
基于市场匹配的多Agent智能爬虫系统
2016-03-17 09:35杜亚军
西华大学学报(自然科学版) 2016年1期
刘 佳,杜亚军
(西华大学计算机与软件工程学院,四川 成都 610039)
基于市场匹配的多Agent智能爬虫系统
刘佳,杜亚军*
(西华大学计算机与软件工程学院,四川 成都 610039)
摘要:在网络文字、图像视频、音频数量日益增长的网络世界中,网络爬虫爬取结果变得越来越差,主要表现在爬取网页的精确率低、召回率低和重复率高等方面。为解决这些问题,结合市场匹配基本原理和网络爬虫的特点,提出一种基于市场匹配算法的多Agent智能爬虫系统。基于市场匹配算法,设计了多Agent智能爬虫系统,以雅虎一级目录12个主题为测试数据对网络爬虫爬取网页的精确率、召回率和重复率进行了分析。结果表明,与未使用市场匹配算法的系统相比较,基于市场匹配算法的多Agent智能爬虫系统的精确率提高了9%、召回率提高了8%、重复率降低了5%,其爬虫性能有较大改善。
关键词:市场匹配算法;多Agent;智能爬虫
随着因特网的快速发展,网络世界里的网络文字、图像视频、音频数量日益增长,导致网络爬虫爬取网页信息的结果越来越差。人们结合分布式网络爬虫中包含多个爬虫且多个爬虫能共同工作的特点提出了多Agent网络爬虫系统,使多个网络爬虫可以根据相同的关键词同时爬取网页[1-4];然而,这导致了网络爬虫在爬取网页时重复爬取网页问题的出现。本文在多Agent网络爬虫系统的基础上,把市场匹配算法应用到多Agent网络爬虫系统中,提出了基于市场匹配的多Agent智能爬虫系统,使多个网络爬虫能够竞争和协作。实验表明,基于市场匹配算法的多Agent智能爬虫系统中的多个爬虫能够相互竞争和协作,且在爬虫的性能上有较大的改善。
1多Agent市场匹配算法
1.1 多Agent协作与竞争模型
在多Agent爬虫系统中,当一些Agent爬虫需要协作完成任务时,它们会将自己的待爬行URLs进行拍卖,其他有能力的Agent通过竞争来购买一些URLs,增加能力值。令被拍卖的URLs集合为SA={S1,S2,…,Sn},购买的Agent爬虫为BA={B1,B2,…,Bm}。这一拍卖过程可以形式化为二分图。设GA=(SA,BA,EA)是一个无向图,其中EA={(Si,Bj),Si∈SA,Bj∈BA},代表边集,连接卖家和买家。如图1所示,在多Agent爬虫系统中,被拍卖的URLs为一个卖家Sp,Sp∈SA,而通过竞争来购买URLs的爬虫为买家Bq,Bq∈BA。边Eqp=(Sp,Bq)表示买家Bq购买Sp。
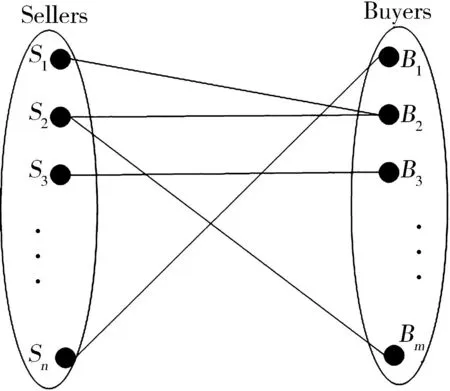
