
基于支持向量机的重污染工业企业碳风险预警研究*
2016-03-13 00:48周志方中南大学商学院湖南长沙40083两型社会与生态文明协同创新中心湖南长沙40083
环境污染与防治 2016年1期
周志方 肖 恬(.中南大学商学院,湖南 长沙 40083;2.两型社会与生态文明协同创新中心,湖南 长沙 40083)
随着全球资源能源供应趋紧、国际国内加紧对重污染工业企业废弃物特别是碳排放量管制的趋势,中国重污染工业企业的内外部经营环境也发生了深刻的变化。虽然气候变化框架公约体现的是“共同但有区别责任”的原则,即作为发展中国家的中国暂时不承担碳排放削减义务[1],但是中国自2006年后超越美国成为碳排放量最大的国家这一情况饱受国际诟病;加之中国“两型”社会建设以及发展低碳经济为导向的国家政策给中国企业、特别是中国重污染工业企业的长期生存与发展带来巨大的减排压力,使得相关企业不得不加强对碳排放的管控意识,进而必须具备和提高碳风险意识。中国重污染工业企业相比其他工业企业来说碳效率较低、含碳废弃物排放量大、与碳排放相关的事故频发,面临着较大的碳风险。正确认识和管控碳风险是今后中国重污染工业企业必须面临和解决的重大问题。
碳风险管理已在全球引起了广泛关注,尽管对于低碳发展、评价环境风险的主要内容及方法以及环境风险预警已有了较全面的探索[2-9],但已有的各项研究缺乏对碳这一重要环境污染元素的针对性。碳风险作为环境风险的一个重要组成部分,学术界对其研究仍存在较大空白,中国乃至国际对碳风险管理的研究仍然仅限于识别风险及评价风险,而对于碳风险的预警和管理来说,相关研究的缺乏导致不仅未形成较统一的碳风险评价指标体系,并且缺乏主流的碳风险及指标数值量化的评价方法与工具。企业面临的碳风险是复杂的,有些碳风险往往难以量化。本研究试图综合运用层次分析(AHP)法与德尔菲法,借鉴现行的多种低碳经济发展情况评价体系和环境风险评价指标体系,从中提升出针对碳风险管理的各项指标,建立起一套碳风险预警指标体系,并结合定性与定量分析,采用企业3年前的相关指标数据并与企业碳风险现状对比,借此训练预警模型。在模型工具的选用方面,支持向量机(SVM)模型作为机器学习的最新成果,在预警商业银行客户流失风险及若干类企业的财务风险[10-12]研究方面都取得的良好效果。这表明,SVM模型用于风险预警研究的可行性,及其在应用范围方面仍有较大的可扩展性。
1 重污染工业企业碳风险的内涵与类别
根据2010年环境保护部公布的《上市公司环境信息披露指南(征求意见稿)》中指示,火电、钢铁、水泥、电解铝、煤炭、冶金、化工、石化、建材、造纸、酿造、制药、发酵、纺织、制革和采矿业等16类行业被认定为重污染行业。
重污染工业企业碳风险指的是因重污染工业企业实施节能减排、发展低碳经济而带来的企业经营的不确定性。企业在运用各种资源能源进行生产、获取经济利益的同时,承担着与碳排放和含碳废弃物处理相关的、可能导致企业蒙受损失的风险。碳风险的形成原因主要可归集为:国际国内的环境保护政策;企业低碳技术的革新;企业管理目标的转变;市场需求影响等。
