
藏语孤立词语音识别技术研究
2016-01-19 01:13:05赵尔平,王聪华,党红恩等
西北师范大学学报(自然科学版) 2015年5期
关键词:语音识别
E-mail:xdzep@163.com
藏语孤立词语音识别技术研究
赵尔平,王聪华,党红恩,雒伟群
(西藏民族大学信息工程学院,陕西咸阳712082)
摘要:针对藏语读音首先看后加字,然后根据元音的位置关系决定读音,而且元音比辅音携带更多听觉感知信息的特点,提出了一种改进的HTK系统藏语孤立词语音识别技术.在识别特征参数中,增加更能表征元音特征的共振峰参数提高语音识别的正确性,通过循环迭代方法提高语音训练速度,利用藏文字母拉丁转写方法解决藏文和语音识别系统编码不一致的问题.在二次开发的HTK平台进行实验,正确率达到92.83%,实验结果表明元音特征在藏语音识别中起到重要作用.
关键词:藏语孤立词;共振峰;Mel倒谱特征;循环迭代;隐马尔可夫模型;语音识别
收稿日期:2014-12-20;修改稿收到日期:2015-01-25
基金项目:国家自然科学基金资助项目(61162025);西藏自治区自然科学基金资助项目(12KJZRYMY07);西藏自治区科技厅重点项目(藏科发[2013]189号);西藏民族学院重大科研项目(11myZ05)
作者简介:赵尔平(1976—),男,陕西彬县人,副教授,硕士.主要研究方向为数据库技术与语音识别.
中图分类号:TP 912.34文献标志码:A
Research on Tibetan isolated word speech recognition technology
ZHAO Er-ping,WANG Cong-hua,DANG Hong-en,LUO Wei-qun
(College of Information Engineering,Tibet Nationalities Institute,Xianyang 712082,Shaanxi,China)
Abstract:Aiming at Tibetan pronunciation firstly look after hong jia zi,then its pronunciation is determined by the position of vowel,and a vowel carry more auditory perception information than a consonant in speech,a Tibetan isolated word speech recognition technology of improved HTK system is proposed in this paper.The accuracy of speech recognition is improved by increasing a formant parameter in the recognition characteristic parameters,the formant parameter can characterize vowel features very well,the speech training speed is raised by cycle iteration,Tibetan letters transformation Latin alphabet solves inconsistent problem that Tibetan and speech recognition system code.The test is executed on the secondary developing HTK platform,the correct rate reaches 92.83%.Experimental result indicates that vowel features play an important role in Tibetan speech recognition.
Key words:Tibetan isolated word;formant;Mel cepstrum features;loop iteration;HMM;speech recognition
0前言
语音识别是应用多学科交叉知识将语音信号转换为对应文字的技术,目的在于用声音实现人机交互.汉语、英语等主流语言的语音识别已取得很多成果,实验室环境下的识别效果可以满足人机交互系统的需要,在一些领域被广范应用.但是藏语语音识别还处在孤立词阶段,刚刚起步.
1相关概念
1.1隐马尔可夫模型
隐马尔可夫模型(Hidden Markov model,HMM)是一种具有双重随机过程的统计分析模型,定义为五元组[1]67:
其中,
1)S为隐含状态,S={s1,s2,…,sN},N为隐含状态数目;
2)O为可观察状态,O={o1,o2,…,oM},M为可观察状态数目,M=N或M≠N;
3)Π为初始状态概率矩阵,Π={π1,π2,…,πN}, πi=P(x0=si)(1≤i≤N)为初始时刻t=0模型各状态的概率;


1.2HTK工具
HTK(HiddenMarkovmodeltoolkit)是英国剑桥大学开发的一套构建隐马尔可夫模型(HMM)的工具箱,主要用于语音合成与识别、故障诊断和DNA排序等领域[2],其核心功能包括数据准备、模型训练、语音识别.HTK具有允许用户根据实际需要进行二次开发的开源代码.
1.3藏语简介
藏语是一种拼音文字,有30个辅音、4个单元音和1个无符号元音.国内学术界将藏语主要分为卫藏、安多和康三大方言[3].三大方言文字相同,发音有较大差异,文中选用使用人数最多、最具有代表性的卫藏方言(拉萨话)作为研究对象.
