
基于改进协同过滤算法的图书网站个性化推荐模型构建研究
2016-03-15 01:26李敬明程家兴
长春师范大学学报 2016年2期
李敬明,程家兴,张 伟,方 贤
(1.安徽新华学院信息工程学院,安徽合肥 230088;2.合肥工业大学管理学院,安徽合肥 230009;
3.安徽大学计算机科学与技术学院,安徽合肥 230031)
基于改进协同过滤算法的图书网站个性化推荐模型构建研究
李敬明1,2,程家兴1,3,张伟1,方贤1
(1.安徽新华学院信息工程学院,安徽合肥 230088;2.合肥工业大学管理学院,安徽合肥 230009;
3.安徽大学计算机科学与技术学院,安徽合肥 230031)
[摘要]协同过滤是推荐系统应用最广泛的方法,其中项目之间的相关性是影响推荐算法质量的关键因素之一,针对基本协同过滤算法中未充分利用项目之间的相关系数,且算法的计算量也会随着用户和项目的不断增加呈现出爆炸性的增长,从而导致推荐质量低下等问题,本文提出了一种基于聚类分析的改进协同过滤算法。该算法加入项目相关性计算,利用聚类分析算法提高推荐算法效率,并将其应用于图书网站个性化推荐模型的构建。仿真实验表明,这种改进后的算法在收敛速度与算法准确性方面取得了显著的提高。
[关键词]改进协同过滤;聚类分析;个性化推荐;图书推荐
1研究背景
近年来,随着网络信息资源的不断丰富和发展,如何精准地向每个用户推荐他们最感兴趣的项目是目前各大网站保持用户粘性和竞争力的关键技术,推荐系统在许多领域都表现出它的巨大应用潜力,尤其在电子商务领域应用更为广泛,如一些大型的在线阅读网站与图书网站都不同程度地使用了各种个性化推荐系统[1]。协同过滤技术[2]是个性化推荐系统中最成功的推荐技术,通过分析历史数据,将兴趣相近的用户作为目标用户的邻居放入邻居集中,找出邻居集中用户感兴趣的项目并推荐给当前用户。目前使用的协同过滤算法是基于用户-项目评价矩阵的,没有考虑项目与项目之间的关系对最终推荐结果的影响,并且当用户-项目矩阵不断增加时,算法的计算量也在不断增加,最终导致结算法的计算量大、可扩展性差及推荐结果的可信度低等。为了解决当前协同过滤技术存在的一系列问题,研究者们基于已有的算法提出了多种改进的算法思想并加以应用。根据项目之间的相似性计算提出了基于评分预测的协作过滤方法[3]、利用算法精简评分矩阵维数而提出的维数简化算法[4]等。
本文采用了一种基于聚类分析的改进协同过滤算法,使用k-means聚类算法将现有的用户进行聚类,使同一个聚类中用户的兴趣度最为相似。在预测评分时加入项目之间的相似性,提高预测评分的精确度。并将其应用于优化图书网站的个性化推荐质量。
2相关工作
协同过滤技术通过分析用户的历史数据,生成与目标用户兴趣相似的用户并组成邻居集,并将邻居用户集中感兴趣的项目推荐给当前用户,即产生top-N推荐集。在传统基于用户的协同过滤算法中,输入当前用户的待处理数据通常是一个m*n的用户-项目评价矩阵R=(ratingij)(i∈m,j∈n);m是用户的数目,n是项目的数目。ratingij表示第i个用户对第j个项目的评分。在本文构建的模型中,ratingij通常为-1~5中的一个整数,其中-1表示其没有浏览过该书籍,0则表示用户阅读了该项目但却没有进行评价,1~5数值的大小表示用户对该书籍的喜爱程度。在其它推荐系统中,比如电子商务的推荐系统中我们也可以使用0~1中的一个整数表述用户是否购买了某件商品,进而进行数据表述的工作。图书个性化推荐系统用户-项评分矩阵如下:

协同过滤技术的关键就是通过计算用户之间的相似性为当前用户找到一个最近邻居集(Neighbor),并按照相似性的大小进行排序,根据邻居用户提供的信息筛选出当前用户最可能感兴趣的项目并进行推荐。例如:对一个当前用户u,使用Person相关度或者目前常用的向量空间相似度计算其与用户集中的任一用户ua的相似性sim(u,ua),按大小进行排序形成用户u的最近邻居集neighbor∈{sim(u,u1),sim(u,u2),…,sim(u,um-1)},并且满足sim(u,u1)>sim(u,u2)>…>sim(u,um-1)。这里,我们使用Person相关度计算用户之间的相似性,计算公式如下:

(1)

当产生了当前用户u的最近邻居Neighbor之后,将包括用户u在内的所有用户评分项目合集减去当前用户的所有已评分项目,得到当前用户u的待预测评分项目合集Iu。并且计算用户u对每一个项目i∈Iu的预测评分,筛选出评分最高的前n项,即产生top-N推荐集推荐给当前用户,用户对待预测项目的预测评分计算公式如下:

(2)
3基于改进协同过滤算法的图书网站个性化推荐模型的构建
3.1基于项目相关性的改进协同过滤算法
目前,基于用户的协同过滤技术发展已经十分成熟,但其有明显的缺点,即没有考虑到项目之间的相关性。比如预测当前用户对一本历史类书籍的评分时,可能会将邻居用户阅读的传记类书籍和侦探类书籍一起考虑进去并进行评分,很明显,传记类书籍对最后预测评分的影响要比侦探类书籍的大,但基于用户的协同过滤技术会将两者同等地考虑进去,降低了最终的推荐质量。
本文采用了一种基于项目属性计算项目之间相关性rel(i,ip)的改进协同过滤算法,并由此计算受不同项目之间相关性所影响的最终预测评分。通常使用Person相关度来计算项目之间的相关性,但此方法不具有客观性,容易受用户的主观影响。不能客观反映项目之间的相关性,导致最终的推荐质量不精准。因此,本文使用了基于项目属性矩阵的项目相关性计算。存在一个项目属性矩阵Attr={attrij},其中attrij表示第i个项目是否具有第j个属性,且其值为0或1中的任一整数,0表示该项目不具有该属性,1表示具有。Attr项目属性矩阵如下:

基于项目属性计算项目相似性计算公式如下:

(3)


(4)
当引入项目相关性之后,用户相似性计算就改进为以下公式:

(5)
其中,sim(ua,ub)iP表示的是用户a和用户b基于待预测项目iP的相似性。最后,将(5)式代入(2)式中得到以下新的预测评分公式,并选出最近邻居集和产生top-N推荐。

(6)
3.2基于聚类分析的K-means算法优化协同过滤技术
协同过滤算法扩展性较差,每次进行个性化推荐时都要计算当前用户与数据库中每一个用户的相似性,之后才能得到最近邻居集并产生top-N推荐。当用户-项矩阵过大时,计算量就会变得十分巨大,也会造成最终的推荐质量低下,不能达到预期额推荐期望。因此,可以使用聚类分析对协同过滤技术进行优化,提高个性化推荐质量。
聚类分析[5-6]是模式识别和数据压缩领域的一个重要问题,是非监督学习的重要方法,我们可以事先对数据库提供的用户信息使用聚类分析算法进行聚类,使得在同一聚类中的用户行为兴趣的相似性较大,处于不同聚类的任两个用户的相似性即兴趣相似度较小。当有用户需要进行个性化推荐时,直接计算出该用户属于哪一个聚类。并在该聚类中产生最近邻居集Neighbor,进而产生top-N推荐。这样便极大地简化了推荐过程。当有过大的用户-项矩阵时,不会有过多的计算量,并且优化了推荐质量。
K-means是基于划分的聚类算法[7-8],该算法简单且易于使用,运行速度快,与其它聚类算法相比应用更加广泛。设k是算法在数据集上输出的聚类数量,数据集是n个图书网站用户构成集合{I1,I2,…,In},并随机在数据集中找出k个用户作为初始聚类中心,分别计算剩下的每个用户与每个初始聚类中心的距离,并将此用户其分配给距其距离最近的聚类中心所在的聚类,然后更新每个聚类的聚类中心,直到准则函数收敛[9]。

