
基于TMS320C6678 DSP的程序优化技术的研究
2016-03-10 00:16海军驻第七一六研究所军代室王国刚
电子世界 2016年24期
海军驻第七一六研究所军代室 王国刚
江苏自动化研究所 杨云高
基于TMS320C6678 DSP的程序优化技术的研究
海军驻第七一六研究所军代室 王国刚
江苏自动化研究所 杨云高
基于TMS320C6678 DSP的程序优化是一个完整的技术体系。程序优化首先要对所用DSP的架构体系和存储资源有一个清晰的认识,并对该架构DSP的汇编语言有一定的了解,再合理的利用DSP底层存储资源分配、C语言的优化、软件流水以及编译器的优化等方法达到预期的优化效果。
DSP程序优化;存储资源分配;C语言的优化;软件流水;编译器的优化
0 引言
数字信号处理(Digital Signal Processing,简称DSP)技术发展迅速,现已广泛应用于图像处理技术、通信、自动控制系统等许多新技术领域[1]。美国德州仪器公司推出了一款基于KeyStone多核心架构体系的高性能数字信号处理器TMS320C6678。该处理器支持定点/浮点混合运算,每个芯片都有8个C66x内核,每个内核得最高工作频率可以达到1.25GHz,即单个TMS320C6678芯片最高能够提供相当于10GHz的内核频率,其单精度浮点运算能力理论上可达160G FLOPS(Floating-point Operations Per Second)[2]。因此,TMS320C6678越来越多被应用于有较高的实时性要求的超高性能计算当中。同时,在这些超高性能的计算当中,实时性是一个必然要解决的问题,这就需要对TMS320C6678 DSP的程序进行优化。
1 TMS32C6678 DSP VLIW架构及其存储资源的概述
对TMS320C6678 DSP的程序进行优化,归根结底就是通过多种优化方法充分利用芯片内部的各个功能单元和存储资源,均衡每个功能单元的计算载荷,合理的分配不同的存储资源,更好的发挥该DSP的性能。所以,要对该DSP的架构有一个深入的了解。
TMS320C6678 DSP的VLIW(Very Long Instruction Word,超长指令字)架构包括两个通用寄存器文件系统、八个功能单元和两个数据通道系统[3]。两个数据通道系统、两个寄存器文件系统和八个功能单元各自内部之间都几乎或者完全相互独立,每个功能单元都能够在一个时钟周期内执行一条指令,而且不同的功能单元和寄存器都可以在同一时刻执行各自的操作。这个机制是DSP程序优化技术中软件流水实现及指令并行的重要因素之一。
TMS320C6678的片上存储资源共包括以下几种[4]:每个C66x核心都配置有32KB的一级程序存储空间(L1 Program Memory,简称L1P)、32KB的一级数据存储空间(L1 Data Memory,简称L1D)、512KB的二级存储空间(L2 Memory,简称L2)。TMS320C6678还有4096KB大小的共享存储空间(Multicore Shared Memory,简称MSMCSRAM),八个核心共享该存储空间,默认配置为二级共享存储空间,也可以配置为三级共享存储空间。
2 基于TMS320C6678 DSP程序优化的技术
2.1 底层存储资源的合理分配
底层存储资源的分配是DSP程序优化需要考虑的第一种方法,是每个DSP程序及其优化必须要做的工作。底层存储资源的合理分配能够使DSP程序优化事半功倍,同时也能够增强程序的稳定性;反之,底层存储资源分配不合理,则会导致DSP程序因为资源冲突而崩溃。
进行底层存储资源分配时,应该站在系统应用层的角度,优化存储结构,合理分配资源。
(1)对实时性较强的程序,其代码、变量及经常访问到的数据尽量放到片上资源之中。
一般情况下,都会将各自的代码放到各自的L2存储空间中。因为该空间可以全部配置成RAM,能够提高指令提取的效率。若代码量或数据量较大,关键代码段和数据可以通过#pragma CODE_SECTION()和#pragma DATA_SECTION()伪指令分配到片上资源之中。
(2)根据代码量和数据量等因素,合理分配Cache和RAM的比例关系,提高Cache的利用率[6]。
一般情况下,为了提高程序运行的效率,在TMS320C6678上面进行程序设计时,L1P和L1D都全部配置为Cache,L2则根据程序大小合理分配RAM和Cache的关系[7]。
(3)各核共享的程序和数据应当存放到共享缓存中,同时一定要注意存储一致性的问题[8]。
TMS320C6678的八个核心共同访问共享存储空间MSMC时,会存在存储一致性的问题。可以通过合理利用CACHE_invL1d()和CACHE_wbL1d()等函数强制实现多核之间的存储一致性。
(4)不经常访问或者访问具有随机性的代码和数据,可以分配到不被Cache的内存空间中和者被L2 Cache的片下的存储资源中,降低对Cache性能的影响和对片上资源的占用。
2.2 C语言的优化
(1)采用固有操作Intrinsic[3]
固有操作就是直接利用DSP的功能单元实现一些特殊的操作。固有操作与函数调用不同,不会产生跳转。所以固有操作在提高某些操作运行效率的同时,省去了程序跳转的时间空隙,能够有效地实现DSP程序的优化。
