
MapReduce环境中的性能特征能耗估计方法
2015-12-26 02:49:06樊源泉伍卫国许云龙高颜
西安交通大学学报 2015年2期
樊源泉,伍卫国,许云龙,高颜
(西安交通大学电子与信息工程学院,710049,西安)
MapReduce环境中的性能特征能耗估计方法
樊源泉,伍卫国,许云龙,高颜
(西安交通大学电子与信息工程学院,710049,西安)
针对MapReduce系统中负载能耗特征多样性为系统成本调度带来的负载与节点难以匹配的问题,提出一种基于负载性能特征的能耗估计方法。该方法以MapReduce系统中各节点操作系统的性能事件为依据估计在线负载的能耗。为了提升负载能耗估计结果的准确度,采用机器学习的方法,在负载执行时,搜集系统的性能特征,并建立估计模型的样本集;采用粗糙集理论中属性约简方法对性能特征属性进行约简;在性能属性约简的结果之上,基于支持向量机理论,建立能耗的估计模型,对负载运行时系统的能耗进行准确的估计。实验结果表明:基于性能特征的能耗估计方法拥有较高的估计准确率,在单作业环境中平均相对误差为4%,在多作业环境中可达到4.5%。
能耗估计;性能特征;MapReduce
随着MapReduce[1]应用的增多及数据处理规模的剧增,基于MapReduce计算模型的集群系统的能耗问题变得日益突出。平台资源协调器YARN(yet another resource negotiator)[2]是支持MapReduce计算模型的新一代开源系统,提升YARN系统中作业执行的能效对于节约成本、保护环境意义重大。但是,YARN集群中任务随机达到的特性,造成集群中部分工作节点在某些时间段出现空闲等待,系统能源的利用率较低[3]。此外,集群工作节点的异构特性导致系统负载失衡,这也对系统的能效产生负面影响。当前提升YARN集群系统能效的方法分为两类:基于工作节点伸缩的节能方法和基于负载成本调度的节能方法[4]。在以上两种方法中,一个核心的问题是负载能耗特征的获取,据此为各个工作节点匹配合适的负载。因此,负载能耗的准确估计是提升YARN系统能效的关键。但是,YARN系统中众多的配置参数、工作节点的异构特性及负载性能特征的多样性为能耗估计带来了挑战。
当前,针对MapReduce系统中负载能耗估计的方法有如下两类。第一类为基于硬件性能计数器的能耗估计方法。该类方法在作业执行过程中,采集工作节点中各个组成部件的性能计数器数据,据此估计工作节点的能耗。Rong等提出了eTune系统[5-6],该系统依赖于专用的能耗测量设备测量工作节点中各个功能部件的能耗,面对数据中心中大规模的工作节点,可用性不强。另外,该方法适用于CPU密集型的负载,针对I/O密集型的负载,估计结果的准确性不高。第二类方法采用软件测量的方式估计系统的能耗。Fan等基于CPU利用率建立了工作节点的能耗估计模型[7]。针对异构的Web服务器,Taliver等考虑磁盘利用率及CPU利用率对能耗的影响,建立了能耗估计模型[8]。但是,以上两种方法仅考虑工作节点中个别组件产生的能耗,预测结果的准确度不高。Suzanne等开发了Mantis系统[9]估计负载产生的能耗。Mantis系统仅考虑CPU及磁盘产生的能耗,将CPU利用率和磁盘利用率作为模型的参数,基于线性回归的方法估计负载的能耗,但是当作业在多处理器环境中运行时,Mantis估计的误差较大。
针对以上问题,本文提出了一种基于负载性能特征的能耗估计方法,该方法能够准确估计MapReduce系统中作业运行时产生的能耗。
