
一种基于项目属性评分的协同过滤推荐算法*
2016-01-26 06:48龚安,高云,高洪福
计算机工程与科学 2015年12期
关键词:协同过滤
一种基于项目属性评分的协同过滤推荐算法*
通信地址:266580 山东省青岛市中国石油大学(华东)计算机与通信工程学院Address:School of Computer & Communication Engineering,China University of Petroleum,Qingdao 266580,Shandong,P.R.China
龚安,高云,高洪福
(中国石油大学(华东)计算机与通信工程学院,山东 青岛 266580)
摘要:协同过滤是电子商务推荐系统中应用最成功的推荐技术之一,但面临着严峻的用户评分数据稀疏性和推荐精度低等问题。针对数据稀疏性高和单一评分导致的推荐精度低等问题,提出一种基于项目属性评分的协同过滤推荐算法。首先通过均值法或缩放法构造用户-项目属性评分矩阵将单一评分转化为多评分;其次基于每个属性评分矩阵,计算用户间的偏好相似度,得到目标用户的偏好最近邻居集;然后针对每个最近邻居集,在用户-项目评分矩阵上完成对目标用户的初步评分预测;最后,将多个初步预测评分加权求和作为综合评分,完成推荐。在Movie Lens扩展数据集上的实验结果表明,该算法能有效提高推荐精度。
关键词:属性评分;均值法;缩放法;协同过滤;推荐
1引言
随着Internet和电子商务的迅猛发展,“信息爆炸”和“信息过载”问题越来越严重,用户很难从海量的信息中找到自己真正需要的信息。推荐系统可以在用户目的不明确的情况下帮助用户找到可能感兴趣的信息并推荐给用户。协同过滤是现行推荐系统中应用最广泛最成功的技术之一,但其需要维护一个存储用户偏好的数据库。因此,随着系统中用户和项目数量的不断增加,协同过滤面临严峻的用户评分数据稀疏性、推荐实时性、可扩展性挑战,推荐质量迅速下降。
对此,很多国内外学者提出了一些改进算法。Luo H等人[1]提出了局部用户相似性和全局用户相似性的概念及LU&GU架构,可发现高质量的邻居用户,提高推荐精度。黄创光等人[2]提出了一种不确定近邻的协同过滤算法,通过不确定近邻因子及调和参数计算基于用户和项目的预测评分从而产生推荐。Lemire D教授[3]提出了Slope One算法,该算法具有易实现、查询效率高等优点。Mi Z等人[4]将聚类和Slope One相结合应用在推荐算法中。Melville P等人[5]使用基于内容的方法填补用户评分向量中的空值,缓解评分数据的稀疏性,从而提高协同过滤的推荐质量。杨兴耀等人[6]通过协调优化的用户评分相似性和基于项目属性的用户相似性改进相似性度量的精度。Huang M等人[7]结合属性论提出了基于项目属性的协同过滤推荐算法,缓解了数据稀疏问题,提高了推荐质量。上述研究虽然提高了推荐质量,但都没有考虑用户的属性偏好。徐红艳等人[8]提出了一种基于多属性评分的协同过滤算法,该算法在一定程度上解决了数据稀疏问题,提高推荐准确度。范波等人[9]提出了一种基于用户间多相似度的协同过滤推荐算法,即通过计算用户间对不同项目类型多个独立的评分相似度来分别描述用户间对不同类型项目喜好的相似程度。上述研究均利用了项目的属性信息,但文献[8]中主要是针对多评分数据集的,对单一评分数据集并不适用;文献[9]虽然计算了用户之间的多个相似度,但其仍是利用用户的直接评分,并未考虑用户对项目某一属性的偏好。
本文针对单一评分数据集上推荐精度低的问题,采用均值法和缩放法将单一评分转换为多评分,计算用户对项目的各个属性的偏好评分得到多个用户-项目属性评分矩阵;然后,在各属性矩阵上计算用户相似度得到用户的多个相似邻居集;接下来,针对每组最近邻,分别在用户-项目评分矩阵进行评分预测;最后,将同一用户对同一项目的多个预测评分加权求和后作为综合评分,依据综合评分的大小进行项目推荐。
2问题定义及基本方法
定义推荐系统中的数据源D={U,I,R};其中U={u1,u2,…,um}表示基本用户,I={i1,i2,…,in}表示基本项目,R代表一个m×n阶的矩阵,用户u对项目j的评分,记作 Ru,j。由于系统中大部分用户对大部分项目没有评分,所以矩阵中存在大量的空值。
传统的基于用户的协同过滤推荐算法首先计算用户之间的相似度。相似度计算方法主要有以下三种:
(1)余弦相似性:用户被看作n维项目空间的向量。设向量u、v分别代表用户u和用户v的评分,则用户u和用户v之间的相似度sim(u,v)定义如下:

