
应用Hadoop提升数据库审计系统检索性能的研究①
2016-02-20 06:51方建生王福民
计算机系统应用 2016年12期
方建生, 王福民
1(广东电信 大数据运营中心, 广州 510080)2(广州速方软件有限公司, 广州 510660)
应用Hadoop提升数据库审计系统检索性能的研究①
方建生1, 王福民2
1(广东电信 大数据运营中心, 广州 510080)2(广州速方软件有限公司, 广州 510660)
鉴于单节点数据库审计系统检索性能低下的现状, 探讨应用Hadoop伪分布模式和HBase列存储模型重构数据库审计系统的检索存储体系, 重点研究HDFS存储机制、MapReduce运算框架和HBase数据模型三者的集成, 以提升数据库审计系统实时检索和综合分析的性能. 重构方案有效提升了检索性能, 但鉴于数据的高可靠性和大体积, 提出结合生产现状应用Hadoop和HBase分布式集群的展望.
数据库审计系统; Hadoop; HBase; RDMS
1 数据库审计系统现状
数据和数据库的安全, 是计算机运维的一个重大课题, 催生数据库安全技术的研究[1], 集中在外部数据库入侵检测[2,3]和内部数据库操作审计两个方面.
数据库审计系统(Database Audit System, 下称: DBAS)主要是通过旁路监听的方式采集访问目标数据库的镜像数据流, 实时监控并记录以审计, 及时发现违规操作和异常行为[4-6], DBAS的系统部署结构如图1所示.
DBAS在定位异常数据操作行为上, 弥补了数据库自身日志的不足, 已广泛应用在银行、医院、电信等行业[7], 其核心模块是:
1) 集引擎模块, 主要从链路层采集网卡数据包,提取数据库会话协议的内容入库, 涵盖DQL、DDL、DML、DCL操作记录, 支持各类数据库协议的解析,包括Oracle的TNS协议、Sybase和SQLServer的TDS协议、DB2的DRDA协议等.
采集引擎的关键技术是及时捕获网卡接收的数据包, 较为常见的是应用pcap库和dpdk库. Intel开发的网络数据包处理转发套件[8,9](DPDK, Data Plane Development Kit), 利用Linux 的CPU affinity和大内存页机制提高处理效率, 并提供UIO机制支撑网卡硬件驱动在用户态下运行, 具有更强的性能.
2) Web审计应用, 主要是对采集入库的SQL语句进行语义分析, 重组网络会话, 开展4W审计, 支持多关键字搜索和多维度统计分析.
Web审计应用的核心是检索功能, 支持在月表亿级数据量中综合查询、分析. DBAS由于其功能和生产特性, 多以单机集成部署采集引擎和Web审计应用,受制于关系型数据库系统(Relational Database Management System, 下称 RDMS)的存储检索体系以及单机硬件资源不足的约束, 尤其是磁盘寻址和传输的IO性能, DBAS检索效能低下.
针对该问题, DBAS查询优化方案集中在Web应用体系和关系型数据库上, 如应用Hibernate架构和Web前端缓存技术[10]、应用数据库索引和分表技术[11],本文则试图从DBAS存储检索体系上研究解决方案.

图1 数据库审计系统部署
2 HBase数据模型的特性
Hadoop是一套可靠的高性能的共享存储和分析系统[12], 可靠是首要, 高性能在于克服单机作业磁盘IO和并行作业网络带宽的两大瓶颈, 核心是负责存储的HDFS[13](Hadoop Distributed File System, 下称: HDFS)分布式文件系统和负责并行分析的MapReduce计算框架[14].
HBase具有分布式、面向列的存储模型特性, 存储的数据介于映射(key/value)和关系型数据之间[15]. 通过Hadoop生态系统圈, 可以看出HBase位于结构化存储层, 底层依赖HDFS提供的高可靠存储支持, 上层分析则借重MapReduce的高性能计算能力[16].
HBase数据模型如表1, 其列存储特性与倒排索引[17]原理一致, 又植根于Hadoop生态圈, 适合应用于全文检索, 主要组成说明如下:
1) Row Key: Table主键、行键, Table中记录按照Row Key排序;
2) Timestamp: 每次对数据操作对应的时间戳, 可视为数据的version number;
3) Column Family: 列簇, 一个table在水平方向有一个或者多个列簇, 列簇可由任意多个Column组成,列簇支持动态扩展, 无须预定义数量及类型, 二进制存储, 用户需自行进行类型转换.
