
基于项目近邻的约束概率矩阵分解算法
2016-02-27 00:43:05张天杰曹苏燕闫世洋
计算机技术与发展 2016年10期
张天杰,曹苏燕,闫世洋
(南京邮电大学 计算机学院,江苏 南京 210003)
基于项目近邻的约束概率矩阵分解算法
张天杰,曹苏燕,闫世洋
(南京邮电大学 计算机学院,江苏 南京 210003)
在个性化推荐领域,协同过滤是目前最为成功应用最为广泛的推荐技术之一。约束概率矩阵分解算法便是一种基于模型的协同过滤算法,它能有效地面对推荐系统中遇到的海量数据问题,保证推荐的实时性。然而,传统的约束概率矩阵分解算法并没有考虑用户或者项目之间的关系,使得算法的推荐质量受到影响。为进一步提高算法推荐的质量,文中在约束概率矩阵分解算法模型的基础上引入项目近邻关系,通过结合从项目简介中提取的固有特征和用户评定的标签特征两方面信息来确定项目的最近邻居集合,并将该邻居集合融合到基于约束的概率矩阵分解模型中产生推荐。通过在真实的数据集上的验证结果表明,该算法能够更有效地预测用户对项目的评分,提高算法的推荐精度。
推荐系统;协同过滤;约束概率矩阵分解;项目近邻
0 引 言
在推荐系统[1-3]领域,协同过滤推荐(Collaborative Filtering)以其推荐策略简单、实用、适用对象多样的特性而备受青睐。根据使用策略的不同,协同过滤可以分为基于内存的协同过滤(Memory based)和基于模型的协同过滤(Model based)[4]。基于内存的协同过滤主要包括基于用户[5]和基于项目[6]两类,两者的重点分别为寻找相似的用户和项目。然而,基于内存的协同过滤对于用户项目评分矩阵的稀疏性比较敏感,并且随着系统用户、项目量的增大,计算量呈非线性增长趋势,不利于实时性推荐。基于模型的协同过滤推荐通过采用线下学习、周期性更新的方式对评分数据进行挖掘。目前,常见的基于模型的协同过滤方法有聚类模型方法[7]、贝叶斯网络[8]、矩阵分解[9]等。相比较基于内存的协同过滤算法,这类算法具有更好的扩展性,在面对海量数据时推荐更具实时性。约束概率矩阵分解算法[10](Constrained Probabilistic Matrix Factorization,CPMF)便是一种基于模型的协同过滤推荐的经典算法,其可以在线性时间内产生推荐,相比较了其他推荐策略能更有效地应对评分稀疏、海量数据等问题[10]。
然而,传统的CPMF算法模型并未考虑用户或者项目之间的关系,算法仅使用了用户对项目的评分信息,忽略了很多额外的信息,从而影响了实际的推荐效果。近年来,学者们[11-13]从评分矩阵信息以外的信息中挖掘用户或项目的关系并将其用于协同过滤算法中,从而实现对原有算法推荐效果的提升。
考虑到项目的关系往往比用户的关系更具稳定性,不需要频繁更新,对于大型系统更具优势[6],文中从项目角度出发,提出了一种基于项目近邻的约束概率矩阵分解算法(Item-neighborhood-based Constrained Probabilistic Matrix Factorization,ICPMF)。在ICPMF中,结合从项目简介中提取固有特征和用户对项目评定的标签特征两方面信息来挖掘项目之间相互影响的关系,将其量化为项目之间的相似度,通过相似度的大小来确定项目的近邻集合,并将该邻居集合融合到CPMF中实现推荐。
