
一种基于证据理论的多传感器目标识别方法
2016-01-27 02:31杜周全徐启建徐勇军王建伟
通信技术 2015年12期
关键词:数据融合
杜周全,徐启建,张 杰,徐勇军,王建伟
(1.解放军理工大学 通信工程学院,江苏 南京 210007;2.中国电子设备系统工程公司研究所,北京 100141;
3.中科院 计算技术研究所,北京 100080)
一种基于证据理论的多传感器目标识别方法
杜周全1,2,徐启建2,张杰2,徐勇军3,王建伟1
(1.解放军理工大学 通信工程学院,江苏 南京 210007;2.中国电子设备系统工程公司研究所,北京 100141;
3.中科院 计算技术研究所,北京 100080)
Foundation Item: Important National Science & Technology Specific Projects(No.2014ZX03006-003)
摘要:证据理论是高层数据融合中的一种重要方法,因其能够很好地处理不确定性问题,近些年来被广泛应用于决策判断、目标识别等数据融合领域。随着人们认知能力的不断提高和科技的不断发展,以及感知信息识别框架的不断完善, 如何给感知信息赋予一个合理而准确的基本概率值成了证据理论发展的一大研究重点。经过学习研究,提出了通过计算感知信息与先验知识之间的距离来生成基本概率赋值函数,再对其进行证据融合的方法。最后经过数据验证,发现融合结果的准确度较高,符合预期。
关键词:证据理论;基本概率赋值函数;数据融合 ;多目标识别
0引言
数据融合是指通过一定的算法将采集到的数据进行各种处理,去除冗余,减少数据传输量,进而降低能耗,延长网络寿命,提高信息传输效率。证据理论是一种基于数学统计的数据融合分类方法,善于处理多传感器信息融合[1]中的不确定性问题,被高层数据融合采纳为一种重要的决策级[2]融合方法。近年来,数据融合技术的不断发展和推广,更是使得证据理论广泛活跃于决策判断[3]、目标跟踪[4]等数据融合领域。随着传感器设备的不断更新,信息感知技术的不断发展,人们认知能力的不断提升,信息识别框架的不断完善,数据复杂度的不断增加以及多传感器网络的普及与推广,在同一融合体系中往往存在多种类型的感知信息,如何对这些感知信息进行准确赋值成了当今证据理论应用中一大难题。而选取一个合理而准确的赋值方式是进行准确证据融合的前提。以计算感知信息与先验知识之间的距离来生成概率赋值函数的方法,优化了证据理论,仿真结果表明,该设计能够有效提高证据理论的数据融合精确度,更好的完成对目标的识别。
1证据理论
证据理论最先是由Dempster提出[5],并由其学生Shafer进行研究发展而成型的一门数据理论[6]。该理论通过采用信任函数等概念,形成了一套以“证据”和“组合”为基础来分析处理不确定性问题的数学方法。首先,定义了一个识别框架,用Θ来表示。定义了变量α以及α的所有互斥且穷尽的原始子命题组成的集合U,称为α的识别框架。其次,为了表示证据对命题的支持程度,还定义了基本概率赋值函数(mass函数)、信任函数、似真函数。最后,利用一定的融合规则对mass函数进行融合,得到最终的融合结果。
