
基于Hadoop的数据仓库构建模式研究
2015-12-31 08:42:00王缓缓郭敬义张警灿余肖生
重庆理工大学学报(自然科学) 2015年7期
王缓缓,郭敬义,张警灿,余肖生
(三峡大学 计算机与信息学院,湖北 宜昌 443002)
基于Hadoop的数据仓库构建模式研究
王缓缓,郭敬义,张警灿,余肖生
(三峡大学 计算机与信息学院,湖北 宜昌443002)
摘要:针对目前基于Hadoop的数据仓库一般采用“一对一”的模式或方法构建的情况,首先通过实例分析其不足之处;然后借鉴软件工程中的“生成器”设计模式的思想,提出一种Hadoop数据仓库的构建模式,称为“元数据驱动的生成器模式”,用于构建基于Hadoop的数据仓库,即ETL过程。该模式具有两点优势:一是由元数据驱动,充分发挥了关系数据库管理系统对元数据操作的效率优势;二是识别了“通用知识”和“具体对象知识”两类知识,并在对知识的分类基础上设计和实现ETL过程,消除了“一对一”模式下大量不必要的重复操作。
关键词:云计算;大数据;数据仓库;Hadoop;ETL
目前,如何对大规模的历史数据进行有效的管理和挖掘,从中发现有用的信息用以辅助管理决策已经成为相关领域的研究课题。数据仓库在此需求背景下产生和发展。数据仓库是一个“面向主题的、集成的、与时间有关的、非易失的数据集合”,它是一个存储了依据业务需求经过转换和清洗后数据的数据库[1]。ETL将数据抽取(Extract)、转换(Transform)以及加载(Loading)到数据仓库或数据集市中,以备前段分析工具使用[2-4]。ETL作为BI/DW(businessintelligence)的核心和灵魂,是实施数据仓库的重要步骤,也是数据仓库实施过程中工作量最大的环节。因此,对其进行系统的改进具有现实意义。
