
特征和位置信息在价值驱动注意捕获中的作用*
2016-02-01 17:43白学军郭志英
心理学报 2016年11期
白学军 刘 丽,2 宋 娟 郭志英
(1天津师范大学心理与行为研究院, 天津 300074) (2天津商业大学心理系, 天津 300134)
1 引言
视觉场景中通常包含大量的信息, 而大脑加工这些信息的能力有限, 所以需要选择一些信息进行加工(Reynolds, Chelazzi, & Desimone, 1999)。注意选择决定了哪些信息能够获得加工并进入到更高级的认知过程, 如推理、决策和记忆存储。人类的注意系统选择和抑制信息, 偏向任务相关或高度突显的客体和特征(Corbetta & Shulman, 2002;Serences & Yantis, 2007)。目标驱动和突显驱动的注意选择都具有适应价值(Chelazzi, Perlato, Santandrea,& Della Libera, 2013), 能够使总体利益最大化(Laurent, 2008)。
但是, 在某种情境中, 最具价值的刺激既不是当前任务目标, 在物理上也不具有突显性。这种情况下, 如果注意选择只考虑目标和突显因素将会使个体失去获得价值的机会。所以, 为了更好地生存,注意系统选择和价值相联结的刺激具有重要意义(Anderson, 2013)。价值的形成主要是通过将刺激与金钱奖励建立联结来实现, 与奖励相联结的刺激特征对注意选择的影响体现在以下三个方面:
第一, 与奖励相联结的刺激特征能够启动注意选择。表现为在启动范式的搜索任务中, 和高奖励相联结的刺激特征能够增加试次间启动(Hickey,Chelazzi, & Theeuwes, 2010; Kristjánsson, Sigurjónsdóttir,& Driver, 2010)。例如, Hickey等(2010)让被试搜索形状奇异项目标, 其中一个非目标形状为物理突显的颜色奇异项分心物。被试在n-1试次中正确识别形状奇异项目标会随机获得高或低的金钱奖励。在n试次中, 目标与分心物的颜色与n-1试次中目标和分心物的颜色是重复的或互换的, 且反应不再伴随金钱奖励。结果表明在高奖励后出现大的启动效应, 而在低奖励后启动效应消失或反转。
第二, 奖励能够调节目标选择的有效性。与奖励相联结的刺激特征在快速系列视觉呈现任务(Raymond & O’Brien, 2009; Yokoyama, Padmala, &Pessoa, 2015)和视觉搜索任务中(Störmer, Eppinger,& Li, 2014)能够促进目标的选择, 并减少任务无关信息的抑制(Krebs, Boehler, & Woldorff, 2010)。例如, Raymond和O’Brien (2009)的研究中, 在训练阶段, 被试学习把不同的面孔和不同的金钱奖励结果建立联结。这些面孔在接下来的注意瞬脱任务中作为目标出现。以前和高金钱奖励或高金钱损失相联结的面孔当作为第二个目标出现时, 相对其它面孔能够更加正确的被报告, 表明它们获得了高的注意优先性。
第三, 以往奖励学习中和奖励建立联结的刺激特征, 当不再能够预测奖励结果时仍然能够无意识的捕获注意(Anderson, Laurent, & Yantis, 2011a,2011b)。Anderson等(2011b)采用训练−测试两阶段范式, 在训练阶段要求被试在6个不同颜色的圆环中搜索红色或绿色的目标圆环, 并对目标圆环里的线段方向(水平或垂直)进行判断, 被试在规定的时间内正确反应将会获得高(10¢)或低(1¢)的金钱奖励反馈。重要的是, 在训练阶段将不同的颜色分别和高、低两种金钱奖励建立联结。如:对于一半被试来说, 对红色目标进行反应在80%的试次中会获得高奖励, 在20%的试次中会获得低奖励; 对绿色目标进行反应在80%的试次中会获得低奖励, 在20%的试次中会获得高奖励。另一半被试恰恰相反。Anderson等(2011b), Anderson (2013)认为, 被试在训练阶段学习将每个目标颜色和一种奖励结果建立联结, 其中一种颜色相对于另一种颜色能够获得更高的金钱奖励。在训练阶段之后, 被试完成测试阶段, 测试任务中被试搜索一个物理突显的形状奇异项(如, 很多个方形中的唯一一个圆形), 并对目标形状里的线段方向进行判断。搜索任务包括6个不同颜色的形状刺激。在50%的试次中, 其中一个非目标形状的颜色为训练阶段和奖励建立联结的颜色(红色或绿色), 要求被试忽视颜色特征,并且反应后不再给予奖励反馈。结果发现训练阶段和高奖励相联结的刺激特征当在测试阶段作为分心刺激出现时, 即使不具有突显性, 并且是任务无关的, 仍然能够捕获注意。这种效应只能归结为训练阶段的颜色−奖励联结, 和高奖励联结的刺激特征获得了注意优先性。ERP的N2pc指标也表明这种捕获是无意识的、基于空间的(Qi, Zeng, Ding, &Li, 2013)。这种现象叫作价值驱动的注意捕获, 是一种独立于突显驱动和目标驱动的注意选择机制(Anderson et al., 2011b)。训练任务中和奖励相联结的刺激所产生的捕获效应可泛化到其它任务中(Anderson, Laurent, & Yantis, 2012; Lee & Shomstein,2014); 并且, 训练阶段学习到的刺激−奖励联结效应可以保持很长时间(Anderson & Yantis, 2013;Della Libera & Chelazzi, 2009)。个体不仅能够将任务相关特征和奖励建立联结, 也能够将任务无关特征和奖励建立联结(Mine & Saiki, 2015)。