1 能耗估计方法
能耗估计的流程如图1所示,其中包括3个步骤:负载性能特征数据的离散化、基于粗糙集的性能属性的约简和基于最小平方支持向量机的能耗估计。以下是估计过程的具体描述。
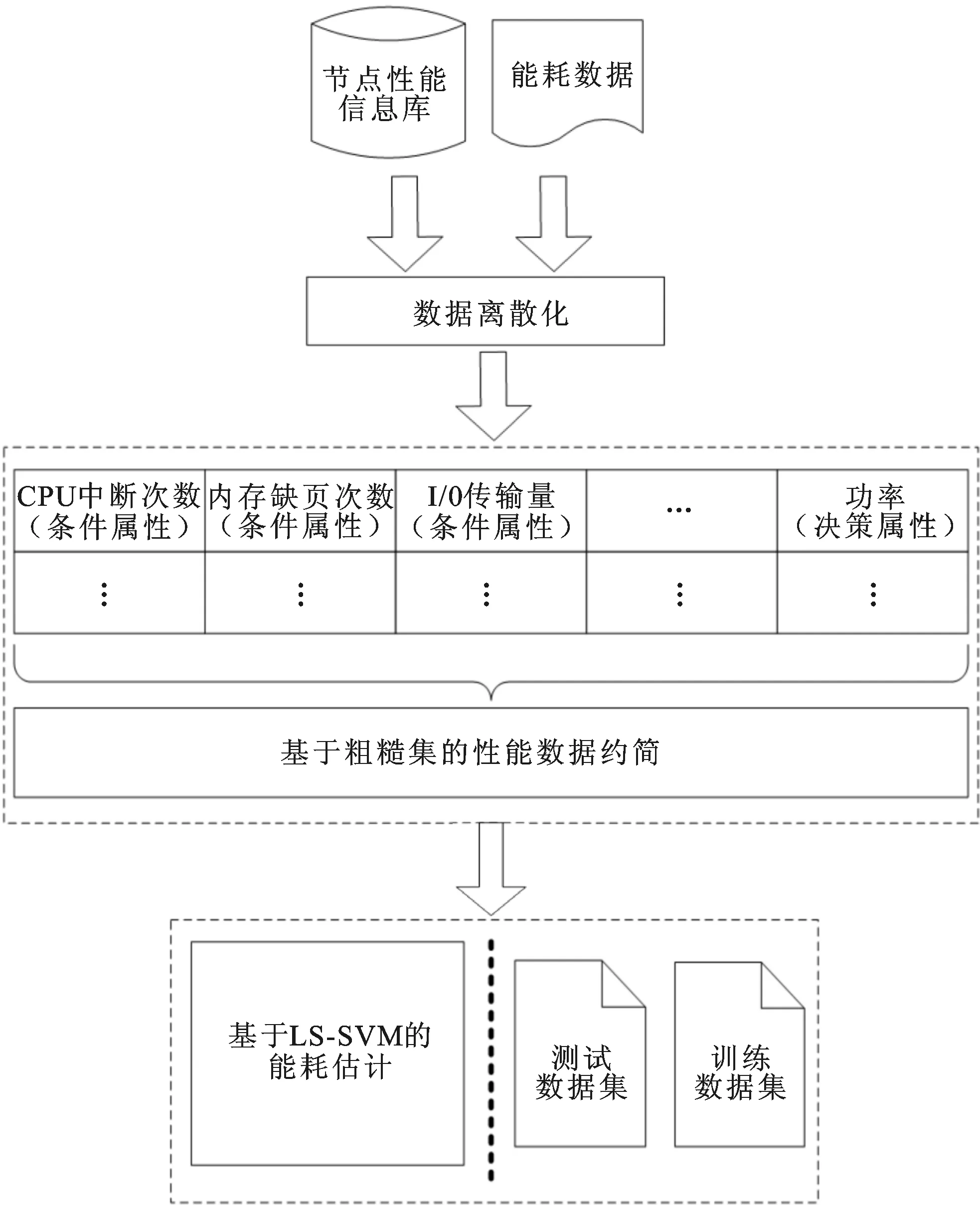
图1 能耗估计流程
1.1 性能特征数据离散化
在MapReduce作业执行过程中,从每个节点采集到的负载性能数据为数值型,首先采用粗糙集理论中的有监督的离散化方法[10-11]对性能数据离散化处理。设X=(x1,x2,x3,…,xn)为离散化处理之前的样本数据集,xi由m个负载运行时系统的性能事件组成,即xi=(xi1,xi2,xi3,…,xim),其中xij为任一性能事件。给定任一性能事件Ai,设阈值为T,X被T分割成两个子集合,则称T为X的一个断点。
设离散化处理之前的样本数据集X被断点划分为t个区间,X中的任一样本xi所对应的系统实时能耗值为P(xi),X中各个样本对应的不同的系统实时能耗值的个数为k,X所包含的总样本个数为N,第i个区间中各样本对应的能耗等于pi的样本总数为sij,X中各样本对应的能耗值为pi的样本总数为si,第j个划分区间中样本数为nj,则X相对于t的列联系数为
(1)
设离散化处理之前的样本数据集X被划分为t个区间,X中的样本xi所对应的系统实时能耗值为P(xi),X的t划分的列联系数为χ2(t),则X对t划分的评判标准为
A(t)=χ2(t)/t(k-1)
(2)
性能数据离散化的过程为求断点集T,依据T中各个断点对离散化处理之前的样本数据集X进行划分,在每次划分时使用A(t)作为评判,寻找最佳断点,依据最佳断点对每个属性的值域进行划分。
1.2 性能属性的约简
MapReduce负载的各性能特征属性对能耗的影响不同,为了去除性能特征属性中的冗余,基于粗糙集理论中的信息熵[12]对性能属性约简。设论域U,P和Q分别为U上的两个集合,X和Y分别为由P和Q确定的U的两个划分,其中X=(X1,X2,X3,…,Xn),Y=(Y1,Y2,Y3,…,Ym),从操作系统中采集到的负载性能属性的集合为C,负载运行时各个性能属性采集时间点对应的系统能耗值为D,X中的子集Xi中所包含的样本的总个数与U中所包含的总样本数的比值为P(Xi),Xi与Y的子集Yj的交集所包含的样本总数与U中总样本数的比值为P(Yj|Xi)。则U中各性能属性相对于负载运行时系统产生的能耗的条件信息熵可表示为
H(D|C)=
(3)
定义1 条件属性集C中的属性Ci相对于论域U的分类重要度表示从C中删除Ci前后,C相对于决策属性的信息熵的变化,则属性Ci的分类重要度为
M(Ci)=H(D|C-{Ci})-H(D|C)
(4)
对MapReduce系统中负载性能属性约简的过程如下:首先,依据离散化之后的条件属性集合C及能耗值所对应的决策属性集合D,依据式(3)计算D相对于C的信息熵H(D|C)及删除某个属性Ci之后的信息熵H(D|C-{Ci});其次,针对C中每个属性,依据式(4)计算其重要度;最后,依据C中各个属性的分类重要度大小,依次删除各个属性Ci,判断从C中删除Ci前后,集合C相对于集合D是否变化,如没有发生变化则保留属性Ci,否则删除属性Ci。
1.3 基于最小平方支持向量机的能耗估计模型
针对约简后的性能属性,采用最小平方支持向量机理论[13-14]建立MapReduce系统中负载能耗的估计模型。
设I为约简之后的负载性能属性,I=(A1,A2,A3,…,Am),Ai为负载性能属性集合中第i个属性的特征值,则基于最小平方支持向量机的估计模型可表示为