现有的关于数据仓库ETL理论的研究主要集中在ETL建模研究[5-6]和ETL过程研究[7-14]两个方面。此外,在数据仓库ETL的实践方面也有很多成果。商用的ETL工具方面,例如IBM公司的Datastage、Informatica公司的Powercenter、微软公司的DataTransformationServices(DTS)、NCRTeradata公司的ETLAutomation;开源的ETL工具方面,例如Kettle、Talend、CloverETL等[15-16]。但是这些ETL工具基本上被用于传统的关系型数据仓库。另外,由于这些工具建立在操作系统和数据库管理系统之上,故其运行效率打了折扣,而对于数据仓库特别是基于云计算的数据仓库构建来说,其数据量相当大,故命令行模式效率最高。然而,如果ETL系统是基于命令行模式的,那么传统的关系型数据仓库构建则不能借助辅助ETL工具,而需要自行开发[17]。
目前基于云计算的数据仓库ETL理论方面的研究相对较少,用于构建HadoopHive数据仓库的成熟的第三方ETL工具也较少,基本上是用户自行开发。通过对现有理论和实践成果进行总结可以发现,Hive在辅助用户实现云数据仓库的ETL过程时,基本是一对一(case-to-case)模式。例如平面文件在抽取、转换和加载时只能是按照每个文件逐一进行,而不能批量进行。这种模式的生产效率较低。对于具体对象,如某个具体的平面文件,这些不同的平面文件的内容各不相同,即是不重复的,本文称之为“具体对象知识”。而对于加载这些平面文件时用到的HiveQL关键字和语法则是相同的,本文称之为“通用知识”。“一对一”模式在实现云数据仓库ETL过程时,具体对象知识和通用知识是混合的、不易清晰分离的。“通用知识”由开发设计人员设计完成后,在大量的设计说明书、程序及测试说明书中不断重复出现,导致了设计、开发、测试部门的重复劳动,是造成“一对一”模式实现云数据仓库ETL过程低效的主要原因[18],因此改进云数据仓库ETL过程的模式是非常必要的[19]。
生成器模式 (builderpattern) 是软件工程设计模式的一种,它将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示[20]。本研究借鉴其思想,将云数据仓库ETL过程中的“通用知识”和“具体对象知识”识别并分离开来,在知识分类的基础上设计并实现Hadoop/Hive数据仓库ETL系统。