(7)
其中,gj是聚类Cj的聚类中心,且l∈{1,2,…,n},j∈{1,2,…,k},下面对k-means算法的实现过程简要概述:
第一步,输入:包含n个对象的项目集以及所需的聚类个数k;
第二步,初始化k个聚类中心{g1,g2,…,gk},其中gj∈In,j∈{1,2,…,k},In是所有用户的集合;
第三步,使每一个聚类Cj与聚类中心gj相对应,In=In-{g1,g2,…,gk};
第四步,从In第一个元素I1开始计算与各个距诶中心的相似度,并将其放入最相似的聚类中心gj所属聚类Cj中,并在In集合中除去该对象,直到集合In为空;

第六步,输出k个聚类。
3.3基于改进协同过滤算法的图书网站个性化推荐模型
对基本协同过滤算法中的项目相关性以及利用聚类算法降低计算复杂度等两方面进行了上述改进,并将其应用于图书网站个性化推荐建模中。具体步骤如下:
第一步,导入网站数据中的图书属性表和用户评价表。根据图书属性表中的数据使用式(3)和式(4)联合计算图书之间的相关性;
第二步,根据3.2给出的步骤对网站用户进行聚类,使处于相同聚类的用户最相似;
第三步,根据用户评价表使用式(5)计算用户之间的相似性,并将前一百的用户作为目标用户的最近邻居集,并通过最近邻居集找出目标用户的待预测评分书籍集合;
第四步,使用式(6)计算预测评分,并将评分前十的书籍作为推荐项目(top-N)推荐给用户。
4实验及结果分析
4.1实验数据集及评价标准
常用的评价推荐系统推荐质量的度量主要包括统计精度度量方法和决策支持精度度量方法两类[10-11],根据本文的实验情况,这里我们使用平均绝对方差MAE方法。该方法通过计算当前用户待预测项目的预测评分和实际评分的偏差作为度量来检查推荐系统推荐结果的精确性。MAE值越低,推荐系统的推荐质量越低。
设当前用户的预测评分集合为{iP1,iP2,…,iPn},用户实际的评分集合为{i1,i2,…,in},则MAE值得计算如下:

(8)
以上基于聚类分析优化的协同过滤技术有效地避免了传统协同过滤技术中出现的各种问题,我们选择某图书阅读网站提供的数据,根据数据集中提供的描述文件采用18277条评价数据。共有2622名用户参与了评价6609本书籍的评价,实验采用了Matlab软件处理实验数据。
我们将所有数据集中的图书分为15个属性分类:悬疑、名著、影视、经管、社科、生活、武侠、历史、传记、人物、恐怖、推理、言情、幻想、学术,共有属性极大个数设为5,如表1所示。
产生一个m*n输入矩阵,该矩阵是用户-图书评价矩阵,矩阵中每个值都是-1~5中的一个整数,值的高低代表了用户对该评价书籍的喜爱程度。0表示用户阅读了该书籍却没有进行有效的评价,-1表示用户没有阅读该书籍,部分数据如表2 所示。
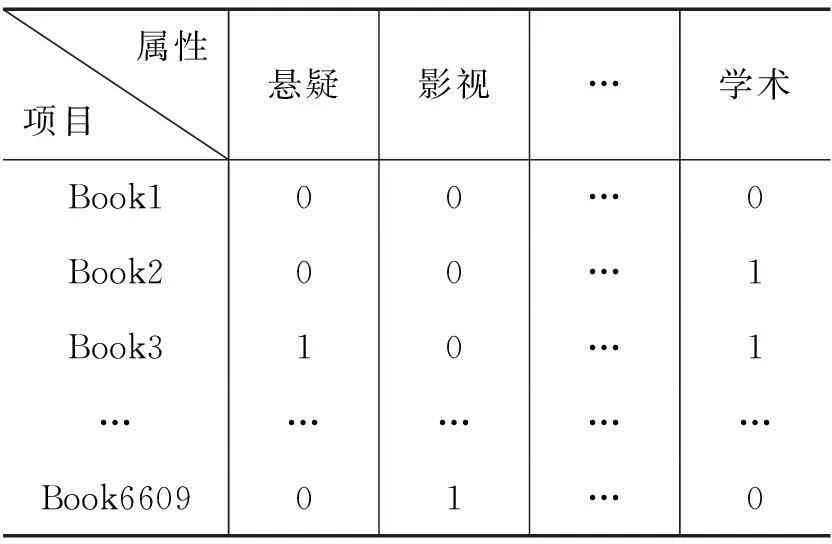
表1 图书属性表
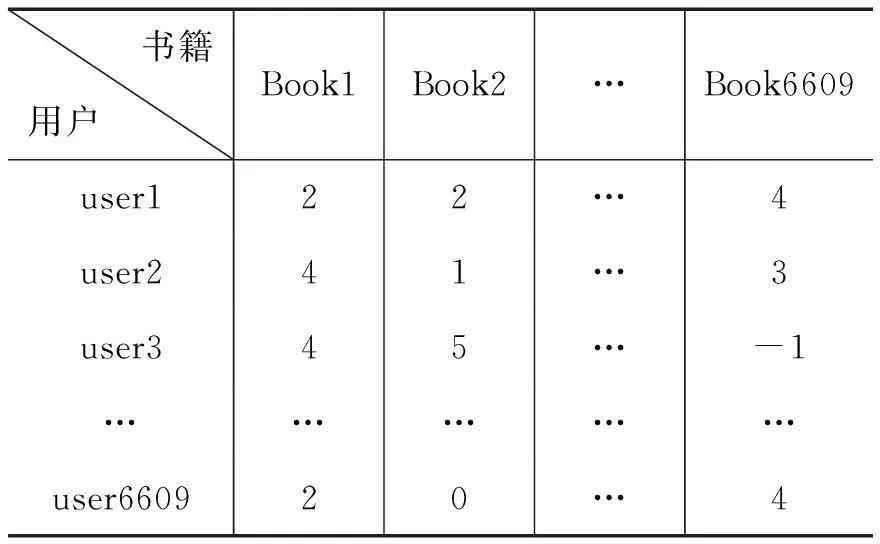