以上关于奖励影响注意选择的研究都是将奖励和低水平的视觉特征建立联结。被试所获得的奖励依赖于颜色搜索任务(Anderson et al., 2011a,2011b; Sali, Anderson, & Yantis, 2014)和stroop任务中(Krebs et al., 2010)的颜色、负启动任务或形状搜索任务中的形状(Della Libera & Chelazzi, 2009;Wang, Yu, & Zhou, 2013)、方向搜索任务中的方向(Laurent, Hall, Anderson, & Yantis, 2015; Lee &Shomstein, 2014), 而不考虑它们呈现的位置。Camara, Manohar和Husain (2013) 使用眼动技术考察了奖励对位置选择的影响。眼动研究采用双任务范式, 每个试次开始时, 被试将眼睛定位到两个位置(同样颜色的两个圆)中的一个。定位到其中一个位置会获得奖励, 定位到另外一个位置会获得惩罚,被试在进行眼动前不能预测奖励结果。奖励反馈后,被试需要完成第二个视觉搜索试次, 将眼睛移动到绿色目标上, 同时忽略粉色的分心物。结果表明当分心物出现在前一个试次被奖励的位置时, 被试的眼动指向分心物位置的可能性增加, 这表明奖励能够独立于特征而启动位置。Hickey, Chelazzi和Theeuwes (2014)采用了相同的启动范式, 反应时结果表明当目标选择获得了奖励结果时, 注意在接下来会返回到目标位置, 并从以前突显的、任务无关的分心物所在的位置转移。这些结果表明奖励能够通过启动视觉刺激的空间位置来引导视觉搜索。奖励不仅引发了眼跳行为, 而且引发了内隐的注意或知觉表征的分配。
采用训练−测试两阶段范式, Chelazzi等(2014)发现通过联结性的奖励学习能够引发注意偏向更加具体的空间位置。他们将空间划分为8个具体的位置(以方框标志), 在训练阶段, 将出现在不相邻的两个特定位置的目标与相对高的金钱奖励建立联结时, 发现测试阶段在两个高奖励位置出现的目标能够更快的, 更正确的被报告。他们认为基于奖励的学习会导致空间优先性地图发生变化, 这种变化是长期的、无意识的。但是, Chelazzi等(2014)的研究中测试阶段采用的是快速搜索任务, 并且需要被试在两个目标同时出现的境况下的进行竞争反应, 并没有考察当分心物出现在高奖励位置时是否会捕获注意。
所以, 本研究的第一个目的是采用训练−测试范式, 考察是否存在基于具体位置的价值驱动的注意捕获效应。在实验1中, 训练阶段将不同的具体位置分别和高、低金钱奖励建立联结, 而其余的位置不和奖励建立联结。在测试阶段考察当分心物出现在高奖励位置时, 和出现在其它位置时相比能否产生捕获效应。
虽然已有研究表明联结性的奖励学习能够分别影响刺激特征和空间位置的注意优先性, 但是两者结合在一起时将怎样影响注意偏向?Anderson(2015b)探讨了这个问题:在训练阶段, 将颜色和空间位置信息联合起来进行学习, 例如, 对左半部出现的红色目标进行正确反应伴随着高奖励反馈, 而对右半部出现的绿色目标进行正确反应伴随着低奖励反馈, 在随后的测试阶段发现, 只有高奖励颜色出现在高奖励位置时才能捕获注意, 而高奖励颜色出现在低奖励位置时不能捕获注意。他采用相同的实验范式, 将空间位置信息换成空间情境信息也得到了相似的结果(Anderson, 2015a)。例如, 被试在测试阶段对森林情境中的红色目标进行反应伴随着高奖励反馈, 而对城市情境中红色目标反应伴随着0奖励反馈, 对于绿色目标来说恰恰相反, 在测试阶段发现只有高奖励颜色出现在高奖励情境下才能产生注意捕获效应。因此, 他认为, 颜色特征产生的注意捕获效应受到空间信息的调节。但是,我们认为, Anderson (2015a, 2015b)的研究虽然将刺激特征和空间信息结合起来考察两者在价值驱动的注意捕获中的交互作用, 但是存在缺陷。在测试阶段, 颜色分心物不是出现在高奖励位置(或情境),就是出现在低奖励位置(或情境), 而没有设置颜色分心物出现在中性奖励位置(或情境)的条件。
所以, 本研究的第二个目的是改进Anderson(2015b)的实验设计, 在训练阶段将颜色和具体的空间位置联合起来与奖励建立联结, 但是在测试阶段将颜色和位置独立开来, 考察当与高奖励相联结的颜色出现在中性位置时能否捕获注意。已有研究表明联结性的奖励学习对注意的影响具有泛化性,能够转移到不同的刺激和情境下, 当训练阶段和测试阶段的刺激、任务要求、反应方式不同时, 仍然能够发现注意捕获效应(Anderson et al., 2012)。这种基于价值的注意选择的泛化具有适应性, 使有机体能够在新情境中最大化的利用之前的学习。在此基础上, 我们预测实验2中, 颜色将能够独立于空间位置而产生价值驱动的注意捕获效应。
2 实验1
实验1的范式是将Chelazzi等(2014)与Anderson(2015b)的范式相结合。将空间位置划分为8个区域。在训练阶段, 8个区域的每个区域内分别出现一个有颜色的圆环, 被试在不同颜色的非目标圆环中搜索一个红色的圆环, 并对圆环里的线段方向进行判断。每个试次正确反应后会获得金钱奖励反馈,其中两个不相邻位置和高奖励建立联结, 而另外两个不相邻位置和低奖励建立联结, 其余的4个位置不出现目标, 也就是不与奖励建立联结(例子见图1)。告知被试目标出现的位置, 但是不告知被试目标位置与奖励的联结规律。测试阶段采用形状奇异项搜索任务, 被试在8个不同颜色的图形中搜索一个唯一的图形, 图形分布的位置与训练阶段相同。告知被试目标出现在和测试阶段不同的另外4个位置上,这样就保证在测试阶段, 颜色和位置信息都是任务无关的。在一半试次中, 其中一个非目标的形状颜色为红色。告诉被试颜色是任务无关的需要忽略,而且目标永远不是红色的。在测试阶段没有奖励反馈。

图1 实验1位置−奖励联结示意图
在实验1中我们想考察红色分心物的出现是否会捕获注意, 使搜索目标的反应时变慢。如果学习到的价值增加了处于高奖励位置的目标的物理突显性, 那么在测试阶段, 分心物出现在高奖励联结位置相对于分心物出现在其它位置来说能够产生注意捕获效应。
2.1 研究方法
2.1.1 被试
20名本科生参加实验(男生7名, 女生13名,平均年龄为19.60 ± 0.82岁, 年龄跨度为19~22岁)。所有被试的视力或矫正视力正常, 无色盲或色弱。训练阶段所获得的奖励反馈作为被试的报酬, 平均为51.95元。所有被试先完成训练任务, 休息10 min后完成测试任务。
2.1.2 实验仪器
实验刺激呈现在17寸联想台式计算机上, 屏幕分辨率为1024×768, 背景为黑色。采用E-prime 2.0编程。被试在微亮的实验室里单独参加测试, 眼睛距离屏幕约55 cm。
2.1.3 训练阶段
刺激
每个试次由注视屏、搜索屏和反馈屏组成(见图2A)。注视屏为呈现在屏幕中心的白色注视点“+” (0.63°× 0.63°), 搜索屏为中心注视点和周围8个不同颜色的圆环(直径2.14°), 圆环粗4磅(0.13°)。8个圆环组成一个虚拟的大圆(直径为11.42°), 每个圆环中心距离中心注视点为4.73°。每相邻两个圆环间距离相等, 圆环分别处于中心注视点的垂直线顺时针和逆时针旋转22.5°、67.5°、112.5°和157.5°。目标是红色圆环(RGB, 255, 0, 0),在每个试次中都出现, 非目标圆环的颜色分别为绿色、蓝色、粉色、橘色、黄色、白色和紫色。每个圆环里包含一个白色线段(1.30°×0.11°), 目标圆环里的线段为垂直或水平, 非目标圆环里线段的方向可能是向左或右倾斜45°, 也可能是水平或垂直,随机选择。反馈屏呈现本试次所获得的金钱奖励的数量和累积的总奖励数量。设计