(1)
(2)修正的余弦相似性:余弦相似性未考虑不同用户之间的评分尺度偏差的问题,修正的余弦相似性通过减去用户的平均评分来改善这一缺陷,其定义如下:
sim(u,v)=

(2)

(3)相关相似性:选取用户u和用户v的共同打分的项目集,记作Iu,v,则sim(u,v)如下:
sim(u,v)=
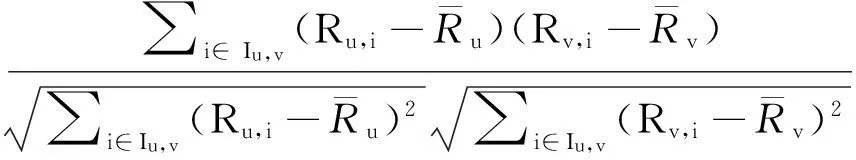
(3)
然后,推荐系统选取与目标用户u相似度较高的用户作为其最近邻居集,记作N(u),并预测用户u对其未评分项目i的评分Pu,i:
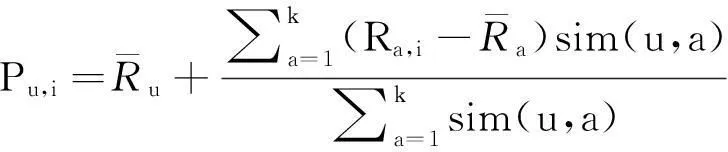
(4)
最后,推荐系统将预测评分最高的前K个项目推荐给用户,完成推荐过程。
3基于项目属性评分的协同过滤推荐算法
本文认为用户使用(购买或者观看)了项目,可能是因为对项目的某种属性有所偏好,例如有些用户喜欢喜剧片,有些用户喜欢动作片,还有的用户购买了大量的电子产品等,因此本文拟通过寻找在属性上有类似偏好的用户作为相似用户,然后基于他们的历史评分产生推荐。
3.1 算法思路
定义项目的属性集为A={A1,A2,…,Ak,…,Al},Ak={a1,a2,…,as,…,at},其中,Ak为属性,as为属性的取值。需要注意的是,对于某一项目ij的属性Ak,其可能有多个取值。例如,一部电影既是动作片又是科幻片,一件商品既是女装又是户外等。
图1给出了算法的流程。首先,构建用户-项目评分矩阵、用户-项目属性评分矩阵并选取属性;然后,在每个属性评分矩阵上计算用户之间的相关相似性,并选取相似度最高的K个用户作为相似邻居;接着,根据K个邻居的历史评分预测目标用户对目标项目的评分;当所有属性评分矩阵的预测完成时,会得到目标用户对于每个目标项目的一组预测评分,将这些评分加权求和作为综合评分;最后,选取综合评分最高的前T个项目推荐给用户。

Figure 1 Algorithm flowchat图1 算法流程
3.2 算法描述
本文分三方面探讨基于项目属性评分的协同过滤推荐算法,即用户-项目属性评分矩阵的构造、项目属性的确定和推荐的生成。
3.2.1 用户-项目属性评分矩阵的构造
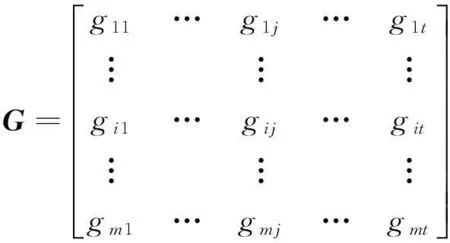
设用户对项目的第k个属性Ak的评分矩阵为G,表示如下:
(5)
其中,m为用户数量,t是属性Ak值的数量。
要构造用户-项目属性评分矩阵,首先要确定用户对各属性值的评分,即gij,文献[8]采用的是用户对属性的直接评分,但是日常生活中数据集大多都是单一评分的。因此,本文采用以下两种方法来构造属性评分:
(1)均值法:即以用户对具有某一属性值的项目的评分的均值作为其评分,定义如下:

