
基于支持向量机的花生荚果品种识别模型优化研究
2016-02-06 11:03于仁师孙华丽宋欣欣韩仲志青岛农业大学理学与信息科学学院山东青岛6609青岛出入境检验检疫局山东青岛6600
河南农业科学 2016年6期
于仁师,孙华丽,宋欣欣,韩仲志*(.青岛农业大学 理学与信息科学学院,山东 青岛 6609; .青岛出入境检验检疫局,山东 青岛 6600)
基于支持向量机的花生荚果品种识别模型优化研究
于仁师1,孙华丽1,宋欣欣2,韩仲志1*
(1.青岛农业大学 理学与信息科学学院,山东 青岛 266109; 2.青岛出入境检验检疫局,山东 青岛 266001)
为实现通过自动化手段进行花生品种真伪的鉴定,通过扫描仪采集了花生荚果侧面的图像,花生共20个品种,每个品种50个花生荚果,对采集的每幅图像提取形态、颜色、纹理方面的50个特征,首先通过主分量分析(PCA)对这些特征进行组合优化,然后采用RBF核函数搭建了支持向量机模型,最后通过网格搜索法、基因算法和粒子群方法优化支持向量机模型的惩罚参数c与gamma参数。优化结果表明,在主成分累积贡献率为95%时,PCA是10个主分量,3种参数优化方案中20个品种的5折交叉验证识别率分别为78.6%、77.6%、78.0%,识别效果相当,花生品种真伪的二分类识别率最高达到95%。优化后该模型对品种真伪的识别已经基本可以推广到实际生产中使用。
花生荚果; 品种识别; 支持向量机; 模型优化
我国花生产量居世界第一,花生品种识别是花生品种流通、种植和选育的关键。花生荚果形态特征[1]是花生DUS测试的主要性状,目前数据采集主要依靠目测和手工测量。图像处理技术通过采集种子外观特征数据,进而建立识别模型来鉴别不同品种。采用图像处理技术对花生品种进行识别,有助于提高品种识别自动化和精确度。
近年来,图像处理技术广泛应用于农产品的品种鉴别,主要应用于小麦[2]、水稻[3]和玉米[4-5]等粮食作物上,笔者前期将图像处理技术应用于花生仁的品质检测中[6],并在花生荚果图像品种识别与DUS测试研究方面做了有意义的探索[7]。然而在花生荚果种子品种识别检验过程中对模型的优化问题,鲜有文献提及。在前期工作[7]的基础上,本研究主要探讨了花生荚果识别过程中特征优化、参数优化、样本选择等问题对花生品种识别模型的影响,以期获得最优的花生荚果识别模型。
1 材料和方法
1.1 试验材料