目标出现在8个位置中的4个位置, 被试在规定的时间内对目标圆环中的线段进行正确判断将会获得金钱奖励(奖励与位置的联结见图1)。为了消除位置对搜索目标的影响, 同时保证在测试阶段高、低奖励位置在不同被试间是不固定的, 奖励和位置的联结有4种方式:分别为左上、左下−高奖励, 右上、右下−低奖励; 右上、右下−高奖励,左上、左下−低奖励; 左上、右上−高奖励, 左下、右下−低奖励; 左下、右下−高奖励, 左上、右上−低奖励。将20名被试平均分配到4种条件下, 每种条件下5名被试。在高奖励条件下, 80%的试次得到0.15元反馈, 20%的试次得到0.01元反馈, 低奖励条件则相反。但是告知被试奖励是依据反应时分配的, 正确反应越快, 越有可能得到高奖励。目标永远不会出现在其它4个位置, 我们把这些位置叫做中性位置, 被试不能预测目标出现在这些位置将会获得什么样的奖励。中性位置和目标位置交替分布。
图2 实验流程示意图
程序
训练阶段包含12个block共672个正式试次和1个block的56次练习。实验流程如图2A所示, 每个试次开始是呈现注视点, 呈现时间在400~600 ms之间随机变化。然后呈现搜索屏, 时间为1500 ms或直到被试反应, 如果被试没有及时反应则认为是超时, 计算机自动进入下一个步骤。搜索屏后是1000 ms的空屏, 然后是1500 ms的奖励反馈, 随后是1000 ms的空屏, 然后呈现下一个试次。要求被试将左右手的食指分别放在“c”和“m”键上, 垂直按“c”键, 水平按“m”键。正确的反应伴随着0.15元或0.01元的奖励, 获得哪种奖励依赖目标所在的位置。反应错误会得到“错误”的反馈提示,反应太慢(没有在1500 ms之内进行反应)会得到“反应太慢”的反馈提示, 呈现时间也为1500 ms。被试在每个block之间可以进行短暂休息。训练阶段约60 min。练习试次不提供金钱奖励的反馈, 只提供正确与否的反馈, 目的是为了让被试熟悉反应规则。2.1.4 测试阶段
刺激
每个试次包含注视屏、搜索屏和反馈屏(如图2B所示)。注视屏与训练阶段相同。搜索屏为8个不同颜色的图形, 呈现位置与训练阶段相同,可能是7个方形(对角线为2.62°)和1个圆形(直径为2.14°), 或者是7个圆形和1个方形, 目标是唯一的形状奇异项(方形或圆形), 测试阶段中非目标图形的颜色在训练阶段的基础上增加了蓝绿色。在一半试次中, 其中一个非目标形状的颜色被训练阶段和奖励建立联结的目标颜色(红色)所取代, 叫做有价值的分心物。如果被试反应正确, 不给予反馈,如果被试反应错误或者反应超时, 会有“错误”或“反应太慢”的提示。设计
在测试阶段, 目标随机呈现在4个中性位置上。当目标呈现在其中一个位置时, 分心物随机出现在其它7个位置。目标为方形或圆形的次数相等且在试次间随机变化。在一半试次中会出现红色(有价值的)分心物, 一半试次中不出现红色分心物。程序
测试阶段包含6个block共336次正式试次和1个block的56次练习。练习时红色分心物不出现, 对被试的反应是否正确给予反馈, 正式实验不再给予反馈。实验流程图如图2B所示, 每个试次开始呈现注视点, 在400~600 ms之间随机变化。然后呈现搜索屏, 呈现时间为1500 ms或者直到被试反应, 如果被试没有及时反应则认为是超时,计算机自动进入下一屏。然后是1000 ms的空屏,然后呈现下一个试次。在指导语中告知被试测试阶段的任务和训练阶段无关, 告知被试目标出现在中性位置, 要求被试忽略颜色。反应和按键规则与训练阶段相同。被试在每个block之间可以进行短暂休息。测试阶段约30 min。2.1.5 实验结束后的问题
在实验结束后, 给被试呈现空间位置示意图,要求被试对训练阶段的奖励−位置联结进行自由选择。
2.1.6 数据分析
删除每个被试正负3个标准差以外的数据, 删除的数据占总数据的1.08%。对正确反应时和错误率进行分析。
2.2 结果

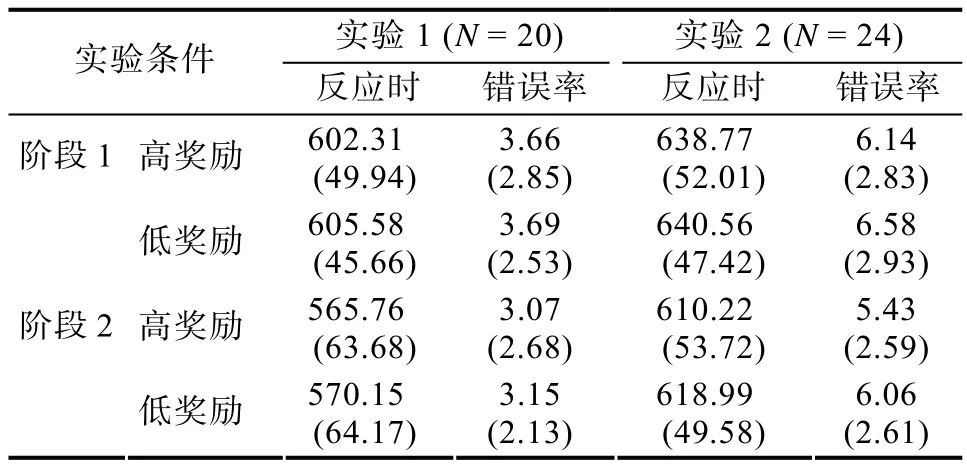
表1 实验1和2训练阶段目标位置的平均反应时(ms)和错误率(%)
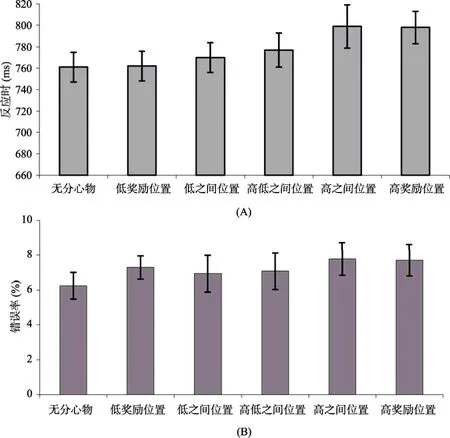
图3 实验1测试阶段各种位置上的反应时(A)和错误率(B)

对附加问题进行统计, 表明在20个被试中有6人能够完全正确的回答奖励与位置的联结; 有7人能够进行部分正确的联结; 有5人放弃填写; 另外2人进行错误的联结。
2.3 讨论
实验1结果表明当分心物出现在高奖励联结位置时能够捕获注意, 而分心物出现在低奖励联结位置时和无分心物条件下的反应时没有差异, 不能捕获注意。另外, 我们也发现, 当分心物出现在两个高奖励位置之间的中性位置时也能够捕获注意, 这表明高奖励位置所获得的注意捕获效应能够泛化到特定的邻近位置。这与Chelazzi等(2014)的研究结果不一致, 他们的结果表明两个高奖励位置之间的位置不能获得注意优先性。对于本研究中出现的位置泛化可有两种解释。第一, 在训练阶段, 我们将两个不相邻位置和高奖励建立联结, 虽然在指导语中明确告知被试目标不会出现在中性位置, 但是被试在进行学习时采用了简单化原则, 将两个位置之间的区域作为一个整体, 与高奖励反馈建立了联结, 因而提高了整个区域的注意优先性。第二, 这种注意捕获效应是在测试阶段出现的。高奖励联结的位置获得了注意优先性, 增加了处在这个位置的特征的突显性。被试在测试阶段将注意转移到了高奖励位置的刺激, 而在高奖励位置附近的位置呈现的刺激也连带捕获了注意, 而处在中间的位置能够同时获得相邻两个高奖励位置的扩散效应, 因而产生了显著的注意捕获效应。以往研究也表明, 价值驱动的注意捕获效应能够扩散到邻近的空间位置(Wang, Duan, Theeuwes, & Zhou, 2014)。而Chelazzi等(2014)的研究中, 训练阶段, 目标出现在所有位置, 当出现在我们研究范式中的中性位置时, 获得高、低奖励的几率各有50%。也就是说, 被试在训练阶段已经将这些位置和中等程度的奖励建立了联结, 这些位置并不是中性的, 所以被试在训练阶段无法再将两个位置之间的区域作为一个整体, 在测试阶段高奖励联结位置所获得的注意优先性也无法扩散到这些位置。所以, 实验1所设置的中性位置并不都是中性的, 根据第一种解释, 只有高低奖励位置之间的位置才是中性位置(被试也将低奖励位置之间的区域作为一个整体, 与低奖励建立了联结); 根据第二种解释, 高低奖励之间的位置和低奖励之间的位置都是中性位置。总的来说, 实验1结果表明, 将奖励反馈与更加具体的位置建立联结,不仅能够使注意偏向这些具体位置, 还能偏向特定的邻近位置, 价值驱动的注意捕获效应在位置上表现出一定程度的泛化。