(6)
其中,N代表用户i评价过的Ak=aj的项目的数量,rh代表用户对Ak=aj的项目的评分。由定义可知,每个用户对每个属性值的评分至多只有一个,例如,用户A对喜剧电影的评分为4;如果A没有看过喜剧电影,则其没有该项评分。
(2)缩放法:如果用户对具有某一属性值的项目的评分的差距都比较小但评分又不完全相同,则可认为用户比较偏爱此类项目,需要对其评分进行放大,反之,其评分需进行适当的缩减;如果用户对具有某一属性值的项目只有一次评分,则可认为用户不喜欢此类项目,令其评分为零;如果用户对具有某一属性值的项目的评分完全相同,则忽略其评分。本文采用方差对评分进行缩放,并将阈值定为1,即如果方差大于1,就将评分缩减,反之,将评分放大。因此,缩放法定义为用户对具有某一属性值的项目的评分的均值和方差的比值,公式如下:

(7)

下面通过一个例子进行阐述,假设用户A、B、C、D观看过的喜剧电影为1、2、3、4,其历史评分、均值评分和缩放评分如表1所示。可以发现,当用户评分比较稳定时,例如用户A的评分,其缩放评分被放大;而当评分波动比较大时,例如用户B的评分,其评分被缩小。另外,注意到缩放法中的评分范围不是从1到5,而是根据用户的历史评分动态调整。
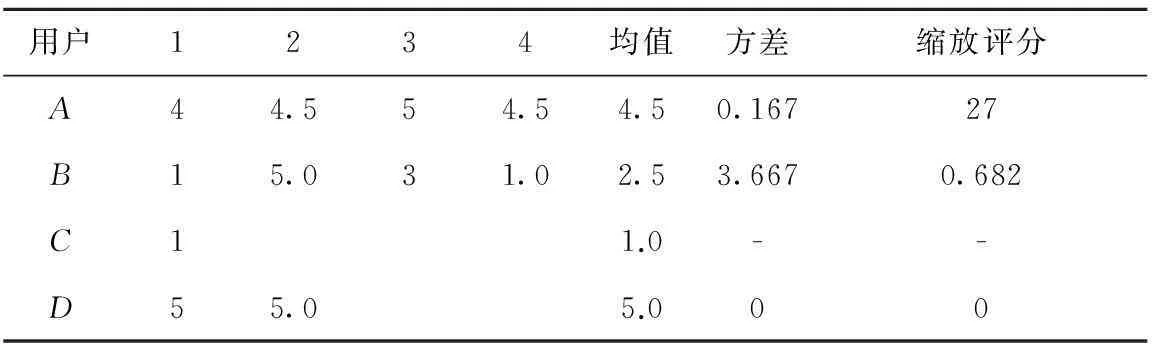
Table 1 Examples of user-rating
3.2.2 项目属性的确定
推荐系统中,项目的属性繁多,若在所有属性上进行推荐,势必增加系统负荷,降低系统效率。因此,本文选取部分属性,选取依据为数据稀疏度和数据减少率:
(1)数据稀疏度:用户评分数据矩阵中未评分条目所占的百分比,其公式如下:
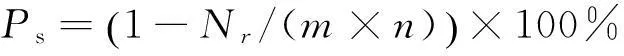
(8)
其中Nr为评分数量,m为矩阵行数(用户的数量),n为矩阵列数(项目或者项目属性值的数量)。
(2)数据减少率:用户-项目属性评分相比用户-项目评分所减少的数据量的比率,定义如下:
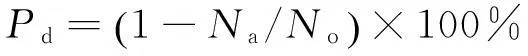
(9)
其中,Na为用户-项目属性评分的数据量,No为用户-项目评分的数据量。
在属性选取时,应选择数据稀疏度低的属性以保证相似度计算的准确性,提高推荐精度;选择数据减少率高的属性以降低系统数据量,提高系统效率。
3.2.3 推荐的生成
由于在多个属性评分矩阵上进行了邻居搜索并针对每个邻居集分别进行了评分预测,因此得到了用户对同一项目的多个预测评分(初步评分)。此时,系统不应将每个属性的推荐直接推送给用户,而应该根据用户对不同属性的偏好程度,对各属性上的预测评分加权后再产生推荐。但是,在推荐系统中,每个用户的偏好不同且不易度量,所以,本文对各属性评分取相同权重求和后作为综合评分,并将综合评分由大到小排序后选取TopT项目推荐给用户。
4实验结果及分析
4.1 实验数据集
本文采用MovieLens10M的扩展数据集,包括2 113个用户对10 197部电影的855 598条评分。其评分数据从1到5,评分越高,表示用户对电影越喜欢。为了分析稀疏度和系统规模对算法性能的影响,本文从数据集中随机抽取三个训练数据集(250位用户对431部电影的10 000条评分,250位用户对247部电影的10 000条评分及1 000位用户对1 101部电影的50 000条评分),对应每个训练集抽取部分数据作为测试集。训练集的用户-项目评分矩阵和采用均值法构造的用户-项目属性评分矩阵描述如表2所示。由于缩放法中对部分评分填充了空值,所以其构造的评分矩阵的数据稀疏度和数据减少率都在一定程度上有所提高。需要注意的是,对于一部电影,其导演、国家、时间只有一个,但是演员、类型、拍摄地、用户所打标签并不唯一。对于前者,将属性的每个值都作为评分矩阵的一列;针对后者,本文分两种情况进行处理:
(1)属性有排序行为,则取前两个值;
(2)属性无排序行为,则考虑所有值。
本实验数据集中,演员、标签属于(1),类型和拍摄地属于(2)。
4.2 评价指标
本文采用平均绝对偏差MAE(Mean Absolute Error)来评价算法的推荐精度。MAE的计算公式如下所示:

(10)
其中,pi为目标用户对项目(或项目属性值)的预测评分,qi目标用户对项目(或项目属性值)的实际评分,N为预测评分的数量。
4.3 实验方案
首先进行属性选取,本文选择的属性为:国家、类型、拍摄地1和时间;然后,将两种构造方法在各属性上产生的推荐分别和直接评分的预测结果进行比较;第三,将由两种方法确定综合评分与直接评分的预测结果进行比较;最后,对比本文方法与直接评分的效率。
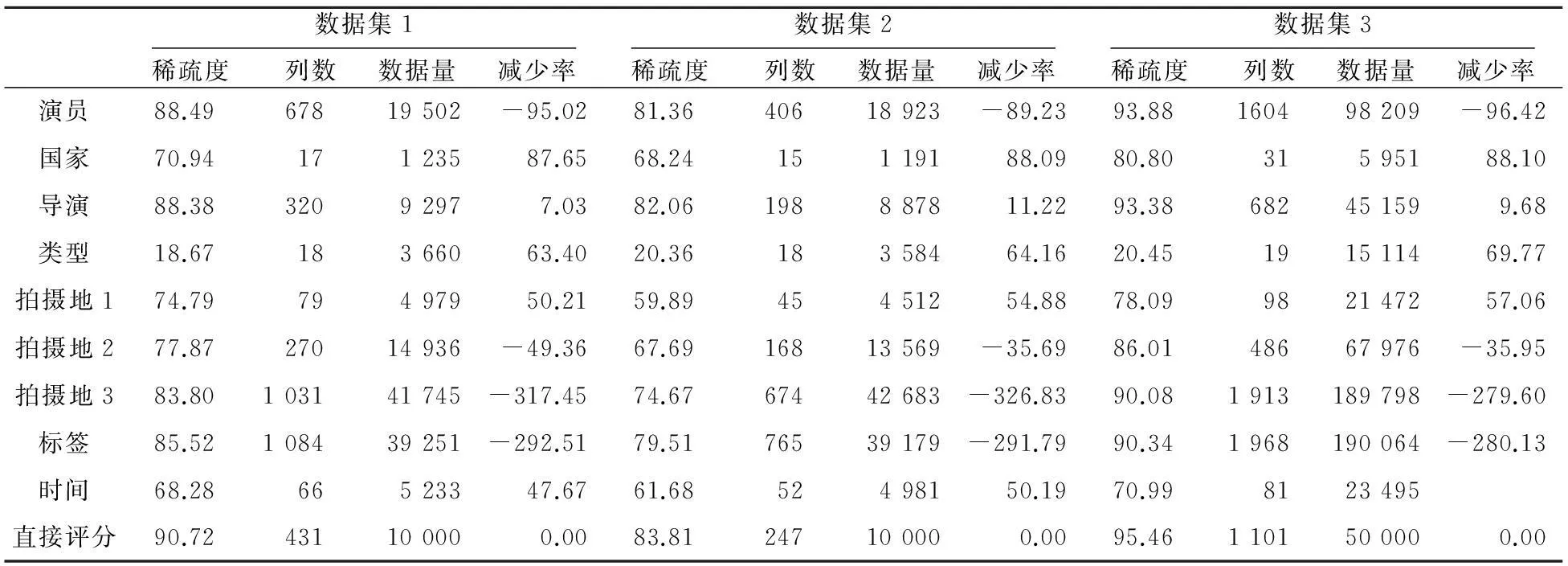
Table 2 Descriptions of datasets
4.4 实验结果及分析
4.4.1 不同构造方法与直接评分推荐精度的对比
图2为均值法和缩放法在数据集1上产生的各属性的推荐结果对比,其他数据集的结果与此相似。由图2可见,均值法在单个属性上的推荐精度基本都低于直接评分;缩放法的推荐精度在属性国家、类型上有所改善但并不稳定。