企业中碳元素的产生与流转主要来源是化石能源的消耗,从资源物质流转[13]角度分析,企业碳风险的分类即可依据化石能源所含碳流在企业中流转的3大过程,即投入、消耗、产出阶段进行探讨(见图1)。在化石能源投入阶段,企业投入生产的能源结构对其碳风险水平有着至关重要的决定性作用;企业在推行节能减排、降低碳风险时进行的大规模的新技术研发和新设备更新,有可能导致大量营业外支出而对企业的持续经营产生不利影响;在化石能源消耗阶段,化石能源利用效率、历史事故的次数、碳排放权交易以及政策对于重污染工业行业的管制等,都从不同的方面影响着企业的碳风险水平[14-16];在化石能源产出阶段,企业碳风险主要由碳排放风险与竞争力风险组成。
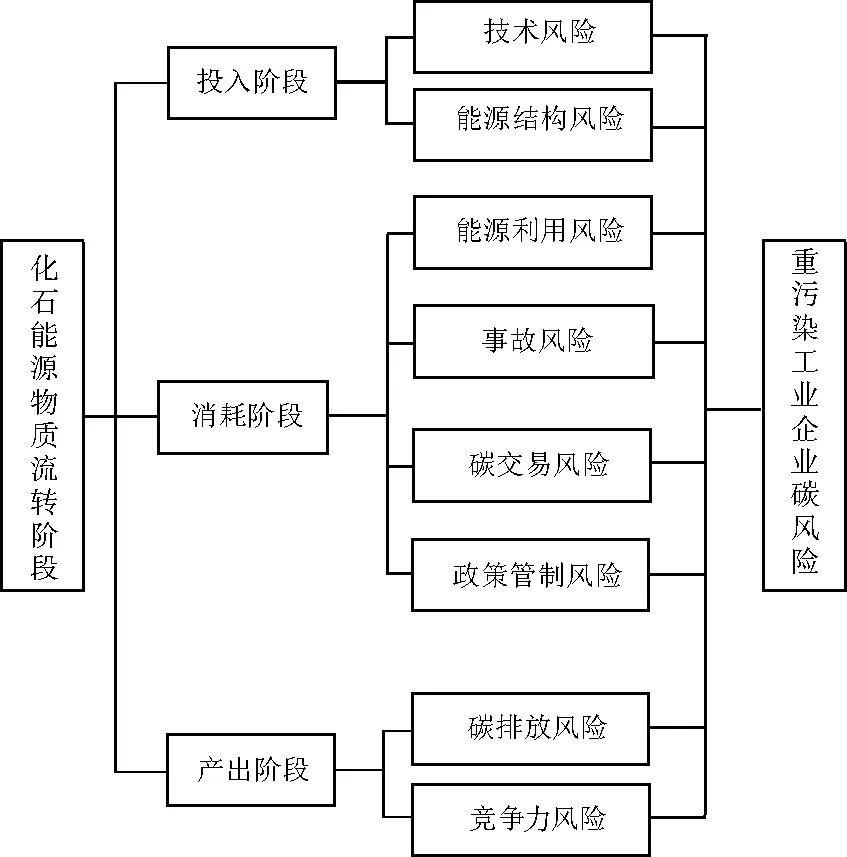
注:本研究中碳排放风险的定义仅限于企业含碳废气的排放风险。图1 碳风险分类Fig.1 Categories of carbon risk
2 SVM模型分类机制
SVM模型擅长解决小规模样本、非线性及高维模式识别问题,能根据有限的样本信息在模型的复杂性(即对特定样本的学习精度)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折衷,以获得最好的推广能力[17]。运用SVM模型对重污染企业碳风险进行预警研究有着较高的准确性与推广性。
二维两类线性可分问题中,尽管存在着很多可能的线性分类器可以正确区分两类模式,但SVM模型旨在寻找一个尽可能精确的最优超平面,使两类样本点到这个最优超平面的分类间隔的边际最大,也就是预测的误差最小[18]。定义n个训练样本点(xi,yi)组成样本集D∈Rd,其中i=1,2,…,j,…,n;xi为第i个训练样本;yi为t元类别符号,t取决于样本的类别数量;Rd为样本空间。存在这样一个分类超平面wTxi+b=0,xi∈Rd,给定条件yi(wTxi+b)≥1,w为坐标系下xi和yi的系数组成的二维行向量,b为任意常数。为使得Rd中任一点(xi,yi)都能够满足给定条件,求最优超平面的问题转化为求式(1)二次规划问题的最优解:
(1)
式中:φ(w)为二次规划问题的目标函数。
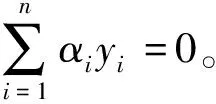
(2)
式中:α为拉格朗日乘数;αi、αj为样本点(xi,yi)和(xj,yj)相对应的拉格朗日乘数。
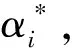
αi(yi(wTxi+b)-1)=0
(3)
而对于非线性可分问题即无法用一个超平面将样本点分为两类时,需要引入松弛变量来推广最优分类超平面的概念。定义第i个训练样本的松弛变量(ηi,ηi≥0)使得超平面wTxi+b=0满足条件不等式yi(wTxi+b)≥1-ηi。当ηi∈(0,1)时,xi仍能被正确分类;当ηi≥1时,条件不等式失效。因此,必须借助另一目标函数(ψ(w,η),见式(4))来判断。
(4)
式中:η为松弛变量;C为惩罚因子。
借助核函数K(xi,xj)来代替最优分类面中的xi·xj,即可实现将原特征空间映射到更高维的空间,将原本线性不可分的问题转化为近似线性可分的问题,并且减少了计算量,此时就可以利用二次规划来实现SVM模型。应当注意的是,并非所有的样本点都有一个ηi与其相对应。实际上只有那些“离群点”才有,或说是所有没离群的点松弛变量都等于0;并且,松弛变量的值实际上标示出了对应的点到底离群有多远,松弛变量的值越大,对应点就离群越远。核函数的选取一般是用满足Mercer条件的对称函数即可。此时,优化函数变为式(5)。相应地,判别函数(f(x))见式(6)。