3 实验2
在实验1范式的基础上, 我们设计了实验2。在训练阶段被试将颜色−位置联合起来与奖励建立联结。例如, 其中两个不相邻位置出现的红色目标和高奖励反馈建立联结, 而另外两个不相邻位置出现的绿色目标和低奖励反馈建立联结。测试阶段的任务与实验1基本相同, 区别是在1/3试次中, 训练阶段的目标颜色不出现; 在1/3试次中, 其中一个非目标形状的颜色被训练阶段的高奖励颜色替代; 在剩下1/3试次中, 其中一个非目标形状的颜色被训练阶段的低奖励颜色替代。有价值的颜色分心物可能出现在高奖励联结位置、低奖励联结位置或中性位置。
在实验2中我们想考察颜色和位置在价值驱动注意捕获中的交互作用。如果颜色能够独立于位置而产生价值驱动的注意捕获效应, 那么高奖励颜色不仅出现在高奖励位置时能够捕获注意, 出现在高低奖励之间的中性位置时也能够捕获注意。
3.1 方法
3.1.1 被试
没有参加过实验1的24名大学生参加了实验2(男生9名, 女生15名, 平均年龄为19.83 ± 0.96岁, 年龄跨度为19~22岁)。所有被试的视力或矫正视力正常, 无色盲或色弱。训练任务所获得的奖励反馈作为被试的报酬, 平均为33.74元。所有的被试先完成训练任务, 休息10 min后完成测试任务。
3.1.2 仪器
仪器同实验1。
3.1.3 训练阶段
刺激
与实验1相同, 每个试次包含注视屏、搜索屏和反馈屏。与实验1的区别仅在于目标为红色或绿色的圆(实验1目标只有红色的圆), 在每个试次中随机出现。设计
颜色和位置不能单独预测奖励, 奖励的高低由目标颜色和目标位置的联合特征所预测。位置与奖励的联结规律与实验1相同, 但是增加了颜色。如, 对于一些被试来说, 对出现在左上和左下位置的红色目标反应伴随高奖励反馈, 对出现在右上和右下位置的绿色目标反应伴随着低奖励反馈(如图4所示)。与实验1相似, 为了平衡目标位置和颜色对搜索反应时的影响, 我们将颜色和位置与奖励的联结分为8种条件, 每种条件下分配3名被试。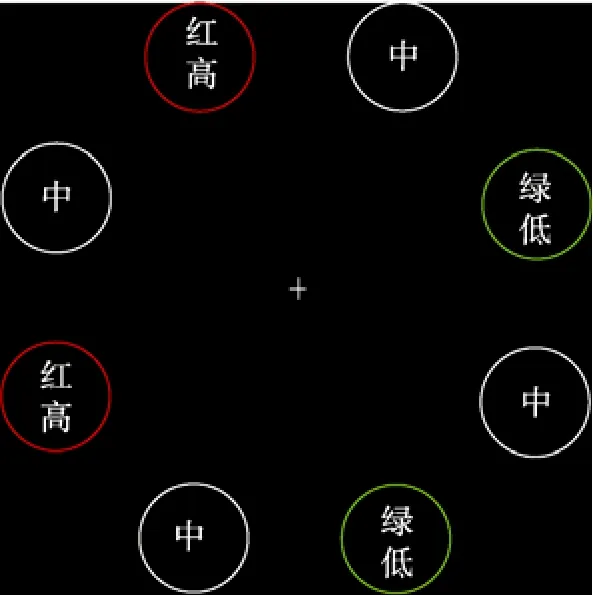
图4 实验2颜色、位置−奖励联结示意图
程序
与实验1相同。区别是训练阶段包含8个block共448个正式试次和1个block的56次练习。训练阶段约40 min。3.1.4 测试阶段
刺激
每个试次包含注视屏、搜索屏和反馈屏,与实验1相同。不同之处在于有价值的分心物为红色或绿色(实验1只有红色), 随机出现, 位置随机分配。设计
与实验1相同。区别在于在1/3试次中出现高奖励联结颜色分心物, 1/3试次中出现低奖励联结颜色分心物, 1/3试次中不出现有价值的分心物。程序
与实验1相同。区别在于实验2测试阶段由9个block共504次正式试次和1个block的56次练习组成。测试阶段约45 min。3.1.5 实验结束后的问题
在实验结束后, 给被试呈现空间位置示意图,要求被试对训练阶段的颜色、位置−奖励联结进行自由选择。
3.1.6 数据分析
删除每个被试正负3个标准差以外的数据, 删除的数据为总数据的1.12%。对正确反应时和错误率进行分析。
3.2 结果
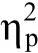
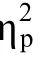
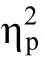

图5 实验2各种位置上的反应时(A)和错误率(B)
对错误率进行了同样的分析, 2(颜色:高奖励和低奖励)×5(位置:高奖励、高之间、高低之间、低奖励、低之间)重复测量方差分析结果表明主效应和交互作用均不显著; 将测试阶段呈现在每个位置上的3种分心物条件(高奖励颜色分心物、低奖励颜色分心物、无分心物)下的错误率分别进行单因素重复测量方差分析, 结果表明主效应均不显著(结果见图5B)。
对附加问题进行统计, 表明在24个被试中有10人能够完全正确的预测奖励与颜色和位置之间的联结; 有6人能够进行部分正确的联结; 有8人放弃选择, 表示没有印象。
3.3 讨论
实验2中, 训练阶段将颜色和位置信息联合起来分别和高、低奖励建立联结, 结果表明只有高奖励联结颜色出现在高奖励位置和高奖励位置之间的中性位置时能够捕获注意, 而低奖励颜色出现在高奖励位置或高奖励位置之间的中性位置或者高奖励颜色出现在低奖励位置都不能捕获注意。对于高奖励颜色出现在高奖励之间的中性位置能够捕获注意, 这个结果与实验1结果一致, 说明高奖励之间的中性位置获得的捕获效应并不是由于高奖励颜色所引起的, 而是由于位置本身引起的泛化。重要的是, 我们发现, 高奖励联结颜色分心物出现在高、低奖励位置之间的中性位置时不能捕获注意,这说明个体在学习阶段所获得的联合特征不能泛化到独立特征上。总的来说, 实验2表明高奖励颜色不能独立于高奖励位置而捕获注意, 不支持价值驱动在不同特征之间的泛化。
4 总讨论
本研究表明当出现在某个空间位置的刺激特征(颜色)和高的金钱奖励反馈建立联结时, 在随后的任务中, 刺激特征只有呈现在高奖励位置或者高奖励位置之间的中性位置时才能捕获注意。而且当将颜色特征和空间位置联合起来进行学习时, 在测试阶段发现只有高奖励颜色特征出现在高奖励位置和高奖励位置之间的中性位置时才能捕获注意,而当高奖励联结颜色特征出现在高低奖励之间的中性位置时则不能捕获注意。