图1 二分图GA
1.2 估值
当进行拍卖匹配时,卖家集合SA中的每个卖家需要对自己有个估值,即为每个卖家的初始估值,初始估值一般为0,而买家集合BA中的每个买家需要对卖家集合SA中的每个卖家Sp(Sp∈SA)都有一个固定不变的估值[5],如图2所示。这些估值是用于在匹配时判断此匹配是否达到最优匹配的标准。
图2 估值图
1.3 最优分配
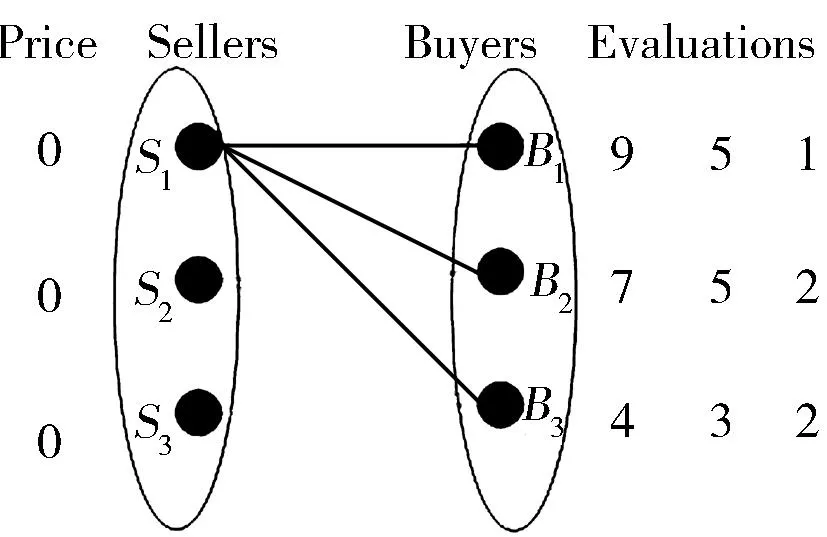
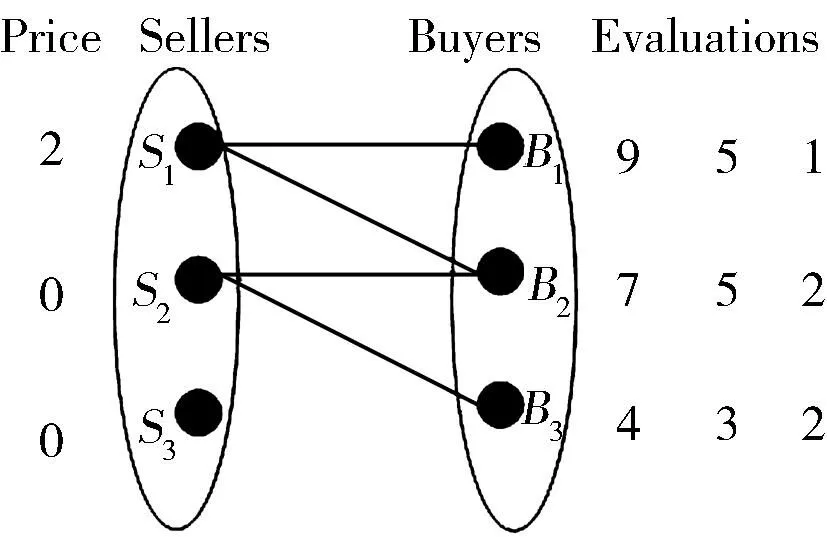
为寻求尽可能高的分配方案质量,即最优分配,文献[5]提出一个合理分配卖家和买家的方法。该方法使每个卖家和买家的满意程度总体达到最高。根据图2给出的一组估值,可以得到此图的最优分配[5],其最优分配的过程如图3所示。在达到最优匹配的二分图中,所有匹配结果如表1所示。从表1可以看出,编号1的匹配结果达到最优匹配,所得到的利益值是最大的,最大利益为6+4+2=12。表中Bq->SP:代表买家q购买卖家p。

编号匹配结果收益1B1->S1,B2->S2,B3->S36+4+2=122B1->S1,B2->S3,B3->S26+2+2=103B1->S2,B2->S1,B3->S34+4+-1=74B1->S2,B2->S3,B3->S14+2+1=75B1->S3,B2->S1,B3->S21+4+2=76B1->S3,B2->S2,B3->S11+4+1=6
图3示出了以图2为初始模型的市场匹配过程。在进行4轮匹配后,此时已经出现了1组最优匹配,即B1->S1,B2->S2,B3->S3,达到此最优匹配的最大利益,为(9-3)+(5-1)+(2-0)=6+4+2=12。
市场匹配算法是求得一组卖家和买家的最优匹配。文献[5]提出了一组市场清仓价格及其对应的卖家图中的最优匹配,能产生卖家和买家回报总和的最大可能值,对于任何一组市场清仓价格,卖家图中的一个最优匹配是使估值总和在所有买家和卖家的配对中达到最高。
2多Agent智能爬虫系统
多Agent智能爬虫系统主要有4个模块组成,分别是爬取种子集模块、爬取网页模块[11-12]、匹配网页模块和统计存储实验数据模块。此系统的总体结构是根据爬虫爬取网页的整个过程(从开始爬取到结束爬取来进行)设计的。系统流程图如图4所示。程序中有HostAgent、AsAgent和CAgent。
HostAgent为用于管理N个爬虫的代理。AsAgent_n、CAgent_n分别是同一个爬虫的不同代理,AsAgent_n用于该爬虫进行交互(协作和竞争),CAgent_n用于该爬虫爬取网页。在市场匹配算法的买卖双方中, AsAgent_n表示该爬虫进行匹配,CAgent_n不参与。一个AsAgent_n对应一个CAgent_n,它们是相互对应的,代表同一个爬虫。