2卫藏语音及元音特征研究
2.1卫藏语音
卫藏方言作为现代藏语的标准,在长期应用发展中形成自己的规律与特点.研究表明[4],现代拉萨话的声母系统已经基本没有复辅音.声母系统主要指单辅音声母,共28个;韵母有45个(由单元音韵母、复合元音韵母和辅音韵尾的韵母三部分组成),韵母中有/a/,/i/,/u/,/e/,//,/ε/,/y/,/ø/ 8个基本元音、/iu/,/au/ 2个复合元音和7个辅音韵尾.现代拉萨话中单元音增多,尤其是鼻化元音,元音发音长短与声调有互补关系.藏语字母有一套严格排列规则,元音符号不能作为基字丁,只能固定地叠加在基字的上方或下方表示不同元音.元音的主要作用是做音节的韵母,每个音节中必须包含元音,元音在字母中的位置不同发音也不同.藏语先看后加字,然后根据元音的位置关系决定读音[5].
2.2元音特征
Cole等提出元音比辅音对语音听觉感知更为重要[6].文献[7]采用噪声替换实验方法分别替换掉语音中的元音和辅音,实验结论是替换掉辅音的语音比替换掉元音的语音具有更高的识别率(比率约为2∶1),证明了元音比辅音携带了更多的信息.Kewley-Port等采用同样方法研究孤立词语音,发现元音比辅音携带了更多对语句可懂度有用的信息[8-9].由此可见,在语音识别中应用和识别元音特征至关重要.
元音激励进入说话人声道引起共振,产生一组共振频率——共振峰,声学界学者研究表明[10],共振峰是区别不同元音的重要声学特征.由于藏语发音与元音位置有关,元音又比辅音携带了更多听觉感知信息,且卫藏韵母中包含8个基本元音和2个复合元音,所以提取共振峰参数(主要是前3个共振峰f1,f2,f3)对识别带有不同元音的藏语音增加了可靠的声学特征.因此文中在蔵语孤立词语音识别中,除了使用Mel倒谱参数外,增加共振峰参数来提高识别正确率.
3改进的HTK平台卫藏语音识别
HTK平台利用12维MFCC系数和1维数能量经过一阶、二阶差分变后的39维MFCC特征向量进行语音识别,没有使用共振峰参数,文中对HTK平台进行改进,增加共振峰声学特征,与MFCC参数结合进行藏语音识别.
3.1提取共振峰特征
共振峰信息包含在语音频率包络之中,因此共振峰参数信息提取的关键是估计自然语音频谱包络,并认为谱包络中的最大值就是共振峰[11].提取共振峰参数的方法主要有倒谱法和线性预测法(LPC),倒谱法可以较好地分离出语音信号频谱包络结构.文中特别采用倒谱法,利用把语音频谱进行z变换、取对数和傅里叶变换变换等得到语音频谱的包络曲线.下面是倒谱法原理:选用最普遍的极零模型来描述表征声道响应x(n),其z变换公式为[12]58
经傅立叶、取对数和逆傅立叶变换得到复倒谱公式为
(3)
倒谱算法将基音谐波和声道的频谱包络分离开,再对频谱包络曲线进行离散傅里叶变换得到离散谱曲线.按照离散频谱包络曲线各峰值能量的大小确定出1~4共振峰参数[11],而前3个共振峰参数就足以确定语音信号中的不同元音.提取中采用同态解卷技术消除基频谐波的影响,获得更精确的共振峰参数.
3.2共振峰与MFCC结合
人耳对低频(<1 000 Hz)感知灵敏,感知力与频率大致呈线性关系;而对高频(>1 000 Hz)感知比较模糊,感知力与频率呈对数关系[13].Mel频率描述了人耳的这一听觉特性,将频谱转换为基于Mel频标的非线性频谱,再转换到频谱域中,Mel频标与频率f的关系可用下式近似表示[13]1333:

MFCC参数提取步骤包括:① 预加重;② 分帧加汉明窗;③ 快速傅利叶转换;④ 三角带通滤波;⑤ 离散余弦变换得到12维MFCC系数;⑥ 对数能量;⑦ 差分变换.