(5)
式中:K(I,Ii)为径向基核函数,可表示为
K(I,Ii)=exp(-‖I-Ii‖2/ρ2)
(6)
式中:ρ为径向基核函数参数。
能耗估计方法包括以下步骤:先依据约简后的性能属性构建数据集I,再将数据集I切分为训练样本集与测试样本集,采用训练样本集对估计模型进行训练,构建能耗估计模型。
基于最小平方支持向量机的能耗估计算法(MPower)表示如下。
算法1 MPower算法
输入 MapReduce系统中负载性能特征属性X与系统产生的能耗值的集合D,能耗值离散化区间数k,误差量的最小值amin和最大值amax,惩罚因子的最小值amin和最大值amax
输出 能耗估计模型P
/*决策属性D的离散化*/
D’=disConAtt(D)
/*负载性能特征属性X的离散化*/
for each attributeXi∈Xdo
xm←max(Xi)
xo←min(Xi)
Bi←initialBoundary(Xi,xm,xo)
for eachbj∈BIdo
calculate the statisticA(bj) according to
equation (2)
BOi←findBestBoundary(A(bj))
end for
BOUND←BOi
end for
C’=disDecAtt(C,BOUND)
/*负载性能特征属性约简*/
calculate the Information Entropy of conditional attributeH(D’|C’) according to equation (3)
for each attributeCi’∈C’ do
calculate the importance of conditional attributeH(D’|C’-{Ci’}) according to equation (3)
Q←H(D’|C’-{Ci’})
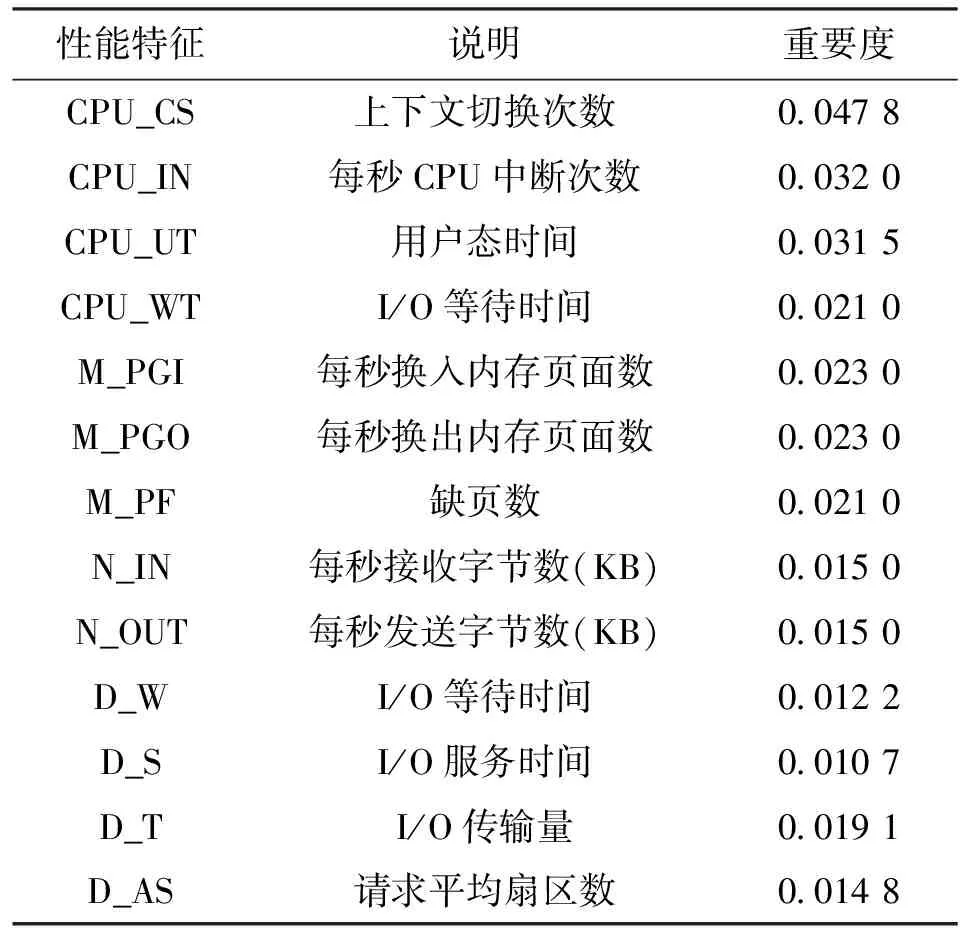
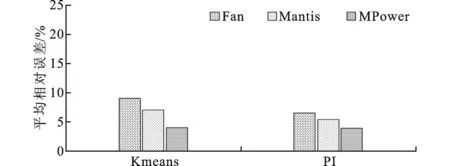
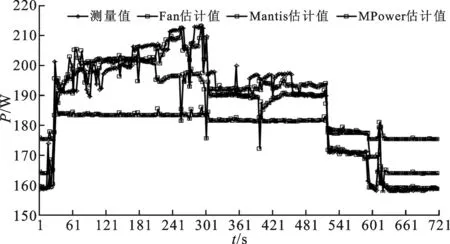
Ascending(Q)
end for
j=0;
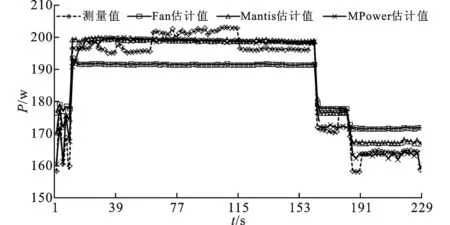
I←C’
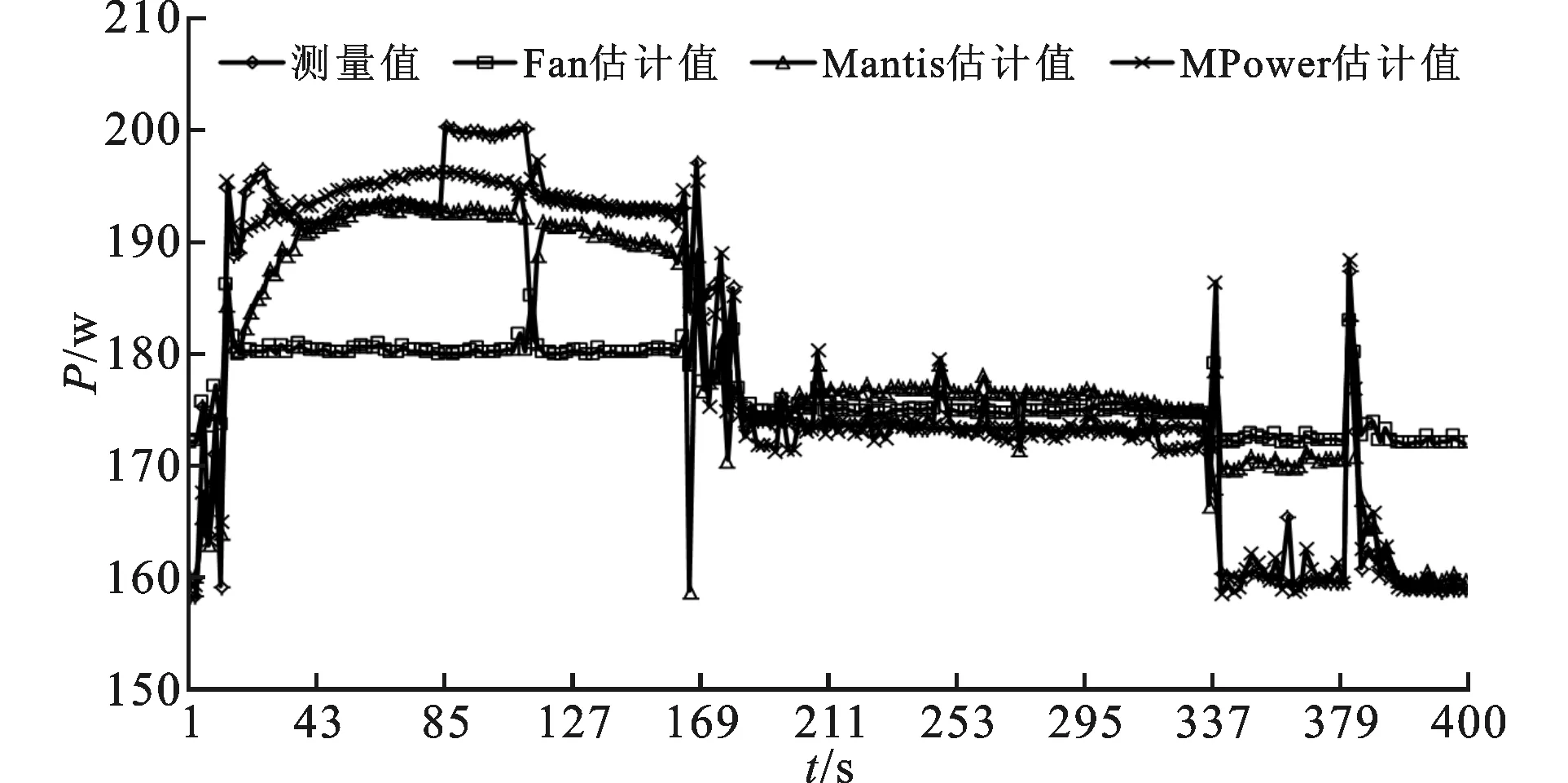
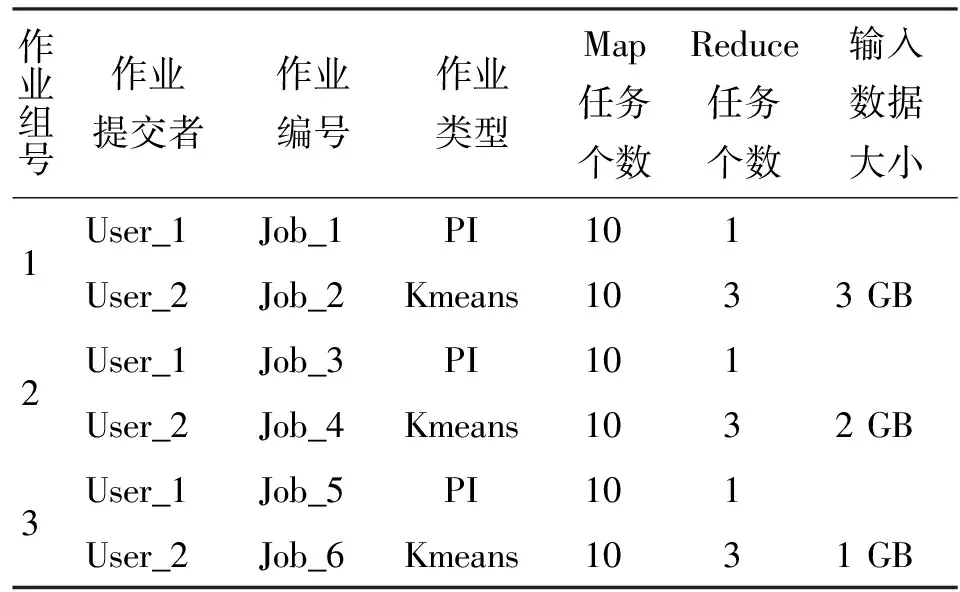
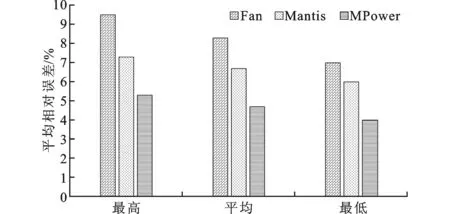
while(j ifH(D’|C’)=H(D’|I-{Qj}) do I←I-{Qj} end if end while /*基于最小平方支持向量机的能耗估计*/ [Itrain,Itest]←divide(I) fora∈[amin,amax] andγ∈[γmin,γmax] do [abest,γbest]←optimization(a,γ,Itrain) end for 本节使用普度大学发布的测试用例[15]验证能耗估计方法的有效性,其中包括WordCount、Sort、Pi、RankedInvertedIndex、RandomWriter和TeraGen等。这些测试用例分别代表I/O密集型、CPU密集型和混合型3种MapReduce负载类型。 