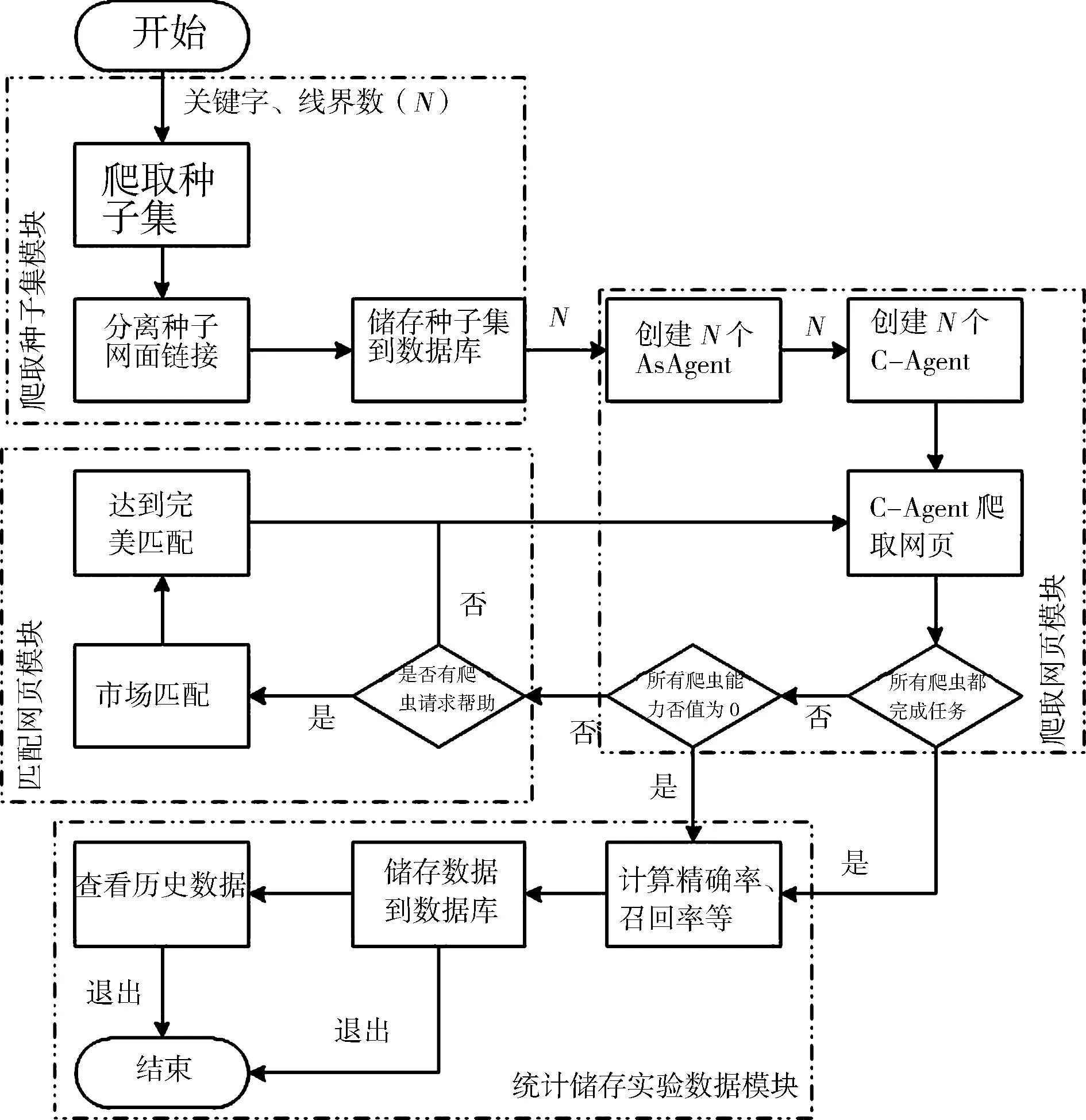
图4 系统流程图
2.1 爬取种子集模块
爬取种子集模块主要是系统在使用N(N≤20)个爬虫爬取网页前,需要给每个爬虫分别设置一个初始种子集,以达到同时爬取需要的网页,提高效率的目的。这部分的设计思想是先利用用户输入的关键词和线程个数,即爬虫个数来爬取相关网页,然后再利用正则表达式的技术来分离出每个网页中的统一资源定位符,最后创建出相应个数的C-Agent来爬取分离出的链接。
2.2 爬取网页模块
爬取网页模块是在爬取种子集模块的基础上,利用系统创建的N(N≤20)个爬虫爬取相关的网页。当爬虫爬取到相关的链接时,它会检测是否是需要的网页,如果不是,则自动跳过,如果是,系统会爬取此条链接,并显示在系统面板search path tree中,如图5所示,然后再把此条链接的网页下载到本地存储。系统每隔一段时间就会检测每个爬虫的爬取情况,并根据每个爬虫的网页爬取情况来进行操作。
图5 爬虫爬取网页图
2.3 匹配网页模块
匹配网页模块是多Agent智能爬虫系统中的核心算法模块。系统在此模块构建了基于匹配网页和网络爬虫的二分图模型。当爬虫还有未爬取的链接时,它会把未爬取的链接根据其相似度定一个初始价格,然后向其他爬虫进行拍卖。系统中成功完成爬取任务的爬虫,如果它还有能力,它会购买一些链接,但不是一直都在进行链接拍卖和购买的过程。系统中有一个时间间隔,每段时间系统将会检测每个爬虫的剩余能力值、是否达到下载网页的目标值等信息,如果达到拍卖的条件,如有大于等于1个网页进行拍卖且大于等于1个爬虫能够购买网页,此时将会进行网页的拍卖和购买。系统会利用市场匹配算法进行匹配网络爬虫和网页,使利益达到最大。
在利用市场匹配算法进行匹配网络爬虫和网页时,每个AsAgent根据网页的相似度来对每个链接进行估值,并且AsAgent用其下标代替。此算法只讨论AsAgent和链接个数相等的情况。如果AsAgent的个数大于链接个数,则选取剩余能力值大的AsAgent进行匹配;如果AsAgent的个数小于链接个数,则表明需要帮助的链接大于爬虫个数,去掉多余的链接[6-10]。算法伪代码如下所示。
Input:N个提供帮助的AsAgent_[0..n];需要帮助的urls;网页价格增长值price。
Output:匹配完成的urls
Begin
001 Evaluation[1..maxn]//爬虫对网页的估值
