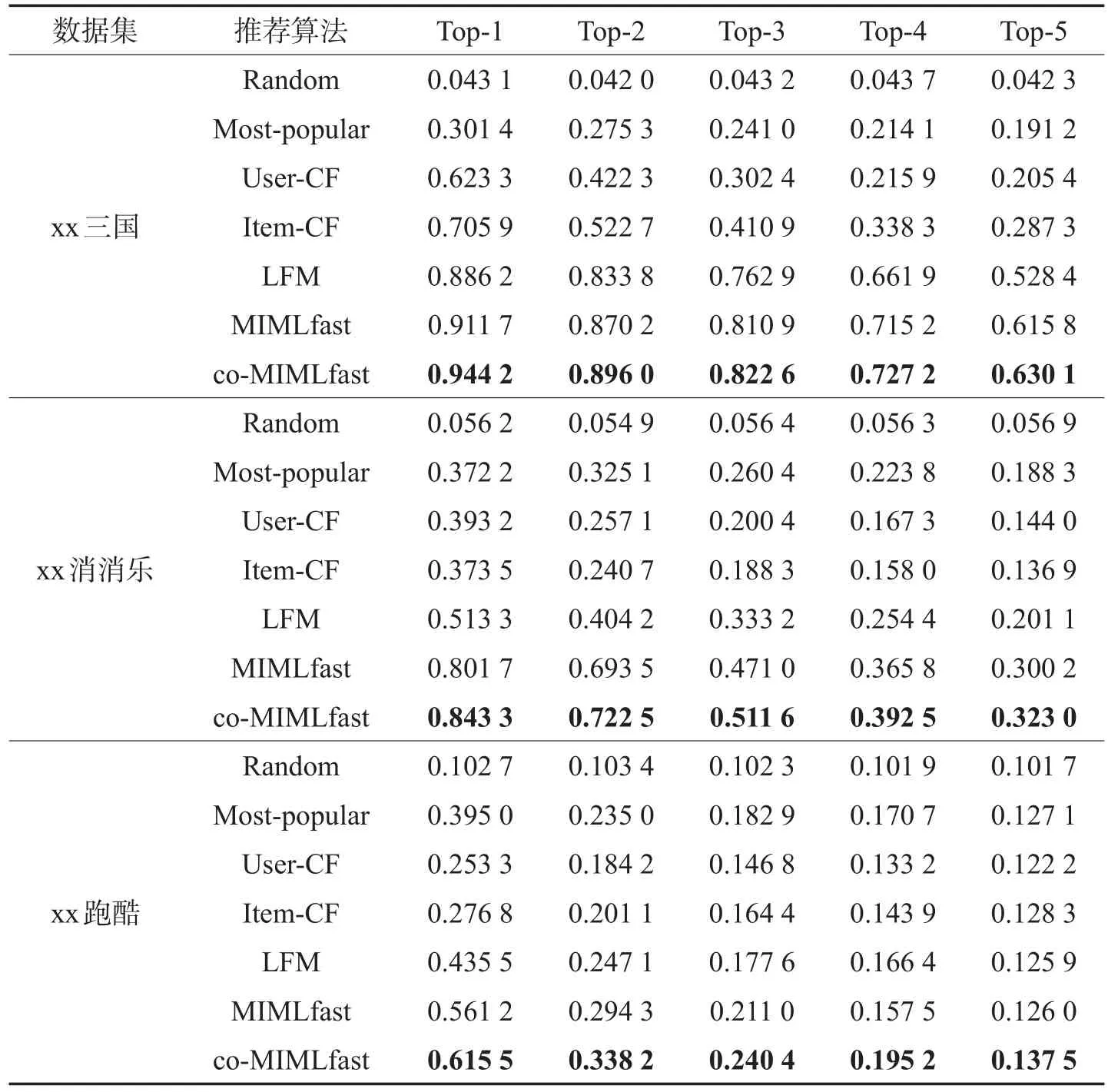
Table 4 Precision of Top-n recommendation on game data sets表4 离线游戏数据集上Top-n推荐准确率
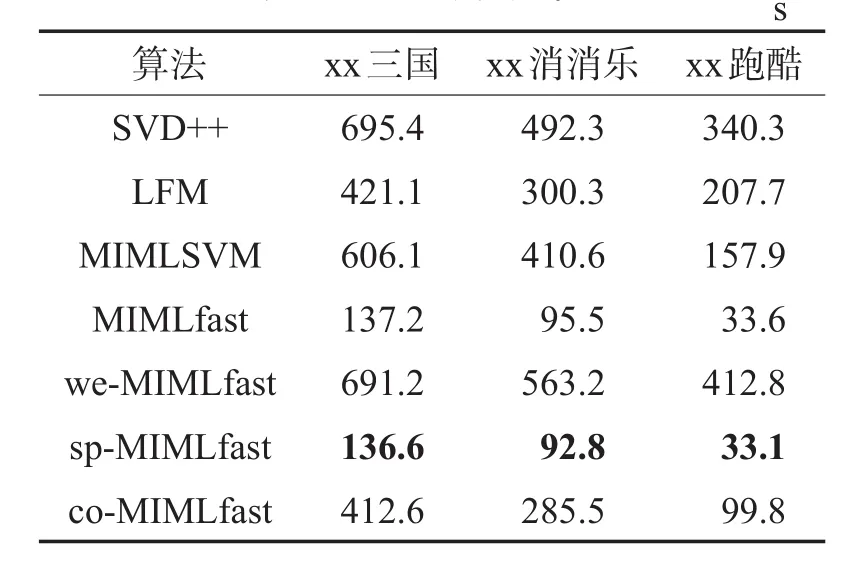
Table 5 Time cost of model training表5 模型训练时间
表5给出了几种算法的模型训练时间对比。从表中可以看出快速多示例多标记学习算法在学习效率上的优势。
最后,选取在离线数据实验中表现较好的LFM 和co-MIMLfast两种算法进行线上A/B测试。A/B测试是指将用户随机分为数量相等的两组,分别使用两种产品,通过比较两种产品的转化率来获悉哪个产品更好。该测试在苏州某公司开发运营的手机网络游戏“xx三国”的道具推荐系统中进行,于2014年12月1日上线,测试周期为一个月。该游戏道具推荐系统是简单的Top-1推荐。A/B测试中,根据玩家ID的奇偶性将玩家分为两组。一组玩家通过LFM模型进行推荐,另一组则通过co-MIMLfast模型进行推荐。表6展示了10月至12月连续3个月该游戏的运营统计数据。其中,“付费确认框弹出”指玩家在游戏道具商店中选择想要购买的道具后弹出的“请确认将从您的手机话费中支付xx元购买xx游戏道具”确认提示框,而“付费成功”指玩家在上述提示框中点击了确定按钮。可以看到,10月至11月游戏的用户增长率与收入增长率分别是15.98%与16.02%,两者基本一致。而11月至12月游戏的用户增长率与收入增长率分别是16.70%与23.28%,收入增长率出现了较大的提升。因此,计算每用户平均收入可知,道具推荐系统给这款游戏带来了5.7%的营收增长。
