
边界Fisher分析的一种改进
2016-03-10 00:16:43安阳工学院计算机学院吴朝霞
电子世界 2016年24期
安阳工学院计算机学院 吴朝霞 郭 强
边界Fisher分析的一种改进
安阳工学院计算机学院 吴朝霞 郭 强
边界Fisher分析(MFA)是一种典型的监督子空间嵌入特征提取方法。该算法解决了由于线性判别分析高斯假设所引起的不足,通过最大化类内紧凑度和类间区分度来获取映射矩阵。该算法虽然相对与线性判别分析已经有了很大的提高,但是在算法执行过程中一个关键的部分,求取每一个样本点的近邻,MFA处理方法简单,求得结果并不能很好的表征近邻关系,所以针对此点进行改进,用一种比较好的方法代替该过程.通过在ORL,耶鲁样本上的人脸识别实验,验证了该方法非常有效,相对于原始的MFA算法又有了明显的提高。
边界Fisher分析;人脸识别;特征提取
0 引言
在现实条件下,人脸识别原始数据都是高维样本,而高维样本并不适应于人脸识别,因为高维数据鲁棒性差、计算复杂度高,因而在人脸识别中,降维也就是特征提取是必不可免的。二十多年来,对于特征提取,国内外学者提出了各种各样的方法。最经典最基本的特征提取算法是主成份分析(PCA)[1]和线性判别分析(LDA)[2]。针对于以上经典的算法进行了大量的改进,例如MPCA[4],2D-LPP[5],DATER[6]改善了小样本问题。边界判别分析(MFA)考虑到LDA的不符合实际的高斯假设问题,应用边界样本进行分类。邻接保留嵌入(NPE),无监督判别映射(UDP),,局部判别嵌入(LDE)[10]等都对邻接矩阵应用的一些改进。
以上提高的区分分析方法,都可以表示做图嵌入[的形式,通过颜等人提出的图模型我们发现以上这些算法降维后的特征应用到人脸识别上效果的不同,完全在于表示各点近邻关系的图的构建方法的不同,所以基于这一点我们对MFA算法做了大量的实验,并找出了一种更好的查找近邻的方法,应用到MFA的图构建过程,实验证明该方法是有效并且可行的。
1 边界Fisher分析
利用图嵌入框架,提出了边界Fisher分析。此后,MFA算法得到进一步的研究和不断的改进,下面我们简单介绍边界Fisher分析。
MFA应用了图嵌入框架的思想,它构建了两个关键性的表示近邻关系的图:一个叫做本质图,用来表征类内紧凑度,记为Gc。另一个叫做惩罚图,用来表征类间区分度,记为Gp。Gc描述了同类数据点的近邻关系,每个数据点连接了k1个同类中与之最近的点。Gp描述了类和类之间的边界关系,每个数据点连接了k2个其他类别中与之最近的点。

类内散度表示为:

类间散度表示为:

其中:

MFA算法的最佳投影轴w通过如下边界Fisher判别准则求出:

。
2 对MFA算法的改进
在求取近邻过程改为先判断两个样本脸的每一对相对应的列是否近邻,并构建两个人脸的每一个相应列的近邻图,然后查看近邻图判断两个脸是否有足够的列为K近邻,从而确定两个人脸是否为近邻,通过该方法求取近邻并应用到该算法中,进行特征提取。
具体实施过程如下:
(1)利用主成成份分析降维:首先把样本投影到PCA子空间,用WPCA表示PCA的投影矩阵。
(2)构造类内散布矩阵W、类间散布矩阵Wp:
其中p为大于1小于m的值。
(3)将上过程求得的构造类内散布矩阵W、类间散布矩阵W p代入到原始的边界Fisher判定准则中,解下边最小化问题。
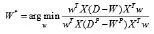
3 实验和结果
为了上面提出的RMFA算法的分类性能,基于ORL和yale两个标准人脸数据库, 本论文对LDA和MFA算法实施了系统的对比实验。在整个实验过程中,所有的人脸图像样本被标准化到32×32维。除此之外,在后续的实验中我们利用表示随机抽取的每个人的m个人脸图像进行训练并且使用剩下的n个人脸图像用来测试。对于三种降维算法,随着参与学习样本数的增加识别率也不断的提高。在同等条件下MFA识别率高于LDA是由于LDA算法本身的缺陷,LDA假设每个类的观测数据点都服从高斯分布,现实中确并非如此。
安阳工学院青年基金项目群体行为识别研究(QJJ2015019);河南省教育厅重点研究项目(15A430012)。
猜你喜欢
车主之友(2022年4期)2022-08-27 00:57:12
作文中学版(2022年1期)2022-04-14 08:00:34
无线互联科技(2020年22期)2021-01-11 13:52:34
弹箭与制导学报(2020年2期)2020-09-01 02:08:56
学生天地(2020年31期)2020-06-01 02:32:06
海峡姐妹(2019年12期)2020-01-14 03:24:40
传感器与微系统(2018年7期)2018-08-29 00:44:42
自动化学报(2017年4期)2017-06-15 20:28:55
计算机工程(2015年8期)2015-07-03 12:19:07
计算物理(2014年1期)2014-03-11 17:00:18