1Hadoop/Hive及生成器模式
1.1 Hadoop项目及其结构
大数据时代,对于如何高效地存储、管理和分析海量数据,传统的关系型数据仓库已经不能满足现有需求,云计算以其强大和高效的存储和计算能力正在成为海量数据管理的经济有效方式。
Hadoop是一个开源的分布式云计算平台,其核心是分布式文件系统(hadoopdistributedfilesystem,HDFS)和MapReduce。Hive是一个建立在Hadoop基础上的数据库管理系统,提供类似于传统RDBMS中SQL语言的查询语言,即HiveQL(hiveSQL)。Hive编译器把HQL编译成一组MapReduce任务,在用户与MapReduce之间建立一个桥梁,以方便用户进行Hadoop系统开发[21]。Hive的系统结构如图1所示。
元数据对Hive来说至关重要。Hive的元数据存储在传统的RDBMS中,Hive通过ODBC或者JDBC连接RDBMS。这样做是因为通常需要快速地访问这些Metadata,如果将元数据存储在hdfs中是无法满足要求的。本文提出的构建HadoopHive数据仓库的生成器模式正是由Hive元数据驱动,对于提高构建效率可起到至关重要的作用。Hive元数据组织结构如表1所示。
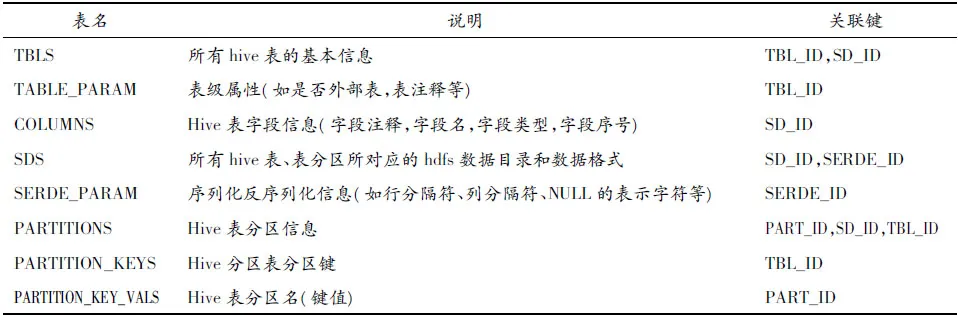
表1 Hive元数据组织结构
1.2 生成器模式
在软件工程中,生成器模式(builderpattern)是指建造者模式可以将一个产品的内部表象与产品的生成过程分割开来,从而使一个建造过程生成具有不同的内部表象的产品对象。生成器模式的结构如图2所示。
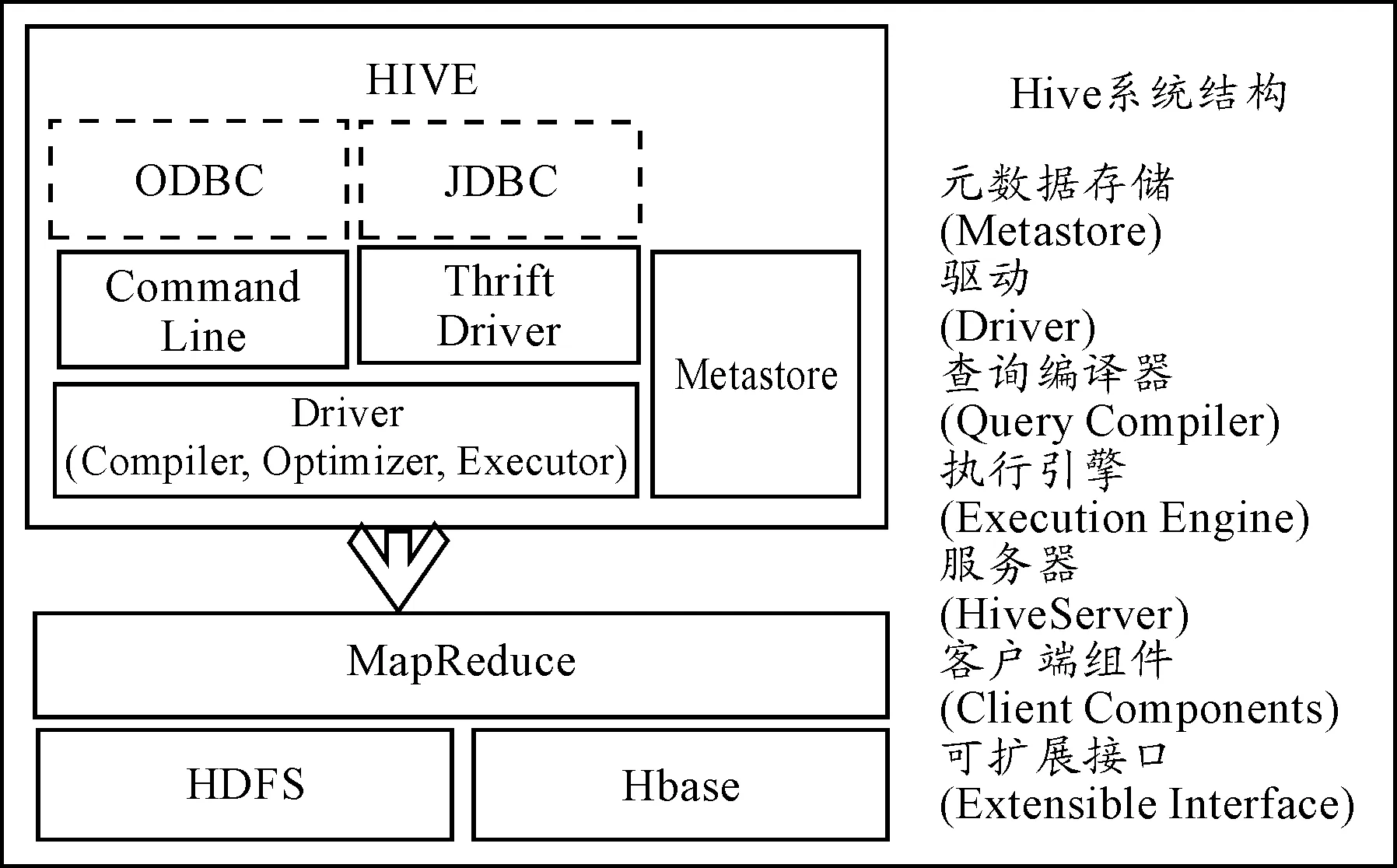
图1 Hive系统结构
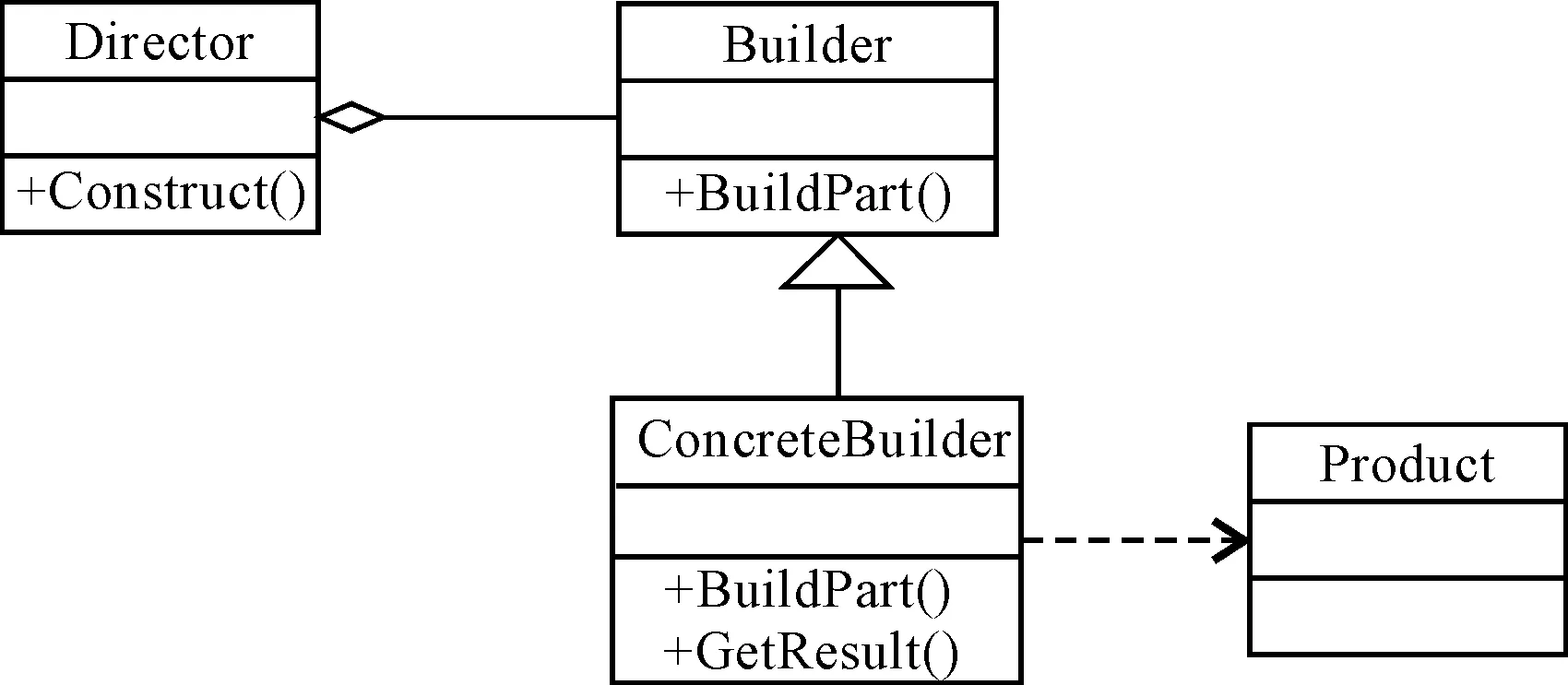
图2 生成器模式的结构
