
基于语料库的中国诗歌英译语言特征探析
2015-12-25 02:13:28高博
天津外国语大学学报 2015年4期
高 博
(南开大学 滨海学院,天津 300270)
一、理论背景
翻译是人类历史上一项古老的文化交往活动,它大大加强了不同地域、不同文化之间的了解与沟通。随着国际间交流的日益频繁以及翻译数量的逐渐增多,越来越多的学者试图从以往的翻译实践中探索出翻译的规律和评价准则。Nida的功能对等及严复的“信、达、雅”等翻译理论都对以往的翻译活动进行了总结和归纳,旨在用于更好地指导未来的翻译实践。但这些归纳式的翻译理论大多具有很强的规约性,它们将忠实作为衡量译本的主要标准,强调原文与译文之间的等值。随着翻译研究视域的不断拓宽,规范性的方法再也难以对某些翻译现象作出合理的解释(余国良,2008:84)。一些翻译理论家开始将目光转移到描写翻译理论上来。Holmes是将翻译学科独立化的学者,他提出了翻译研究中纯理论研究的两大分支:描写翻译研究和翻译理论(Gentzler,2004:94)。Toury 继承了Holmes的思想并进一步发展了描写翻译理论,主张用描写式的翻译理论代替规约式的翻译理论,即将翻译研究由以原文文本为核心的研究方法引向以译文文本为核心的研究方法(ibid.:125)。正是在这样的理论背景下,基于语料库的翻译语言特征研究应运而生。
作为语料库翻译学的开创者,英国曼彻斯特大学的Mona Baker于20世纪90年代创建了世界上第一个翻译英语语料库(Translation English Corpus,简称TEC)。通过对比译自印欧语系的翻译英语与非翻译英语,她提出了翻译语言中所具有的普遍特征(universal features of translation),又称翻译共性。所谓翻译共性,指的是翻译文本而不是源语中出现的典型语言特征,并且这些特征不是特定语言系统干扰的结果(Baker,1993),其中以简化、显化、净化、范化和平整化等特征研究最广为熟知。
近些年来,国外的语料库翻译语言特征研究主要集中在“从相近的欧洲语言翻译过来的英语译文”(肖忠华,2012:4),而我国学者对以汉语为源语的英语译本也作了大量研究。但这些研究大多是以某个单一个案为基础进行的讨论,如《红楼梦》英译本,研究结果缺乏一定的普遍性。目前的翻译共性研究还仅限于文学文体,以小说和散文体裁为主,针对诗歌体裁的共性研究尚属罕见。高博和陈建生(2011)曾以许渊冲的《诗经》英译本为案例,探讨了古典诗词英译文中的翻译共性效度。但该研究语料规模相对较小,且缺乏现代诗歌译本的佐证,研究结果不足以描述中国诗歌英译语言的总体特征。本文拟利用语料库语言学相关检索软件,以诗歌体裁的英语译本为研究对象,通过对比英语原创诗歌与中国古典和现代诗歌译本在词汇、句法及语篇层面上的差异,试图揭示中国诗歌英语译文的语言特征。
二、研究方法