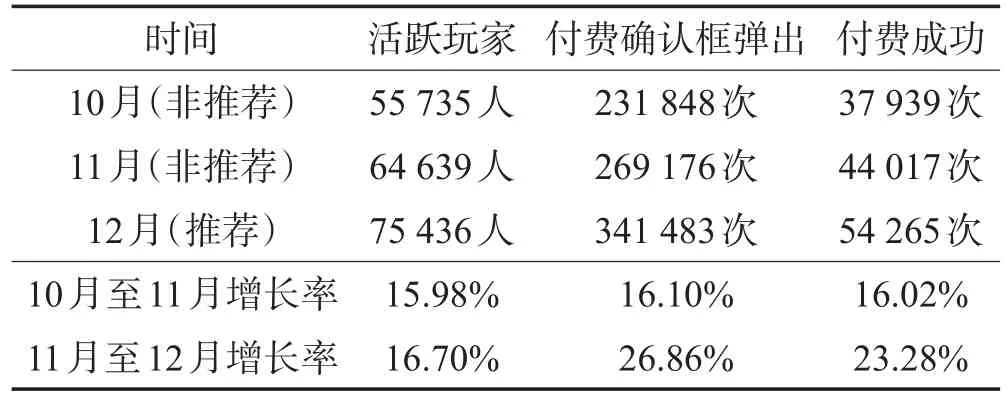
Table 6 Statistics of the“xx Three Kingdoms”表6 “xx三国”运营数据统计

Table 7 Results of A/B test表7 A/B测试结果
表7给出了A/B测试的结果,其中转化率等于付费成功次数除以付费确认框弹出次数。co-MIMLfast 在A/B测试中胜出,与线下离线实验的实验结果一致,表现出在网络游戏道具推荐上的优势。
6 结束语
手机网络游戏中的玩家行为数据具有上下文信息丰富,隐性事件信息丰富等特点。本文的主要贡献是将多示例多标记学习(MIML)框架用于描述手机网络游戏道具推荐问题,并在实际游戏上线运营中测试了MIML在手机游戏道具推荐中的性能。本文设计的算法虽然并不复杂,但在离线测试和实际上线运营中都取得了很好的效果,显示出MIML这一新型机器学习框架的巨大潜力。未来工作中将尝试把MIML技术应用到更多手机网络游戏的道具推荐中,并利用MIML的关键示例检测机制[25]来发现触发道具购买的具体事件,从而设计出更好的运营策略。
References:
[1] Liu Jin. Video game is the ninth art[EB/OL].(2012-08-27)[2015-03-13]. http://www.cflac.org.cn/ys/xwy/201208/t20120827_ 146180.html.