表2 用户-评价表
当目标用户进入时,服务器提取其历史浏览日志,计算它与各个聚类中心的相似度,并将其分入最相似的一个聚类中。之后用(5)式计算目标用户与当前聚类中每一个对象基于未评分图书项目的相似度,并按照大小顺序进行排列,产生当前用户的最近邻居集。找出最近邻居集中所有邻居已评分图书的合集,除去其中当前用户已评分的图书项目,得到待预测评分的图书候选集。使用(6)式计算当前用户对所有未评分图书的预测评分并按大小进行排列,选出前6项评分最高的图书推荐给当前用户,即产生top-N推荐集。
4.2实验数据集及评价标准
将实验得到的MAE值结果绘制成表格数据如表3所示,并与使用其它没有进行优化的协同过滤算法得到的结果进行比较。
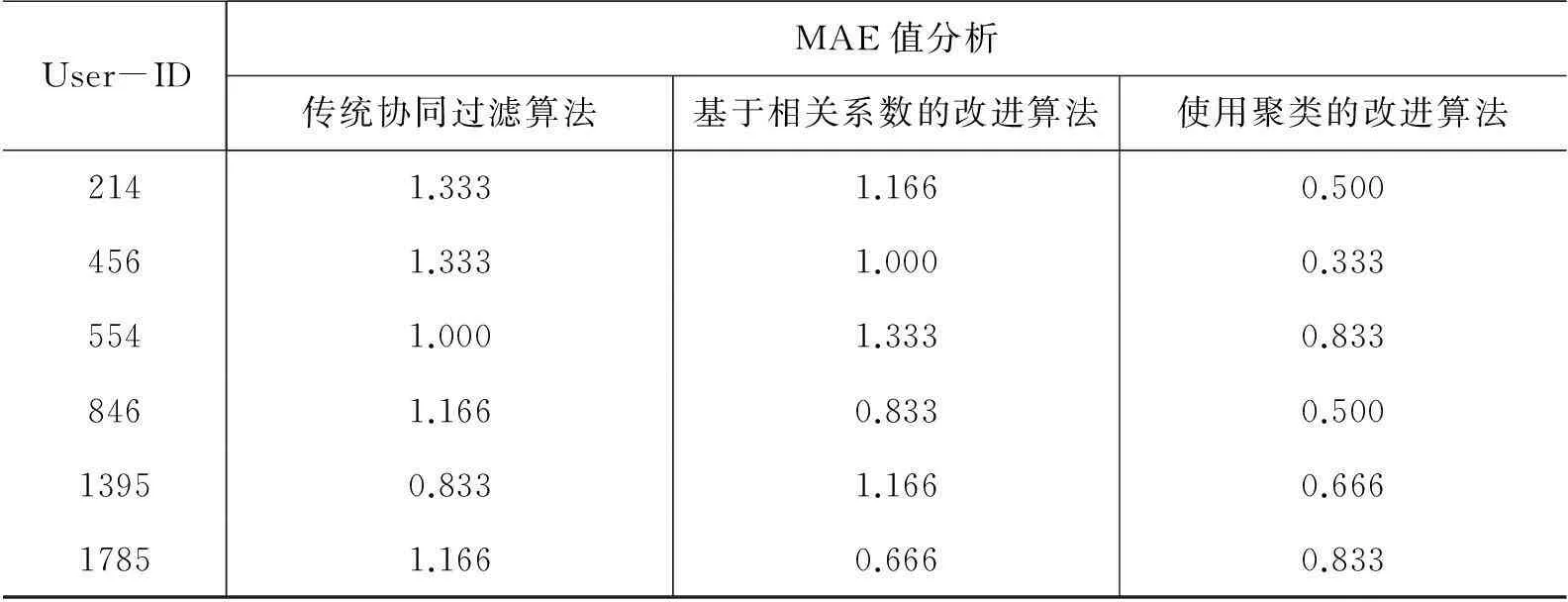
表3 MAE值分析表
使用Matlab绘图结果如图1和图2所示。