实验的硬件平台为3台服务器与1台PC机构成的YARN集群。其中每台服务器的CPU为Intel(R) Xeon(R) E5-2420,内存大小为16 GB,硬盘为SATA接口。PC机的CPU为Intel(R) Core(TM) Q6000 @ 2.40 GHz,内存大小为2 GB,硬盘为IDE接口,存储容量大小为150 GB。能耗测试仪器为Watts’up,其额定电压为250 V,额定电流为15 A。软件采用的是Apache发布的YARN平台,版本号为2.0。 2.1 数据集 本文基于PerfMon2实现了性能属性采集器PProfile。实验中分别向YARN集群提交不同类型的作业,并在作业执行过程中对性能特征数据进行采集,采集间隔为1 s,每次采集40个性能属性的特征值。同时,读取采样频率间隔内系统的能耗值,每次采集到的性能数据和能耗值构成一个样本数据,最终构成估计模型的样本数据集。 2.2 结果分析 2.2.1 负载性能特征属性的约简 针对浮点型的能耗值,使用等频离散化方法[10]执行离散化操作,属性重要度阈值设为0.01,得到如表1所示的重要度大于0.01的性能特征及重要度。 如表1所示,YARN集群系统中负载的能耗与工作节点的各个组成部件均有关联,其中CPU对应的性能特征属性的重要度最大,是耗费电能最大的部件。内存所耗费的电能来源于内存的读写,评判内存读写能力的重要指标为每秒钟内存缺页个数和换入换出内存个数,这两个性能数据均在表1中有所体现。 表1 性能特征属性约简结果 2.2.2 能耗估计方法的有效性验证 为了验证MPower算法的估计准确度,本小节引入估计相对误差。设Pi为MPower算法对负载能耗的估计值,Qi为测量得到的负载能耗值,则MPower算法的估计相对误差可表示为 E=|Pi-Qi|/Qi (7) (1)单作业环境。分别向YARN集群提交3个Kmeans作业和3个PI作业,分别采用MPower、Mantis[9]与Fan[7]估计系统能耗,图2、图3为3种方法估计结果的比较。 如图2、图3所示,3种方法均可较为准确地估计负载产生的能耗。对于作业PI,3种方法得到了相似的估计结果,这是由于作业PI运行过程中系统产生的能耗主要来自于CPU,而3种模型中均考虑了CPU的性能特征对能耗的影响。但是,Mantis与Fan方法并没有考虑网络I/O对能耗的影响,而这两个影响因素均被MPower方法所考虑,因此MPower算法的估计准确度较高。对于作业Kmeans,MPower的估计准确度明显优于Mantis与Fan方法,这也是由于MPower方法充分考虑了工作节点内部主要组成部件对能耗的影响,而Fan方法仅考虑了CPU对负载能耗的影响,Mantis方法仅考虑了磁盘及CPU对负载能耗的影响。 (a)PI (b)Kmeans图2 单作业环境中负载能耗估计 图3 单作业环境中不同估计模型平均相对误差 (2)多作业环境。在多作业环境中,每种类型的作业拥有不同的特征,因此对集群系统资源的使用情况也不同。两个用户分别向YARN集群提交两种类型的作业PI和Kmeans,如表2所示。比较MPower、Mantis和Fan 3种方法分别在最好、最坏及平均情况下的平均相对误差。图4、图5描述了实验的结果,可以看出MPower方法较另外两种方法获得了较高的估计准确率。这主要是因为MPower方法中考虑了作业运行时工作节点中主要功能部件产生的能耗,而Mantis及Fan方法仅考虑了部分功能部件耗费的电能。