002 Price[1..maxn]//网页的价格
003 Connection[1..maxn,1..maxm]//连线
004 function Distribute(agent,urls) //匹配函数
005 gn=agent.length;gm=urls.size();
006 gn=gm=min(gn,gm);
007 beforePrice=(SSPandSBP.SBP(urls);
008 sort(beforePrice);
009 while(NotOver)//拍卖过程
010Connection=0;//初始没有连线
011Evaluation=beforePrice[n++];
012fori=0 to n do//选取收益最大的网页
013max=Evaluation[i][0]-Price[0];
014max1=i:int;max2=0;
015for j=1 to n do
016if(max<(Evaluation[i][j]-Price[j]))
017then max=Evaluation[i][j]-Price[j];
max2=j;
018end if;
019end for;
020for k2=0 to gm do //连线
021if max==Evaluation[i][k2]-Price[k2]
022do Connection[i][k2]=1;
023end if;
024end for;
025for i2=0 to gn //验证是否达到完美匹配
026for j2=0 to gm
027if Connection[i2][j2]==1 do
028Perfect[j2]=1; line[j2]++;
029end if
030end for
031end for
032if Dvalue==gndo
033NotOver=false;
034else do//未达到最优匹配
035被多条线连接的网页增加价格;
036end if;
037end for;
038 end while;//匹配完成
039 if(Connection[i][j]=1)then //存储结果
040 urls.get(j).setDistinguishAsAgent(i);
041 end if;
042 return urls;//返回结果
End
2.4 统计存储实验数据模块
统计存储实验数据模块是在用户点击search stop按钮或者爬虫存活时间完毕后,系统根据相应的链接访问数、网页下载数等实验数据计算此次系统爬取网页的准确率、召回率和重复率。系统完成计算后,会把相应的计算信息显示在面板statistics results中,然后再把这些数据存储到数据库中去。