[2] Ricci F,Rokach L,Shapira B,et al. Recommender systems handbook[M]. New York: Springer-Verlag,2011.
[3] Breese J S,Heckerman D,Kadie C. Empirical analysis of predictive algorithms for collaborative filtering[C]//Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence,Madison,USA,1998. San Francisco,USA: Morgan Kaufmann Publishers Inc,1998: 43-52.
[4] Cremonesi P,Koren Y,Turrin R. Performance of recommender algorithms on top-n recommendation tasks[C]// Proceedings of the 4th ACM Conference on Recommender Systems,Barcelona,Spain,2010. New York,USA: ACM,2010: 39-46.
[5] Herlocker J L,Konstan J,Borchers A,et al. An algorithmic framework for performing collaborative filtering[C]//Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,Berkeley,USA,1999. New York,USA:ACM,1999: 230-237.
[6] Sarwar B,Karypis G,Konstan J,et al. Item-based collaborative filtering recommendation algorithms[C]//Proceedings of the 10th International World Wide Web Conference,Hong Kong,China,2001. New York,USA:ACM,2001: 285-295.
[7] Chen C,Zheng L,Thomo A,et al. Comparing the staples in latent factor models for recommender systems[C]//Proceedings of the 29th Annual ACM Symposium on Applied Computing,Gyeongju,Korea,2014. New York,USA:ACM,2014: 91-96.
[8] Hofmann T. Latent semantic models for collaborative filtering[J]. ACM Transactions on Information Systems,2004,22(1): 89-115.
[9] Cai Yi,Leung H,Li Qing,et al. Typicality-based collaborative filtering recommendation[J]. IEEE Transactions on Knowledge and Data Engineering,2014,26(3): 766-779.
[10] Kabbur S,Ning X,Karypis G. FISM: factored item similarity models for top-n recommender systems[C]//Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Chicago,USA,2013. New York,USA:ACM,2013: 659-667.
[11] Zheng Xiaodong,Ding Hao,Mamitsuka H,et al. Collaborative matrix factorization with multiple similarities for predicting drug-target interactions[C]//Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Chicago,USA,2013. New York,USA:ACM,2013: 1025-1033.
[12] Zhou Zhihua,Zhang Minling,Huang Shengjun,et al. Multiinstance multi-label learning[J]. Artificial Intelligence,2012,176(1): 2291-2320.
[13] Zhou Zhihua,Zhang Minling. Multi-instance multi-label learning with application to scene classification[C]//Advances in Neural Information Processing Systems 19: Proceedings of the 20th Annual Conference on Neural Information Processing Systems,Vancouver,Canada,Dec 4-7,2006. Cambridge,USA: MIT Press,2006: 1609-1616.
[14] Sebastiani F. Machine learning in automated text categorization[J].ACM Computing Surveys,2002,34(1): 1-47.
[15] Li Yingxin,Ji Shuiwang,Kumar S,et al. Drosophila gene expression pattern annotation through multi-instance multilabel learning[J]. IEEE/ACM Transactions on Computational Biology and Bioinformatics,2011,9(1): 98-112.
[16] Xu Xinshun,Jiang Yuan,Xue Xiangyang,et al. Semi-supervised multi-instance multi-label learning for video annotation task[C]// Proceedings of the 20th ACM International Conference on Multimedia,Nara,Japan,2012. New York,USA:ACM,2012: 737-740.
[17] Briggs F,Fern X,Raich R. Rank-loss support instance machines for MIML instance annotation[C]//Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Beijing,China,2012. New York,USA:ACM,2012: 534-542.
