
基于改进的模糊时间序列预测模型的HDFS副本选择策略
2016-02-13 01:08莫文导孙全忠
广东公安科技 2016年4期
莫文导 孙全忠
(广东省公安厅科技信息化处,广东广州510050)
基于改进的模糊时间序列预测模型的HDFS副本选择策略
莫文导 孙全忠
(广东省公安厅科技信息化处,广东广州510050)
随着公安机关大数据计算和警务云平台的建设、推广,云存储改变了以往数据本地存储和处理的传统模式,能够通过网络根据需求快捷访问计算与存储等服务。为了满足云存储系统的动态性、复杂性以及实时性的要求,本文提出了基于改进的模糊时间序列预测模型的HDFS副本选择策略。对模糊时间序列预测模型进行改进,利用改进后的模糊时间序列预测模型对副本读取时间进行预测,并在hadoop平台的数据访问实验,证明了改进后的模糊时间序列预测模型相比于经典模型能够较好地刻画云存储数据副本读取时间的变化,并在数据访问耗时方面有明显的性能提升。
云存储副本选择预测模型模糊时间序列
随着大数据时代的到来,越来越多的公安业务应用场景对数据的分析从离线转向在线,而数据价值随着时间的流逝而衰减的特点,导致对数据处理的实时性要求越来越高。云存储系统作为大数据的主要存储平台,应满足大数据处理的高速访问性能的需求。因此,提高云存储平台的数据访问速率,是改进大数据处理性能,保证数据处理和公安科技信息化应用系统实时性的重要手段。
云存储系统通过引入副本机制提高数据的可靠性并降低访问延迟,以HDFS为代表的云存储系统副本选择决策机制,根据主控节点(NameNode)统一计算的结果,决定读取哪个数据块副本(一般为网络距离最小的),没有考虑数据节点负载、集群内部带宽变化、磁盘IO和多客户端并发访问等因素对数据读取性能造成的影响。导致主控节点的计算负荷大幅度增加,难以控制客户端的数据副本读取性能和预测响应时间变化。本文利用预测的方法来优化HDFS副本的选择策略,在客户端访问HDFS副本时,基于模糊时间序列预测模型来选择HDFS副本,从而减少数据访问时间和优化数据访问性能。
1 改进的模糊时间序列预测模型
普通时间序列预测模型是建立在数据完整性、准确性和确定性基础上的一种规律分析方法,对应用环境的要求高,并需要大量的历史数据支撑。而实际应用环境的复杂性使得观测到的数据准确性不高,存在大量无法用精确数据表示的模糊变量,导致普通时间序列预测模型的实用性不高。为了解决普通时间序列预测模型存在的不足,Song和Chissom[1][2]在模糊集理论[3]的基础上提出了第一个模糊时间序列预测模型,并衍生出大量的改进模型,但这些模型要么过于复杂,要么没有考虑实际应用的数据动态性,难以适应复杂而多变的云存储系统环境。
为了能在可接受的时间内给出预测结果,使得预测过程的计算时间对副本响应时间的影响降到最低,且能够从新获取到的训练数据里提取有用信息并逐步更新模糊计算逻辑关系。本文在Chen[4]模型的基础上,结合文献[5]提出的改进方法,对经典预测模型进行优化调整。
1.1 论域动态调整
由于网络状态、磁盘IO速度、并发访问数等因素均会对副本响应时间产生影响,云存储环境下,长期的数据特征稳定性较差,经典模糊时间序列预测模型并不适合对副本响应时间进行长期预测,因此,该模型的预测应用重点应放在副本响应时间短期预测上。