(5)
(6)
式中:x为空间横向坐标;b*为分类域下限值,可以对两类模式中任意一对支持向量取中值求得。
对于核函数的选择有很多种,KEERTHI等[19]证明了RBF核函数(也称高斯核函数,其函数式见式(7))不仅简化了求解难度、减少了参数数量,还在处理自变量与因变量之间的非线性关系上有着很明显的优势。因而,本研究选取了高斯核函数作为SVM模型的核函数,将高斯核函数代入式(6)得到最终判别函数(见式(8))。
K(xi,xj)=exp(-g·‖xi-xj‖2),g>0
(7)
(8)
式中:g为高斯核函数参数。
由式(8)可知,利用高斯核函数支持的SVM模型需要若干样本来训练C和g以期达到准确的分类效果。
3 基于SVM的重污染工业企业碳风险预警模型
3.1 重污染工业企业碳风险预警流程
风险预警模型是企业为预先警示经营的薄弱环节、以事前控制的理想状态规避一定的风险而建立的一套重点监测碳有关指标或碳风险警戒标准。在相关的碳风险出现时,有关人员能据此分析企业碳风险的产生原因或是企业生产中的潜在问题并及时针对这些问题作出相应的防范措施的一种数据化管理模式。碳风险预警模型的关键就在于预警指标体系的建立。企业碳风险预警流程如图2所示。
3.2 重污染工业企业碳风险预警指标体系
指标可以通过对表面数据和现象的处理,抽象出事物内部本质联系与变化规律,并最终以较简单的形式表达出来。因此,评价指标是评价体系的骨架,科学建立有效的评价指标体系是决定一个企业综合评价成功的关键。指标体系既要反映其内涵,又要综合考虑环境社会特性、企业生产流程以及碳元素流转状态;既要有利于公司管理决策,又要有利于行业发展。
企业碳风险预警指标体系作为一种多指标综合评价方法的应用,其“不平衡性”尤为突出,因而指标权重的确定很重要。指标权重的确定主要遵循系统优化、群体决策以及引导意图与现实相结合的原则。
在国内外文献研究中,对指标权重确立方法的选择主要有主观赋权法和客观赋权法两种,前者主要涵盖指数比较法、专家评价法、AHP法等,后者主要包括主成分分析法、因子分析法、熵值法等,两者各有利弊[20-21]。前者虽能反映评价的真实目的,但易受主观因素影响;后者虽可避免人工干预,但不能有效反映目标的真实重要性程度,且需大量原始数据作为支撑。由于企业碳风险的特征限制了客观赋权法的应用,而定性与定量相结合的AHP法更适合于确定评价客体的指标权数:(1)个体主观思维呈现数字化和系统化特征、能以有限数据揭示问题内在因素;(2)“树”状特征不仅为碳流在企业流转3环节提供了“结构”基础,也增加了其实际应用的灵活性;(3)随着数据积累的增加,可与德尔菲法及客观分析法联合使用以增加指标权数的客观性。

图2 重污染工业企业碳风险预警流程Fig.2 The procedure of carbon risk early warning of heavy-polluted industrial enterprises
需要注意的是,由于受专家填表随意性以及其他不确定因素的影响,因此在运用AHP法两两比较构造判断矩阵时,应运用德尔菲法以多轮匿名征询的方法构造判断矩阵,再用AHP法进行一致性检验和计算权重值。
