
一种基于句法规则的文本挖掘技术的设计
2016-02-15 07:07宁琳
现代情报 2016年2期
宁 琳
(重庆交通大学图书馆,重庆400074)
一种基于句法规则的文本挖掘技术的设计
宁 琳
(重庆交通大学图书馆,重庆400074)
文本挖掘是数据挖掘技术的一个重要方面,本文根据句法规则的特征,利用文本挖掘技术,提出基于句法规则的文本知识挖掘设计模型,从数据准备、句法规则构造、文本预处理、文本知识挖掘、挖掘结果评价等方面对工作原理进行了分析,重点阐述了句法规则的构造过程,最后通过实验验证了该模型,该设计对实现文本知识的智能化挖掘具有一定的研究意义和应用价值。
文本挖掘;句法规则;模式匹配;文本预处理
随着信息技术、网络技术和各种数字化资源的建设,人们正面临着海量、快速增长的文本数据资源,传统的搜索引擎和查找技术已远远不能满足人们的需求。如何从大量原始的、未经处理的文本数据集合中挖掘出潜在未知的知识,满足人们获取各种信息和知识的需要,已成为一个重要的研究课题。
1 文本挖掘及句法规则概述
文本挖掘(Text Mining,TM)是在数据挖掘的基础上发展起来的一个分支,它以文本数据作为挖掘对象,主要任务是对隐藏于海量文本中没有检测到的非结构化知识进行提取的过程[1]。文本挖掘处理的对象是由多数据源组成的大量文本文档,包括新闻文章、研究论文、书籍期刊、报告会议、档案文献、Internet网络信息等半结构化或者高度非结构化的数据[2]。
汉语句子的结构非常自由,但其蕴含的基本规则相对稳定,句法规则是从汉语本身的属性特点出发,将构成句子的词或词组按一定的语法关系和句子结构,组合成能够表达完整意思的规则[3],如词语的分类、句式结构的确定、句法描述体系和句法构成元素的建立等,它是对句子结构的抽象概括,通过组合和聚合关系造出无数合格的句子,是对句子分析的一种总结结果。
2 基于句法规则的文本知识挖掘技术的分析与设计
本文采用句法规则构造实现文本知识挖掘,主要设计如下:首先,根据知识的表示和用户的不同需求,构造出能全面准确表达文本内容的句法规则;其次,针对多源文本数据的特点和存在的问题进行预处理操作,为核心挖掘提供干净、准确、简洁的目标数据;再次,基于模式匹配算法,执行句法规则与目标文本数据的匹配,得出满足句法规则条件的挖掘结果;最后,通过一定的指标对挖掘结果进行评价,将满足用户需求的知识可视化表达到用户界面,供其选择和使用,具体过程如图1所示:
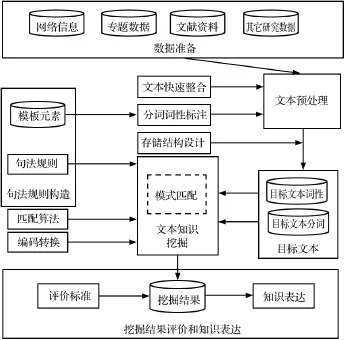
图1 基于句法规则的文本知识挖掘设计
2.1 数据准备
数据准备主要是多源文本数据的获取,它通过多种数据源获取用于文本知识挖掘的数据,并存储在本地硬盘中[4]。文本数据的获取有多种途径,主要来源是Internet网络信息、研究成果、各种专题数据,以及其他文献资料。选择文本数据的数据源需要遵循以下原则:一是能为对象提供详细、准确数据;二是要考虑数据的可整合性、可挖掘性和现势性。文本知识的挖掘是一种基于句法规则的集中式挖掘,务必要求多源文本数据在结构上能够整合到同一平台框架下,并且保持一定的现势性,从而简化挖掘操作,提高知识获取的准确度。
2.2 句法规则构造
句法规则构造是根据知识的表示方法和汉语的句法组成结构,通过对表达语料库的的详细分析,将知识规则化,为核心挖掘提供模式匹配的基础条件。它主要分为3个层次:模板元素、句法规则、规则库。建立用于构造句法规则和约束文本分词、词性标注的模板元素,构造出用于模式匹配的句法规则,构建相应的规则树。从模板元素建立到句法规则构造,再到规则库的构建带有明显的层次性和结构性。
句法规则构造过程分为以下几步:一是收集并提炼出资料中的模板元素并建立相应的模板元素库;二是根据语法要求和句法结构将模板元素组合成句法规则;三是把句法规则存放入规则库。
2.2.1 句法规则的模板元素
模板元素是用户作为约束文本预处理结果的一种扩充词典,各个模板元素之间相互作用、相互影响构成了表达文本内容的句法规则。在这里借鉴汉语句法结构组成和本体概念的构建方法,将构成规则的每个〈词语〉抽象为词性,每种词性下面包含了能够反映该词性性质的元素,称为模板元素,规则中的每个模板元素都是该事件的参与者,一个句法规则看作是一个句子的语义的某种抽象化表示[5],用模板元素表示该句子的语义,具体表示为:
〈模板元素1〉+〈模板元素2〉+〈模板元素3〉+…+〈模板元素n〉(1)
从式(1)可以看出,多个模板元素根据汉语句子的语法要求和句法结构组合,即可构成能够表示特定文本知识的规则,我们称这种表示知识的规则为句法规则。因此,本文的句法规则是以模板元素为基本单位,根据人们表达习惯将多个模板元素按照语法关系组合成能够表达知识的句子。模板元素作为句法规则的组成,是一种类似本体的表达类型,可表示为属性(内容1,内容2,…,内容n),其中属性抽象为能够表达该领域知识的任意一种词性,如“词性:名词”,内容则表示该模板元素范围内包含的所有词的集合。
本文在采用中科院ICTCLAS分词系统汉语词性标记统计的基础上,提出了多个属性类别选项以描述模板元素,具体如表1所示:

表1 词类标注表
然后,对各词类内容进行具体划分,如以谓词表为例:

表2 谓词表
2.2.2 句法规则构造
句法规则是模式匹配的逻辑核心,是知识表示内容的形式化概要,起到把要挖掘的知识内容类型化和结构化的作用。一条句法规则通常指出模板元素之间的关系,当句法规则与目标文本进行匹配时,必须合理约束各模板元素之间的语法关系和句法结构,严格按照每个模板元素在句法规则中的出现顺序对其进行匹配[4]。例如:北京是中国的首都,与天津市相邻,它的句法化表达为:〈主语〉+〈谓词〉+〈地名〉,〈连词〉+〈地名〉+〈谓词〉,它的句法规则为:n/v/ns/f/w2/cc/ns/v。
2.2.3 规则库
规则库是用户需求与目标文本之间进行问题求解的基础,用于描述相应领域内知识概要的产生式集合[6],它包含了所有能反应和表达实体文本知识的方法和表现形式,能够为用户提供不同的抽象描述,形成不同的推理链,得出不同的挖掘结果。本文规则库采用规则树结构存储,如图2所示:
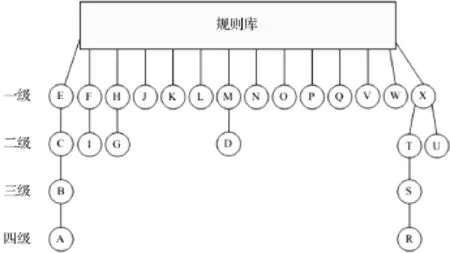
图2 规则树的建立
图2 中,规则库作为树的根结点,共包含24个子结点,分别代表本文构造的24条句法规则。按照结点所在层次由高到低分别定义为一级、二级、三级和四级规则。该规则树构建的基本策略是:
(1)将所有的句法规则置于一个集合中,即规则库作为规则树的根结点;
(2)根据句法规则的组成结构对其进行划分,将相互独立并且不被包含的句法规则按编号顺序(从A到X)依次作为第二层的子结点,定义为一级规则;
(3)将其余句法规则根据包含与被包含的关系,依次划分到相应子结点下面,并分别定义为二级、三级和四级规则。
采用以上树结构存储句法规则,结构清晰,便于执行与目标文本的匹配,减少部分句法规则与目标文本之间不必要的匹配。
2.3 文本预处理
文本预处理是文本挖掘的基础,主要对目标对象的多源文本数据进行操作,将多数据源中获取的文本数据进行处理,为下一步的文本知识挖掘提供比较“满意”的目标数据。预处理主要包括文本快速整合、文本分词和词性标注、目标文本存储等,本文采用中科院的开源ICTCLAS分词系统对文本进行分词和词性标注。
文本预处理主要分为3个步骤:
(1)多源文本数据快速整合。将目标对象的多源文本数据集成到同一文本文档中。
(2)中文分词和词性标注。将经过整合的目标对象文本数据分词、标注词性。
(3)目标文本存储。将目标文本以段为单位编码并索引标记,建立两个二维表分开存储目标文本分词结果和目标文本词性标注结果。例如,对于预处理之后的目标文本:南京/n位于/v江苏省/ns中部/f,我们采用表3和表4所示存储:

表3 目标文本分词

表4 目标文本词性
2.4 文本知识挖掘
文本预处理完成以后,即可进行文本挖掘操作。文本知识挖掘是采用模式匹配算法,将规则库中的句法规则和目标文本执行精确匹配,得出符合规则条件的文本结果,并将其保存。它的主要任务是通过各种算法挖掘出用户需要的信息,主要包括特征提取、文本分类、文本聚类、文本提取、关联分析等[7]。本文采用KMP(Knuth-Morris-Pratt)算法进行模式匹配,基本思想是:当匹配过程中出现字符比较不相等时,模式串利用已经得到的“部分匹配”结果将模式串向右“滑动”,重新开始下一趟的匹配。例如对于主串“acabaabaabcac”,模式串“abaabcac”,利用KMP算法进行匹配的过程如下:
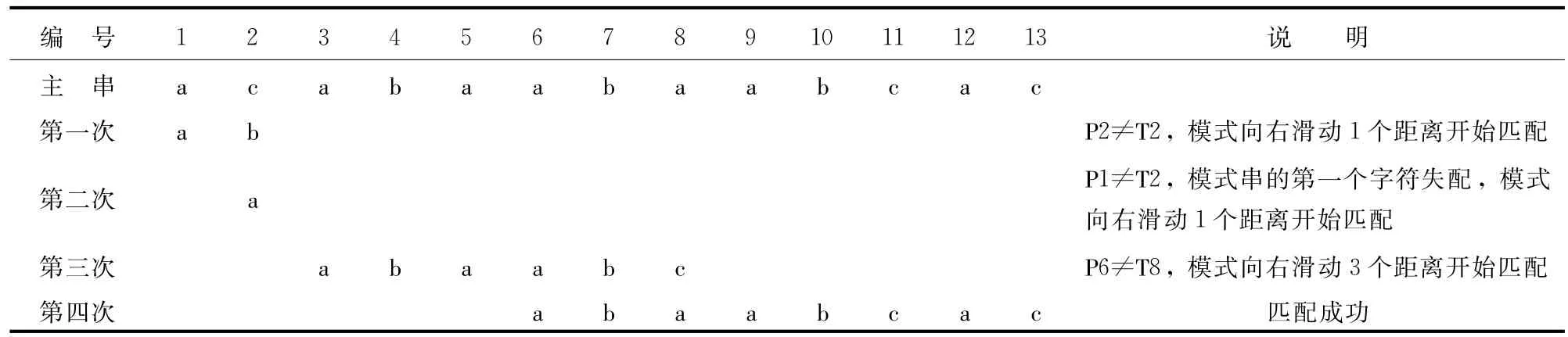
表5 KMP算法匹配的过程
具体挖掘流程如图3:

图3 基于句法规则的文本知识挖掘流程
基于句法规则的模式匹配的执行步骤为:
(1)读取句法规则库,输入目标文本词性和目标文本分词,启动基于句法规则的模式匹配。
(2)对规则库中的句法规则按照由高到低级别依次和所有编码的目标文本词性执行匹配。采用匹配算法遍历目标文本词性执行精确匹配,直到所有句法规则与目标文本词性执行完匹配,输出所有句法规则匹配结果。若无句法规则匹配结果,则匹配失败,结束整个模式匹配。
(3)将所有句法规则匹配结果转换为对应文本字符。根据二维表编码关联返回到对应目标文本分词中,根据索引标记将句法规则匹配结果转换成相对应的文本字符,该文本字符即为文本知识挖掘结果。
(4)输出所有基于句法规则的挖掘结果,匹配结束。
2.5 挖掘结果评价和知识表达
评价是指通过一定的评价标准对挖掘结果进行评估,把符合条件的结果返回到可视化模块。知识表达是将评价后的结果表达到用户界面,供用户选择使用,最终经过可视化表达的结果即为用户期待已久的知识。文本挖掘质量评估是对挖掘结果的整体衡量,若挖掘结果满足评价指标,则挖掘完成,否则重新挖掘。
3 实验结果验证
下面我们以郑州市地理信息文本知识的挖掘为例,利用VisualStudio 2010作为开发平台,介绍整个挖掘实现过程。
3.1 数据选取
打开数据源接口,通过Internet搜索引擎选取30篇郑州市地理信息数据,并保存到“F:\郑州市地理信息文本数据”中。
3.2 文本预处理
对以上选取的文本数据进行预处理。在ICTCLAS分词系统上进行设置,通过选择文本、添加用户词典、分词并标注词性、结果保存,实现文本快速整合、分词和词性标注。对预处理后的目标文本设置过滤功能,将对应的目标文本分词和目标文本词性以段为单位编码同时用索引标记,分开存储。存储结果如下图所示:

图4 目标文本词性

图5 目标文本分词
3.3 文本知识挖掘
文本知识挖掘是在本文2.2句法规则构造的基础上进行,主要分为3个过程:匹配条件提交、匹配实现和结果转换。匹配条件提交指读取规则库、输入目标文本词性和目标文本分词,匹配实现通过执行模式匹配算法代码来实现,结果转换利用句法规则匹配结果的编码和索引标记将其转换为对应的目标文本分词字符,实现挖掘结果。挖掘结果分别如图6所示:

图6 文本知识挖掘
3.4 评价和表达
在完成文本知识挖掘以后,便对挖掘结果进行评价,并按相对优劣次序将地理位置文本知识可视化表达,并可导出为常用的EXCEL、WORD等文档格式,如图7所示:
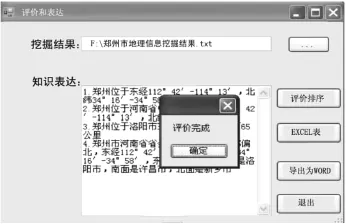
图7 挖掘结果与表达
通过以上实例可以看出,采用基于句法规则的文本挖掘方法,能够为用户在挖掘结果中得到比较满意的信息,从而较好的达到设计的目的。
4 结束语
随着文本数据资源的不断增长,仅仅通过简单的搜索引擎和数据筛选功能已经无法满足人们对信息和知识的需求,迫切需要高效率的信息分析方法。采用基于句法规则的文本知识挖掘设计方案,能够从句法规则设计入手,利用现有文本挖掘技术,从众多文本数据中快速地获取用户需求的知识,对实现文本知识智能化挖掘具有一定的借鉴意义。
[1]Antonis Spinakis.Text Mining A Powerful Tool for Knowledge Management[EB/OL].http:∥www.quantos-stat.com/articles/Text-Mining.pdf,2010,(7).
[2]张雯雯,许鑫.文本挖掘工具述评[J].图书情报工作,2012,(4):26.
[3]杨晖.言语实践中的句法认知[J].吉林师范大学学报:人文社会科学版,2007,(4):64-66.
[4]马绍龙.基于句法规则的地理位置文本知识挖掘[C].郑州:信息工程大学论文集,2014(4):170-173.
[5]吴平.论元控制谓词与非论元控制谓词的逻辑语义分析与计算[J].外语与外语教学,2006,17(3):5-10.
[6]刘晨帆.基于规则引擎的军事地理信息自定义查询技术研究与实现[D].郑州:信息工程大学,2010:23.
[7]黄晓斌,赵超.文本挖掘在网络舆情信息分析中的应用[J].情报科学,2009,(1):96.
(本文责任编辑:孙国雷)
Text Mining Design Based on Syntactic Rules
Ning Lin
(Library,Chongqing Jiaotong University,Chongqing 400074,China)
Text mining is an important aspect of data mining technology.According to the features of syntactic rules,the paper uses the text mining technology,and puts forward the design model based on the syntactic rules text knowledge mining.It analyzes the working principles of the data preparation,the syntactic rules knowledge structure,the text preprocessing,the text mining and the evaluation of mining results.Meanwhile it expounds the process of the construction of the syntax rules.At last,the paper identifies the model after some physical experiments.All in all,the design has certain research significance and application value to implement the intelligent of the text knowledge mining.
text mining;syntactic rules;pattern matching;text pretreatment
10.3969/j.issn.1008-0821.2016.02.027
TP391
A
1008-0821(2016)02-0140-05
2015-11-05
宁 琳(1979-),女,馆员,硕士,研究方向:信息管理,发表论文10余篇。
猜你喜欢
大连民族大学学报(2021年2期)2021-07-16
数学小灵通(1-2年级)(2021年4期)2021-06-09
校园英语·月末(2021年13期)2021-03-15
Coco薇(2017年11期)2018-01-03
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
外语学刊(2011年3期)2011-01-22