在差分变换之前,将3.1节中提取的f1,f2,f3共振峰参数增加到HTK系统,使得每帧语音基本特征为16维(1维对数能量、12维MFCC系数和3维共振峰参数),然后将16维基本特征进行一阶、二阶差分变换得到48维特征向量,即语音的差量倒频谱参数,它可以增加语音的动态特征.文中用48维差分倒谱参数对拉萨话语音进行训练与识别.
3.3循环迭代训练
改进HTK训练过程(hmm0→hmm1→hmm2→hmm3→hmm4…),采用循环迭代训练过程(图1).采用循环迭代有两点益处:① 多次修正HMM模型参数的初始值(hmm3→hmm0迭代),使训练算法快速收敛;② 有利于统一搭建语音识别系统环境.由于每个单词发音不同,训练时的观察值个数不同,训练模型重估迭代次数存在不同,结果输出需要的文件目录就不一样多,不利于环境搭建.改进的循环迭代训练给每个单词统一搭建3个观察值目录,如果hmm2到hmm3迭代还未收敛,则继续hmm3到hmm0迭代,直到hmm2到hmm3迭代收敛时停止训练.

图1 循环迭代训练
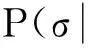
基于Baum-Welch算法[14]的训练本质上是一种梯度下降方法,在训练过程中可能存在局部极小问题,所以训练开始用HCompv工具对模型平坦初始化,用可变基底宏(varFloor1)的值在后续训练过程中作为估计的变化向量的基底,当后续训练某状态的估计变化值很小时,就用基底宏的值来代替,以避免局部极小问题,使得训练算法快速准确收敛.实践表明,循环迭代不会影响藏语音识别正确率,反而会加快训练速度,并使藏语音识别系统环境配置统一起来.
3.4藏文拉丁转写
HTK工具箱是用来识别英语语音的,程序和配置文件(语法、任务字典、语音标注等)编码格式都是ANSI编码,文献[15]所述藏语字库国际标准编码是Unicode编码,如果配置文件中直接输入藏文就会成乱码,所以此系统不能直接识别藏语音.藏语研究者通常将藏文字母转写为拉丁字符来表示藏语的发音,所以文中采用国际通用的藏文字母拉丁转写来表示藏语单词,按文献[16]中规则转写.藏文拉丁转写方法解决了藏文与HTK系统编码不一致问题,方便改进的HTK系统实现藏语音识别.
4实验结果与分析
对HTK系统进行二次开发,增加共振峰参数提取、统计和分析功能,把原来的HTK平台系统与改进后的HTK平台系统进行比较实验测试.实验中,用于声学模型训练和测试的孤立词语音集采用16K采样频率,用16bit量化精度,双声道麦克风连接PC机在实验室环境下录制.选择拉萨地区发音标准的10位藏族学生(5男、5女)作为训练语料库发音对象,训练语料库包含10个学生对60个藏语词汇的一次朗读语音数据.测试语音库是30 个说话人(15 男、15 女)分别对60个训练词3次朗读语音数据,频谱特征观察矢量为每帧48 维向量.图2是改进后的HTK平台上进行的某一次测试结果,图2中单词识别率是93.55%,N=62表示被识别的孤立词总数(60个词和1个开始标志与1个结束标志),H=58表示正确识别词的数量,参考副本ref.mlf是训练时的整个语音标注文件,识别副本reco.mlf是测试时整个语音标注文件.通过比较语音在参考副本和识别副本中每项数据,进行识别性能测评.
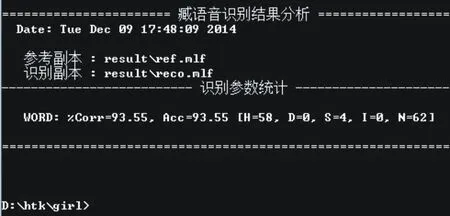
图2 改进的 HTK上某次识别结果
HTK与改进后的HTK系统30次平均测试结果如表1所示.由表1可知,共振峰与MFCC参数结合的方法(改进后的HTK)明显提高了拉萨话非特定人孤立词语音识别正确率,再次证明元音特征为孤立词识别提供了有用信息,元音在藏语发音中具有重要作用.实验过程中发现影响识别率的因素有:① 语音信号正确标注,每个孤立词语音信号标注3个区域:开始停顿区、单词语音区、结束区,3个区域不能重叠,要有很小的间隙.② 训练的语音必须有3个以上观察序列,否则不能训练,所以不能把一个人的连续几次发音数据作为语料库.③ 虚假共振峰影响识别率,尽量完全消除.④ 实验过程证明HMM模型选6个状态最佳,状态数增加或减少不会增加识别正确率.⑤ 循环迭代训练法不影响识别结果.