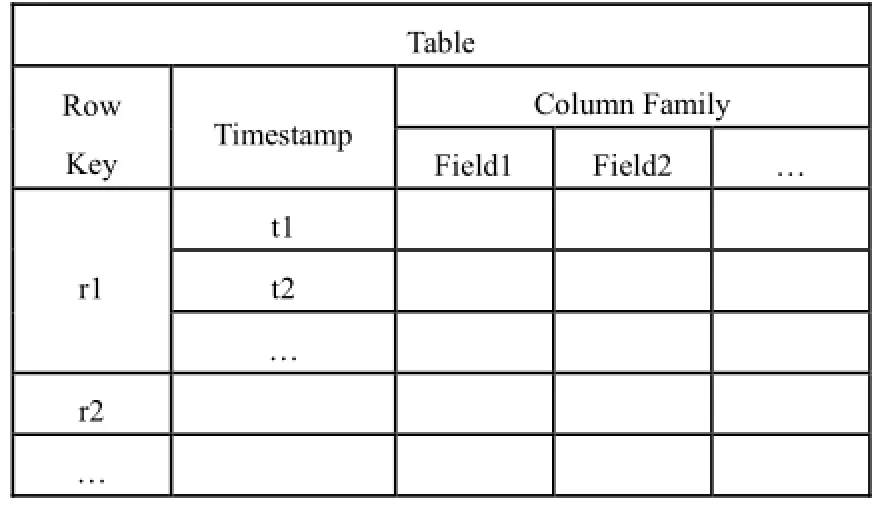
表1 HBase数据模型
得益于Hadoop生态圈和HBase的列存储数据模型特性, 使HBase适合于廉价PC Server上实现实时查询和综合分析并易于扩展成分布式集群生产.
3 重构DBAS存储检索体系
传统上, DBAS存储检索体系应用RDMS支撑采集引擎模块的数据写入和Web审计应用模块的数据读取. 通过剖析DBAS现状和理解HBase存储模型特性,结合DBAS数据具有列存储的基因特征, 显见基于Hadoop平台应用HBase可提升DBAS的检索性能[18,19].
本文研究应用Hadoop平台的高性能海量数据处理能力[20]和HBase数据库的列存储模型重构DBAS存储检索体系, 高效及时挖掘数据库操作的违规和异常行为. 重构核心是基于DBAS单机生产的特点部署Hadoop伪分布式模式, 并用HBase替换RDMS.
3.1 DBAS存储检索需求分析
DBAS数据存储检索具有单机大数据量存储和高并发操作、数据持续写入和读取操作的特点. DBAS数据存储检索的基本信息如表2所示, 主要是数据库操作信息的4W记录, 溯源什么时间什么人在哪里做了什么.
采集引擎模块解析网卡数据包中访问数据库操作的信息入库, 同时Web审计应用模块频繁、大量地读取数据支撑前台手工综合查询和后台自动综合统计,单机性能和RDMS显然无法满足大数据的高并发读写.为保证审计信息及时入库, 资源上侧重采集引擎模块的数据处理, 从而严重影响Web审计应用模块的使用.
DBAS的查询和分析, 主要集中在SQL语句语义分析的全文关键词搜索和多关键字联合查询, 较为常用场景是: 操作类型、操作时间和SQL语句的综合查询.

表2 RDMS表信息
3.2 DBAS存储检索体系重构方案
综合DBAS的数据特征和存储检索需求, DBAS存储检索体系重构方案以Hadoop核心模块HDFS和MapReduce及其HBase整套体系来替换DBAS传统上单一RDMS的存储检索体系. 重构方案以具有列存储特性的HBase作为DBAS采集引擎模块写入和Web审计应用模块读取的数据库, 集成伪分布的HDFS存储和MapReduce运算框架, 支持DBAS单机大数据量的高速并发读写, 提升RDMS的读写性能.
重构方案重点研究HBase表结构设计、HBase集成HDFS和MapReduce、以及DBAS实时检索的实现.
1) HBase表结构设计
针对表2信息, 综合DBAS检索的常用场景, 重构方案中将按照4W审计需求来定义HBase的列存储表结构, 如表3所示.
在RDMS中, 一般建立操作类型和时间作为索引满足常用查询, 重构方案中的HBase存储结构便以操作类型作为Row行键.