Figure 2 Recommendation comparison of each attribute on dataset 1图2 数据集1上各属性的推荐结果对比
4.4.2 组合评分与直接评分推荐精度的对比
在该部分,将两种构造方法得到的初步预测评分进行组合,即加权求和后与直接评分进行对比,在数据集1、数据集2、数据集3上的实验结果如图3所示。将图3和表2结合对比可见,当系统数据量相同、数据稀疏性比较低的时候,缩放法的推荐精度明显高于均值法和直接评分;当数据稀疏性相似、系统数据量不同时,缩放法和均值法的推荐精度均高于直接评分,但前者略优于后者。综上,本文认为,当数据稀疏度较高时,应采用缩放法以取得较高的推荐精度,反之,则可任选其一。

Figure 3 Precision comparison on each data set图3 各数据集上的推荐精度对比
4.4.3 组合评分与直接评分效率的对比
该部分以均值法在数据集1上30个邻居用户的推荐为例,对比组合评分与直接评分的时间复杂性问题,各属性上的推荐与直接评分所需时间如图4所示。可以发现,单个属性推荐所需时间均明显低于直接评分,分析原因如下:在相似度计算阶段,由于每个属性矩阵的列的数目和数据量相对较少,所以每个属性矩阵在该阶段花费的时间比直接评分少;在计算预测评分阶段,两种方法均是基于原始用户-项目评分矩阵的,所以当邻居用户数目相同时,本文方法与直接评分的方法在该阶段花费时间相同。综上,本文方法在单个属性矩阵上的推荐所需时间少于直接评分。如前所述,本文需要计算多个评分的组合值,如果依次计算每个初步评分,本文算法的效率势必低于直接评分。但实际上,各属性上的推荐是相互独立的,可以并行计算,这样本文算法所需时间即为各个属性推荐中所需的最长时间,在图4中即为时间属性推荐所需的时间(30 s)。当然,直接评分也可以并行推荐,此处不再比较。
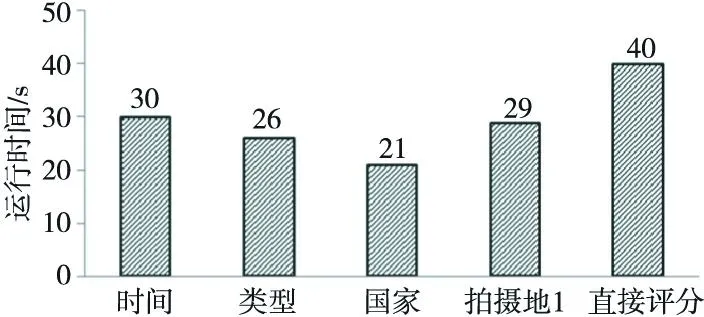
Figure 4 Efficiency comparison between the mean value method and the directed ratings图4 均值法在各属性上的推荐与直接评分效率的对比
5结束语
本文提出了一种基于项目属性评分的协同过滤推荐算法,并详细阐述了项目属性的选取原则和用户-项目属性评分矩阵的两种构造方法:均值法和缩放法。该算法首先计算用户在不同属性上的相关相似度,从而得到多个相似邻居集;然后,针对各个邻居集,在用户-项目评分矩阵上产生目标用户对同一项目的多个初步预测评分;最后将评分进行组合作为综合评分,进而对目标用户给出推荐结果。实验结果表明该算法能有效提高推荐精度。
参考文献:附中文
[1]Luo H,Niu C Y,Shen R M,et al.A collaborative filtering framework based on both local user similarity and global user similarity[J].Machine Learning,2008,72(3):231-245.
[2]Huang Chuang-guang,Yin Jian,Wang Jing,et al.Uncertain neighbors’ collaborative filtering recommendation algorithm[J].Chinese Journal of Computers,2010,33(8):1369-1377.(in Chinese)
[3]Lemire D,Maclachlan A.Slope one predictors for online rating-based collaborative filtering[C]∥Proc of SDM,2005:1-5.
[4]Mi Z,Xu C.A recommendation algorithm combining clustering method and slope one scheme[C]∥Proc of ICIC’11,2011:160-167.
[5]Melville P,Mooney R J,Nagarajan R.Content-boosted collaborative filtering for improved recommendations[C]∥Proc of the 18th International Conference on Artificial Intelligence,2002:187-192.
[6]Yang Xing-yao,Yu Jiong,Ibrahim Turgun,et al.Collaborative filtering recommendation models considering item attributes[J].Journal of Computer Applications,2013,33(11):3062-3066.(in Chinese)
[7]Huang M,Sun L,Du W.Collaborative filtering recommendation algorithm based on item attributes[C]∥Proc of the 15th IEEE/ACIS International Conference on Software Engineering,Artificial Intelligence,Networking and Parallel/Distributed Computing(SNPD),2014:1-6.
[8]Xu Hong-yan,Du Wen-gang,Feng Yong,et al.A collaborative filtering algorithm based on multi-attribute rating[J].Journal of Liaoning University(Natural Sciences Edition),2015,42(2):136-142.(in Chinese)
[9]Fan B,Cheng J J.Collaborative filtering algorithm based on users’ multi-similarity[J].Computer Science,2012,39(1):23-26.(in Chinese)
[2]黄创光,印鉴,汪静,等.不确定近邻的协同过滤推荐算法[J].计算机学报,2010,33(8):1369-1377.
[6]杨兴耀,于炯,吐尔根·依布拉音,等.考虑项目属性的协同过滤推荐模型[J].计算机应用,2013,33(11):3062-3066.
[8]徐红艳,杜文刚,冯勇,等.一种基于多属性评分的协同过滤算法[J].辽宁大学学报(自然科学版),2015,42(2):136-142.
[9]范波,程久军.用户间多相似度协同过滤推荐算法[J].计算机科学,2012,39(1):23-26.