建造者(Builder)角色:给出一个抽象接口,以规范产品对象的各个组成成分的建造。一般而言,此接口独立于应用程序的商业逻辑。模式中直接创建产品对象的是具体建造者(ConcreteBuilder)角色。具体建造者类必须实现这个接口所要求的方法:一个是建造方法,另一个是结果返还方法。
具体建造者(ConcreteBuilder)角色:担任这个角色的是与应用程序紧密相关的类,它们在应用程序调用下创建产品实例。这个角色主要完成的任务是实现Builder角色提供的接口,逐步完成创建产品实例的过程,并在建造过程完成后提供产品的实例。
指导者(Director)角色:担任这个角色的类调用具体建造者角色以创建产品对象。指导者并没有产品类的具体知识,真正拥有产品类的具体知识的是具体建造者对象。
产品(Product)角色:建造中的复杂对象。
指导者角色是与客户端打交道的角色。建造者角色将客户端创建产品的请求划分为对各个零件的建造请求,再将这些请求委派给具体建造者角色。具体建造者角色做具体建造工作,但不为客户端所知。
本文借鉴生成器模式的思想,采用shell脚本和关系数据库的存储过程来构建基于Hadoop/Hive的数据仓库。
2Hadoop/Hive数据仓库的一般构建模式分析
以一个简单抽象的平面文件“test.txt”的抽取和加载到Hadoop/Hive数据仓库的“test表”为例,对基于传统范式的数据仓库构建行为进行分析。
首先假设在Hadoop中已经建了一张“test”表,建表的HiveQL语句为“CREATETABLEpokes(SNOINT,SNamestring,BirthDate)”,即“test表”含有SNO、SName、Birth3个字段。然后将test.csv文件加载到hadoop/hive的test表:
hive>LOADDATALOCALINPATH′/mgo/test.txt′OVERWRITEINTOTABLEtest
该操作仅完成一个平面文件的加载,如果有更多的平面文件需要加载,则必须根据要加载的平面文件的具体情况,多次复制并局部修改上述语句。因此,采用这种方法构建HadoopHive数据仓库,本文称为“一对一”模式。需要指出的是,在加载之前通常伴随着数据的清洗工作,因而如果采用“一对一”模式构建HadoopHive数据仓库,效率是非常低的。