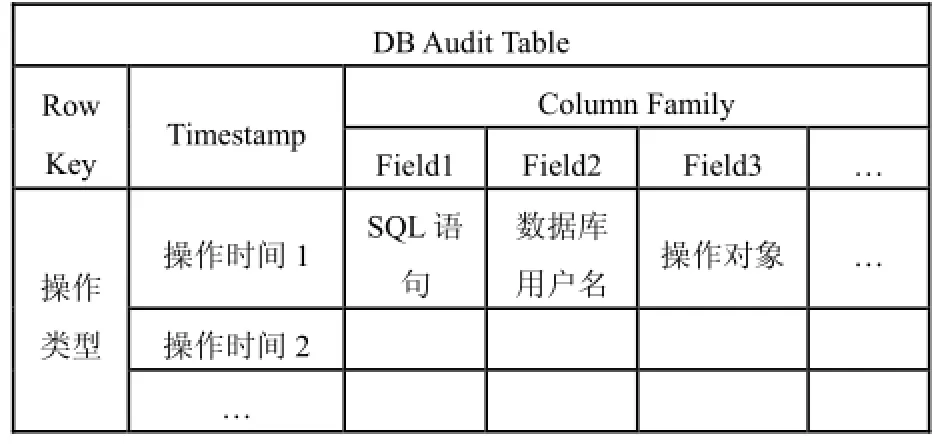
表3 HBase表结构
2) HBase集成HDFS和MapReduce
Web审计应用模块提出的检索业务逻辑, 通过HBase提交到MapReduce作业, 而MapReduce基于HDFS上存储的HBase表运算并输出HBase表, 提供给Web审计应用统计分析结果, 三者集成的具体数据流如图2所示.
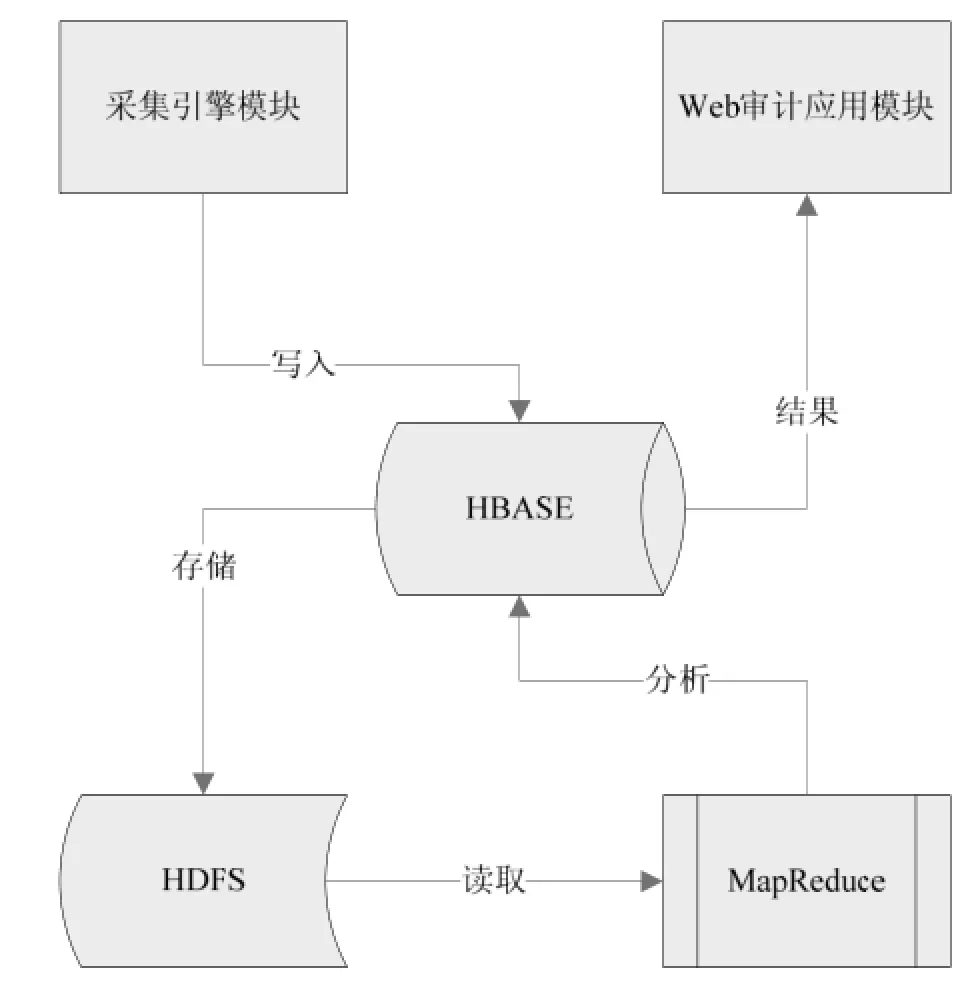
图2 DBAS数据流图
HBase按行键分成<key,value>对存储在HDFS, key 值对应行健, value 值为该行所包含的数据, 定义MapReduce的Mapper类和Reducer 类支持Web审计应用模块提出的检索业务需求.