在实验1中, 训练阶段, 同一个红色特征目标出现在某两个位置时选择性的伴随高奖励反馈, 而出现在另两个位置时伴随低奖励反馈。在测试阶段,发现拥有这个特征(红色)的分心物出现在高奖励位置时能够捕获注意。这与Anderson (2015b)采用左右两半部位置的研究结果一致。他们的研究结果表明, 只有奖励联结分心物出现在高奖励部分时能够捕获注意, 而出现在低奖励部分时不能捕获注意,确实存在基于位置的价值驱动的注意捕获。在实验1中, 我们通过实验设计将空间位置进行了更加具体的划分, 结果表明价值驱动的注意捕获不仅出现在具体的空间位置, 而且也出现在特定的邻近空间位置。这个结果拓展了Chelazzi等(2014)的研究, 不仅在快速识别的竞争性任务中和高奖励联结位置作为目标时能够促进反应, 当作为分心物时也能够干扰对目标的搜索, 产生注意捕获效应。并且, 这种效应存在一定程度上的泛化。Della Libera和Chelazzi (2009)采用启动范式, 将n-1试次中和高或低奖励联结的刺激在n试次中既作为目标又作为非目标出现, 结果也表明以前和高奖励联结的刺激在作为目标时能够被更快的识别, 在作为分心物时能够被更慢的识别, 而和低奖励联结的刺激恰恰相反。
在实验1中, 红色不能预测奖励的高低, 但是红色对于价值驱动的注意捕获的产生仍然是至关重要的, 因为它是目标定义的特征, 所以, 在学习阶段进行奖励联结时, 被试也将红色这个特征纳入到了奖励联结体系中。也就是说, 基于位置的注意捕获效应的产生是以颜色的出现为前提的。早在Treisman (1992)的特征搜索研究中就表明当目标定义的特征和位置都重复时, 被试对具有单一视觉特征的目标的反应变快, 说明位置启动可能依赖于目标定义特征的重复。在实验1中, 我们也发现基于位置的价值驱动的注意偏向只局限于以前和目标相联结的特征。这个结果看似和以前报告的注意偏向能够预测奖励位置的结果矛盾(Chelazzi et al.,2014), 他们的结果表明即使没有颜色特征, 被试也会产生基于位置的价值驱动的注意选择效应, 被试在测试阶段对高奖励位置呈现的目标的搜索反应时变快。但是他们的研究采用的是同质的颜色,颜色不是目标定义的特征; 而在我们的实验1中,颜色为目标定义的特征, 虽然在整个实验不变(都是红色的), 但会使相同的颜色和不同的位置绑定起来去预测奖励, 这和Chelazzi等(2014)只将位置和奖励联结起到的效果是相同的。第二, 在我们的实验1中, 测试阶段的目标被定义为形状奇异项,是相对突显的特征, 这鼓励被试在整个刺激系列广泛的分布注意; 而在Chelazzi等(2014)的研究中,测试阶段被试的任务是寻找数字或字母, 目标的突显性不是很强。
在实验1中, 训练阶段的目标特征作为分心物出现在高奖励联结的位置时能够捕获注意, 表明存在基于位置的价值驱动的注意捕获效应, 并且在位置上表现出一定程度的泛化。在实验2中, 我们考察当颜色特征和空间位置联合起来预测奖励时会获得什么样的结果。在训练阶段, 目标特征和位置不能独立预测奖励, 只有两者联合起来才能预测奖励:某个特征出现在某个位置时才能获得奖励。结果发现只有高奖励颜色出现在高奖励位置和高奖励位置之间的中性位置时能够捕获注意, 而高奖励颜色出现在其它中性位置和低奖励位置时都不能捕获注意, 表明被试在训练阶段不是形成两个独立的偏向:一个是和奖励相联结的特征, 一个是和奖励相联结的位置。而是将颜色和位置结合起来与不同的奖励建立联结, 颜色和位置共同引导注意。
本研究采用了修改的实验设计, 实验结果与Anderson (2015a,2015b)的结果基本一致, 表明空间位置和颜色特征对价值驱动的注意捕获的产生都很重要。如果在训练阶段不考虑位置, 只将颜色与奖励联系起来, 那么它们能够在所有的空间位置产生相等的注意捕获(Anderson et al., 2011a, 2011b;Lee & Shomstein, 2014; Qi et al., 2013)。同时, 如果将颜色特征和空间位置联合起来进行学习, 那么颜色与位置共同决定了的注意优先性。
关于颜色特征和位置信息在价值驱动的注意捕获中的作用机制, Anderson (2015b)进行了两种推论性解释:第一, 颜色特征和空间位置的联合才能产生引导注意选择的偏向信号。第二, 奖励−联结的颜色特征总是能够产生偏向信号而不管它呈现在什么位置, 但是当特征所处的情境(位置)预测价值低时, 这种偏向信号会被抑制。如果第二种解释成立, 那么当高奖励联结的颜色出现在高、低奖励位置之间的中性位置时, 位置的偏向信号不会被抑制, 而颜色的偏向信号仍然存在, 那么可以推测当高奖励颜色出现在这些中性位置时仍然能够捕获注意, 但是实验2的结果不支持这点。而且, 如果颜色特征和位置信息所产生的注意捕获效应是独立的, 那么我们可以推测, 实验2所产生的捕获效应是颜色特征和位置信息两者捕获效应的叠加, 所以相对于实验1会有显著增加。在本研究实验1中,分心物出现在高奖励位置的捕获效应(与无分心物出现条件相比)为37 ms, 在实验2中, 将颜色与位置联合起来学习, 测试阶段高奖励颜色出现在高奖励位置所获得的捕获效应为33 ms, 独立样本t
检验表明两种情况下的捕获效应差异不显著,t
(43) < 1。本研究结果表明:将单一位置与奖励建立联结时, 价值驱动的注意捕获效应在位置上表现出一定程度的泛化(实验1), 而将联合特征与奖励建立联结时, 价值驱动的捕获效应不能泛化到个别特征上(实验2)。这说明价值驱动注意捕获的泛化具有选择性。实验1与实验2的不同之处在于:在实验1中, 训练阶段泛化的位置为中性位置, 不能预测奖励, 因而能够泛化到这个中性位置。这也与以往表明基于价值的注意优先性可以泛化到不同刺激、位置和任务的研究结果相一致(Anderson et al., 2012;Lee & Shomstein, 2014)。在这些研究中, 只有颜色特征能够预测奖励结果, 而位置、任务、刺激都作为背景信息。在这种情况下, 注意系统会忽略那些不能预测奖励的信息, 只进行关键的表征, 所以产生泛化现象。但是在实验2中, 当位置信息也能够预测奖励时, 个体就会将位置信息整合到注意系统中, 因而不会产生泛化现象。从这个角度说, 有机体在新的情境中能够较精确的利用以前所获得的学习结果, 能够产生一定程度的泛化, 但又避免了学习的过度泛化, 泛化具有选择性。这种选择性可能有助于收益最大化。以往研究也表明甚至使用复杂的奖励结构, 为了最大化总体的奖励获得, 个体也能够精确的分配注意优先性到不同的目标上(Navalpakkam, Koch, & Perona, 2009; Navalpakkam,Koch, Rangel, & Perona, 2010)。