3实验结果分析
为验证基于市场匹配算法的多Agent智能爬虫系统的性能,本文以雅虎一级目录中12个主题,如表2所示,作为测试数据进行测试,并得到了爬虫的相关指数,如表3、表4所示。在用雅虎一级目录中的12个主题分别测试时,界面中的参数设置如下:keyword每次在雅虎12个主题中分别取5个关键词;C-Agent的最大存活时间为系统默认值600,单位为s;C-Agent的个数为系统默认值5;关键词的理解度为系统默认值0.2;时间间隔也为系统默认值120。参数α和参数β为系统默认值,分别为5和5.0。参数δ1、参数δ2、参数δ3和参数δ4也为系统默认值,分别为0.5、0.10、10 s和50 kb。每次实验时间是300 s,即5min。参数α为每个爬虫爬取网页的目标值;参数β为每个爬虫(CAgent)初始的能力值;参数δ1为爬虫每爬取一个网页消耗的能力值;每进行一次匹配后,若没有达到最优匹配且有多个爬虫欲购买此网页,则此网页会增加价格,增加的价格值为参数δ2;参数δ3为成功购买网页的爬虫每次奖励的时间值;参数δ4为成功购买网页的爬虫每次奖励的空间值。
以下表中各数据英文简写分别为: VC,网页数量;CC,主题相关访问数量;CR,精确率,CR=CC/VC; DTOC,下载到本地的网页数量;RCR,召回率,RCR=DTOC/VC;RC,重复下载的网页数量;RR,重复率,RR=RC/VC。文中,A、B和Tn代表的意义分别为:A表示使用市场匹配算法; B表示没有使用市场匹配算法;Tn表示第n个主题,如T1表示第1个主题news。

表2 雅虎一级目录12个主题表
在实验中,每个主题分别取了5个关键词进行实验,得到了每个关键词的准确率、召回率和重复率等实验数据。表3和表4分别列出了主题T1、T4和T11中的5个关键词的实验数据。其中,表3的实验数据是在使用市场匹配算法情况下进行实验得到的,表4的实验数据是在没有使用市场匹配算法情况下进行实验得到的。准确率、召回率和重复率都精确到小数点后2位。VC和VUC值相等,但表达的意义不一样。因召回率的需要(召回率是用下载到本地的网页数量/本该下载到本地的网页数量),在这里把访问网页数量VC当作本该下载到本地的网页数量。
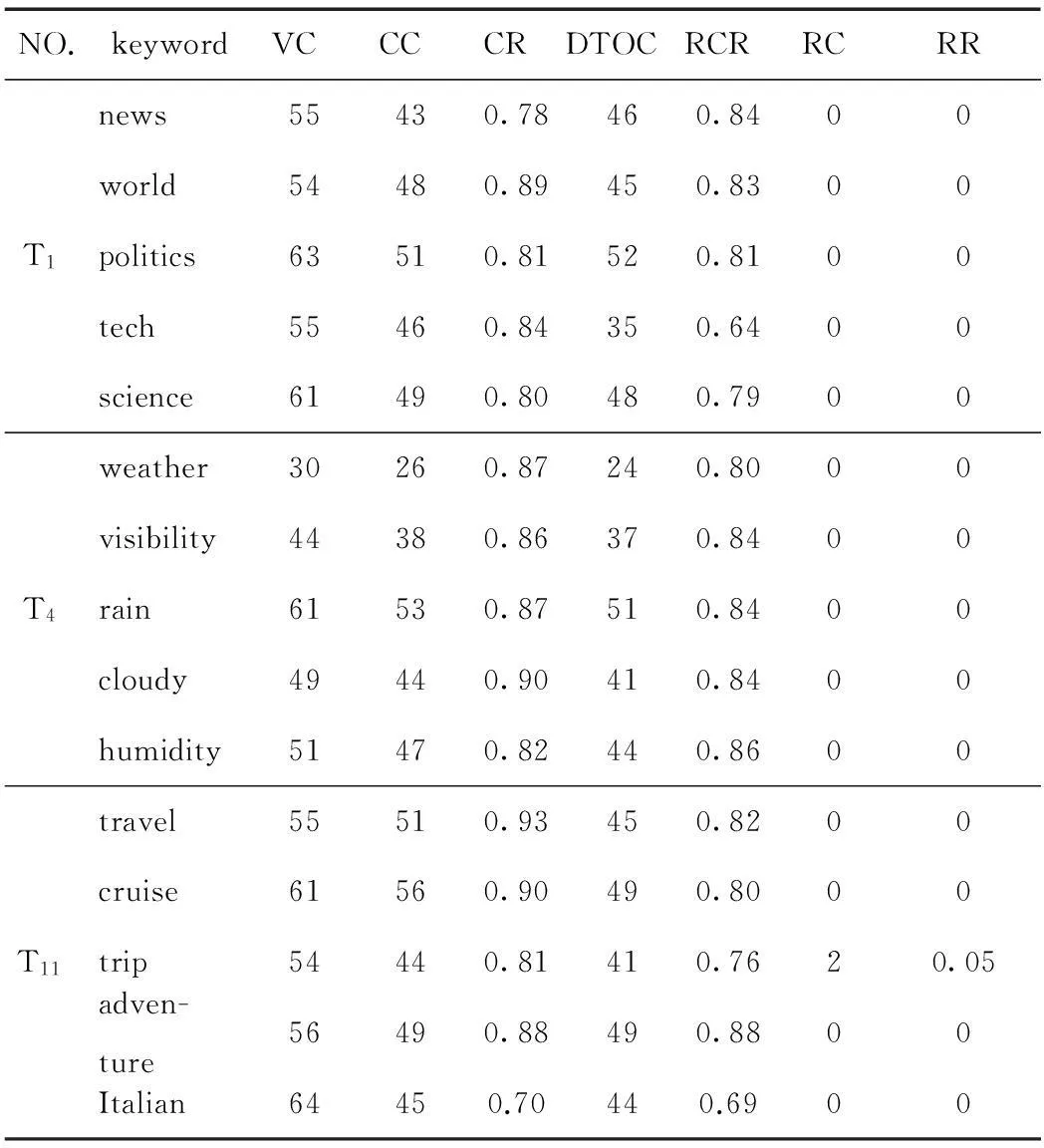
表3 雅虎一级目录实验数据表(A)
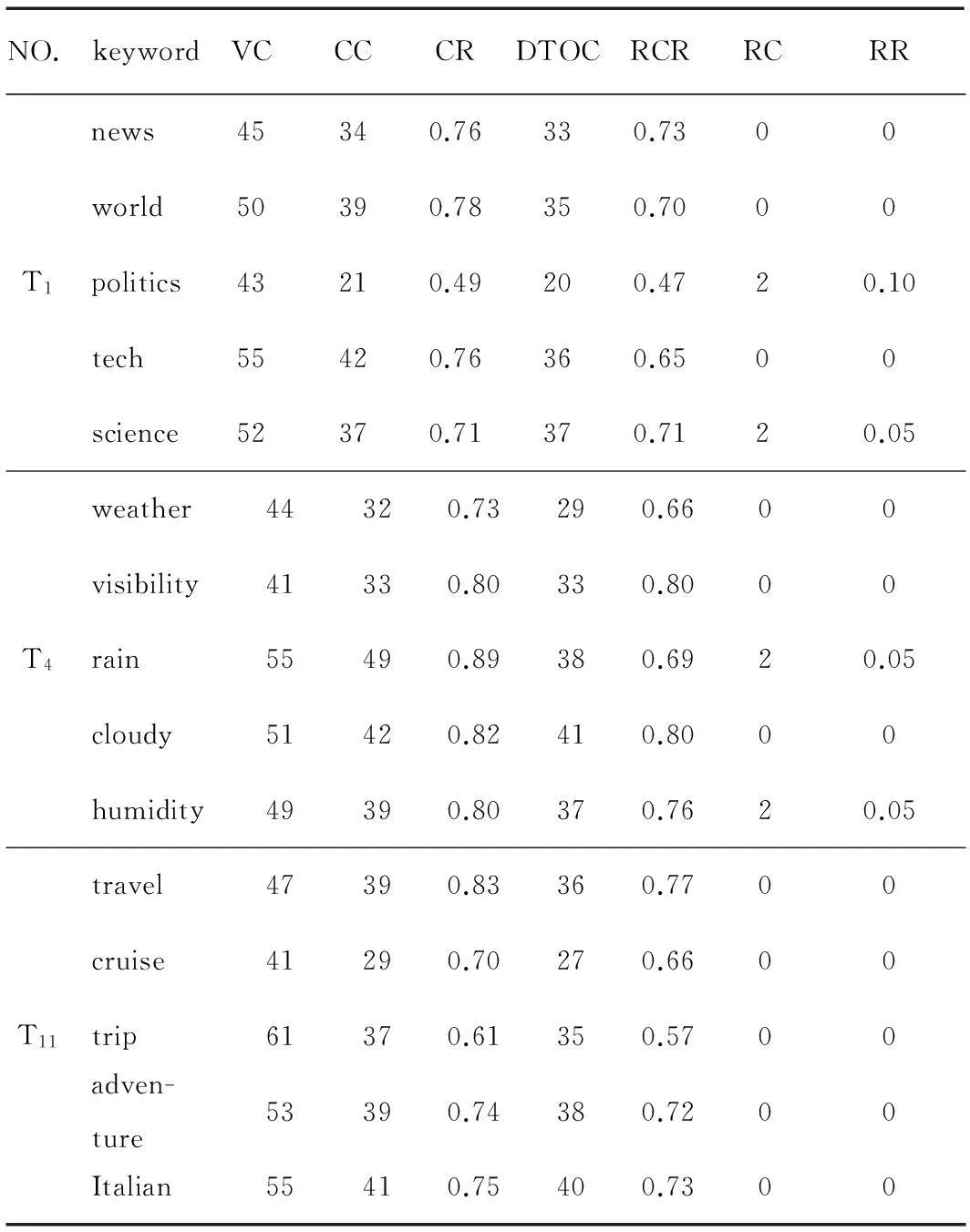
表4 雅虎一级目录实验数据表(B)