龚安(1971-),男,四川巴中人,博士生,副教授,研究方向为数据库及信息系统。E-mail:gongan0328@sina.com
GONG An,born in 1971,PhD candidate,associate professor,his research interests include database, and information system.
A collaborative filtering recommendation algorithm based on ratings of item attributes
GONG An,GAO Yun,GAO Hong-fu
(School of Computer & Communication Engineering,China University of Petroleum,Qingdao 266580,China)
Abstract:Collaborative filtering is one of the most successful techniques in E-commerce recommender system. However, it faces severe problems of sparse user ratings and low recommendation accuracy. To solve the problems of lower recommendation quality caused by rating data sparseness and single rating, we propose a collaborative filtering recommendation algorithm based on ratings of item attributes. Firstly, we construct user-item attribute rating matrices using the mean value method or scaling method to transform single rating to multi-rating. Based on each rating matrix of attributes, we then calculate the similarity among users to obtain the preference set of the nearest-neighbors, and accomplish a primary prediction for each set of the nearest-neighbors based on user-item rating matrices. Finally, we calculate the weighted sum of multiple primary predictions as the final scores, and then complete the recommendation. The experimental results on the extended datasets of Movie Lens show that the proposed algorithm can get higher recommendation accuracy than traditional algorithms.
Key words:attribute rating;mean value method;scaling method;collaborative filtering;recommendation
作者简介:
doi:10.3969/j.issn.1007-130X.2015.12.026
中图分类号:TP311
文献标志码:A
基金项目:中央高校基本科研业务费专项资金资助(14CX06150A)
收稿日期:修回日期:2015-10-21
文章编号:1007-130X(2015)12-2366-06
猜你喜欢
软件导刊(2016年12期)2017-01-21
软件(2016年4期)2017-01-20
计算机时代(2016年12期)2017-01-14
中国新通信(2016年22期)2017-01-13
软件导刊(2016年11期)2016-12-22
现代情报(2016年11期)2016-12-21
电脑知识与技术(2016年27期)2016-12-15
电脑知识与技术(2016年26期)2016-11-24
商(2016年29期)2016-10-29
电脑知识与技术(2016年20期)2016-08-19