本研究所采用的范式是对Anderson (2015b )范式的修改, 他的研究中也是用圆或方形(6个而不是8个)来定位抽象的空间位置。而本研究中性位置的设置则是借鉴了Chelazzi等(2014)的实验范式, 将中性位置和高、低奖励位置进行交叉分布。这样的交叉分布导致了这些中性位置其实并不都是中性的。而对于实验1位置泛化的原因, 本研究也并不能作出明确解释。同时, 我们的实验材料也缺乏生态学意义。未来的研究应该通过设置具体的背景来增加位置感, 同时取消高、低奖励之间的中性位置的设定, 然后考察颜色和位置在价值驱动注意捕获中的交互作用。
在本研究中, 采用自由选择法在实验结束后让被试对奖励与颜色、位置之间的联结进行选择, 结果与Anderson (2105b)不同:他的结果表明有80%的被试不能正确报告出训练阶段的正确联结。而我们的研究结果表明, 有65%的被试能够正确或部分正确的报告训练阶段的正确联结。这可能是由于两个研究所采用的方法不同所导致。在Anderson(2105b)的研究中, 训练阶段在所有的6个位置都呈现目标; 而在我们的研究范式中, 训练阶段只在8个位置中的4个位置呈现目标, 所以本研究的目标更加突出, 被试对目标的位置印象更加深刻, 所以容易建立正确的联结。在这点上, 我们的研究支持被试能够意识到刺激与奖励的联结, 注意优先性的建立可能是策略性的, 这与支持奖励学习所建立的联结能够自动引导注意, 在很大程度上是内隐的结果不同(Anderson & Yantis, 2013; Le Pelley, Pearson,Griffiths, & Beesley, 2015; Hickey & van Zoest,2013)。为了进一步确定训练阶段建立的不同程度的联结是否会影响测试阶段的结果, 我们将不同联结程度组被试作为组间变量, 对测试阶段结果重新进行分析。将实验1测试阶段的反应时进行3(全部正确联结组、部分正确联结组、放弃和错误联结组)× 6(位置:高奖励、高之间、高低之间、低奖励、低之间、无分心物)方差分析, 结果表明, 不同联结程度组的主效应以及其与不同奖励位置的交互作用均不显著,F
s < 1。将实验2测试阶段的反应时先进行3(全部正确联结组、部分正确联结组、放弃组)× 2(颜色:高奖励和低奖励)×5(位置:高奖励、高之间、高低之间、低奖励、低之间)方差分析, 结果表明, 不同联结程度组与颜色和位置的交互作用均不显著, 三者之间的交互作用不显著,F
s < 1。然后将每组被试在每个位置上的3种分心物条件(高奖励颜色分心物、低奖励颜色分心物、无分心物)下的反应时分别进行3×3方差分析, 结果表明在每个位置上, 不同联结程度组与不同分心物条件均不存在交互作用, 且不同联结程度组的主效应均不显著,Fs
< 1。这说明在实验1和2中, 将被试按联结程度的不同进行分组后, 并没有改变原来的实验结果模式, 不同组被试的结果没有差异。也就是说,虽然在我们的研究中, 大多数被试在学习阶段都能够外显的意识到奖励−联结的规则, 但是不管在训练阶段奖励−联结是外显的还是内隐的, 都能够引起价值驱动的注意捕获。但是需要强调, 我们将自由选择阶段放到实验结束后进行, 不能排除有一部分被试在训练阶段能够外显意识到奖励−联结规则,但是在测试阶段后就忘记了。但是, 即使存在这种可能, 也不影响本研究结果。而且, Miranda和Palmer (2014)的研究表明奖励系统可以分为独立的两个:外显的认知系统和内隐的知觉系统, 而且两个系统在注意捕获量上是没有差异的。Della Libera,Perlato和Chelazzi (2011)也认为和价值相关的视觉选择性注意通过两个独立的学习机制形成:一个是对成绩和伴随的奖励进行积极监控; 一个只是消极的检测环境中的客体和所伴随奖励之间的联结。价值驱动的注意捕获可能反应了内隐的和外显定向的共同作用(范玲霞, 齐森青, 郭仁露, 黄博, 杨东,2014)。不依赖于竞争性的当前目标, 而注意到和价值相联结的刺激或位置虽然具有适应性, 但不足是当学习到的刺激−奖励联结不能反应当前环境的奖励结构时, 价值驱动注意捕获的出现可能会误导注意,使个体注意到既不是目标又不具价值的刺激或位置。本研究结果表明注意的泛化具有选择性, 在单一特征(位置)上表现出一定程度的泛化; 同时, 个体能够在训练阶段将所有预测价值的信息(位置和颜色特征)进行整合, 并与奖励建立联结, 从而能够较高效的利用训练阶段所获得的信息, 避免了学习的过度泛化。
5 结论
(1)和高奖励相联结的具体位置所引发的注意捕获效应能够泛化到特定的邻近位置。
(2)个体在训练阶段能够将颜色和位置的联合特征与奖励建立联结; 训练阶段建立的联结不能泛化到部分特征上。
(3)价值驱动注意捕获的泛化具有选择性。
Anderson, B. A. (2013). A value-driven mechanism of attentional selection.Journal of Vision, 13
, 7.Anderson, B. A. (2015a). Value-driven attentional priority is context specific.Psychonomic Bulletin and Review, 22
,750–756.Anderson, B. A. (2015b). Value-driven attentional capture is modulated by spatial context.Visual Cognition, 23
, 67–81.Anderson, B. A., Laurent, P. A., & Yantis, S. (2011a). Learned value magnifies salience-based attentional capture.PLoS One, 6
, e27926.Anderson, B. A., Laurent, P. A., & Yantis, S. (2011b).Value-driven attentional capture.Proceedings of the National Academy of Sciences of the United States of America, 108