SIMD中两条最常用指令就是LDDW和STDW(执行64bits的取数和存数),若程序中我们采用的数据单元为8位、16位或者32位,通过SIMD就能够实现一次读取或者写入8个、4个或者2个操作数,相当于.D功能模块在一个指令周期内便实现了原本要多个指令周期和延迟间隙才能实现的操作。SIMD的要点是数据单元应尽可能小、循环应展开并且数据应边界对齐。
(3)手动展开循环结构体(UNROLL LOOP)
UNROLL的作用就是将单次循环体的操作,强制变为展开因子的倍数,降低总的循环次数,强制为DSP功能单元的并行操作创造条件。当编译器反馈内核两侧功能单元的使用严重不平衡时,可以选择使用UNROLL命令。UNROLL运行的前提是循环体的循环次数能够整除展开因子。
2.3 软件流水(Software Pipeline)
CPU每执行完一次指令具有一定的为延迟间隙,一条LOAD指令有4个延迟间隙,一条单精度浮点运算有3个延迟间隙,一条跳转指令有5个延迟间隙。在循环体里面,延迟间隙会显著降低程序的效率。可以采用软件流水解决延迟间隙的问题。
对于大部分DSP应用程序来说,绝大部分CPU时间是消耗在循环体当中,因此代码优化过程中最重要的是对循环的优化。在C6000系列的DSP中,循环执行的性能取决于软件流水的实现程度。使用编译器优化选型-O3或者-O2,能够使C编译器自动对循环代码实现软件流水。图1是DSP软件流水和非软件流水程序运行效率对比示意图:
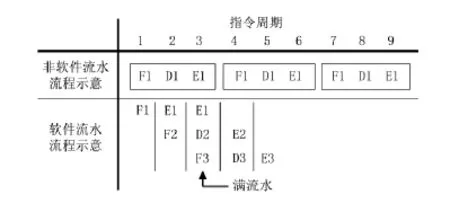
图1 软件流水与非软件流水的程序运行效率对比示意图
其中,F代表取指,D代表译码,E代表执行指令。从图4中可以看出,简单的软件流水也能够通过排列流水操作和并行运算有效地提高程序的运行效率。
2.4 编译器的优化
秋季播种,以幼苗越冬,翌年春季收获的菠菜,又称根茬菠菜、冻菠菜、白露菠菜。一般当地日平均气温17~19℃时为播种适期,选用晚熟或不易抽薹的品种10月下旬至11月上旬栽植,翌年春天收获。其他地区播种期可随纬度的不同做适当调节。
编译器优化的方法主要分为两种:设置编译器选项和告知编译器信息。编译器选项的设定能够启动文件级的优化,已经可以满足大多数应用的需求。告知编译器信息则是代码级的优化,合理的应用能够大幅提升关键代码段的执行效率。
2.4.1 编译器选项
编译器选项较多,下面仅列出常用的几个:
(1)在调试选项中,选择-symdebug none选项,表示程序运行过程中不再提供软件调试信息,如果选择-g选项,会增加调试信息,降低代码的并行度并产生额外的代码;
(2)选择-opt_level = -O3/-O2优化选项,能够启动对循环体的软件流水操作,消除未使用的全局赋值语句等,配合-pm实现文件级的优化;
(3)选择-mt选项,表示程序中没有使用别名计数,可以使编译器好的进行优化。
2.4.2 告知编译器信息
(1)#pragma MUST_ITERATE()伪指令
循环次数的判断也是导致循环执行效率低下的因素。因为循环体每执行完一次,都要对循环次数进行判断,然后根据判断结果跳转执行相应的语句,判断和跳转本身会消耗多个指令周期和延迟间隙,产生额外操作,降低程序的实时性。可以通过启用#pragma MUST_ITERATE()命令,传递循环次数的信息给编译器,编译器便能不需要判断循环次数而自动展开循环体,实现软件流水,免去判断和跳转的时间消耗;
(2)restrict关键字
变量之间的相关性对程序优化有较大的影响,完全不相关的变量更利于提高编译器对程序的优化效率。为了帮助编译器变量之间的相关性,我们可以为相互独立的指针、引用和数组变量加上restrict关键词,这样可以向编译器保证过这些变量是相互独立的,他们指向的存储区域没有重叠或者冲突。
(3)_nassert()声明
_nassert()声明的作用就是告诉编译器括号内的表达式是成立的,从而暗示编译器可以采用某种优化措施。
3 实例演示
采用不同的优化方法对下面一段代码进行优化,并在TI提供的评估板TMDS EVM6678L上进行实例的调试,测量记录针对不同的优化方法,执行该段代码所消耗的时钟周期数。
char adata[100000];
char bdata[100000];
int i = 0;
for(i=0;i<100000;i++)
{
adata[i]= i/4+1;
bdata[i]= adata[i]+1;
}
优化方法1:将所有变量、代码等都放到DSP TMS320C6678的片下存储资源DDR3中;
优化方法2:在优化方法1的基础上,选择-opt_level = -O3优化选项,启动对循环体的软件流水操作;
优化方法3:在优化方法2的基础上,将adata和bdata两个数组都利用DATA_ALIGN命令强制进行128位边界对齐,并在程序中利用_nassert()声明adata和bdata数组都是128位边界对齐的,最后将i/4改变为intrinsic操作_rcpsp(4)*i;
优化方法4:在优化方法3的基础上,将adata和bdata两个数组的128位边界对齐命令改为32位边界对齐;
将所有的变量、代码等都放到DSP TMS320C6678的片上存储资源L2 SRAM中,重新采用优化方法2到4进行优化测试。