指标权重的确定过程[22]是:
(1) 建立层次结构模型。
(2) 专家判断。①选择专家,所选专家一般5~20个为宜;②依据相关资料,让每个专家对各层次因素集给出一个判断矩阵;③回收专家的判断结果并计算判断矩阵各元素的均值与离差;④将计算结果及资料返还给专家,要求重新确定判断矩阵;⑤重复上述第③、④步,直至离差不超过预先标准,即专家意见基本趋于一致。
(3) 计算权重向量。根据判断矩阵,先计算判断矩阵的特征向量,然后进行归一化处理。特征向量就是各指标(因素)相对上一层次的相对重要程度,即权重向量。
(4) 计算判断矩阵一致性指标,检验其一致性。①计算一致性指标(CI,见式(9))。当判断矩阵具有满意的一致性时,λmax稍大于n,其余特征根均接近于零,此时所得权重向量才基本符合实际。②找出相应的平均随机一致性指标(RI),计算一致性比例(CR,见式(10))。一般认为,当CR<0.1时,判断矩阵基本符合完全一致性条件;当CR≥0.1时,认为所给出的判断矩阵不符合完全一致性条件,需要进行调整和修正判断矩阵的元素取值。
(9)
CR=CI/RI
(10)
式中:λmax为最大特征根。
依据本研究指标设置逻辑,经过指标形式确定、指标初选和指标体系完善,确定递阶层次结构(目标层、准则层和指标层);通过查阅和收集重污染工业企业生产的相关资料和信息,采用频度统计法、理论
分析法和专家咨询法的初选确定了45个评价指标,其初选指标涵盖经济效益、环境保护、碳流物质流及价值流转量等各方面。在指标筛选过程中,剔除18个可行性和准确性无法满足的指标,经过指标主成分分析和独立性分析剔除9个指标,最终留下18个评价指标,限于篇幅不予详细列出。最终确定的重污染工业企业碳风险预警指标如表1所示。
3.2.1 投入阶段
(1) 节能减排技术指标
节能减排技术研发支出占比是评价企业在评估年份内节能减排技术和设备方面的投入力度,体现企业对于节能减排的重视程度。节能减排技术研发支出的下限往往是当地政府强制政策或企业所在园区的强制准入条件,考虑这一支出比例,是为了直接考察企业的节能减排意识和重视程度,这种意识和重视可从侧面考评、预测企业的碳风险。
(2) 能源结构指标
消耗的化石能源占总能源比例是用来评估企业在评估年份的能源结构合理程度,相对来说,该比例越高,企业碳风险相应越高,反之则越低。从长远来看,化石能源的限制使用是政府政策的必然趋势。
3.2.2 消耗阶段
(1) 能源效率指标
单位产值(产量)能耗是指生产单位产品或万元产值所消耗的碳流价值量,用以衡量企业的碳效率;节能效果是指与上年比较,评估年份企业年节约能源总量的指标;节能设备运转率是衡量企业相关节能设备的启用、运转与保养状况;化石固废资源综合利用率是对企业实行固废资源循环利用以及循环经济的效果进行评价。

表1 重污染工业企业碳风险预警指标体系Table 1 Carbon risk prediction indicator system
(2) 事故风险指标
近5年事故发生次数是指企业在近5年内发生的与碳排放相关的环境污染事件次数;应急措施完备程度是评价企业是否制定了健全、有效的处理碳排放紧急事件的应急措施。
(3) 碳交易风险指标
碳交易事项参与程度是评价企业参与碳排放权交易市场的程度。这一指标的影响可能是双向的,即企业作为排放权交易的卖方时,可以从侧面认定企业的碳排放量较少、碳风险较低,反之则较高。