1 CPMF算法概述
约束概率矩阵分解算法是由Salakhutdinov等[10]提出的一种基于模型的协同过滤推荐策略,是一种潜在特征因子分解算法。该算法假设每个用户的兴趣只受几个潜在的特征影响,并假设这些特征向量符合均值为0的高斯先验分布,通过用户对项目的评分记录来学习获得每个用户和项目的潜在特征向量,最后利用得到的低维度的潜在特征向量矩阵计算出用户对项目的预测评分,进而产生推荐。CPMF能够通过线下学习潜在特征,线上直接使用学习到的潜在特征向量计算出用户对某个项目的预测评分,从而可以快速地为用户产生要推荐的项目集合。实验结果表明,CPMF在推荐准确性和抗稀疏性上和其他只使用用户-项目评分矩阵的协同过滤算法比较更具优势[10]。

(1)
其中,W∈RD×M为潜在相似约束矩阵,Wk为W的第k列;Y∈RD×N,Yi代表Y的第i列;I为指示函数,即如果用户i对项目k有评分,则Iik为1,否则Iik为0,当用户i没有评分时Ui=Yi。
根据以上的定义,已观察到的评分数据的条件概率定义如式(2)。
p(R|Y,V,W,σ2)=
(2)
其中,g(x)=1/(1+e-x)用于将预测评分区间映射到[0,1]上;Rij对应用户i对项目j的评分数据,通过函数t(x)=(x-1)/(K-1)将其从1到K映射到[0,1]区间上;Yi、Wk、Vj先验服从均值为0的高斯先验分布且相互独立,即如式(3)、(4)、(5)所示。
(3)
(4)
(5)
由贝叶斯推理可得,Y,V,W的后验概率分布如式(6)所示。
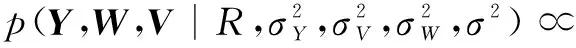
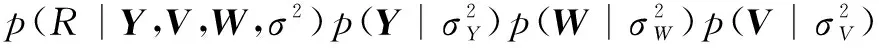
(6)
将式(3)、(4)、(5)带入式(6),对上述的后验概率取对数后并最大化后验,化简后等价于式(7)。
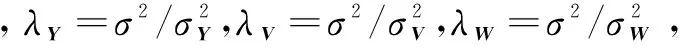
CPMF算法的图模型[10]如图1所示。

图1 约束概率矩阵分解模型
2 ICPMF算法描述
结合前文对于CPMF算法的描述,文中提出的ICPMF算法共包括两个过程:根据项目的简介和标签信息进行项目近邻选择;根据相似性假设将项目近邻关系融入到CPMF算法中进行特征向量学习,得到用户和项目的潜在特征向量。
ICPMF算法的两个过程皆可由线下计算完成,并进行周期性更新。
2.1 项目近邻的选择
一般而言,项目简介是系统为用户介绍特定的项目内容而设,如图书有图书内容简介、电影有剧情简介等。项目简介一般由一段简短的文本描述,是对项目特征的一段客观描述,通过项目简介用户可以了解项目的内容和它所具有的一些特征。所以作为为用户导航的一种方式,项目简介中往往蕴含了项目所具有的一些固有特性,即客观特性。标签则一般由使用过某个项目的用户给出,是用来描述信息的关键词,可以实现对信息的分类[14],对于每一个项目而言标签往往反映了用户对其使用过项目的主观感受,对于同样的项目而言,不同的用户可能会给出截然不同的标签,所以系统在收集用户为项目添加的标签信息时往往会附带标签的数量,从而能够更好地衡量标签对项目的价值。