表1 两个系统识别结果比较
5结束语
文中对藏语拉萨话孤立词语音进行了分析,提出语音共振峰与MFCC参数为特征的藏语孤立词识别技术.在二次开发的HTK平台上进行测试,证明该方法明显提高藏语孤立词语音识别率,并指出影响识别率的几个干扰因素和解决方法.拉萨话是有声调的,长短声调与韵母发音有严格对应关系,今后研究方向是如何提取声调特征参与识别.而基字丁拆分技术可以实现藏语音中声母和韵母分离,声母、韵母声学特征也是今后研究的重要方向.
参考文献:
[1]王川,段德全,王晓东.基于改进的POS和HMM的Web信息抽取算法[J].河南师范大学学报(自然科学版),2010,38(5):65.
[2]魏 巍,张海涛.一种基于HTK 的数字语音识别系统[J].计算机系统应用,2011,20(9):17.
[3]李冠宇,孟猛.藏语拉萨话大词表连续语音识别声学模型研究[J].计算机工程,2012,38(5):189.
[4]于洪志,高璐,李永宏,等.藏语机读音标SAMPA_ST的设计[J].中文信息学报,2012,26(4):67.
[5]刘博,杨鸿武,甘振业,等.利用SAMPA实现藏语的字音转换[J].计算机工程与应用,2011,47(35):117.
[6]COLE R A,YANG Hong-yan,MAK B,et al.The contribution of consonants versus vowels to word recognition in fluent speech[C]//ProcICASSP1996.Atlanta:IEEE,1996:853.
[7]KEWLEY-PORT K,BURKLE Z,LEE Jae Hee.Contribution of consonant versus vowel information to sentenceintelligibility for young normal-hearing and elderly hearing-impairedlisteners[J].AcousticalSocietyofAmerica,2007,122(4):2365.
[8]LEWICHI M S.A signal take on speech[J].Nature,2010,466(12):821.
[9]颜永红,李军锋,应冬文.语音中元音和辅音的听觉感知研究[J].应用声学,2013,32(3):231.
[10]赵力.语音信号处理[M].北京:机械工业出版社,2003:5-9.
[11]王坤赤,蒋华.基于语音频谱的共振峰声码器实现[J].现代电子技术,2007(21):168.
[12]王晓亚.倒谱在语音的基音和共振峰中提取的应用[J].无线电工程,2004,34(1):57.
[13]王宏志,徐玉超,李美静.基于Mel频率倒谱参数相似度的语音端点检测算法[J].吉林大学学报(工学版),2012,42(5):1331.
[14]张增银,元昌安,胡建军,等.基于GEP和Baum-Welch算法训练HMM模型的研究[J].计算机工程与设计,2013,31(9):2027.
[15]黄鹤鸣,赵晨星.藏文信息处理的Windows支持环境[J].计算机应用与软件,2009,26(12):188.
[16]李用宏,孔江平,于洪志.藏语文-音自动规则转换及其实现[J].清华大学学报(自然科学版),2008,48(S1):622.
(责任编辑惠松骐)

猜你喜欢
科技创新与应用(2017年3期)2017-02-18 15:47:14
中国新通信(2016年21期)2017-01-06 13:55:48
电脑知识与技术(2016年12期)2016-06-14 00:01:51
智富时代(2015年9期)2016-01-14 06:26:40
电脑知识与技术(2015年25期)2015-12-08 13:10:12
物联网技术(2015年9期)2015-09-22 09:34:29
现代电子技术(2015年11期)2015-07-28 12:23:40
现代电子技术(2015年8期)2015-07-09 21:40:50
电子技术与软件工程(2015年6期)2015-04-20 17:21:52
无线互联科技(2015年2期)2015-04-02 14:23:43