(4) 政策管制指标
强制性政策达标情况是指企业是否达到地区、国家政策或行业规范的排放量及排放浓度等要求;违规碳排放罚没情况是指企业的排污费或因违规违法而导致的经济利益流出情况。
3.2.3 产出阶段
(1) 碳排放指标
温室气体排放量是评价企业在评估年份中以二氧化碳为主的温室气体排放总量;减排效率是衡量企业在评估年份中单位减排投入引致的碳减排量。
(2) 竞争力指标
节能产品占产出产品比是指用于衡量企业产品结构中节能产品的比例,该指标越大,企业的竞争力越强;节能减排成果受表彰情况是反映企业的节能减排成果的社会认可度,包括行业协会、政府及国际组织给予的称号、奖励等;碳信息披露程度是评价企业的社会责任报告或可持续发展报告、年报中与碳排放相关信息披露的完善、真实程度;节能减排宣传效果是衡量企业对于节能减排的宣传力度与效果,不仅包括企业内部的宣传,还包含企业节能减排宣传对地区甚至社会的辐射效果;能源与环境管理制度完备程度是评价企业能源与环境管理相关制度的制定、完善与执行状况,如是否进行了ISO 14001环境管理体系认证等。
考虑到碳风险评价时缺乏相应的规范性量化评估方法,对碳风险的评价采用德尔菲法,德尔菲法具有匿名性、反馈性和评估结果收敛的特点。其优势在于可以有效集中相关领域专家的经验、依靠他们的知识储备及对相关问题的了解,通过反复的评分修正,加之避免了群体内成员受他人的影响或是个人局限,采用德尔菲法对企业碳风险的评价结果较客观并易于理解和操作。
评价标准如下:将相应指标的实际发生值发放给各位专家,咨询各位专家对于评估年份内企业各指标的评分,专家估分值为0~5.0分。5.0分为最高分,表示专家对企业某一指标的完成情况感到满意;反之,得最低分0分。统一规定,样本企业年度财务报表、社会责任书及可持续发展报告书中未予以披露的指标数值,按谨慎性原则统一评分为2.5。在获得第一轮评分后,各指标取平均值后再将结果发回专家团,专家们根据第一轮评分结果平均值进行再评分,收集结果后再计算平均值,多轮反复后得到较统一的答案。
3.3 碳风险预警模型的构建
设企业碳风险预警指标体系中含有s个指标数值,SVM的输入即为s维;判别企业碳风险状况的结果为t个(本研究中即风险高或风险低两种情况,则t=2),即输出为t维。则n个企业构成D={(xi,yi)|i=1,2,…,n}。对所有企业输入德尔菲法评分的最终结果,并定义碳风险高企业标签为-1、碳风险低企业标签为1,输入样本企业的数据及标签用以训练模型与确定参数,采用网格搜索法与交叉验证法来确定最优参数组C和g,网格搜索法即将参数组的所有可能取值来训练模型进行参数寻优。用交叉验证法来确定模型的预测正确率,即将样本总体均分为v组,用其中的某一组作为验证样本,其余的v-1组作为样本,如此循环v次,最终准确率由v次验证正确结果总和数除以样本总数确定。取使训练平均准确率最高的参数组作为最优参数组,最后得到可用于判定实验企业碳风险状况的预测模型。
4 实证分析