为提高数据的可信度,把每个主题中求得的5个准确率、召回率和重复率求取平均值,分别作为此主题的准确率、召回率和重复率,其结果如表5、表6所示。
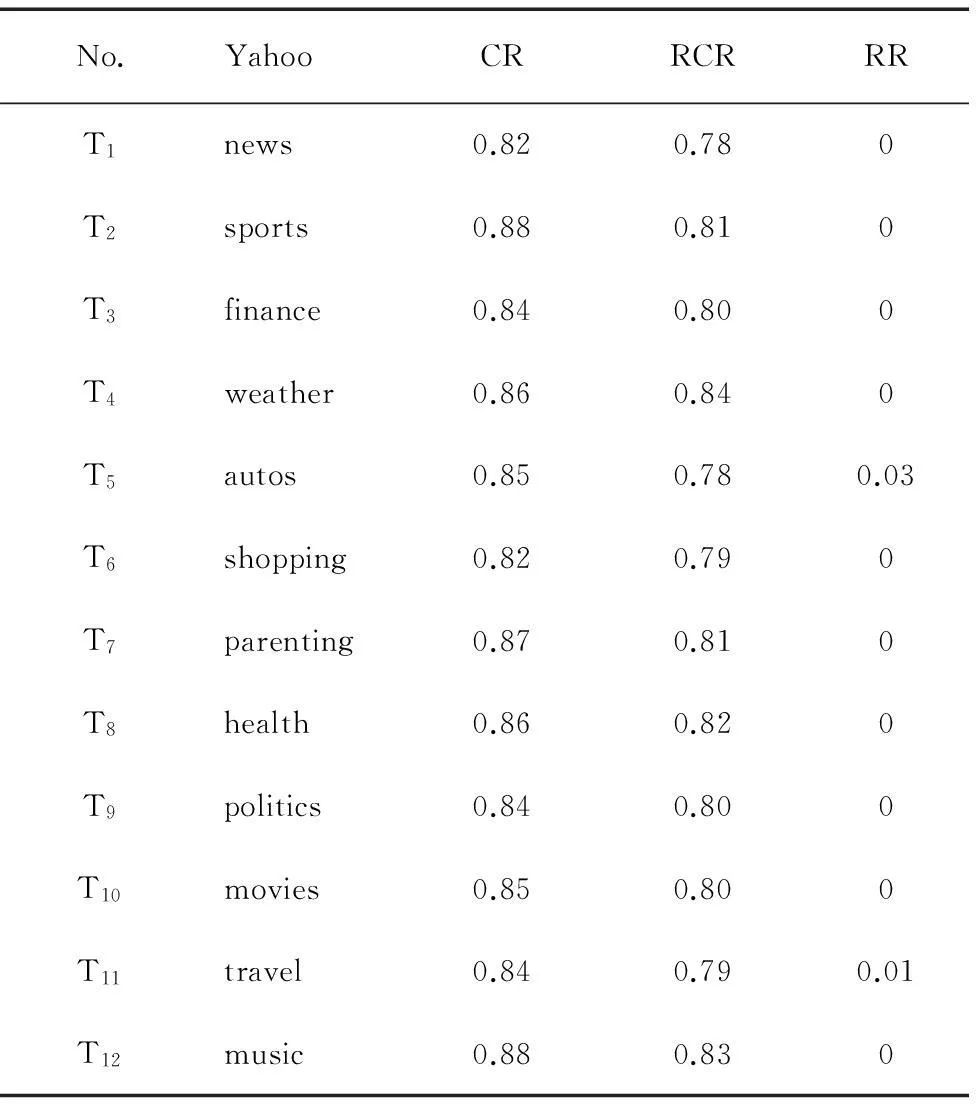
表5 平均精确率、召回率、重复率表(A)
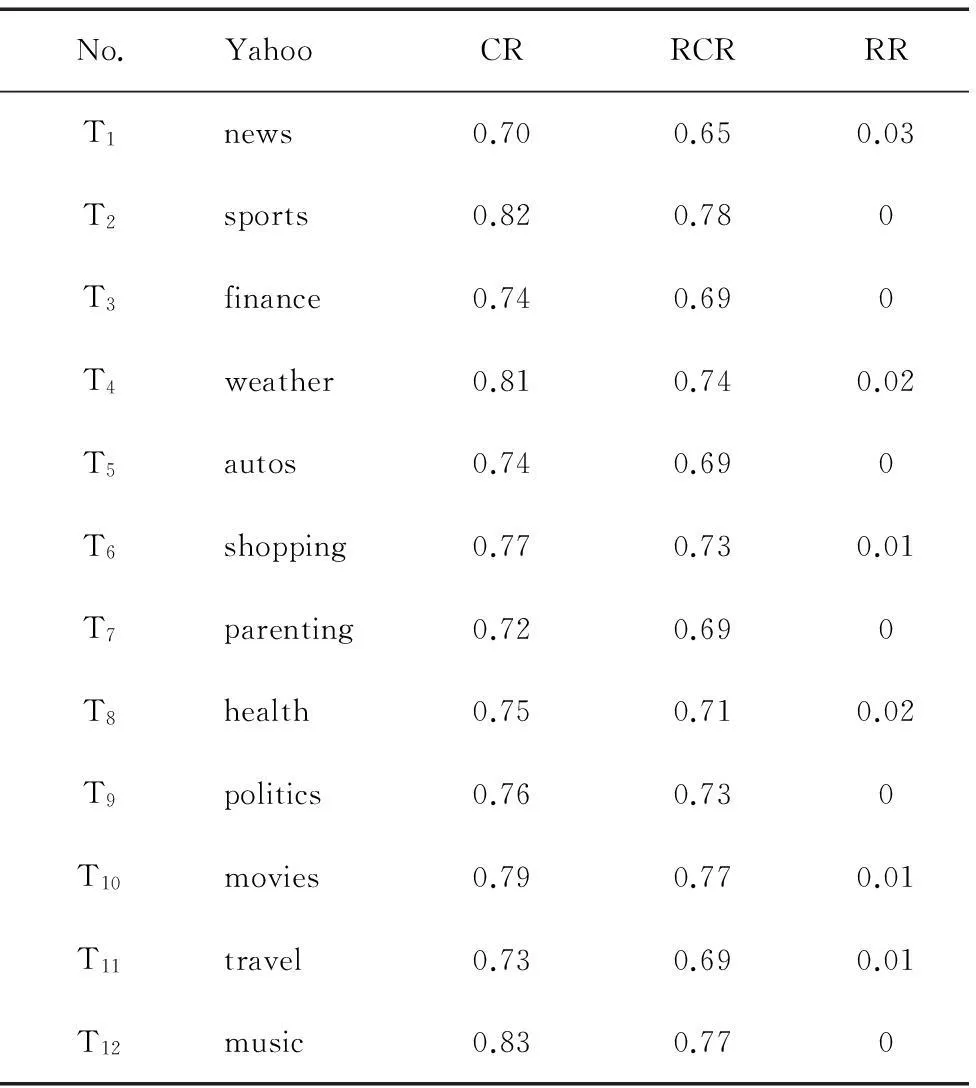
表6 平均精确率、召回率、重复率表(B)
在上述2种情况下所得的智能爬虫爬取网页的准确率、召回率和重复率的平均值分别为:CR/N(A)=85%, RCR/N(A)=80%, RR/N(A)=0.3%;CR/N(B)=76%,RCR/N(B)=72%, RR/N(B)=0.8%。
在使用市场匹配算法和不使用市场匹配算法的2种情况下,爬取网页的精确率、召回率和重复率如图6所示。由图知,使用了市场匹配算法提高了多Agent智能爬虫系统爬取网页的精确率和召回率,也降低了爬取网页的重复率。此实验中,以Yahoo12个主题为测试数据得出的精确率提高了9%,召回率提高了8%,重复率降低了5%。
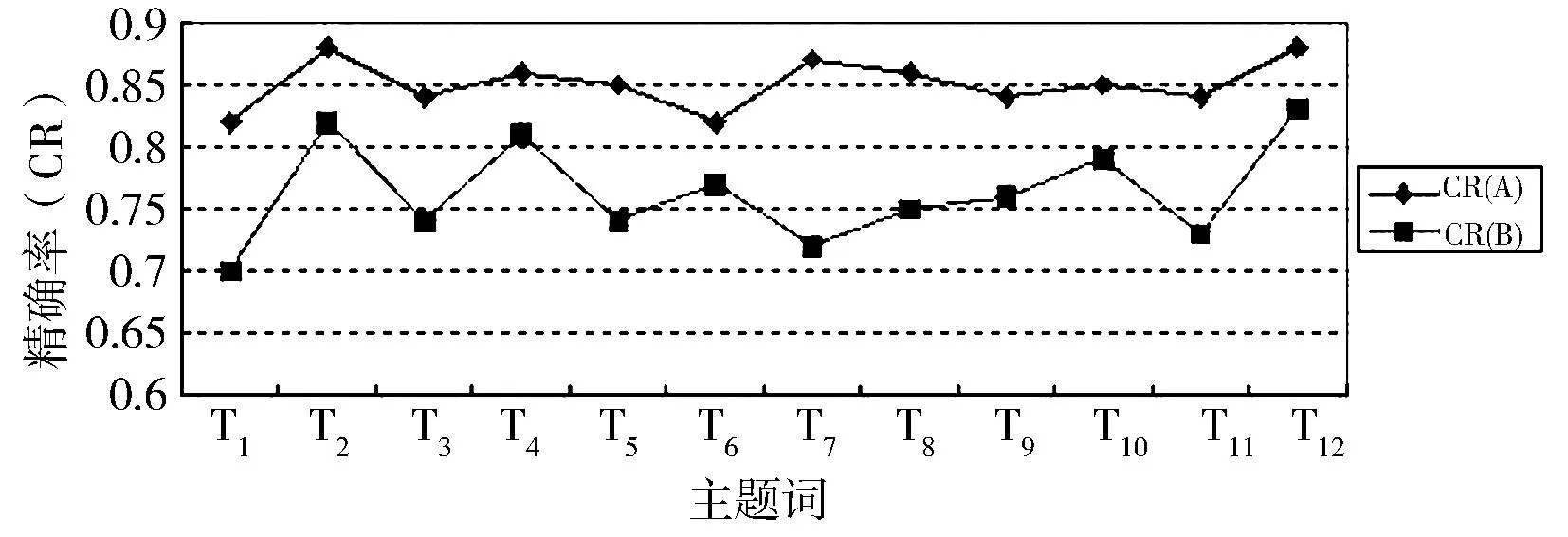
(a)精确率对比图
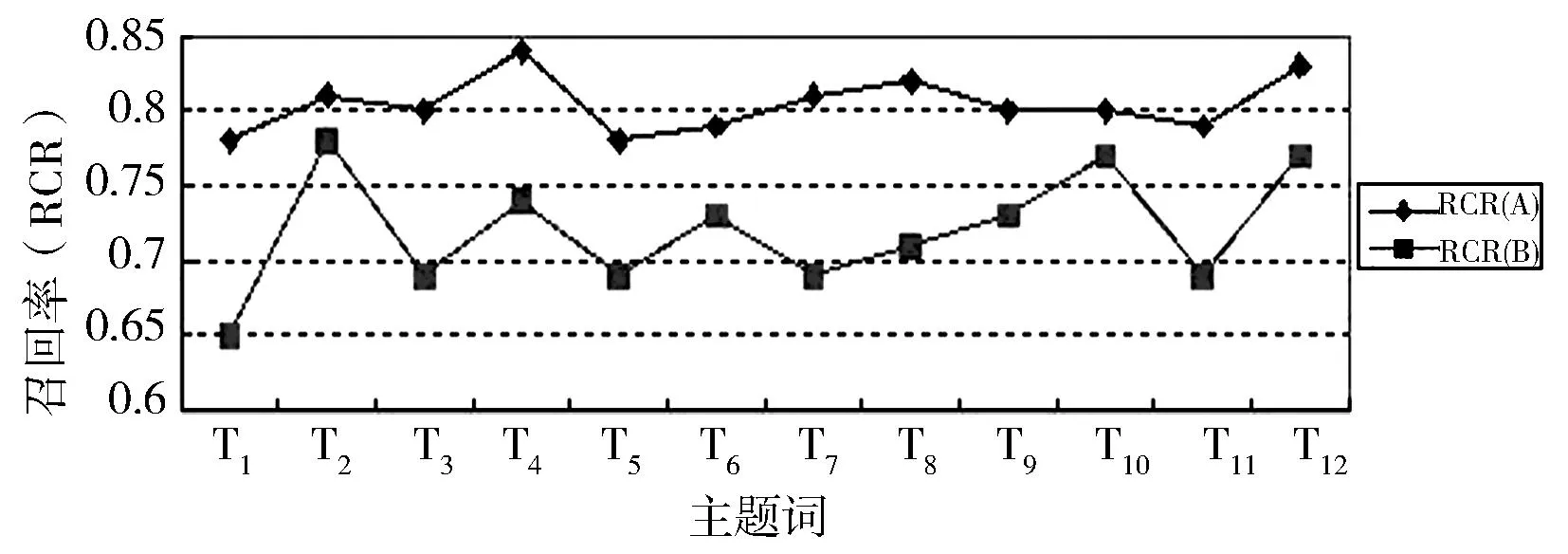
(b)召回率对比图

(c)重复率对比图
图6系统爬取网页的精确率、召回率、重复率对比图
4结论
基于多Agent的智能爬虫设计与实现涉及多方面的理论知识、技术和方法,本文主要完成了: 1)多Agent市场匹配算法的实现; 2)设计基于该算法的智能爬虫系统; 3)用Yahoo一级目录12个主题作为实验数据进行实验,分析了爬虫系统的性能。此系统还有一些不足之处,需要结合实际情况不断地积累和完善。此次实验只是比较了2种情况,将来的工作就是在网络爬虫系统使用的其他方法,如深度优先[1]、模糊规则推理[8]等方法,进行精确率、召回率等对比,使实验更加完善。
参考文献
[1]王莹煜.基于多Agent系统的主题爬虫理解与协作研究[D].成都:西华大学,2010.
[2]Wang Yingyu,Du Yajun,Chen Shaoming.The Understanding between Two Agent Crawlers Based on Domain Ontology[C]//Proceedings of the 2009 International Conference on Computational Intelligence and Natural Computing.[S.l.]:Neural Network World,2009:47.