3基于元数据驱动的生成器模式构建Hadoop/Hive的数据仓库
3.1 通用知识和具体对象知识
分析上面的实例,可以发现最突出的问题是“重复”。这里有两种类型的“重复”:
1) 内容重复:例如,上述完整加载过程的HiveQL命令“LOADDATA文件名intoTable表名”。
2) 操作重复:即上述HiveQL命令的编辑操作,旨在为产生后续的加载更多的平面文件:“复制(命令语句)-粘贴(多次)-搜索(表名和文件名,多次)-替换(用新的表名和文件名替换旧的多次)-调整(如有必要的话,多次)-验证(验证结果语句是否正确,多次)”。
这些内容重复和操作重复正是导致“一对一”模式构建Hadoop/Hive数据仓库低效的主要原因。 内容重复出现的原因是因为上述创建表和加载平面文件的HiveQL命令是相同的,本文中称类似重复的内容为“通用知识”。而在上述平面文件加载的实例中,表名和文件名是不重复的,称之为“具体对象知识”。因此,可以总结如下规律:在实现Hadoop/Hive数据仓库ETL过程中通用知识重复,具体对象知识的载体不重复。
在“一对一”模式下,两类知识是混合的,不易清晰分离。这就是“一对一”模式的本质特征,正是该特征导致了“一对一”模式大量的内容重复和操作重复,是其效率低下的主要原因。
3.2 构建Hadoop/Hive数据仓库的元数据驱动的生成器模式分析
本节仍以平面文件加载为例,介绍构建Hadoop/Hive数据仓库的元数据驱动的生成器模式。Hadoop/Hive的元数据是采用关系型数据库管理系统来存储的,本文提出的生成器模式是一种元数据驱动的、并采用shell脚本来生成Hive脚本代码的方法,其工作流程如图3所示。
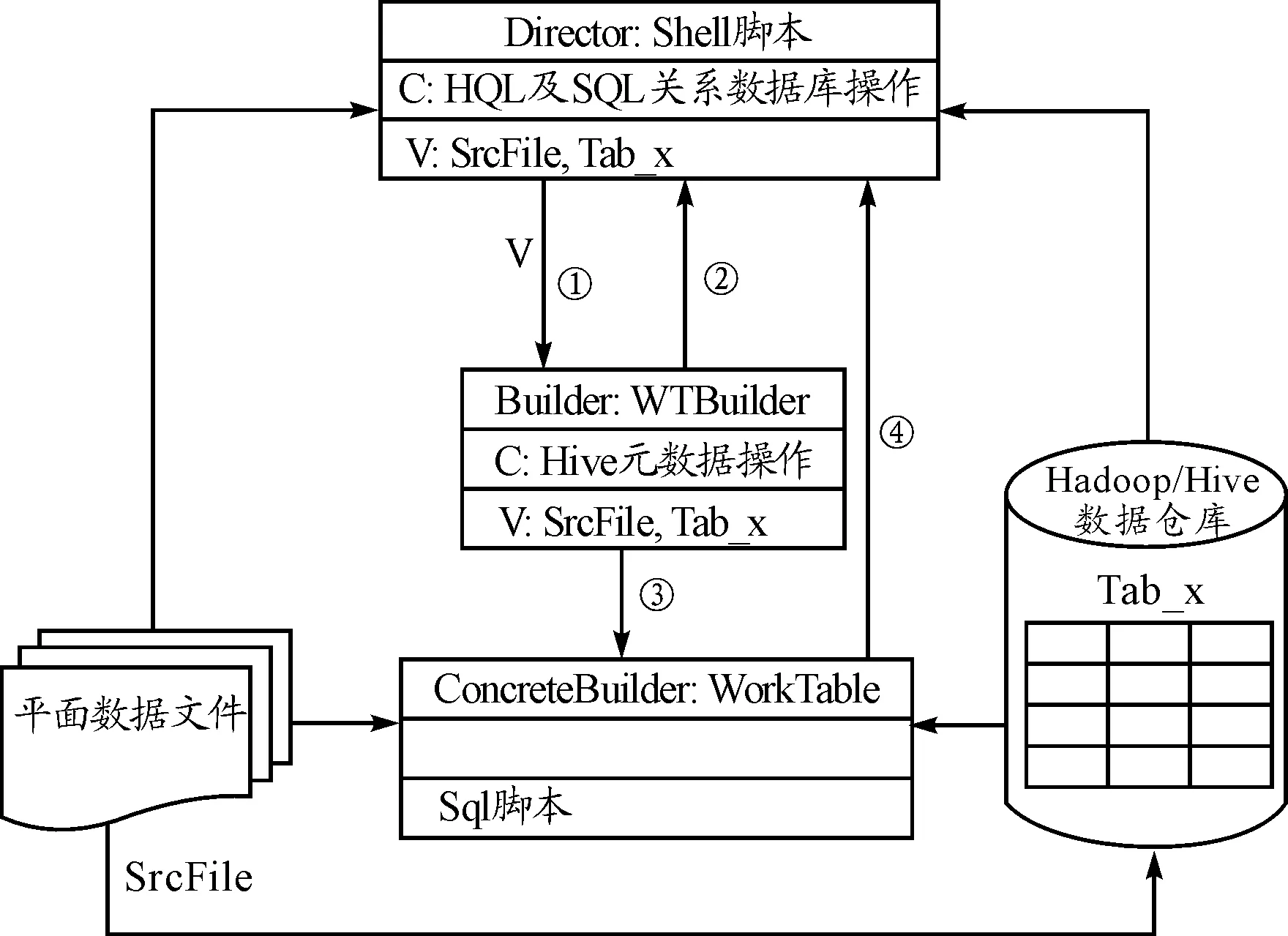
图3 构建Hadoop/Hive数据仓库的元数据驱动的