基本概率赋值函数(mass函数):设函数m:2u→[0,1],且满足:
(1)m(φ)=0m(φ)=0;

信任函数(BEL):由表达式(1)所定义的函数Bel:2u→[0,1];

(1)
似真函数(PLS):由表达式(2)所定义的函数Pls:2u→[0,1];

(2)
证据理论组合规则:证据理论的组合规则由表达式(3)给出的函数进行定义。
(3)
变量K为冲突系数,由式(4)进行计算:
(4)

例1:传感器A的数据报告mA(a2∪a3)=0.5,mA(Θ)=0.5;传感器B的数据报告为mB(a3∪a4)=0.6,mB(Θ)=0.4;此时冲突系数K=0,则合成结果为m(a3)=0.3,m(a3∪a4)=0.3,m(a2∪a3)=0.2,m(Θ)=0.2。最终Bel(a3)=m(a3)=0.3,Pls(a3)=m(Θ)+m(a3)+m(a2∪a3)+m(a3∪a4)=1。即P(a3)的概率为[0.3,1]。具体合成过程如表1所示。

表1 K=0时的数据融合过程
若传感器B的数据报告为mB(a1∪a4)=0.6,mB(Θ)=0.4;此时冲突系数K=0.3,则合成结果m(a1∪a4)=0.428,m(a2∪a3)=0.286m(Θ)=0.286;Bel(a3)=m(a3)=0.3,Pls(a3)=m(a2∪a3)+m(Θ)=0.572,即P(a3)的概率为[0,0.572]。具体合成过程如表2所示。
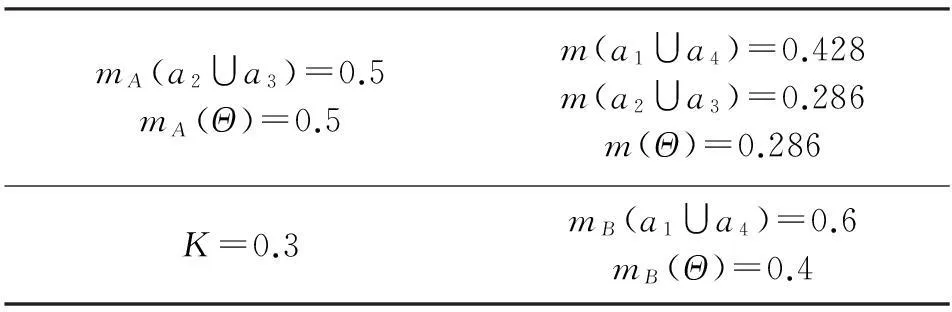
表2 K=0.3时的数据融合过程
2证据理论的优点和局限性
证据理论中引入了全集的概念,将不确定性进行了统一度量,并通过建立基本概率赋值函数(BPA)、信任函数(BEL)、似真函数(PLS)等,将单点赋值进一步扩展成为集合赋值,弱化了概率论中对相应的公理系统的要求。采用“区间”的方法完成对不确定信息的描述,在区分“不知道”与“不确定”以及精确反映证据聚合方面显示出很大的灵活性。这也使其在做出有效识别判断时,不需要完整的先验概率和条件概率知识,比传统贝叶斯理论的更加容易实现,并且在数据真实可靠且没有产生冲突的前提下减小了计算量。该理论工程实现简单,可对互相重叠、非互不相容的数据进行组合,能快速捕获并融合多类多个传感器的信息,在专家系统、数据融合、目标跟踪、多属性决策分析和情报分析等领域广泛应用[7]。
但是证据理论要求参与融合的证据必须是完全相互独立的,在工程实践中难以严格满足这一特性;证据源的多样性和数据的复杂性同样会导致建模结构复杂,难以准确实现mass函数赋值;当遇到证据间冲突较大、证据源可信度较低、常规识别框架不完备或特征值不明显时,采用组合规则得到的结果与实际情况有较大差异;识别框架内的因子较多时容易出现组合爆炸问题[8]。由此,也诞生了许多研究如何解决证据冲突的数据融合规则,比如文献[9]提出了易发生证据冲突的情况,并设计了相应的解决方法。