[3]杜亚军.多Agent主题爬虫协作策略的研究与分析[J].西华大学学报(自然科学版),2013,32(1):1.
[4]Ali Hesham.Self Ranking and Evaluation Approach for Focused Crawler Based on Multi-Agent System[J].The International Arab Journal of Information Technology,2008,5(2):1.
[5]Easley David,Kleinberg Jon.网络、群体与市场[M].李晓明,王卫红,杨韫利,译.北京:清华大学出版社,2011:175-185.
[6]姜梦雅.基于Java的多线程网络爬虫设计与实现[J].Microcomputer Applications,2010,26(7):21.
[7]张亮.基于HTMLParser和HttpClient的网络爬虫原理与实现[J].电脑编程技巧与维护,2011(20):94.
[8]徐朝军,李艺,杨小江.基于模糊规则推理的主题资源搜索系统设计与实现[J].情报学报,2009,28(6):815.
[9]林海霞,司海峰,张微微.基于Java技术的主题网络爬虫的研究与实现[J].Microcomputer Applications,2009,25(2):56.
[10]罗刚,王振东.自己动手写网络爬虫[M].北京:清华大学出版社,2010:4-64.
[11]罗林波.基于内容和链接的主题爬虫研究与设计[D].海口:海南大学,2010.
[12]张红云.基于页面分析的主题网络爬虫的研究[D].武汉:武汉理工大学,2010.
(编校:饶莉)
System of Intelligent Crawler Based on Multi-Agent
LIU Jia,DU Yajun*
(SchoolofComputerandSoftwareEngineering,XihuaUniversity,Chengdu610039China)
Abstract:With the number of network texts, graphics videos,audios in the online world is growing rapidly, the web crawler becomes more and more powerless, mainly showed in the lower precise rate, lower recall rate and higher repetition rate while crawling web pages. In order to address the problem mentioned above, a multi-Agent intelligent crawler system using market-matching algorithm is proposed by combining market-matching fundamentals and characteristics of web crawler. This paper firstly analyzed and designed every important part of multi-Agent intelligent crawler system in detail based on market-matching algorithm. Then the precise rate, recall rate and repetition rate of crawling web pages were analyzed by using the directory of Yahoo as test data. Experimental results show that the multi-Agent intelligent crawler system can improve the performance of the web crawlers compared to the system without using market-matching algorithm, specifically manifest in the precision rate and recall rate increased by 9%,8% respectively, while its repetition rate decreased by 5%.
Keywords:market-matching algorithm; multi-Agent; intelligent crawler
doi:10.3969/j.issn.1673-159X.2016.01.014
中图分类号:TP393.09
文献标志码:A
文章编号:1673-159X(2016)01-0067-06
*通信作者:杜亚军( 1967—) ,男,教授,博士,硕士生导师,主要研究方向为网上信息挖掘与搜索引擎、计算机软件开发技术。E-mail:duyajun@aliyun.com
基金项目:国家自然科学基金(61271413,61472329)。
收稿日期:2015-07-16
·计算机软件理论、技术与应用·