3) DBAS实时检索的实现
不同于RDMS满足规范性数据持续性写入的存储和分析需求, Hadoop适合应用于一次写入、多次读取的数据操作场景. 针对DBAS持续性写入HBase的需求, 重点研究数据实时存储到HDFS的实现.
HBase底层的存储是采用key/value的文件结构,写操作有三个步骤: 1)写入HLog, 防止宕机丢失数据; 2)按row有序写入对应的memstore内存; 3)当memstore写满时, 数据被flush到HDFS, 持久化到新的storefile数据文件. 基于HBase的存储机制, 应结合实际生产情况来设置memstore被flush时的阈值, 同时采集引擎模块建立多级缓存.
4 实验案例
DBAS部署在X86结构的单服务器上, 操作系统为centos, 采用RAID1镜像结构, 整体资源优先满足网卡采集的IP包持续性写入, 再而尽快响应大数据量读取的检索. 实验以某三甲医院DBAS为案例, 存储记录月表8000万条左右、存储空间50G左右.
在软硬环境一致、读写数据量和频度一致的情况下, 部署两套独立的DBAS及其存储检索数据库, A方案采用Mysql, B方案基于Hadoop平台的HBase. 实验中, 在正常生产情况下和资源优先保障磁盘写入下,分别对两套独立的DBAS执行三类常见的检索场景,观察磁盘IO和CPU/内存利用率, 比较两个方案三类场景的执行响应时间.
场景一: 统计delete操作的次数, delete的数据库操作记录比较少, 是审计中的敏感点, 经常被检索;场景二: 统计select操作的次数, select记录最多, 经常用于统计各类审计事件; 场景三: 查询两类处方药联合出现的记录, 是医院防统方的主要审计点. 三类场景执行的响应速度如图3执行时间, 并观察执行区间的资源利用率.

图3 执行时间
首先, A方案中, 磁盘IO保持在较高水平, 接近30M/S的满负荷状态, 而B方案基本在10M/S左右,在同样数据量写入情况下, A方案Mysql在读取IO请求上占用过高资源; 其次, A方案的CPU和内存占用80%以上, 而B方案基本维持在50%左右. A方案的资源利用率达到临界, 一旦出现突发数据请求, 则会出现系统各类响应延迟, 写入溢出; 而B方案还有很多资源空间来满足生产.
最后, 分析两个方案三个场景的执行时间: 1)场景一上A方案响应快, 主要在于delete记录少且Mysql针对操作类型建立索引; 2)场景二随着查询数据量的体积倍增, B方案优势明显, 且实验中A方案仅做单表统计, 如果涉及跨月联表查询, A方案性能更低; 3)场景三两个方案的执行速度和场景二一样, 对A方案来说, 处方药联合出现的查询事前无法建立索引和存储块, 全表检索耗时巨大.
在实验案例中, 更多的同类场景执行, 发现B方案的响应时间基本稳定在20秒上下, 而A方案检索大数据量的情况就要到60秒以上, 可见HBase列存储模型、HDFS流式数据读取模式、MapReduce批处理方式在大数据检索方面的优势.
5 展望
本文基于DBAS存储检索的现状, 应用Hadoop平台及其生态圈数据库HBase重构DBAS存储检索体系, 从DBAS的检索需求和数据特点出发, 研究HDFS及MapReduce机制和HBase的集成, 使三者有效发挥以提高DBAS单节点检索性能.
在实际产品运行中, 重构方案明显提升了DBAS检索性能, 但数据体积的不断膨胀和高可靠性要求,面对审计产品行业应用的个性化要求, 展望未来, 综合权衡DBAS的生产现状和成本下, 研究Hadoop和HBase分布式[21,22]来支持DBAS存储检索是一个方向.
1 吴溥峰,张玉清.数据库安全综述.计算机工程,2006, 32(12):85–88.
2 叶碧野.计算机数据库入侵检测技术探析.电脑知识与技术, 2012,8(2X):1012–1014.