选取被《上市公司环境信息披露指南》认定为重污染行业内的上市公司,数据来源为其公布的2012年度财务报表与社会责任报告或可持续发展报告书,并以某企业2012年数据作为实验样本,判断该企业是否具有碳风险。选取的样本企业主要满足以下条件:来自重污染工业各行业、2012年碳风险的相关数据可得,具体见表2。选取2012年作为评估基准年出于两方面的考虑:(1)在2012年,越来越多的企业公布了与节能减排信息密切相关的社会责任报告或可持续发展报告书,便于原始数据的收集;(2)2012-2014年有3年的间隔时间,以2012年的数据评估企业碳风险,以企业碳风险现状来验证模型评估结果的准确性,保证预警系统可以在提前3年的情况下对企业碳风险状况进行评估。
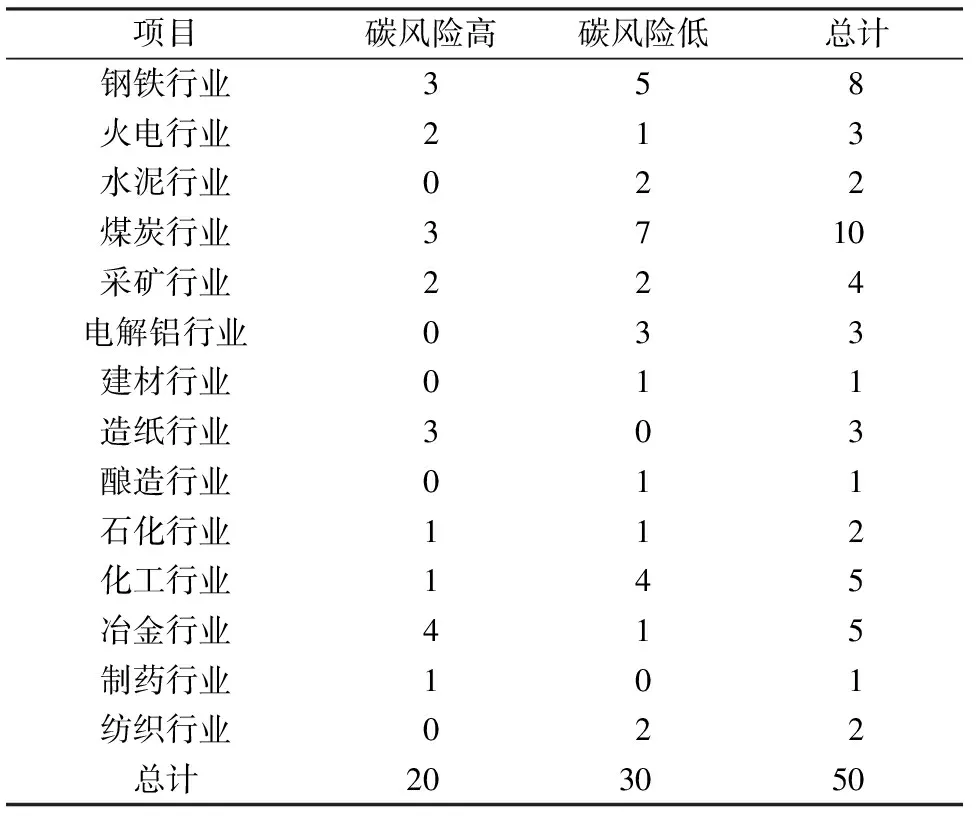
表2 样本企业行业分布Table 2 The industry distribution of sample enterprises
运用Matlab软件加载Libsvm工具箱对样本企业数据及实验企业数据进行处理,由于建立的企业碳风险预警指标体系中含有18个指标,SVM的输入即为18维;判别企业碳风险状况的结果为2个(1/-1,即碳风险低/高),即输出为2维,50个企业构成了模型的样本集,即输入18×50的样本数据矩阵。定义2012年后被披露因淘汰落后装备、推进节能环保和结构调整改造而导致大量营业外支出或由于重大污染事件而关停、调整的20家企业标签为-1,视为因企业在发展节能减排过程中陷入严重碳风险;其余30家企业标签为1。由样本企业的数值建立svmtrain与svmpredict运算。
将各样本的18个指标数值输入模型,并按对应顺序输入标签1或-1,相互对应的样本数据与其标签顺序构成了SVM模型的分类标准用于训练模型的参数。由于可参考的最优参数值很少,因而要采用较大的取值范围。选取C为[10-4,104]、g为[2-10,210],每次参数增加的步长均取0.05,采用五折交叉验证(即进行5次迭代)。
结果显示,经过5次迭代后,最高单次预测准确率可达98%,最高平均准确率为95%,达到最高平均准确率的参数组(C,g)为(1.021 9,1.525 9)。当log2g达到0.609 7时、log2C在(0.031 25,0.200 00)内,预测准确率均为95%。模型显示,在g∈(1.525 9,1.527 0±ε)内(其中,ε为无穷小量,以保证数据估计值的准确性),对应的C均可保证95%的预测准确率,但当g≥(1.527 0±ε)时,预测准确率下降;当log2C到达定点0.200 00后,C的增加不再对准确率造成影响。模型默认选取第一次使得准确率最高的参数组为默认参数,因而(1.021 9,1.525 9)为最佳参数组。在运行结果中显示,g对提高预测准确率的影响比C更显著。利用模型参数寻优得到的最优参数组,随机选取样本中的30家企业作为训练样本、另20家企业作为验证样本带入模型,验证结果见表3。
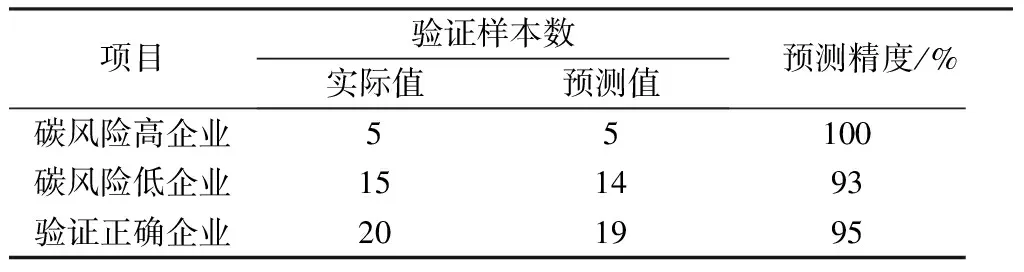
表3 模型验证结果Table 3 The validation result
将实验企业的数值输入模型,预测结果显示实验企业预测碳风险标签为1,即预测实验企业的碳风险水平较低,节能减排技术推进效果较好;这与实验企业2012年至今发展状况良好,节能减排成果显著的情况是一致的。