将HDFS集群的副本响应时间历史数据窗口定义为W,大小为|W|=k,k个时刻上的时间序列为W(t)={w1(t),w2(t),…,wk(t)}。由于数据离群点(Outlier)会影响到确定论域、划分模糊区间等过程,导致预测准确性降低,因此确定论域前,需预先剔除捕获训练数据的离群点。
本文使用3σ准则剔除离群点,设历史数据窗口为W,数据平均值为xˉ,标准差为σ,如果W的观测值中有wp(t)满足以下条件:wp(t)<xˉ-3σ或者wp(t)>xˉ+3σ,则将满足条件的wp(t)作为离群点进行剔除预处理。如将预处理操作后的时间序列表示为:W′(t)={…,wi(t),wj(t),…,wm(t),…},则历史数据窗口W上的论域为UW=[min(W′(t)),max(W′(t))]。
根据获取到的新副本响应时间,动态调整历史数据窗口W的大小。每当获取到新的响应时间相关数据时,首先判断该数据值是否处于UW的范围内,若新的响应时间数据值处于论域UW内,则在历史数据窗口W的末端添加该数据值,窗口大小相应增加1个单位,并利用模糊逻辑关系矩阵更新模型数据;若新的响应时间数据值不处于论域UW内,则从历史数据窗口W中截取||Wmin个历史数据,和新的响应时间数据值共同构成新的历史数据窗口,其中,截取历史数据的数量||Wmin,应根据历史数据窗口大小、论域范围等具体情况进行规定。新的历史数据窗口确定后,重新执行论域调整、模糊预测区间划分、模糊关系矩阵生成和更新等过程。
1.2 模糊逻辑关系矩阵动态更新
由于经典预测模型对模糊逻辑关系不进行多次(重复)计算,因此该类模型的模糊逻辑关系矩阵不能体现由模糊逻辑关系出现频繁度产生的影响。本文在重新建立模糊逻辑关系的权重矩阵时,将模糊逻辑关系出现的频繁程度作为重要计算参考因素。
经调整后的模糊时间序列预测算法流程如图1所示。首先,选取最小样本数据作为训练数据,其中,应根据不同系统规定的最小样本个数,选取符合系统预测要求的样本数量。其次,对训练数据做预处理,剔除对预测结果影响较大的离群数据;接着定义样本论域并划分模糊区间。与经典模型不同,调整后的模糊时间序列预测算法根据LEM2规则[6]来生成模糊逻辑关系矩阵,并给出最后的预测结果,随后执行论域动态调整过程(见“1.1论域动态调整”)。
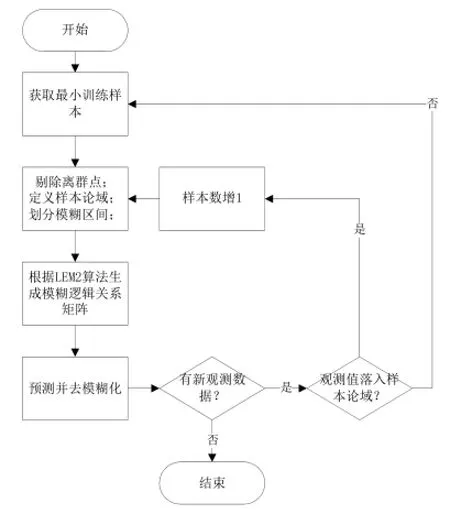
图1 调整后的模糊时间序列预测算法流程图
2 基于预测的副本选择策略
在改进的模糊时间序列预测模型算法的基础上,重新设计分布式副本的选择和读取策略:
设R={r1,r2,…rn}表示HDFS集群的文件F中数据块B的候选副本集,候选副本ri响应时间为客户端C选择候选副本ri并将其读取到内存的时间。
当安装了副本选择服务的客户端向HDFS集群主控节点(NameNode)发出读取请求时,NameNode将拟读取的数据块副本的位置信息反馈给客户端,安装在客户端上的副本选择服务根据反馈的数据块副本位置信息,区分相同数据块内的不同副本,同时记录所有成功访问的副本响应时间。则基于改进的模糊时间序列预测模型重新设计的数据副本选择和读取策略如下:
(1)如果客户端访问数据时,候选副本集中有新创建的副本,此时,由于缺少副本响应时间的历史样本数据,客户端直接读取新创建的副本并记录响应时间;
(2)若存在候选副本集响应时间的历史样本数小于||Wmin的情况,则选择并读取访问次数最少的副本,记录响应时间,并纳入历史样本数进行统计;