此外,对比图2和图4,单作业或多作业环境中负载产生的能耗与操作系统中采集到的性能特征并非简单的线性相关,MPower方法中对性能特征进行属性约简,保留贡献较大的性能特征,以此建立非线性估计模型,对负载的能耗值进行估计,因此获得了较低的估计平均相对误差。 表2 作业类型及输入数据大小 图4 多作业负载能耗估计 图5 多作业环境中不同能耗估计方法的平均相对误差 总之,在多作业和单作业环境中,MPower估计准确度高于已有的Fan方法和Mantis方法。 2.2.3 能耗估计方法的应用场景 在YARN集群中,一种常用的节能机制是动态电压可扩展技术(DVFS)。为此,可将本文所提能耗估计方法与DFVS技术结合制定节能策略。如图2a所示,PI用例的能耗具有很强的规律性,在161 s之前PI用例处于Map阶段,能耗较高,但161 s之后PI用例进入Shuffle阶段,能耗明显降低,该规律已被MPower监控到,此时工作节点可以启动DVFS机制降低CPU主频,从而降低负载的能耗。在185 s之后PI用例进入Reduce阶段的后期,此时,从MPower估计结果可以看出工作节点的能耗进一步降低。此时,可启动DVFS技术降低CPU能耗从而达到节能目的。 此外,MPower可用来制定基于成本的调度策略。例如,结合MPower估计的能耗值及节点的性能特征,在保证服务质量的前提下,将Map或Reduce任务调度至当前能耗值较低的节点,而将部分节点休眠或关闭,从而提高YARN集群的能效。 本文针对YARN集群提出了一种负载能耗的估计方法,该方法基于负载的性能特征估计工作节点的能耗。针对Fan与Mantis等线性模型估计结果的平均相对误差高的问题,本文依据MapReduce作业运行时的系统性能特征,利用粗糙集理论中的属性约简方法来约简性能特征属性,并基于属性约简的结果来构建能耗估计模型。实验结果表明:本文所提方法估计结果的平均相对误差为4.5%,低于已有的Fan和Mantis方法。 [1] DEAN, JEFFREY, SANJAY G. MapReduce: simplified data processing on large clusters [J]. Communications of the ACM, 2008, 1(1): 107-113. [2] VAVILAPALLI V K, MURTHY A C, DOUGLAS C, et al. Apache Hadoop YARN: yet another resource negotiator [C]∥Proceedings of the 4th Annual Symposium on Cloud Computing. New York, USA: ACM, 2013: 1-16. [3] 谭一鸣, 曾国荪, 王伟. 随机任务在云计算平台中能耗的优化管理方法 [J]. 软件学报, 2012, 23(2): 266-278. TAN Yiming, ZENG Guosun, WANG Wei. Policy of energy optimal management for cloud computing platform with stochastic tasks [J]. Journal of Software, 2012, 23(2): 266-278. [4] LEVERICH, JACOB, CHRISTOS K. On the energy (in) efficiency of hadoop clusters [J]. ACM SIGOPS