3基于证据理论的多传感器目标识别方法
在第一节的例子中我们得到的传感器数据报告为mA(a2∪a3)=0.5,而在多传感器目标识别过程中,单一传感器常常只能判断该目标的某一属性特征,采集相应的特征信息,同时传感器所感知的报告数据大多都是某些特定的物理量,比如速度,距离,角度,颜色,温度,湿度,风力等,这就需要我们在数据融合前快速准确的构造基本概率赋值函数,对不同的数据信息进行分类,并将特定物理量转化为融合所需要的概率值[10],然后将这些特征数据进行融合识别,最终得到我们想要的结果。
下面实验中我们使用公开数据(鸢尾花数据库)来进行建模和验证,实验结果更具有普遍性和说服力。鸢尾花数据库中的鸢尾花共有三种类型,分别为Se型、Ve型和Vi型,其中每个品种各含有50个样本,该数据库中收集了三种鸢尾花的4种属性,分别是花萼的长度(SL)、花萼的宽度(SW)、花瓣的长度(PL)和花瓣的宽度(PW)。该数据库对应了一个含有3个元素识别框架的数学模型,共有4类相互独立的传感器进行信息采集和识别。本次实验中,我们采用了多特征数据融合方法[11],利用采集到的四种特征属性值,对三类不同类型的鸢尾花进行了目标识别,通过数据融合滤去特征信息之间的冗余和互补,经过分析处理消除和降低目标的不确定性,然后进行决策判断,得到融合结果。多次实验的数据结果表明,该方法能够在多特征数据融合中对目标进行准确识别,准确度较高,符合我们的预期,能够满足实际的一些目标识别应用需求。具体实验方法步骤如下:

(5)
然后以各属性的实际观测值与预估值之间的协方差距离dij为基础,经过变换得到各个品种的概率mij,最后再进行归一化处理,得到对应的基本概率赋值m。
mij=exp(-(dij-dmin))
(6)
m=mij/∑mij
(7)
抽取原始预估样本的样本容量大小代表了先验知识的丰富程度,样本数目选取的越多表示先验知识越丰富,得到的预估值也就越准确。本文从数据库中各选取5个随机样本作为预估样本,如表3所示,旨在验证该方法在先验知识缺乏的条件下是否依然能进行准确的数据融合识别。

表3 选择的样本数据 cm
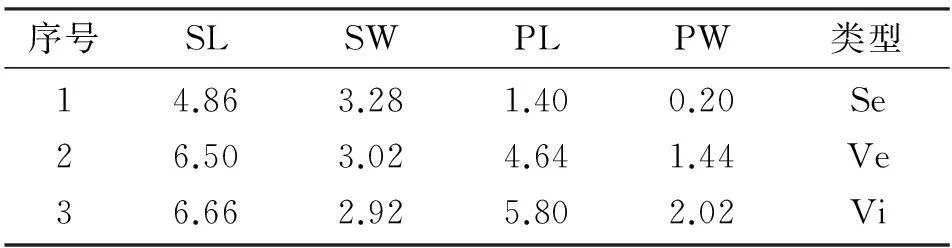
表4 所选样本各属性的平均属性
假设观测样本为Se型的第一个样本(5.1,3.5,1.4,0.2),按照上述方法对SL、SW、PL、PW四种属性分别进行赋值,得到如表5中各类型对应的基本概率赋值数据。

表5 各类型对应的基本概率赋值
运用上述证据理论融合规则对该样本的SL、SW、PL、PW四种属性进行融合,经计算得到的结果为:m(Se)=0.992 3,m(Ve)=0.006 5,m(Vi)=0.001 2。根据得到的概率数据结果可判断该样本为Se型,该结论与真实情况相一致。
4仿真验证