与SVM模型相比,同样是在5次迭代、学习步率0.05、对准确率要求设定为95%情况下,BP神经网络预测虽然耗时较短,有时只需迭代2~3次即可达到95%的准确率要求,最高效度能达到86.286%,但由于每次运行都采用随机参数进行预测,使得效度不稳定,难以固定下来作为一个可推广的模型使用。这进一步体现了SVM模型在预测碳风险方面的优越性:稳定、可推广、准确度及信效度高等。
5 结 语
采用SVM模型对企业碳风险进行预警,该方法能很好地处理碳风险评价因子与碳风险困境之间的非线性关系,不仅预测结果准确、操作简便,并且使用范围不局限于重污染工业企业,具有很好的推广性。从预测结果来说,经过SVM模型验证的碳风险水平较低的企业普遍具有以下特征:
(1) 已经初步具备企业碳风险意识。树立和提高碳风险意识是从企业基层员工到管理层共同防范碳风险的第一步,碳风险如能较早识别和应对,其对于企业的消极影响是可控的,如企业缺乏碳风险意识,则可能导致企业蒙受巨大损失。
(2) 碳政策研究力度投入较大,对政策敏感度与配合度较高。影响重污染工业企业碳风险的很大一个因素即碳管制政策,因而企业对相关政策导向及趋势的敏感度、碳政策研究的投入力度直接推动了企业在管控碳风险角度上化被动为主动。积极主动地配合相关政策,推动低碳经济发展对重污染工业企业的碳风险管控有着非常重要的意义。如果企业能满足较高的强制性政策达标情况和较低的违规罚没情况,可以合理推测在政策收紧时,企业也有回转的余地,不会受到极大影响,反之亦然。
(3) 已经或尝试建立较健全的碳排放或环境污染事件的应急处理机制。健全完善的应急处理机制可有效降低碳风险对企业的负面影响,同时应急处理机制也体现了企业对于碳风险的管控意识水平以及企业处理类似紧急事件的能力。从预测结果来说,预测碳风险较低的企业普遍已基本设立了碳风险应急处理机制、具备了一定的管控能力。
(4) 致力于优化能源结构和技术创新提高能源利用效率。碳排放权交易市场的形成和兴起是企业面对碳管制政策的新途径,但随着管制政策收紧,碳排放权交易规模将被压缩。企业要想管控碳风险和获得长期稳定发展,根本举措就是优化企业生产耗能结构、充分研发新技术来提高能源的利用效率。
(5) 积极参与碳信息披露制度。碳信息披露是利用报表对企业碳利用效率和碳排放强度进行量化记录计量,规范细致的碳信息披露有利于企业明确碳自身风险程度和承担的社会责任。现阶段来说,企业多处于被动披露阶段,披露信息质量不高。相比之下,碳风险水平较低的样本企业碳信息披露更全面与细致。
(6) 产品结构较合理,低碳产品、绿色产品竞争力强。由于面对的是难以量化与预测、变幻莫定的市场需求,本研究采用了竞争力指标来体现企业及其产品在未来的竞争力。尽管未来市场的需求难以量化确定,但可以确定的是,未来市场对于低碳产品、绿色产品的总需求是呈上升趋势的。企业具备低碳产品或绿色产品的生产能力,或是已有了较合理的产品结构,体现了企业对于管理碳风险的重视程度,对于应对未来市场的需求非常具有竞争力。
囿于条件限制,本研究样本数据不排除客观可能存在与事实不符的情况从而影响研究结论的真实性,但不影响本研究提出的方法在企业中的应用。本研究也存在着难以避免的不足,如德尔菲法量化指标数值时带有的不确定性、未能考虑部分行业产能过剩等实际情况等,对于企业碳风险的评价与预警仍有待进一步深入的研究。
[1] INC/FCCC.联合国气候变化框架公约(UNFCCC)[R].里约热内卢:联合国,1992.