供试花生品种共20个,均是农民自留种,品种采集区域为河北(冀花2号、冀花4号、冀花5号、中农108、天府3号),山东莱阳(潍花8号、花育22、矮2、莱农13号)、日照(101花生、小白沙、鲁花9号)、潍坊(p12、未知名3个品种)和青岛农业大学试验站(花育25、青花6号、鲁花11、16-2)。上述品种依次编号为1~20,这些品种主要为北方大果花生品种。每个品种选取正常无破损的带壳双粒荚果100个。
按固定次序将花生荚果摆放于扫描仪上,为使背景为黑色,扫描时打开扫描仪盖板,用扫描仪(佳能 CanoScan 8800F)进行图像扫描。图1为青岛农业大学选育的花生新品种青花6号的扫描图像。数据处理使用的计算机为联想ideaCentre Kx 8160,Winows XP操作系统。处理过程基于Matlab R2008a和LibSVM软件编程实现。
1.2 方法
提取的外观特征共分三大类50个特征(并对下面的特征进行编号1~50),其中形态类特征包括反映大小的特征(8个)和反映形状的特征(5个),共13个;反映颜色的特征24个;反映纹理的特征13个。 对这些特征的定义参见相关文献[7]。本研究所涉及的识别模型为支持向量机(SVM)模型[8],鉴于本研究需对多个品种进行识别,所以构建一个多类SVM分类模型,类别数为20。
图1 扫描图像样片(青花6号)
2 结果与分析
2.1 识别模型与结果
20个品种,每个品种50个荚果,每个荚果50个特征,共得到20×50×50的统计特征矩阵。基于这些统计特征分别使用SVM算法进行特征识别,由于特征数据量大,特征间会存在大量的信息冗余,所以在构建识别模型之前有必要进行数据降维和特征优化。在此选择了主分量分析(PCA)的特征优化方法,优化后主分量的个数作为二次特征,然后构建SVM算法进行品种识别。主分量个数的多少影响识别率,前10个主分量的贡献率和累积贡献率如图2(a)所示,此时测得累积贡献率接近95%,说明原始统计特征的主要信息集中在前面的主分量上。实际应用中,涉及的品种数目往往较少,采用更少的PCA特征如3~5个主分量即可得到较为满意的识别结果。图2(b)是基于PCA特征的SVM模型识别的结果,其中纵坐标是类别标签,当真实值和预测值重合时表示识别正确,非重合时表示识别错误。
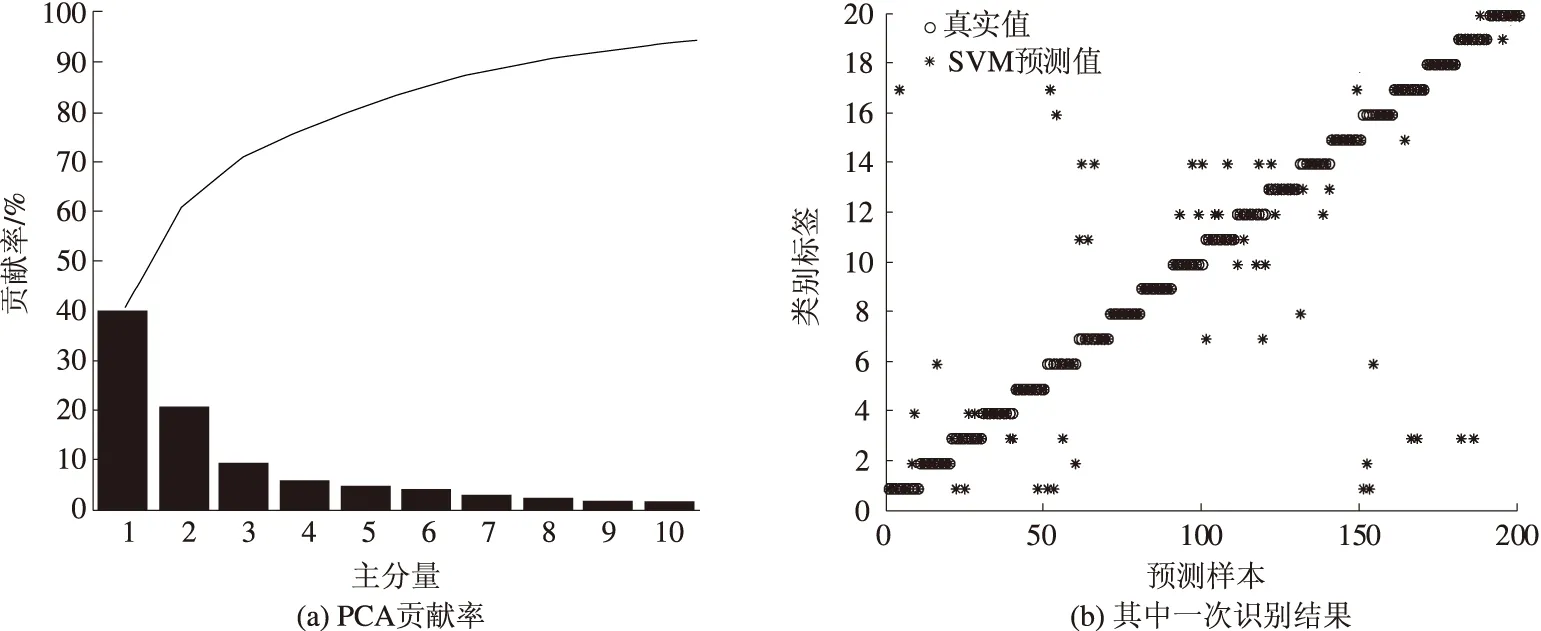
图2 主分量贡献率和识别结果