3 肖大薇.计算机数据库入侵检测技术分析研究.信息系统工程,2012,(4):54–55.
4 晏明春,李酒.一种新型在线数据库审计系统.计算机工程与设计,2007,28(5):1012–1015.
5 杨磊.数据库安全审计检测系统的设计与实现[硕士学位论文].北京:北京交通大学,2014.
6 安鹏.基于云架构的统一审计平台设计与实现[硕士学位论文].长春:吉林大学,2015.
7 聂元铭,吴晓明.基于数据库安全审计的研究.信息网络安全, 2009,(6):4–6.
8 Cerrato I, Annarumma M, Risso F. Supporting fine-grained network functions through intel DPDK. 2014 Third European Workshop on Software Defined Networks (EWSDN). IEEE Computer Society. 2014. 1–6.
9 Pongracz G, Molnar L, Kis ZL. Removing roadblocks from SDN: OpenFlow software switch performance on intel DPDK. 2013 Second European Workshop on Software Defined Networks. IEEE Computer Society. 2013. 62–67.
10 刘晨莹.数据库审计系统中数据快速查询与智能分析设计与实现[硕士学位论文].保定:华北电力大学,2015.
11 李凯,杨永清,范渊.一种在大数据量存储中快速检索的方法:CN, 2012. CN 102184222 B.
12 White T. Hadoop: The definitive guide. O’reilly Media IncGravenstein Highway North, 2010, 215(11): 1–4.
13 Kaushik RT, Bhandarkar M, Nahrstedt K. Evaluation and analysis of GreenHDFS: A self-adaptive, energy-conserving variant of the Hadoop distributed file system. IEEE Second International Conference on Cloud Computing Technology and Science (CloudCom), 2010. IEEE. 2010. 274–287.
14 Wang L, Tao J, Ranjan R, et al. G-Hadoop: MapReduce across distributed data centers for data-intensive computing . Future Generation Computer Systems, 2013, 29(3): 739–750.
15 George L. HBase: The definitive guide. Andre, 2011, 12(1): 1–4.
16 Taylor RC. An overview of the Hadoop/MapReduce/HBase framework and its current applications in bioinformatics. Bmc Bioinformatics, 2010, 11(6): 3395–3407.
17 邓攀,刘功申.一种高效的倒排索引存储结构.计算机工程与应用,2008,44(31):149–152.
18 王欢,许暖,沈波.基于大数据的智能审计平台研究.电信工程技术与标准化,2014,(12):19–22.
19 张萌.基于hadoop的网络安全日志审计系统关键技术研究[硕士学位论文].哈尔滨:哈尔滨工程大学,2013.
20 翟岩龙,罗壮,杨凯,等.基于Hadoop的高性能海量数据处理平台研究.计算机科学,2013,40(3):100–103.
21 施磊磊,施化吉,束长波,等.基于Hadoop和HBase的分布式索引模型的研究.信息技术,2015,(6):109–111.
22 万轶,向广利.基于hadoop和hbase的分布式索引集群研究.信息技术与信息化,2015,(1):102–103.
Study on Applying Hadoop to Enhance the Retrieval Performance of Database Audit Systems
FANG Jian-Sheng1, WANG Fu-Min212
(Operation Center of Big Data, Guangdong Telecom, Guangzhou 510080, China) (Guangzhou Soofound Software Co. Ltd., Guangzhou 510660, China)
Based on the present situation of lower retrieval performance of the single node database audit system, this paper carries out research of application of the Hadoop pseudo distribution model and the HBase column storage model to reconstruct the database audit system of the single node deployment for enhancing the retrieval performance. This paper focuses on the study of integrating HDFS storage mechanism, MapReduce computing framework and HBase data model to improve the performance of real-time retrieval and comprehensive analysis of database audit system. Reconstruction scheme can effectively improve the retrieval performance, but in view of the high reliability and large volume of the data, the application of Hadoop and HBase distributed cluster is proposed in combination with the production status.
DB audit system; Hadoop; HBase; RDMS
2016-03-30;收到修改稿时间:2016-06-06
10.15888/j.cnki.csa.005562
猜你喜欢
当代陕西(2022年4期)2022-04-19
摄影世界(2022年1期)2022-01-21
北京大学学报(自然科学版)(2021年3期)2021-07-16
中国生殖健康(2020年7期)2020-12-10
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
商周刊(2017年6期)2017-08-22