考虑到以上情况,为了更好地构建项目的特征,进而寻找到更加合理的项目近邻关系,文中结合项目简介和用户对项目打的标签两方面数据对项目近邻进行计算和选择。具体的近邻选择过程包括:
(1)项目特征的选取和权重计算得到项目的特征向量;
(2)针对任一项目Itemj,根据特征向量计算其与系统中任一其他项目Iteml的项目间的相似度得到S(j,l);
(3)选择相似度最大的L个项目作为项目j的近邻Nj。
具体步骤如下:
Step1:对项目j的简介内容进行中文分词(文中采用IKAnalyzer中文分词器),过滤停止词和虚词,并对剩余的词进行词频统计。
Step2:以Step1统计出的词作为项目的一组特征,并根据对应的词频,计算TF-IDF[15]值作为词权重、计算项目标签的TF-IDF值作为标签的权重。TF-IDF计算公式如下:
(8)

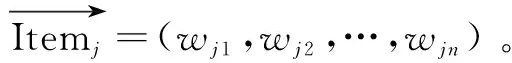
Step4:计算项目j与任一其他项目l的余弦相似度得到S(j,l),如式(9)所示,并选取和项目j相似度最大的L个项目集合作为项目j的近邻Nj。
2.2 ICPMF算法模型

其中,Nj为项目j的邻居集合;S(j,l)为项目j与项目l的相似度,即权重参数。
ICPMF算法的模型图如图2所示。

图2 ICPMF算法模型
具体地,对于项目的潜在特征先验概率可以表示为式(10),与式(7)类似通过贝叶斯推理,后验概率如式(11)所示,将式(2)、(3)、(4)、(10)带入后,进行对数处理并且最大化,除去常数项后等价于最小化公式(12)。
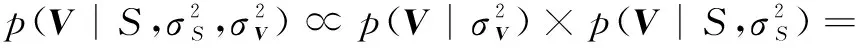
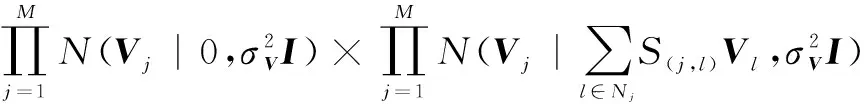
(10)
(11)
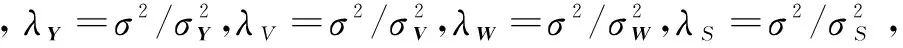
3 实 验
3.1 实验数据
为了探究文中所提算法的推荐效果,从豆瓣读书上抓取了真实的数据集作为实验数据。该数据集共包含三部分:34 250个用户对10 897本图书所做出的评分信息共258 111条,其中评分区间为[1,5]的整数;用户对图书添加的标签共23 084个,并附带了每个标签被用户添加的次数;评分信息中每本图书的简介信息,图书简介信息平均在300字左右。
实验中使用了开源的分词工具IK Analyzer 2012对图书简介信息进行分词并进行停止词过滤。实验采用10折交叉实验的方式,将总数据集分成10份,每次取1份作为测试集,剩余作为训练集,迭代10次后,取10次评价标准的平均值作为算法最终的评测结果。
3.2 评价标准
3.3 实验结果及分析
实验共包括两部分:(1)比较CPMF、TCPMF、ICPMF算法在不同的特征向量维度D下的推荐准确度情况,其中TCPMF为只使用标签信息计算项目近邻的ICPMF算法,ICPMF则融合了项目简介和标签两方面信息进行项目近邻计算。(2)测试参数λS对于ICPMF的影响。实验中设定所使用到的参数λY=λV=λW=0.001。