SVM模型采用RBF核函数。其中核函数的惩罚参数c默认为1,参数gamma(g)默认为特征数的倒数,1/20=0.05。采用5折交叉验证法进行试验,即在每个品种50个样本中随机选择40个作为训练集,剩余10个作为测试集,由于每次选择的训练样本和测试样本都是随机产生的,所以每次识别的结果都不同。通过5个指标衡量模型参数的优化性能,其中c和g默认分别取1和0.05,采用网格法优化得到的最佳参数分别为724.077 3和0.022 1,由表1可以看出,采用优化后的最佳参数,5个指标都得到了不同程度的提高,可见,通过优化可以得到最佳的识别模型,识别模型的参数严重影响识别模型的准确性能,合理优化参数是必要的。
表1 平均10次5折交叉验证的平均结果
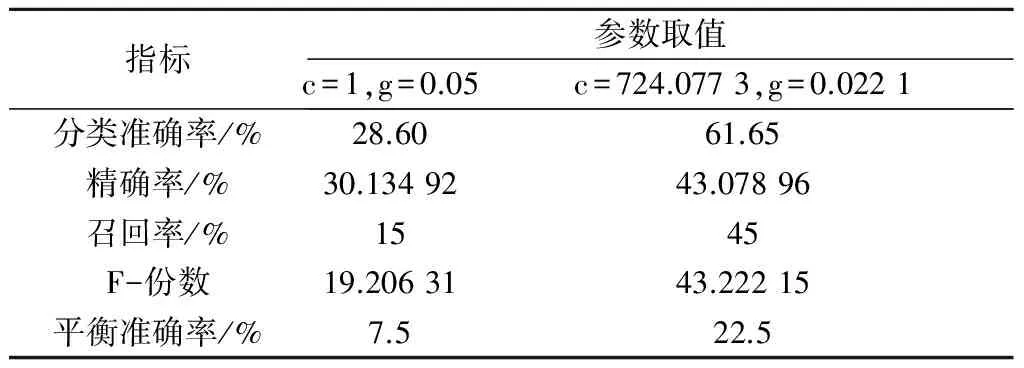
指标参数取值c=1,g=0.05c=724.0773,g=0.0221分类准确率/%28.6061.65精确率/%30.1349243.07896召回率/%1545F-份数19.2063143.22215平衡准确率/%7.522.5
2.2 参数优化方法对识别率的影响
SVM模型中选择使用C-SVC模型和RBF核函数时,模型的参数严重影响识别模型的效果,需要对识别模型的参数c和g进行优化,本研究选择3种方法进行参数优化。从表2可以看出,通过3种参数寻优方法,均可有效提高识别率,对20个品种的总体识别率都达到了70%以上。可见,3种优化方法得到的识别效果相当。
表2 3种优化算法的识别结果
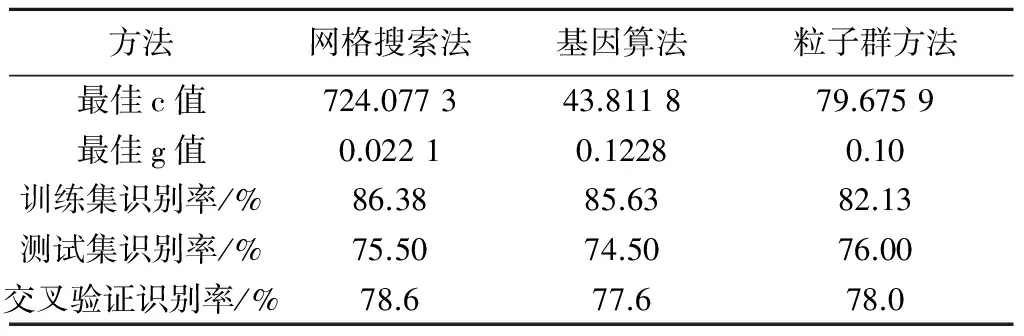
方法网格搜索法基因算法粒子群方法最佳c值724.077343.811879.6759最佳g值0.02210.12280.10训练集识别率/%86.3885.6382.13测试集识别率/%75.5074.5076.00交叉验证识别率/%78.677.678.0
注:表中数据为2次试验的平均结果。
2.3 样本和特征分析
试验发现,样本数的增加会带来识别率的下降,在类别较少时,如2个品种的二分类,PCA特征优化后识别率达到90%以上[图3(b)];当品种数量增加到20个时,识别率只有70%~80%(表2)。图3(a)是对2个类别采用交叉验证法测得的结果,其中颜色越深表示识别率越高;如品种编号5和19的识别率达到95%;图3(b)表示前2个主分量对这2个品种(编号5和19)的散点分布图,可以看出已经基本上做到线性可分。但必须说明,特征的增加并不能进一步提高识别率,所以有必要对特征参数进行适当优化。
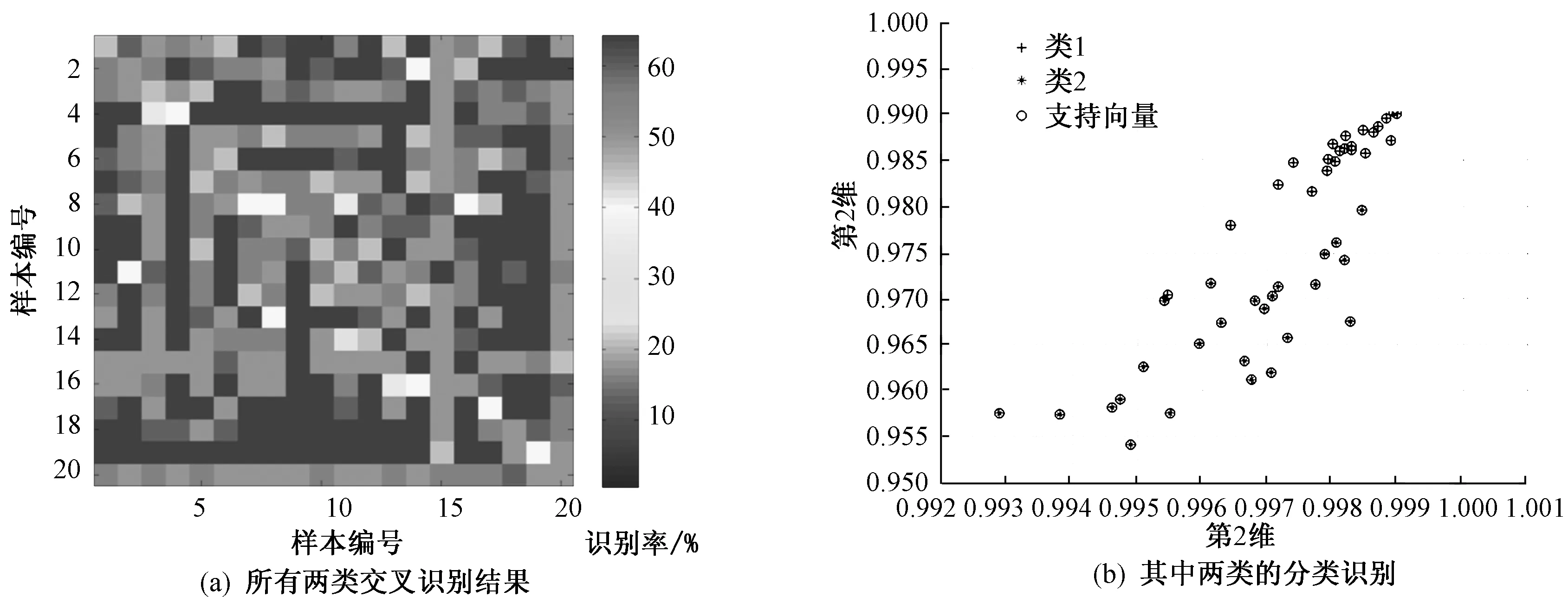
图3 两类识别结果