本研究通过自建可比语料库进行实证性研究。该语料库主要包括两个部分:英语翻译诗歌语料库(以下称为译文库)和英语原创诗歌语料库(以下称为原创库)。译文库又包括两个子库,即古典诗歌和现代诗歌①。

表1 中国诗歌译本可比语料库的描述
原创库由1 100首英美原创诗歌组成,作者 包 括 Keats,Byron,Whitman及 Frost等英美著名诗人。古典诗歌译文库包括 《诗经》及《唐诗三百首》的英文译本,译者分别为James Legge与Witter Bynner。现代诗歌译文库中的语料均译自于中国现当代诗人的作品,如顾城、张爱玲、徐志摩及北岛。需要指出的是,译文库中所有译文均出自西方译者之手。本研究使用TreeTagger词性赋码器进行词性赋码,使用的语料库检索软件是WordSmith 4.0。
三、中国诗歌英译语言特征考察
1 词汇层面
本文通过对比两个语料库的形符类符比、词汇密度及高频词的使用情况,析出中国诗歌英译语言在词汇层面上的特征。
1.1 形符类符比
形符类符比一般用来反映文本词汇使用的丰富程度,其比值越高,说明该文本使用的词语越丰富,变化性越大(Baker,2000)。由于本研究中两个语料库的规模不同,采用标准化形符类符比(STTR)作为考察依据。

表2 两个语料库的形符数、类符数和标准化形符类符比
由表2可知,译文库与原创库的STTR存在显著性差异(χ2=189.14,p<0.01),这说明在用词上英译诗歌比原创诗歌更加灵活多变。这个结论与Laviosa(1998)提出的翻译文本词汇量化模式②相左。笔者认为,这个结果与汉语诗歌的语言特点及译者的翻译策略有着密切关系。汉语诗歌以短小精炼著称,在简短的语言中蕴含着大量的典故和隐喻。因此,为了保证译文能够顺利地被西方读者接受,并且最大程度地保持译文的异域特色,西方译者在翻译过程中频繁采用了异化加注释的翻译策略。例如:
(1)去时里正与裹头。(杜甫《兵车行》)
The elder wrap up their young heads when they went away.
Note: The phrase “wrap up their young heads(guotou)” is actually a rite of doing up one’s hair like an adult in ancient China.
(2)当日后羿的一箭,劫后余生。(秋梦《演出的太阳》)
Shot by Hou-Yi that day, a calamity survived.
Note: Hou-Yi is the name of a famous archer in Chinese legendary.
通过以上两例可以看出,译者对原文中的文化负载词(culture-loaded words)均采用了异化的翻译策略。而这些异化过来的词汇(guotou,Hou-Yi)几乎不会出现在英语原创诗歌之中,这就在一定程度上拓宽了译者的用词范围,提高了译文用词的多样性。加注的翻译方法增加了译文的长度,对提高文本用词的丰富程度也起到了促进作用。