(3)在候选副本集响应时间的历史样本数据充足的情况下,用调整后的模糊时间序列预测模型,预测候选副本集中所有副本的响应时间,选择并读取预测响应时间最小的副本,记录实际的副本响应时间;
(4)结合实际的应用系统需求,设定一个访问时间阀值,当副本最近被访问的时间超过了阀值,将该副本标记为长时间未被访问数据副本,并当作新创建副本进行处理。
3 实验与分析
3.1 实验环境与配置
为了验证改进的模糊时间序列预测模型及其副本选择策略的有效性,设计了一个Hadoop集群实验环境,其中包括1个NameNode和4个DataNode,实验环境的网络拓扑结构如图2所示。
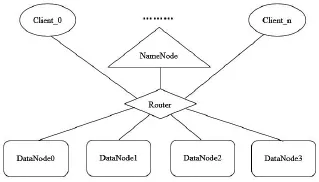
图2 Hadoop集群实验环境网络拓扑结构
实验环境中的集群角色(NameNode、DataNode和Client等)使用1个路由器实现互联,等同于所有节点均处于同一个机架内。根据Hadoop集群的网络距离计算模式,实验环境中的2个节点相互之间的网络距离均为2,符合使用HDFS副本随机选择策略的条件和要求。Hadoop集群实验环境中NameNode与DataNode节点的配置参数如表1所示。
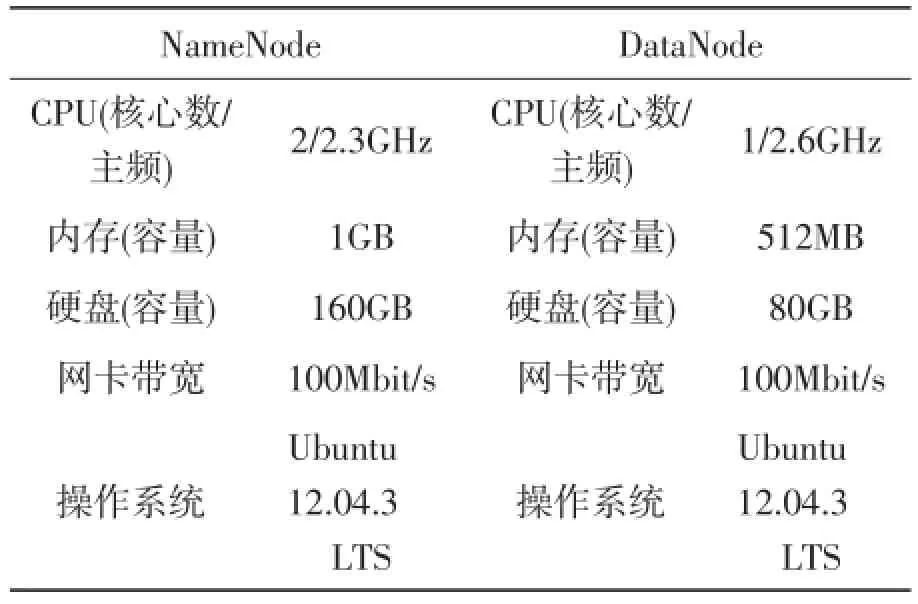
表1 Hadoop集群实验环境节点硬件配置参数
由于Hadoop没有直接操作数据块副本的接口,无法直接测量数据块副本的响应时间,因此,实验过程采用场景模拟的方式测量并收集副本响应时间。先将实验环境中的Hadoop集群默认副本因子设置为1,然后每次仅选择1个且与上次不同的DataNode节点上传目标测试文件,目标测试文件大小均为60MB,具有相同的数据内容,分别命名为TestFiles0~3,重复4次上传操作,历遍所有DataNode节点后,同时启动4个DataNode节点,在不使用HDFS的Bal⁃ancer工具平衡各节点存储空间利用率的情况下,确保每个DataNode节点中存在唯一的目标测试文件。
在使用5个客户端(Client)不间断、随机访问集群文件,模拟现实的集群环境中网络状态、磁盘IO速度、并发访问数等影响副本响应时间的场景和因素的情况下,用另外1个独立的客户端,以2秒的时间间隔,读取4个DataNode节点上的目标测试文件(TestFiles0~3)并记录响应时间,重复读取操作直到获取足够的实验数据。
3.2 经步骤调整的模糊时间序列预测效果对比
本实验选取单个时间序列前20个(||Wmin=20)数据作为训练数据,应用经典模糊时间序列预测算法和调整后的预测模型,对从目标测试文件(TestFiles0~3)的响应时间序列中随机选取的30个序列进行预测,通过与实际副本读取响应时间进行对比,得出两者的预测效果如图3、图4所示。

图3 经典模糊时间序列模型预测结果
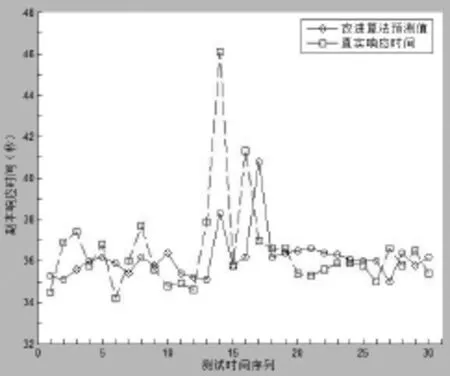
图4 经调整的模糊时间序列模型预测结果
由图可知,经典模糊时间序列预测模型难以反映真实响应时间的趋势。调整后的模糊时间序列预测模型的预测结果虽然具有一定的滞后性,但能够较好地反映数据的变化趋势,更适合云存储环境下副本响应时间的动态预测。3.3基于预测的副本选择策略与随机选择策略
的比较
使用重新设计的副本选择策略,选择目标测试文件(TestFiles0~3)中,预测响应时间最小的副本进行读取,其预测效果如图5所示。
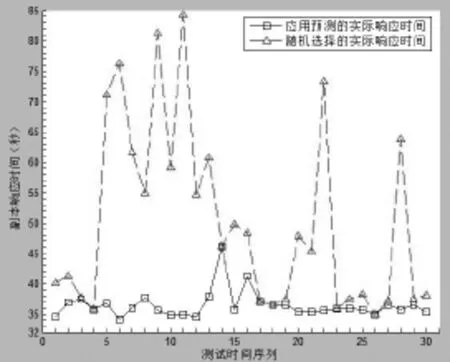