针对上述实验方法,首先简单抽取鸢尾花数据库的三类共15个预估样本进行数据融合仿真,通过仿真计算得到的融合结果如表6所示,对于抽样得到的15个预估样本全部判断正确,准确率100%。从表6中可以看出第11和第13个样本的判断难度相对较大,融合特征不够明显,存在误判可能性。

表6 预估样本的融合结果
从图1中可以更直观看到融合结果,除了第11个样本之外,其余样本均能明确判断其类型,从原始数据分析来看,Ve型和Vi型的部分属性参数之间差别较小,而Ve型的第11个样本中,SL、SW、PL三种属性均比Vi型的平均样本值偏小,因此判断起来比较困难。此外,由于此次试验仅选取五个随机样本进行评估参考,各参数预估值的准确度也会影响最终的融合结果。
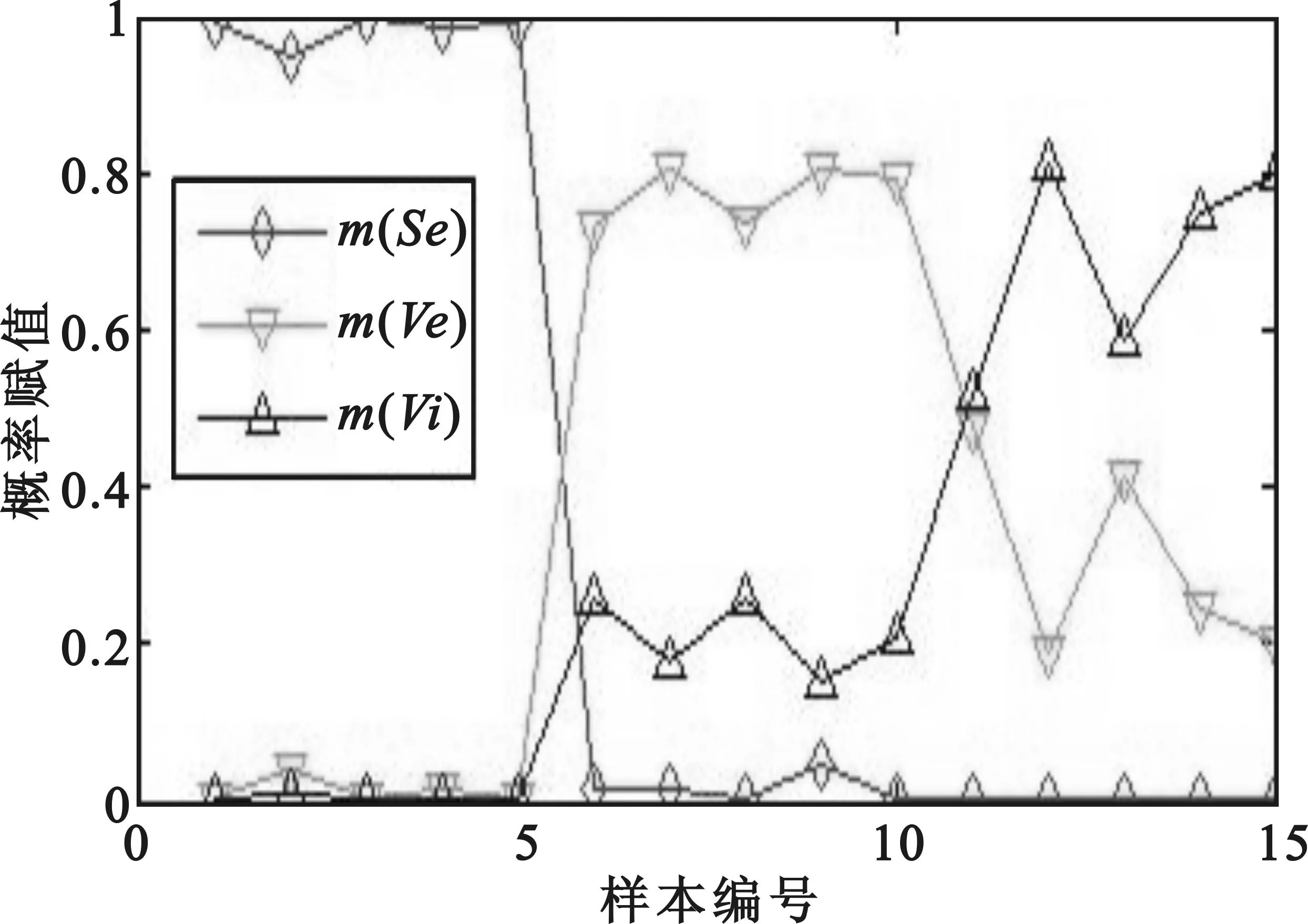
图1 预估样本融合结果
在此基础上,假设由于某些特定原因,未能采集到花萼宽度这一数据,或者该类数据在传输中丢失,即从四种属性中抽取三个作为原始数据来进行融合。将得到的融合结果与四属性数据融合结果相比对,结果如图2所示。从图2中可以看出,蓝色标识所代表的三种属性融合的效果明显比红色标识所代表的四属性融合效果要差,甚至在第11个样本上出现了判断错误。一般情况下,如果融合数据量越大,融合的数据种类越多,那么融合精度就会越高。本次实验中在缺少某种属性数据时,仅在第十一个样本出现误判,并且试验中只选取了15个样本容量的数据进行融合,得到的融合结果仍具有较高的准确度,这也间接证明了前面提出的方法的准确度和可用性。
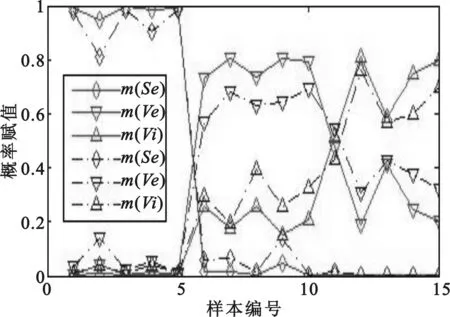
图2 不同属性数量的融合结果对比
同理,运用上述方法对全部150个样本容量的四种属性进行仿真融合,结果发现150个样本全部融合正确,准确率高达100%。为了更好的验证该方法的性能,重复进行了10次融合实验,即从总样本中随机选择100个预估样本,然后对抽取的样本进行融合。多次重复试验得到的融合结果中6次准确率为100%,2次准确率99%,2次为98%。经分析发现,出错数据始终为第11个样本,该数据属于Vi型,但融合结果为Ve型,该花萼长度和花瓣长度(5.8,5.1)与Vi型平均属性(6.66,5.8)差距较大,更接近于Ve型平均属性(6.50,4.64),应该属于Vi型中差异较大的特例。而第十四个样本的花萼长度(SL)和花萼宽度(SW)为(6.5,3.0),相比于Vi型的平均属性(6.66,2.92),更接近于Ve型的平均属性(6.5,3.02),因而在试验中也出现了误判。这些属性数据较为特殊的个体往往是目标识别中的难点,而如何降低这些难点目标的误判率,避免出现证据冲突等问题,提高数据融合的有效性仍需要我们进一步研究。
5结语