图1 MAE值分析表

图2 收敛时间分析表
未采用聚类优化的协同过滤算法效率不高,收敛速度较慢,且当数据量过大时,推荐结果质量比较差,从MAE值分析表(图1)中可以看出,采用聚类之后的算法得到的结果相比而言质量较高,能准确地推荐给用户所希望看到的书籍。从收敛时间分析表(图2)中可以看出,采用了聚类的算法收敛速度较快,实际操作中更能满足企业用户和阅读用户的需求。因此,给予项目相关性改进后的协同过滤算法得到的结果更加良好,值得进一步进行推广。
5结语
基本的协同过滤算法是从用户相似邻居的角度,分析用户兴趣并自动进行推荐。此算法在信息量适度的情况下具有良好的效率,在进行网站数据分析时数据量通常十分庞大,使用基本算法时每次推荐都必须要在计算用户与其它所有用户的相似性之后再进行推荐,效率较低。使用聚类算法使得每次推荐的搜索范围和计算量都大大降低,并且由于加入了项目之间的相似性计算,其推荐质量相对于基本的协同过滤算法得到了很大的提升。
[参考文献]
[1]Sivapalan S,Sadeghian A,Rahnama H,et al.Recommender systems in e-commerce[C].World Automation Congress, IEEE,2014:179-184.
[2]张腾季.个性化混合推荐算法的研究[D].杭州:浙江大学,2013.
[3]Sarwar B,Karypis G,Konstan J,et al.Item-based collab—orative filtering recommendation algorithms[C]. Proceeding of the 10th international World Wide Web Conference,New York,ACM Press,2010:285-295.
[4]邓爱林,朱扬勇,施伯乐.基于项目评分预测的协同过滤推荐算法[J].软件学报,2003,14(9):1621-1628.
[5]Jiawei Han,Micheline Kamber.数据挖掘概念与技术[M].北京:机械工业出版社,2005:185-218.
[6]于文倩.聚类相关知识简介[J].电子世界,2014(11):190.
[7]崔丹丹.K-Means聚类算法的研究与改进[D].合肥:安徽大学,2012.
[8]沈艳,余冬华,王昊雷.粒子群K-means聚类算法的改进[J].计算机工程与应用,2014(21):125-128.
[9]张雪凤,张桂珍,刘鹏.基于聚类准则函数的改进K-means算法[J].计算机工程与应用,2011,47(11):123-127.
[10]吴发青,贺樑,夏薇薇,等.一种基于用户兴趣局部相似性的推荐算法[J].计算机应用,2008,28(8):1981-1985.
[11]梁天一,梁永全,樊健聪,等.基于用户兴趣模型的协同过滤推荐算法[J].计算机应用与软件,2014(11):261-263.
[12]皮佳明.基于用户兴趣变化的协同过滤推荐算法研究[D].昆明:云南财经大学,2014.
The Research on Construction of Library Website Personalized Recommendation Model Based on Improved Collaborative Filtering Algorithm
LI Jing-ming1,2,CHENG Jia-xing1,3, ZHANG Wei1,FANG Xian1
(1.School of Information Engineering, Anhui Xinhua University, Hefei Anhui 230088, China;2.School of Management, Hefei University of Technology, Hefei Anhui 230009, China;3.School of Business, Anhui Finance and Economics University, Hefei Anhui 230031, China)
Abstract:Recommend system based on collaborative filtering algorithm has been widely used at present. Correlation between the two projects has not been considered in the basic collaborative filtering algorithm. There is a explosive growth of the compute when the users’ and the projects’ volume has been huge, which it reduces the quality of recommendation. An improvement collaborative algorithm based on clustering analysis is proposed in this paper. The project correlation calculation is added to collaborative filtering algorithm, which it is applied to build personal book recommend model. The experiments show that the improved algorithm can achieve good recommending quality.
Key words:improved collaborative filtering; clustering analysis; personalized recommendation; book recommendation
[作者简介]李敬明(1979- ),男,讲师,博士研究生,从事智能计算与数据挖掘研究。
[基金项目]国家自然科学基金项目“面向交易和服务过程的民营中小型银行经营模式及相关政策研究”(71403001);安徽省教育厅人文社会科学研究重点项目“体制外金融与安徽小微企业对接服务机制和风险防范研究”(SK2013A011)。
[收稿日期]2015-12-12
[中图分类号]TP319.3
[文献标识码]A
[文章编号]2095-7602(2016)02-0040-06
猜你喜欢
东方教育(2016年8期)2017-01-17
软件导刊(2016年11期)2016-12-22
电脑知识与技术(2016年27期)2016-12-15
电脑知识与技术(2016年27期)2016-12-15
商(2016年34期)2016-11-24
大经贸(2016年9期)2016-11-16
中国市场(2016年33期)2016-10-18
科技视界(2016年20期)2016-09-29
企业导报(2016年9期)2016-05-26