图3为三种算法在不同的特征维度D下的推荐准确度情况,其中TCPMF和ICPMF的项目近邻个数L=25,参数λS=5。

图3 不同特征向量维度D下各算法结果比较
由图3可知,融入了项目近邻信息的ICPMF和TCPMF的推荐准确度明显好于CPMF,ICPMF好于TCPMF,这说明文中将项目近邻关系融入CPMF算法进行推荐的有效性,同时也表明在项目近邻计算时融合从项目简介中提取固有特征和标签特征这两方面信息进行项目近邻计算的合理性。
图4比较了不同的λS取值对ICPMF算法的影响,实验中将λS的值分别设为0.1,0.5,1,5,10,25,并设用户近邻个数L=25,特征向量维度D=10。
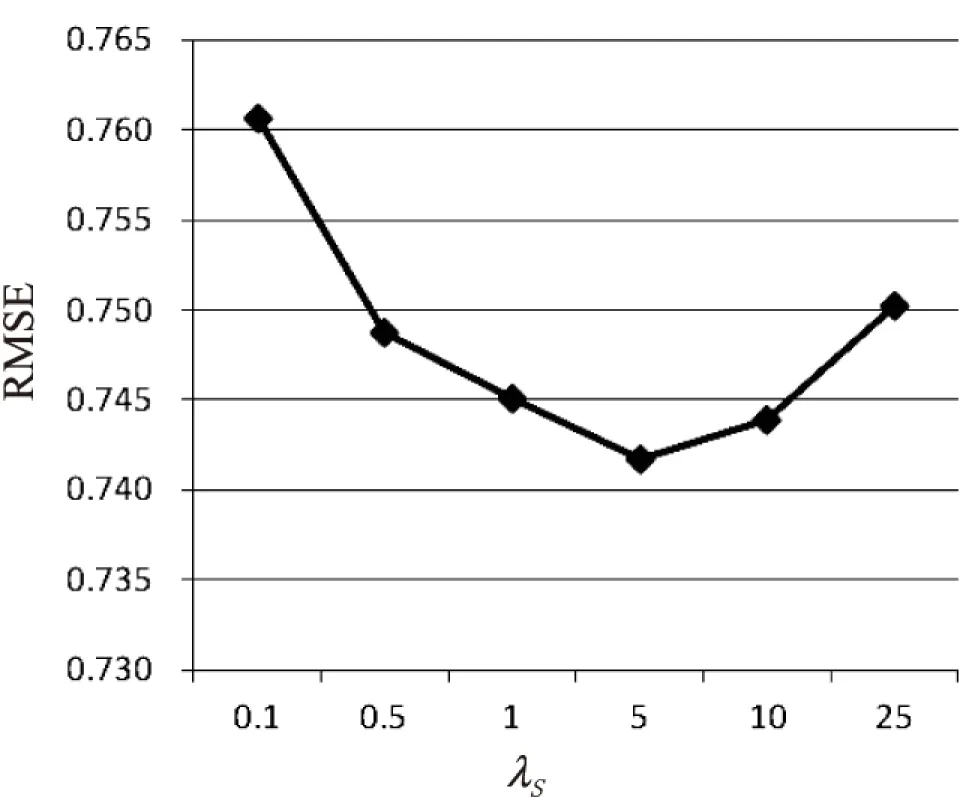
图4 λS对ICPMF的影响
由图4可知,λS对ICPMF的推荐准确度产生了较明显的影响,当λS在[0.1,5]上变化时,ICPMF的推荐准确率随着λS的增大而提高,当λS大于5时算法的准确率随之下降,由此可知项目近邻的引入对改进CPMF算法的有效性。
4 结束语
文中通过结合项目简介和用户为项目添加的标签两方面信息来挖掘系统中项目的近邻关系,并将该近邻关系融入CPMF算法中进行评分预测。在真实的数据集上的实验结果表明,提出的方法和传统的CPMF算法相比能够有效地提高推荐算法评分预测的准确度,进而验证了文中项目近邻关系计算方法的合理性和将此近邻关系融入CPMF算法的有效性。然而,实验中也发现,训练过程中存在特征向量初始值设置问题以及如何防止模型过拟合问题,这些值得进一步研究。
[1]RicciF,RokachL,ShapiraB.Introductiontorecommendersystemshandbook[M].US:Springer,2011.
[2] 王国霞,刘贺平.个性化推荐系统综述[J].计算机工程与应用,2012,48(7):66-76.
[3] 任 磊.推荐系统关键技术研究[D].上海:华东师范大学,2012.
[4] 刘士琛.面向推荐系统的关键问题研究及应用[D].合肥:中国科学技术大学,2014.
[5]AdomaviciusG,TuzhilinA.Towardthenextgenerationofrecommendersystems:asurveyofthestate-of-the-artandpossibleextensions[J].IEEETransactionsonKnowledgeandDataEngineering,2005,17(6):734-749.
[6]SarwarB,KarypisG,KonstanJ,etal.Item-basedcollaborativefilteringrecommendationalgorithms[C]//Proceedingsofthe10thinternationalconferenceonworldwideweb.[s.l.]:ACM,2001:285-295.