[18] Huang Shengjun,Zhou Zhihua. Fast multi-instance multi-label learning[C]//Proceedings of the 28th AAAI Conference on Artificial Intelligence,Quebec City,Canada,2014. Menlo Park,USA:AAAI,2014: 1868-1874.
[19] Wang Wei,Zhou Zhihua. Analyzing co-training style algorithms[C]//LNCS 4701: Proceedings of the 18th European Conference on Machine Learning,Warsaw,Poland,Sep 17-21,2007. Berlin,Heidelberg: Springer,2007: 454-465.
[20] Zhu Xiaojin. Semi-supervised learning literature survey,TR 1530[R]. Computer Sciences,University of Wisconsin-Madison,2006.
[21] Pise N N,Kulkarni P. A survey of semi-supervised learning methods[C]//Proceedings of the 4th International Conference on Computational Intelligence and Security,Suzhou,China,Dec 13-17,2008. Piscataway,USA: IEEE,2008: 30-34.
[22] Zhou Zhihua,Li Ming. Semi-supervised learning by disagreement[J]. Knowledge and Information Systems,2010,24(3): 415-439.
[23] Winn J,Criminisi A,Minka T. Object categorization by learned universal visual dictionary[C]//Proceedings of the 10th IEEE International Conference on Computer Vision,Beijing,China,2005.Piscataway,USA:IEEE,2005:1800-1807.
[24] Schapire R E,Singer Y. BoosTexter: a boosting-based system for text categorization[J]. Machine Learning,2000,39(2/3): 135-168.
[25] Li Yufeng,Hu Juhua,Jiang Yuan,et al. Towards discovering what patterns trigger what labels[C]//Proceedings of the 26th AAAI Conference on Artificial Intelligence,Toronto,Canada,2012. Menlo Park,USA:AAAI,2012: 1012-1018.
附中文参考文献:
[1]刘瑾.电子游戏的第九艺术之说[EB/OL].(2012-08-27)[2015-03-13]. http://www.cflac.org.cn/ys/xwy/201208/t20120827_ 146180.html.

TANG Jun was born in 1990. He is an M.S. candidate at Nanjing University. His research interests include machine learning,data mining and phone game,etc.
唐俊(1990—),男,南京大学硕士研究生,主要研究领域为机器学习,数据挖掘,手机游戏等。

ZHOU Zhihua was born in 1973. He is a professor and Ph.D. supervisor at Nanjing University,ACM distinguished scientist,IEEE fellow and CCF fellow. His research interests include artificial intelligence,machine learning and data mining,etc.
周志华(1973—),男,南京大学教授、博士生导师,ACM杰出科学家,IEEE会士,CCF会士,主要研究领域为人工智能,机器学习,数据挖掘等。
Mobile Phone Game Props Recommendation Based on Multi-Instance Multi-Label Learning*
TANG Jun1,2,ZHOU Zhihua1,2+
1. National Key Laboratory for Novel Software Technology,Nanjing University,Nanjing 210023,China
2. Collaborative Innovation Center of Novel Software Technology and Industrialization,Nanjing 210023,China
Abstract:Mobile phone game providers gain profits by selling virtual props in games. This paper describes an event in game log data of players as an instance and represents the states of players’prop purchases by labels,so that the game props recommendation is modeled as multi-instance multi-label learning(MIML)problem. On the basis of this abstraction,an MIMLfast algorithm is used to recommend mobile phone game props and a semi-supervised learning part is integrated to improve the performance of recommendation. The results of experiments conducted on offline data sets and a real mobile phone game show that the MIML-based game props recommendation brings a remarkable increase of game profits.
Key words:machine learning; multi-instance multi-label learning(MIML); semi-supervised learning; recommendation
文献标志码:A
中图分类号:TP301
Corresponding author:+ E-mail: zhouzh@lamda.nju.edu.cn
TANG Jun,ZHOU Zhihua. Mobile phone game props recommendation based on multi-instance multi-label learning. Journal of Frontiers of Computer Science and Technology,2016,10(1):103-111.
doi:10.3778/j.issn.1673-9418.1505055
猜你喜欢
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
活力(2016年8期)2016-11-12
科学与财富(2016年28期)2016-10-14
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年12期)2016-06-14
科教导刊·电子版(2016年10期)2016-06-02
科教导刊·电子版(2016年10期)2016-06-02
电脑知识与技术(2016年3期)2016-04-07