Operating Systems Review, 2010, 44(1): 61-65. [5] GE Rong, FENG Xizhou, WIRTZ T, et al. eTune: a power analysis framework for data-intensive computing [C]∥Proceedings of the 2012 41st International Conference on Parallel Processing Workshops. Piscataway, NJ, USA: IEEE, 2012: 254-261. [6] WIRTZ T, GE Rong. Improving Mapreduce energy efficiency for computation intensive workloads [C]∥Proceedings of the 2011 International Green Computing Conference and Workshops. Piscataway, NJ, USA: IEEE, 2011: 1-8. [7] FAN Xiaobo, WEBER W D, BARROSO L A. Power provisioning for a warehouse-sized computer [J]. ACM SIGARCH Computer Architecture News, 2007, 35(2): 13-23. [8] HEATH T, DINIZ B, CARRERA E V, et al. Energy conservation in heterogeneous server clusters [C]∥Proceedings of the 10th ACM Sigplan Symposium on Principles and Practice of Parallel Programming. New York, USA: ACM, 2005: 186-195. [9] RIVOIRE S, RANGANATHAN P, KOZYRAKIS C. A comparison of high-level full-system power models [J]. HotPower, 2008, 8: 1-5. [10]LI Bing, CHOW T W S, TANG Peng. Analyzing rough set based attribute reductions by extension rule [J]. Neurocomputing, 2014, 123: 185-196. [11]HAN Jiawei, KAMBER M, PEI Jian. Data mining: concepts and techniques [M]. San Francisco, CA, USA: Morgan Kaufmann, 2006: 63-70. [12]王国胤, 姚一豫, 于洪. 粗糙集理论与应用研究综述 [J]. 