图5 基于预测的读取时间与随机策略读取时间对比
由图可知,经过30次的副本读取比较,重新设计的模糊时间序列预测模型选取副本读取时间为1093.7s,比随机选择副本所耗费时间(1504.2s)减少了410.5s的时间,平均每个副本节省访问时间约13.7s,说明重新设计的模糊时间序列预测模型的副本访问性能得到了有效提升。
4 结语
本文针对HDFS在读取文件时所采用的副本选择策略的不足,对经典模糊时间序列预测模型进行了适当调整,提出了基于模糊时间序列预测模型的副本选择策略,并通过Hadoop集群上模拟实验环境,验证了基于改进的模糊时间序列预测方法应用在HDFS副本选择策略时,可以更好地体现出用户读取数据的规律性,获得更好的数据访问性能,更加适合云存储系统环境下动态预测的需求。
[1]Song,Q.and B.S.Chissom,Forecasting enrollments with fuzzy time series—part I.Fuzzy sets and systems, 1993.54(1):p.1-9.
[2]Song,Q.and B.S.Chissom,Forecasting enrollments with fuzzy time series—part II.Fuzzy sets and systems, 1994.62(1):p.1-8.
[3]Zadeh,L.A.,B.Yuan,and G.J.Klir.Fuzzy sets,fuzzy logic,and fuzzy systems:selected papers by LotfiA.Za⁃deh.1996:World Scientific Publishing Co.,Inc.
[4]Chen,S.-M.Forecasting enrollments based on fuzzy time series.Fuzzy sets and systems,1996.81(3):p. 311-319.
[5]Teoh,H.J.,et al.,Fuzzy time series model based on probabilistic approach and rough set rule induction for empirical research in stock markets.Data&Knowl⁃edge Engineering,2008.67(1):p.103-117.
[6]Grzymala-Busse JW.A new version of the rule induc⁃tion system LERS[J].Fundamenta Informaticae,1997, 31(1):27-39.
猜你喜欢
成都信息工程大学学报(2021年6期)2021-02-12
传媒评论(2019年5期)2019-08-30
网络安全和信息化(2019年8期)2019-08-28
计算机系统应用(2019年2期)2019-04-10
传媒评论(2018年4期)2018-06-27
传媒评论(2018年4期)2018-06-27
传媒评论(2018年2期)2018-06-06
人民音乐(2016年3期)2016-11-07
现代电子技术(2015年2期)2015-09-18
重庆工商大学学报(自然科学版)(2015年3期)2015-05-25