一种极端情况,特征的数量为1个或2个,当特征为1个,则可以从中找出一些优秀的特征,这些特征在进行花生品种DUS测试时十分有用,图4(a)为特征数量为1即进行单特征识别时,采用默认参数的SVM模型对20个品种五折交叉验证得到识别率的直方图,可见有3个特征的识别率达到了20%左右(第11、14、45个特征),有1个特征识别率最高,为25%(第27个特征),平均识别率为12.7%。特征增加时,如2个特征组合时,识别率分布图如图4(b)所示,可以看出,当有2个特征时,两两组合特征识别率有所增加,但提高幅度不明显,并且可以发现特征组合存在明显的条带特性,3个明显的条带出现在11、27、45左右,这与单特征识别率的趋势相同,说明提取优秀的特征仍是未来模式识别的核心内容。
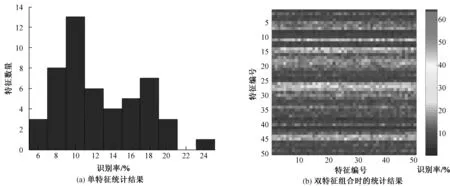
图4 特征数量对识别率的影响(数量为1和2)
3 结论与讨论
植物器官外观表现是细胞分裂、生长、分化与代谢相互作用的最终形态体现[4]。这是本研究基于外观图像进行花生荚果品种识别的理论基础。本研究表明,通过图像处理的方法,采用合适的识别模型能够对某一花生品种荚果的真伪进行有效鉴别。
特征的选择和优化方面,本研究基于PCA优化了特征参数,并得到了很好的效果,提高了模型识别的效率;模型的参数在很大程度上影响识别效果,在模型参数c和gamma的优化问题上,比较了3种参数寻优方法,结果表现出了大致相同的优化性能,然而,如果需要在优化算法中作出抉择,选择的依据是测试集识别率高的优化方案,这种方案的泛化能力要强一些,另外选择的依据是程序优化时间。
特征和样本数目多少在很大程度上影响着SVM模型的识别能力,本试验研究了单、双特征和两类分类的极限情况,对单个特征的考察可以发现花生荚果图像特征中有价值的品种性状,将其作为DUS候选性状[3],供遗传育种家参考。在现今市场上往往需要鉴别的是种子的真伪,所以两类问题的识别更具有现实意义。
本研究详细讨论了基于支持向量机的花生荚果识别过程中的模型优化问题,基于PCA的特征优化使得原来的50个特征降低到10个,提高了模型的效率,对C-SVC模型惩罚函数和RBF核函数的优化,使得识别率得到大幅提高,对特征的选择和识别样本的简化使得模型更符合生产实际需要。实现了花生品种鉴定与真伪识别的自动化,可将相关成果推广到实际生产中使用。
[1] 农业部植物新品种测试(广州)分中心.花生新品种DUS测试性状照片拍摄规范[S].北京:中国农业出版社,2010.