计算机学报, 2009, 32(7): 1229-1246. WANG Guoyin, YAO Yiyu, YU Hong. A survey on rough set theory and applications [J]. Journal of Computers, 2009, 32(7): 1209-1246. [13]CORTES C, VAPNIK V. Support vector machine [J]. Machine Learning, 1995, 20(3): 273-297. [14]SUYKENS J A K, VANDEWALLE J. Least squares support vector machine classifiers [J]. Neural Processing Letters, 1999, 9(3): 293-300. [15]AHMAD F, CHAKRADHAR S T, RAGHUNATHAN A, et al. Tarazu: optimizing Mapreduce on heterogeneous clusters [C]∥Proceedings of the 17th International Conference on Architectural Support for Programming Languages and Operating Systems. New York, USA: ACM, 2012: 61-74. [本刊相关文献链接] 袁通,刘志镜,刘慧,等.多核处理器中基于MapReduce的哈希划分优化.2014,48(11):97-102.[doi:10.7652/xjtuxb2014 11017] 史椸,耿晨,齐勇.一种具有容错机制的MapReduce模型研究与实现.2014,48(2):1-7.[doi:10.7652/xjtuxb201402001] 崔华力,钱德沛,张兴军,等.用于无线多跳网络视频流传输的优先级机会网络编码.2013,47(12):13-18.[doi:10.7652/xjtuxb201312003] 陈衡,钱德沛,伍卫国,等.传感器网络基于邻居信息量化的能量平衡路由.2012,46(4):1-6.[doi:10.7652/xjtuxb2012 04001] (编辑 武红江) A Power Estimation Method Based on Performance Features in MapReduce Environments FAN Yuanquan,WU Weiguo,XU Yunlong,GAO Yan (School of Electronics and Information Engineering, Xi’an Jiaotong University, Xi’an 710049, China) It is difficult to improve the energy efficiency of MapReduce clusters by matching active nodes to the needs of the workload since it is difficult to capture the features of energy consumption for cost-based scheduler for different types of workloads. A power estimation method based on performance features of workloads is proposed to solve the problem. The method estimates the power consumption by leveraging performance monitoring