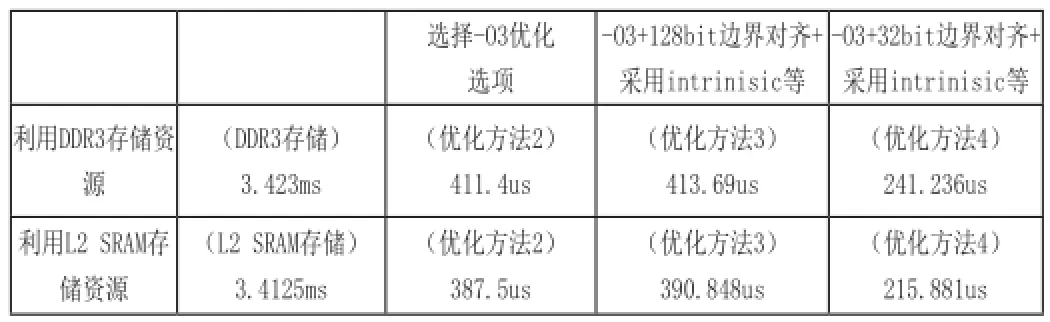
从上边中可以实例演示的结果可以得出三个结论:
(1)相同的优化方法,利用DDR3存储资源时程序的运行效率要低于利用L2 SRAM存储资源的运行效率;
(2)优化的方法很多,组合方式也会随着代码的不同而不同,要合理的选择不同的优化方法,否则可能会达不到预期的优化效果;
(3)合理的利用本文中介绍的优化方法,能够显著的缩短代码执行所消耗的时间,提高应用程序的实时性。
4 结束语
TMS320C6678 DSP一款高性能数字信号处理芯片,充分发挥该DSP的运算潜能对后续数字信号处理技术的理论研究有一定的推动作用。本文首先对TMS320C6678 DSP的架构及存储资源进行了介绍,然后从底层存储资源的合理分配、C语言的优化、软件流水及编译器的优化等方面较为全面的介绍了该DSP能够采用的程序优化的方法。最后实例表明本文中的程序优化方法明显缩短了代码运行的效率,提高了程序运行的实时性,对现有数字信号处理技术的工程实践具有一定的借鉴意义。
[1]苏涛,吴顺君,李真芳等.高性能DSP与高速实时信号处理[M].西安:西安电子科技大学出版社,2002.
[2]牛金海,TMS320C66x KeyStone架构多核DSP入门与实例精解[M].上海:上海交通大学出版社,2014.
[3]TMS320C6000Programmer’s Guide[D].Texas Instruments Inc.,2011.
[4]TMS320C6678 Data Manual[D].Texas Instruments Inc.,2014.
[5]TMS320C66x DSP CorePac User Guide[D].Texas Instruments Inc.,2013.
[6]Multicore Programming Guide[D].Texas Instruments Inc.,2012.
[7]TMS320C66x DSP Cache User Guide[D].Texas Instruments Inc.,2012.
[8]黄安文,张民选.多核处理器Cache一致性协议关键技术研究[J].计算机工程与科学,31(2009):104-108.
王国刚,男,工程师,研究领域为自动控制。
杨云高(1988—),男,江苏连云港人,研究领域为嵌入式控制和软件设计。
Research on program optimization technique based on DSP TMS320C6678
Wang Guo-gang1,Yang Yun-gao2
(1.Naval Representative Of fi ce of the 716 Institute of CSIC,Lianyungang 222061,China;2.Jiangsu Automation Research Institute of CSIC,Lianyungang 222061,China)
Program optimization based on DSP TMS320C6678 is a complete technical system.To optimize the DSP program,we must have a clear vision of the architecture and the memory resources of the DSP,and understand the assembly language of the exactly DSP.Then we can have the ability to apply different methods appropriately to achieve the desired optimization results.The methods include distribution of the memory resources,optimization of C code,software pipeline,optimization of the complier,and so on.Also,DSP program optimization is the process of combining theory with practice.
DSP program optimization;distribution of the memory resources;optimization of C code;software pipeline;optimization of the complier.
猜你喜欢
智能计算机与应用(2021年6期)2021-12-17
综艺报(2020年21期)2020-11-30
文苑(2020年10期)2020-11-07
铁道通信信号(2020年7期)2020-02-06
电脑爱好者(2019年17期)2019-10-30
计算机与网络(2019年9期)2019-10-21
天津诗人(2017年2期)2017-11-29
视野(2015年6期)2015-10-13
组合机床与自动化加工技术(2014年10期)2014-03-01
海峡姐妹(2014年5期)2014-02-27