在证据理论的工程应用中,基本概率赋值函数的生成往往与实际应用密不可分,在提出该函数生成方法后,还需要通过实际应用来检验并做出相应修正,以得到更加精准的数据融合结果。在多传感器目标跟踪应用中,结合已有的知识对传感器感知信息进行分类处理,着重利用问题内在的不确定性进行建模,运用证据理论进行融合,再把正确的融合结果作为先验知识储存在学习系统中,为下一次融合提供经验,才能不断提高融合的效率和精度,充分发挥证据理论的优势。基于感知信息与先验知识之间的距离来生成基本概率赋值函数的方法,对证据融合进行了优化,并具有较高的融合精度,但仍存在一定的误差。如何通过加权或其他方式来对该方法进行优化改进,提高识别精度和识别效率,以及对一些特殊环境和突发事件的处理能力,仍需要进一步的深入研究。
参考文献:
[1]齐伟,杨风暴,周新宇.一种多传感器数据融合系统方案研究[J].通信技术,2010,43(10):84-86.
QI Wei, YANG Feng-bao, ZHOU Xin-yu. Study on Scheme of Multi-Sensor Data Fusion [J].Journal of Communication Technology, 2010,43(10):84-86.
[2]周芳,韩立岩.多传感器信息融合技术综述[J].遥测遥控,2006, 27(03):1-7.
ZHOU Fang,HAN Li-yan.A Survey of Multi-Sensor Information Fusion Technology[J]. Journal of Telemetry, Tracking, and Command. 2006. 27(3):1-7.
[3]吴艳.多传感器数据融合算法研究[D]. 西安电子科技大学, 2003. DOI: doi: 10.7666/d. y531253.
WU Yan. Study of Multi-Sensor Data Fusion Algorithms[D]. Xidian University,2003. DOI: doi:10.7666/d.y531253.
[4]刘国成.一种基于多传感器数据融合的目标跟踪算法[J].系统仿真学报,2009, 21(02): 194-197.
LIU Guo-cheng. Algorithm for Multi-Sensor Data Fusion Target Tracking[J]. Journal of System Simulation,2009,21(2):194-197.
[5]Dempster A P. Upper and Lower Probabilities Induced by a Multivalued Mapping[J]. Studies in Fuzziness and Soft Computing, 2008:57-72.
[6]Shafer G.A Mathematical Theory of Evidence[M].Princeton,NJ:Princeton Univ.Press,1976.
[7]杨万海.多传感器数据融合及其应用[M].西安:西安电子科技大学出版社,2004:133-142.