[7]O’ConnorM,HerlockerJ.Clusteringitemsforcollaborativefiltering[C]//ProceedingsoftheACMSIGIRworkshoponrecommendersystems.UCBerkeley:ACM,1999.
[8]MiyaharaK,PazzaniMJ.CollaborativefilteringwiththesimpleBayesianclassifier[M]//PRICAI2000topicsinartificialintelligence.Berlin:Springer,2000:679-689.
[9]GoldbergK,RoederT,GuptaD,etal.Eigentaste:aconstanttimecollaborativefilteringalgorithm[J].InformationRetrieval,2001,4(2):133-151.
[10]MnihA,SalakhutdinovR.Probabilisticmatrixfactorization[C]//Procofadvancesinneuralinformationprocessingsystems.[s.l.]:[s.n.],2007:1257-1264.
[11]MaH,YangH,LyuMR,etal.SoRec:socialrecommendationusingprobabilisticmatrixfactorization[C]//Procofinternationalconferenceoninformation&knowledgemanagement.[s.l.]:ACM,2008:931-940.
[12] 孙光福,吴 乐,刘 淇,等.基于时序行为的协同过滤推荐算法[J].软件学报,2013,24(11):2721-2733.
[13]Tso-SutterKHL,MarinhoLB,Schmidt-ThiemeL.Tag-awarerecommendersystemsbyfusionofcollaborativefilteringalgorithms[C]//Proceedingsofthe2008ACMsymposiumonappliedcomputing.[s.l.]:ACM,2008:1995-1999.
[14]DuWH,RauJW,HuangJW,etal.Improvingthequalityoftagsusingstatetransitiononprogressiveimagesearchandrecommendationsystem[C]//ProcofIEEEinternationalconferenceonsystems,man,andcybernetics.[s.l.]:IEEE,2012:3233-3238.
[15]JoachimsT.AprobabilisticanalysisoftheRocchioalgorithmwithTFIDFfortextcategorization[R].USA:Carnegie-MellonUniversity,1996.
[16]SaltonG,WongA,YangCS.Avectorspacemodelforautomaticindexing[M].[s.l.]:MorganKaufmannPublishersInc.,1997.
A Constrained Probabilistic Matrix Factorization AlgorithmBased on Item-neighborhood
ZHANG Tian-jie,CAO Su-yan,YAN Shi-yang
(College of Computer,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
Collaborative filtering is one of the most successful applications in the field of personalized recommendation.Constrained probabilistic matrix factorization is a model-based collaborative filtering algorithm which can effectively deal with the problem of scalability in large-scale recommendation system and guarantee the real-time of recommendation.However,the traditional one does not consider the relationship between the users or the items,which makes the quality of the algorithm affected.It takes the relationship of item-neighborhood into the algorithm model of constrained probability matrix factorization to improve the quality of the proposed algorithm.To guarantee the accuracy of item-neighborhood,the inherent features extracted from the item’s summary and the tag of user marked for the item are used to get the set of the nearest neighbor for the items,then the item-neighborhood set is applied into the framework of the constrained probabilistic matrix factorization algorithm.The experiments on real datasets show that the proposed algorithm can predict the user’s rating on the item more effectively,and improve the accuracy of the recommendation.
recommendation system;collaborative filtering;constrained probabilistic matrix factorization;item-neighborhood
2016-01-10
2016-04-13
时间:2016-09-19
国家“863”高技术发展计划项目(2006AA01Z201)
张天杰(1992-),男,硕士研究生,研究方向为数据挖掘、大数据、云计算。
http://www.cnki.net/kcms/detail/61.1450.TP.20160919.0842.054.html
TP311
A
1673-629X(2016)10-0064-05
10.3969/j.issn.1673-629X.2016.10.014
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
科学大众(2020年23期)2021-01-18 03:09:08
汽车观察(2019年2期)2019-03-15 06:00:50
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
中国卫生(2016年5期)2016-11-12 13:25:26
公民与法治(2016年10期)2016-05-17 04:12:58