, 10367–10371.Anderson, B. A., Laurent, P. A., & Yantis, S. (2012).Generalization of value-based attentional priority.Visual Cognition, 20
, 647–658.Anderson, B. A., & Yantis, S. (2013). Persistence of value-driven attentional capture.Journal of Experimental Psychology: Human Perception and Performance, 39
, 6–9.Camara, E., Manohar, S., & Husain, M. (2013). Past rewards capture spatial attention and action choices.Experimental
Brain Research, 230
, 291–300.Chelazzi, L., Eštočinová, J., Calletti, R., Lo Gerfo, E., Sani, I.,Della Libera, C., & Santandrea, E. (2014). Altering spatial priority maps via reward-based learning.The Journal of Neuroscience, 34
, 8594–8604.Chelazzi, L., Perlato, A., Santandrea, E., & Della Libera, C.(2013). Rewards teach visual selective attention.Vision Research, 85
, 58–72.Corbetta, M., & Shulman, G. L. (2002). Control of goal-directed and stimulus-driven attention in the brain.Nature Reviews Neuroscience, 3
, 201–215.Della Libera, C., & Chelazzi, L. (2009). Learning to attend and to ignore is a matter of gains and losses.Psychological Science, 20
, 778–784.Della Libera, C., Perlato, A., & Chelazzi, L. (2011). Dissociable effects of reward on attentional learning: From passive associations to active monitoring.PLoS One, 6
, e19460.Fan, L. X., Qi, S. Q., Guo, R. L., Huang, B., & Yang, D.(2014). Toward understanding the role of reward in attentional selection.Advances in Psychological Science,22
, 1573–1584.[范玲霞, 齐森青, 郭仁露, 黄博, 杨东. (2014). 奖励影响注意选择的认知加工机制.心理科学进展, 22
, 1573–1584.]Hickey, C., Chelazzi, L., & Theeuwes, J. (2010) Reward changes salience in human vision via the anterior cingulate.The
Journal of Neuroscience, 30
, 11096–11103.Hickey, C., Chelazzi, L., & Theeuwes, J. (2014). Reward-priming of location in visual search.PLoS One, 9
, e103372.Hickey, C., & van Zoest, W. (2013). Reward-associated stimuli capture the eyes in spite of strategic attentional set.Vision Research, 92
, 67–74.Krebs, R. M., Boehler, C. N., & Woldorff, M. G. (2010). The influence of reward associations on conflict processing in the Stroop task.Cognition, 117
, 341–347.Kristjánsson, Á., Sigurjónsdóttir, Ó., & Driver, J. (2010).Fortune and reversals of fortune in visual search: Reward contingencies for pop-out targets affect search efficiency and target repetition effects.Attention, Perception and Psychophysics, 72
, 1229–1236.Laurent, P. A. (2008). The emergence of saliency and novelty responses from reinforcement learning principles.Neural Networks, 21
, 1493–1499.Laurent, P. A., Hall, M. G., Anderson, B. A., & Yantis, S.(2015). Valuable orientations capture attention.Visual Cognition,
23, 133–146.Le Pelley, M. E., Pearson, D., Griffiths, O., & Beesley, T.(2015). When goals conflict with values: Counterproductive attentional and oculomotor capture by reward-related stimuli.Journal of Experimental Psychology: General, 144