[2] 朱俊,周树勋,陈通.建立环境风险防范体系 加强对环境风险的管理[J].环境污染与防治,2007,29(5):387-389.
[3] 邵超峰,鞠美庭.环境风险全过程管理机制研究[J].环境污染与防治,2011,33(10):97-100.
[4] 李力.全球低碳发展评估及中国低碳发展的实现途径[J].环境污染与防治,2014,36(12):97-101.
[5] 周志方,肖序.基于环境风险评估技术的企业环境负债确认、预防与控制研究[J].环境污染与防治,2011,33(3):107-110.
[6] CHEN Xiaohong,LIU Xiang,HU Dongbin.Assessment of sustainable development:a case study of Wuhan as a pilot city in China[J].Ecological Indicators,2015,50(3):206-214.
[7] LENTON T M.What early warning systems are there for environmental shocks?[J].Environmental Science & Policy,2013,27(1):60-75.
[8] 毛小苓,刘阳生.基于非财务变量国内外环境风险评价研究进展[J].应用基础与工程科学学报,2003,11(3):266-271.
[9] 袁广达.基于环境会计信息视角下的企业环境风险评价与控制研究[J].会计研究,2010(4):34-41.
[10] 朱发根,刘拓,傅毓维.基于非线性SVM的上市公司财务危机预警模型研究[J].统计与信息论坛,2009,24(6):49-53.
[11] 谢赤,罗长青,王蓓.财务困境预警SVM模型的构建及实证研究[J].当代经济科学,2007,29(6):96-100.
[12] HE Benlan,SHI Yong,WAN Qian,et al.Prediction of customer attrition of commercial banks based on SVM model,ITQM[J].Procedia Computer Science,2014,31:423-430.
[13] 肖序,熊菲,周志方.流程制造企业碳排放成本核算研究[J].中国人口·资源与环境,2013,23(5):29-34.
[14] 魏东,岳洁,王璟珉.碳排放权交易风险管理的识别、评估与应对[J].中国人口·资源与环境,2012,22(8):28-32.
[15] 潘岳,朱继业,叶懿安.江苏省碳排放影响驱动因素分析——基于STIRPAT模型[J].环境污染与防治,2014,36(12):104-109.
[16] 杨花,杜斌,吕锋骅,等.基于IPCC排放清单和LEAP模型的山西省CO2排放研究[J].环境污染与防治,2014,36(3):103-109.
[17] CORES C,VAPNIK V N.Support-vector network[J].Machine Learning,1995,20(3):273-297.
[18] VAPNIK V N.The nature of statistical learning theory[M].New York:Springer,1995.
[19] KEERTHI S,LIN C J.Asymptotic behaviors of support vector machines with gaussian kernel[J].Neural Computation,2003,15(7):1667-1689.
[20] 李建磊,徐晓明,金浩.层次分析法在河北省可持续发展水平评价中的应用[J].河北工业大学学报,2005,34(5):31-36.
[21] 冷克平,霍众.灰色关联分析在平衡计分卡战略性业绩评价模型中的应用研究[J].现代管理科学,2005(8):34-36.
[22] 许树柏.层次分析法原理及其应用[M].天津:天津大学出版社,1988.
猜你喜欢
数学物理学报(2022年5期)2022-10-09
中学生数理化·高一版(2021年2期)2021-03-19
今日农业(2019年12期)2019-08-13
计算机应用(2018年12期)2019-01-08
商周刊(2018年26期)2018-12-29
知识经济·中国直销(2018年8期)2018-08-23
现代园艺(2017年22期)2018-01-19
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
火控雷达技术(2016年3期)2016-02-06