构建Hadoop/Hive的数据仓库的元数据驱动的生成器模式的具体实现伪代码如图4所示。
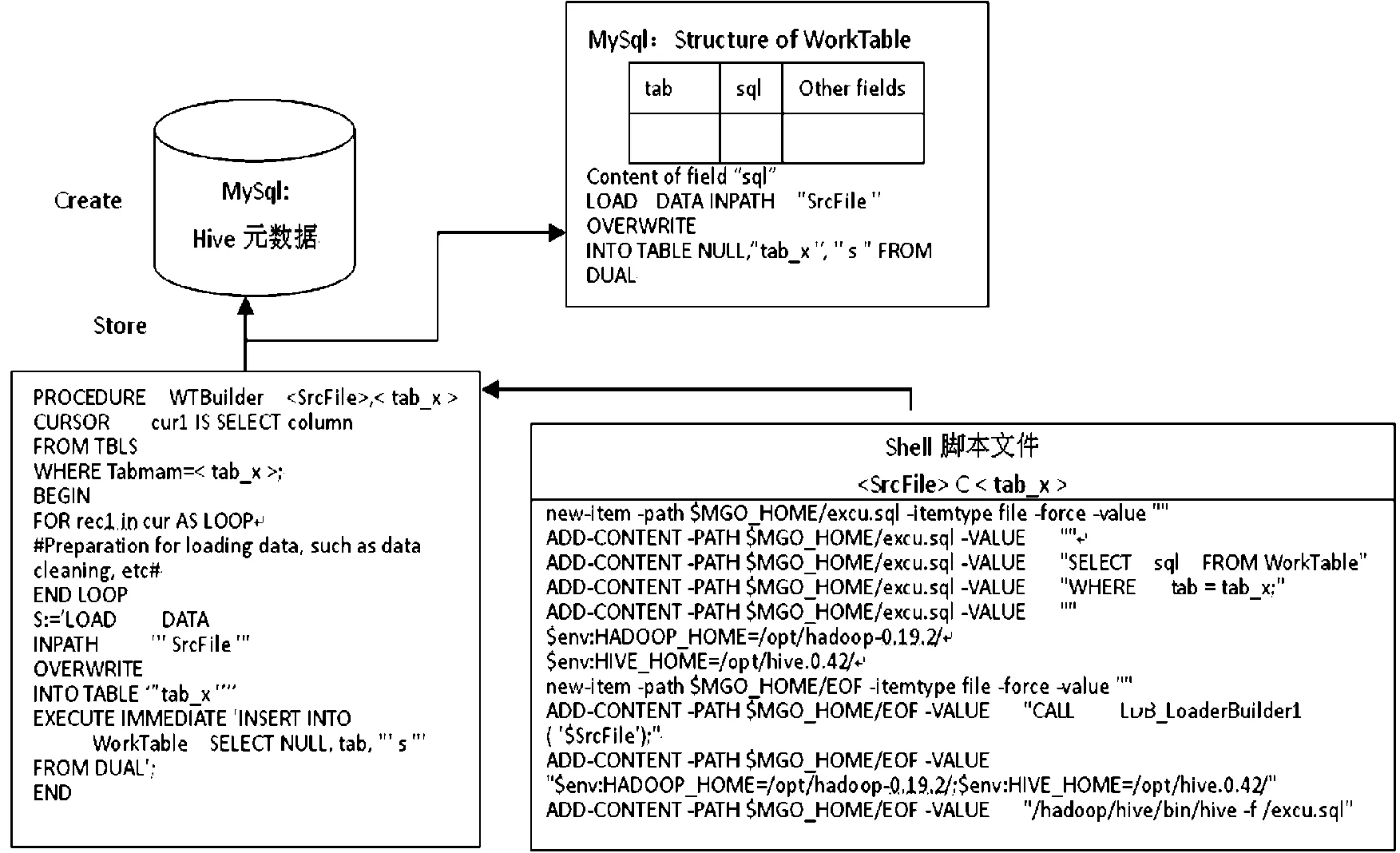
图4 存储过程和Shell脚本的伪代码及其执行顺序
对于采用元数据驱动的生成器模式,将具体对象知识作为shell脚本文件的参数。脚本文件通过调用关系数据库中的存储过程生成要加载的平面文件的HiveQL脚本文件,再将HiveQL脚本文件导入到Hive执行,完成具体某一个平面文件的加载。仅通过在Shell脚本文件给出平面文件参数即可,不需做“查找&替换”。此外,通过关系数据库的存储过程来操作Hive元数据相比在Hive中使用HiveQL命令操作Hive数据的效率要高很多,因此,与“一对一”模式相比,元数据驱动的生成器模式的效率明显提高。
4结束语
本文设计了一种构建基于Hadoop/Hive数据仓库的方法,称为“基于Hive元数据的生成器模式”。这种模式由于建立在“通用知识”和“具体对象知识”两类知识分类的基础上,因而有着更高的灵活性、可扩展性。实践证明,将本方法用于HadoopHive的数据仓库ETL过程可以取得较好的效果。
参考文献:
[1]InmonWH.BuildingtheDataWarehouse[M].America:JohnWiley,1992.
[2]Luján-MoraS,VassiliadisP,TrujilloJ.DataMappingDiagramsforDataWarehouseDesignwithUML[C]//Proc.ofthe23rdInternationalConferenceonConceptualModeling.USA:Springer,2004:191-204.
[3]TrujilloJ,Lujan-MoraS.AUMLBasedApproachforModelingETLProcessesinDataWarehouses[C]//Proc.ofthe22ndInternationalConferenceonConceptualModeling.NewYork:ACM,2003:7-320.