counters on components of worker nodes during MapReduce jobs execution. A machine learning method is used to improve the estimation accuracy. The performance monitoring counters of MapReduce system are collected to build a sample set, and then the rough set method is used to select the performance attributes that show strong impact on the energy consumption of workloads. A power estimation model based on the least square support vector machines is built from the attribute reduction results. Experimental results show that the energy estimation method accurately forecasts the power consumption of workloads in MapReduce systems. The relative error of accuracy for power prediction is 4% for only one running job and 4.5% for jobs sharing MapReduce clusters. power estimation; performance features; MapReduce 2014-05-26。 樊源泉(1982—),男,博士生;伍卫国(通信作者),男,教授,博士生导师。 国家自然科学基金资助项目(61202041,91330117);国家高技术研究发展计划资助项目(2011AA01A204,2012AA01A306)。 时间:2014-12-11 10.7652/xjtuxb201502003 TP333 A 0253-987X(2015)02-0014-06 网络出版地址:http:∥www.cnki.net/kcms/detail/61.1069.T.20141211.0849.002.html2 实验分析
3 结 论
猜你喜欢
昆钢科技(2022年2期)2022-07-08 06:36:14
当代水产(2021年10期)2022-01-12 06:20:28
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
建材发展导向(2021年23期)2021-03-08 01:05:38
成都信息工程大学学报(2019年2期)2019-08-28 10:00:46
华人时刊(2018年15期)2018-11-10 03:25:26
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
自动化学报(2018年2期)2018-04-12 05:46:01
成都信息工程大学学报(2017年1期)2017-07-21 14:14:11
数学学习与研究(2017年3期)2017-03-09 18:12:42