,158–171.Lee, J., & Shomstein, S. (2014). Reward-based transfer from bottom-up to top-down search tasks.Psychological Science,25
, 466–475.Mine, C., & Saiki, J. (2015). Task-irrelevant stimulus-reward association induces value-driven attentional capture.Attention,Perception, and Psychophysics, 77
, 1896–1907.Miranda, A. T., & Palmer, E. M. (2014). Intrinsic motivation and attentional capture from gamelike features in a visual search task.Behavior Research, 46
, 159–172.Navalpakkam, V., Koch, C., & Perona, P. (2009). Homo economicus in visual search.Journal of Vision, 9
, 31.Navalpakkam, V., Koch, C., Rangel, A., & Perona, P. (2010).Optimal reward harvesting in complex perceptual environments.Proceedings of the National Academy of Sciences of the United States of America, 107
, 5232–5237.Qi, S. Q., Zeng, Q. L., Ding, C., & Li, H. (2013). Neural correlates of reward-driven attentional capture in visual search.Brain Research, 1532
, 32–43.Raymond, J. E., & O’Brien, J. L. (2009). Selective visual attention and motivation: The consequences of value learning in an attentional blink task.Psychological Science,20
, 981–988.Reynolds, J. H., Chelazzi, L., & Desimone, R. (1999).Competitive mechanisms subserve attention in macaque areas V2 and V4.Journal of Neuroscience, 19
, 1736–1753.Sali, A. W., Anderson, B. A., & Yantis, S. (2014). The role of reward prediction in the control of Attention.Journal of Experimental Psychology: Human Perception and Performance,40
, 1654–1664.Serences, J. T., & Yantis, S. (2007). Spatially selective representations of voluntary and stimulus-driven attentional priority in human occipital, parietal, and frontal cortex.Cerebral Cortex, 17
, 284–293.Störmer, V., Eppinger, B., & Li, S.-C. (2014). Reward speeds up and increases consistency of visual selective attention: A lifespan comparison.Cognitive, Affective, & Behavioral Neuroscience, 14
, 659–671.Treisman, A. (1992). Perceiving and re-perceiving objects.American Psychologist, 47
, 862–875.Wang, L. H., Duan, Y. Y., Theeuwes, J., & Zhou, X. L. (2014).Reward breaks through the inhibitory region around attentional focus.Journal of Vision, 14
, 2.Wang, L. H., Yu, H. B., & Zhou, X. L. (2013). Interaction between value and perceptual salience in value-driven attentional capture.Journal of Vision, 13
, 5.Yokoyama, T., Padmala, S., & Pessoa, L. (2015). Reward learning and negative emotion during rapid attentional competition.Frontiers in Psychology, 6
, 629.猜你喜欢
科学与社会(2022年1期)2022-04-19
莫愁(2019年36期)2019-11-13
科学与财富(2019年17期)2019-04-17
计算机教育(2017年5期)2017-05-31
少儿科学周刊·儿童版(2015年11期)2015-12-17
考试周刊(2015年62期)2015-09-10
营销界(2015年22期)2015-02-28
海峡姐妹(2015年6期)2015-02-27