[4]VassiliadisP,SimitsisA,GeorgantasP,etal.AGenericandCustomizableFrameworkfortheDesignofETLScenarios[J].InformationSystems,2005,30(7):492- 525.
[5]鲍玉斌,孙焕良,冷芳玲,等.数据仓库环境下以用户为中心的数据清洗过程模型[J].计算机科学,2004,31(5):52-55.
[6]SellisT.FormalspecificationandoptimizationofETLscenarios[C]//Proceedingsofthe9thACMinternationalworkshopondatawarehousingandOLAP.NewYork:ACM,2006:1-2.
[7]SkoutasD,SimitsisA.Ontology-basedConceptualDesignofETLProcessesforbothStructuredandSemi-structuredData[J].Semanticwebandinformationsystems,2007,3 (4):1-24.
[8]KimballR,CasertaJ.TheDataWarehouseETLToolkit[M].USA:JohnWiley&Sons,2004.
[9]Oracle.OracleWarehouseBuilderProductPage[EB/OL].[2014-11-17].http://otn.oracle.com/products/warehouse/content.html.
[10]HalevyA,RajaramanA,OrdilleJ.Dataintegration:theteenageyears[C]//Proceedingsofthe32ndinternationalconferenceonverylargedatabases.NewYork:ACM,2006:9-16.