YANG Wan-hai. Multi-Sensor Data Fusion and Application [M]. Xi’an: Xi’an Electronic Sience & Technology University Press, 2004:133-142.
[8]王栋. 基于数据融合的机载多传感器目标识别[D]. 上海交通大学, 2010.
WANG Dong. Airborne Multi-Sensor Target Recognition based on Data Fusion [D].Shanghai Jiaotong University, 2010.
[9]白剑林, 王煜. 一种解决D-S理论证据冲突的有效方法[J].系统工程与电子技术, 2009, 31(09):2106-2109.DOI:doi:10.3321/j.issn:1001-506X.2009.09.017.
BAI Jian-lin,WANG Yu. Efficient Combination Approach to Conflict Evidence for D-S Theory[J].Journal of Systems Engineering and Electronics, 2009, 31(9):2106-2109.DOI:doi:10.3321/j.issn:1001-506X.2009.09.017.
[10]韩德强, 杨艺, 韩崇昭. DS 证据理论研究进展及相关问题探讨[J]. 控制与决策,2014,29(01):1-11.
HAN De-qiang, YANG Yi, HAN Cong-zhao. Advance in DS Evidence Theory and Related Discussion[J].Journal of Control and Decision,2014,29(1):1-11.
[11]宋建勋, 张进, 吴钦章. 基于D-S证据理论的多特征数据融合算法[J]. 火力与指挥控制, 2010(35):96-98.DOI:doi:10.3969/j.issn. 1002-0640.2010.07.028.
SONG Jian-xun, ZHANG Jin, WU Qin-zhang. Algorithm of Multi-Feature Data Fusion based on D-S Theory of Evidence[J].Journal of Fire Control & Command Control, 2010, 35:96-98.DOI:doi:10.3969/j.issn.1002-0640.2010.07.028.

杜周全(1990—),男,硕士研究生,主要研究方向为无线传感器网络;
徐启建(1955—),男,博士,研究员,主要研究方向为军事通信;
张杰(1974—),男,博士,高工,主要研究方向为无线传感器网络;
徐勇军(1979—),男,博士,副研究员,主要研究方向为无线传感器网络;
王建伟(1986—),男,硕士研究生,主要研究方向为安卓系统代码安全。
Multi-Sensor Target Recognition Method based on Evidence Theory
DU Zhou-quan1, XU Qi-jian2, ZHANG Jie2, XU Yong-jun3, WANG Jian-wei1
(1.College of Communication Engineering, PLA University of Science and Technology, Nanjing Jiangsu 210007,China;
2.Research Institute of Electronic Equipment System Engineering Company, Beijing 100141, China;
3.CAS Research Institute of Computing Technology, Beijing 100080,China)
Abstract:Nowadays, evidence theory, as an important method for high-level data fusion, is widely adopted in the fields of decision-making judgment and targets tracking for its fairly dealing with uncertain issues. With the increasing of people’s awareness, the development of science and technology and the constant perfection of perceptive-information recognition framework, how to assign perceptive information a reasonably accurate value becomes a major research topic in the development of evidence theory. This paper puts forward a method to generate basic belief assignment function by calculating the distance from prior knowledge to perception information, and then to fuse them through the evidence theory. Experiment indicates that the fusion result has a good veracity and is accordant with the expectation.
Key words:evidence theory; basic belief assignment function; data fusion; multi-targets recognition
作者简介:
中图分类号:TP301
文献标志码:A
文章编号:1002-0802(2015)12-1362-05
基金项目:国家科技重大专项(No.2014ZX03006-003)
收稿日期:2015-08-01;修回日期:2015-11-02Received date:2015-08-01;Revised date:2015-11-02
doi:10.3969/j.issn.1002-0802.2015.12.009
猜你喜欢
现代电子技术(2016年24期)2017-01-19
东方教育(2016年10期)2017-01-16
电子技术与软件工程(2016年22期)2016-12-26
科技视界(2016年14期)2016-06-08
科技视界(2016年3期)2016-02-26
物联网技术(2015年11期)2015-11-26
物联网技术(2015年11期)2015-11-26
物联网技术(2015年8期)2015-09-14
物联网技术(2015年5期)2015-07-18
物联网技术(2015年4期)2015-04-27