[2] Sakai N,Yonekawa S,Matsuzaki A,etal.Two-dimensional image analysis of the shape of rice and its application to separating varieties[J].Journal of Food Engineering,1996,27(4):397-407.
[3] Dubey B P,Bhagwat S G,Shouche S P,etal.Potential of artificial neural networks in varietal identification using morphometry of wheat grains[J].Biosystems Engineering,2006,95(1):61-67.
[4] 赵春明,韩仲志,杨锦忠,等.玉米果穗DUS性状测试的图像处理应用研究[J].中国农业科学,2009,42(11):4100-4105.
[5] 韩仲志,赵友刚,杨锦忠.基于籽粒RGB图像独立分量的玉米胚部特征检测[J].农业工程学报,2010,26(3):222-226.
[6] 韩仲志,赵友刚.基于计算机视觉的花生品质分级检测研究[J].中国农业科学,2010,43(18):3882-3891.
[7] 韩仲志,赵友刚.利用花生荚果图像特征识别品种与检验种子[J].作物学报,2012,38(3):535-540.
[8] Chang C C,Lin C J.LIBSVM:A library for support vector machines[DB/OL].[2015-03-01].http://wenku.baidu.com/view/b50dec6cb84ae45c3b358c18.html from=related.
Model Optimization of Peanut Varieties Recognition Based on Support Vector Machine
YU Renshi1,SUN Huali1,SONG Xinxin2,HAN Zhongzhi1*
(1.Science and Information College,Qingdao Agricultural University,Qingdao 266109,China; 2.Qingdao Entry Exit Inspection and Quarantine Bureau,Qingdao 266001,China)
In order to realize the identification of peanut varieties automatically,using scanner we collected the side images of peanut pods.Here were 20 varieties and each variety had 50 pods.For each image we extracted 50 characters of shape,color,and texture.First by principal component analysis (PCA) we did the combinatorial optimization on these characteristics,then using the RBF kernel function built a recognition model based on support vector machine,and finally,using the grid search,genetic algorithm and particle swarm methods optimized the penalty parameter C and gamma parameters of the support vector machine model.Optimization results showed that,when the principal component percentage was 95%,the number of principal components was 10.By the three parameter optimization methods,the recognition rates of five-fold cross validation were 78.6%,77.6%,78.0% separately for 20 varieties.If there were only 2 kinds of peanut cultivars,the highest classification recognition rate reached 95%.The method of identifying the authenticity of peanut varieties can be used in actual production.
peanut pods; varieties recognition; support vector machine; model optimization
2015-11-23
国家自然科学基金项目(31201133);青岛市科技发展计划项目(14-2-3-52-nsh);青岛市民生计划项目(13-1-3-107-nsh)
于仁师(1963-),男,山东莱阳人,副教授,本科,主要从事计算机应用研究。E-mail:yurenshi@163.com
*通讯作者:韩仲志(1981-),男,山东莒南人,副教授,博士,主要从事计算机视觉研究。E-mail:hanzhongzhi@qau.edu.cn
S126;S565.2
A
1004-3268(2016)06-0157-04
猜你喜欢
儿童时代·快乐苗苗(2022年10期)2022-12-09
花生学报(2022年1期)2022-08-16
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
草地学报(2019年2期)2019-05-31
农机化研究(2019年9期)2019-05-24
中国交通信息化(2018年3期)2018-06-13
儿童时代·快乐苗苗(2016年4期)2016-11-07
学苑创造·A版(2016年7期)2016-07-06
中国交通信息化(2016年2期)2016-06-06