[11]VassiliadisP,VagenaZ,SkiadopoulosS,etal.Arktos:towardsthemodeling,design,controlandexecutionofETLprocesses[J].InformationSystems,2001,26 (1):537-561.
[12]XuJG,PeiY.Overviewofdataextraction,transformationandloading[J].JournalofComputerScienceinChina,2011,38(4):15-20.
[13]戴超凡,王涛.面向ETL的数据起源追踪系统[J].计算机工程,2011,37(17):256-261.
[14]宿芳,寿永熙,苏依拉.元数据驱动ETL的研究[J].计算机工程与应用,2012,48(6):114-125.
[15]IBM.IBMDataWarehouseManager[EB/OL].[2014-11-17].http://www-3.ibm.com/software/data/db2/datawarehouse.
[16]Informatica.PowerCenter[EB/OL].[2014-11-17].http://www.informatica.com/products/powercenter.
[17]蒋彬,余肖生,王东娟,等.数据仓库构建之行为模式分析[J].信息系统学报,2013(12):1-8.
[18]余肖生,吴西燕,王东娟,等.基于MGO的数据仓库ETL过程构建方法[J].重庆理工大学学报:自然科学版,2014,28(2):63-66.
[19]JiangB.基于元数据驱动通用操作器的数据仓储构建[M].郑悦林,译.武汉:武汉大学出版社,2013.
[20]GammaE,HelmR,JohnsonR,etal.DesignPatterns:AbstractionandReuseofObject-OrientedDesign[M].USA:Addison-WesleyProfessional,1994:11.
[21]Hadoop[EB/OL].[2014-11-25].http://hadoop.apache.org.
(责任编辑杨黎丽)
收稿日期:2015-03-22
基金项目:湖北省教育厅自然科学研究项目(Q20141212)
作者简介:王缓缓(1978—),女,博士,副教授,主要从事信息管理与数据挖掘研究。
doi:10.3969/j.issn.1674-8425(z).2015.07.013
中图分类号:TP311
文献标识码:A
文章编号:1674-8425(2015)07-0069-05
ResearchonConstructionPatternofHadoopDataWarehouse
WANGHuan-huan,GUOJing-yi,ZHANGJing-can,YUXiao-sheng
(CollegeofComputerandInformationTechnology,
ChinaThreeGorgesUniversity,Yichang443002,China)
Abstract:The “case to case” pattern is a commonly used method for constructing Hadoop Hive data warehouse recently. Firstly, the “case to case” pattern was introduced and its disadvantage was shown with an example. Then inspired by the “Builder Pattern” which is one of design patterns in the area of software engineering, a pattern called “metadata-driven builder pattern” was put forward for constructing Hadoop Hive data warehouse and ETL process. This pattern has two advantages. One is that it is driven by the metadata and the metadata is operated by the relational database management (RDBMS). Doing so can achieve higher efficiency because the metadata of Hive is just stored in the RDBMS. The other one is that the “general knowledge” and “specific-object knowledge” are differentiated and the ETL process is designed and realized based on such differentiation. Doing so can avoid lots of repetitions that the “case to case” pattern leads to.
Key words:cloud computing; big data; data warehouse; Hadoop; ETL
引用格式:王缓缓,郭敬义,张警灿,等.基于Hadoop的数据仓库构建模式研究[J].重庆理工大学学报:自然科学版,2015(7):69-73.
Citationformat:WANGHuan-huan,GUOJing-yi,ZHANGJing-can,etal.ResearchonConstructionPatternofHadoopDataWarehouse[J].JournalofChongqingUniversityofTechnology:NaturalScience,2015(7):69-73.
猜你喜欢
自然资源信息化(2019年4期)2019-03-29 03:20:48
电子制作(2016年15期)2017-01-15 13:39:15
山东工业技术(2016年15期)2016-12-01 05:31:24
电脑知识与技术(2016年21期)2016-10-18 22:11:15
大学教育(2016年9期)2016-10-09 08:54:03
科技视界(2016年20期)2016-09-29 13:34:06
科技视界(2016年20期)2016-09-29 10:53:22
中国教育信息化(2015年10期)2015-08-23 11:43:42