1.2 词汇密度
词汇密度指的是在特定语料库中实词在总词数中所占的比例。词汇密度越大,说明该文本实词使用频率越高,信息量越大,反之则信息量越小(Baker,1995)。胡壮麟(2002)将英语中具有稳定语义的名词、动词、形容词和副词归为实词类。本文采用胡壮麟的分类标准,并根据Ure (1971)提出的计算词汇密度的公式,即词汇密度=实词数/总词数×100%,对两个语料库进行了统计,统计结果如图1。
图1数据表明,译文库的词汇密度高于原创库,且两者存在显著性差异(χ2=197.33,p<0.01)。这意味着相对于英语原创诗歌,英语翻译诗歌的实词使用比例更高,信息负载量更大。此结论有悖于Laviosa对英语译文实词偏低的假设。为了能够探明该结果产生的原因,笔者又分别对比了古典诗歌译文和现代诗歌译文与原创诗歌在词汇密度上的差异(见表3)。
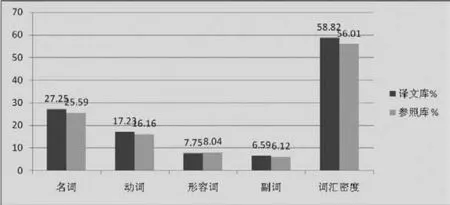
图1 两个语料库的词汇密度统计
由表3数据可见,原创库与现代诗歌译文库的词汇密度差别不大,古典诗歌译文库的词汇密度明显高于原创库(χ2=427.83,p<0.000 1)。通过以上对比可以看出,造成译文库的词汇密度整体高于原创库的原因与古典诗歌译本词汇的使用情况呈高相关性。对古典诗歌译文库中的具体词类进行进一步分析发现在名词和动词的使用频率上古典诗歌译文库要高于原创库,其中名词的使用差异最为明显(χ2=352.18,p<0.000 1),而在形容词和副词的使用频率上两者无显著性差异。导致这个结果的原因主要在于中国古典诗歌独特的创作手法和译者所用的异化翻译策略。
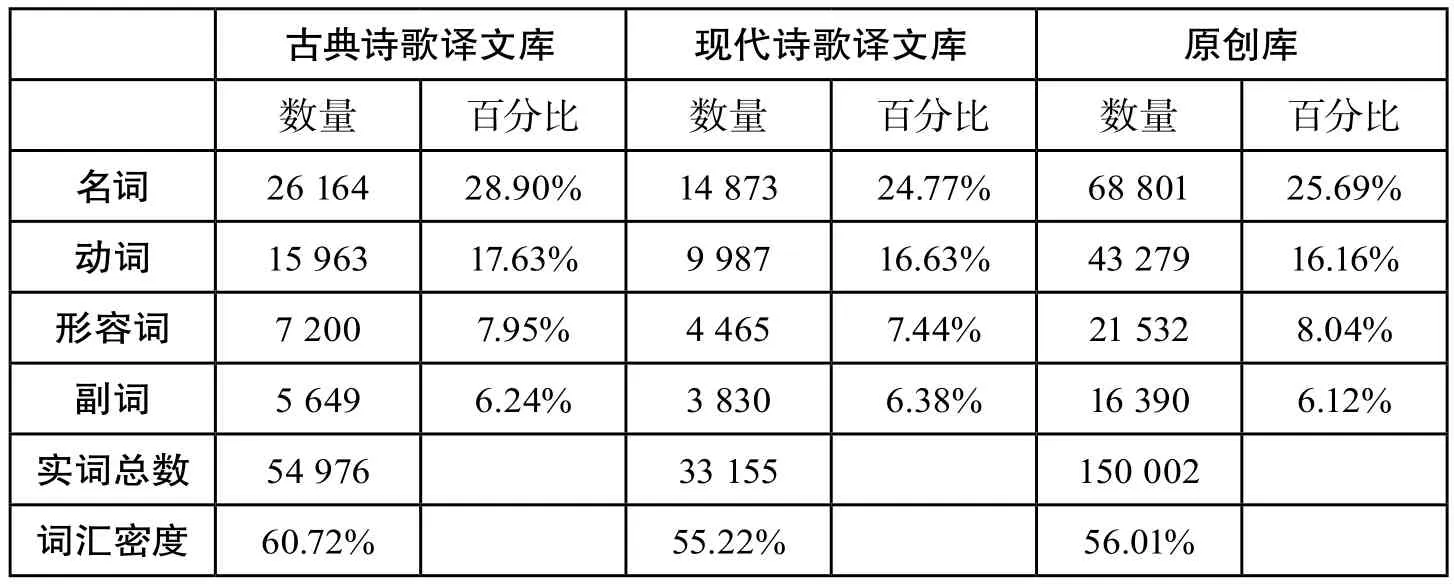
表3 古典诗歌译文库、现代诗歌译文库和原创库词汇密度对比
中国古诗创作的基本单位是意象,并依靠意象的不断组合来传达作者的思想感情(张敏,2009)。意象组合中最重要的当属意象并置,所谓意象并置,指的是“诗歌中的意象名词或词组的排列,完全是靠意合手法来表现,而不是靠关联词、虚词或是‘规范’的句法手段来连接实现这样的现象”(同上)。这种表现手法在汉语中称之为“列锦”(程红,2013)。在中国古典诗歌中,“列锦”的使用比比皆是。例如:
(3)浮云游子意,落日故人情。(李白《送友人》)
The mind of traveling man, floating wide cloud. His feelings of parting old friend, the setting sun.
例(3)原文由六个意象名词并置而成,中间没有知性的参与和逻辑的链接。译者采用了异化的翻译策略,继承了原文的语言特点,进而扩大了译文的文化视野。译文除了使用必要的英语介词of之外,其余部分模仿原文结构,均使用名词或名词性词组进行翻译。这种翻译方法导致了中国古典诗歌译文库中名词数量大量增加,进而提高了词汇密度。
1.3 高频词的使用
Laviosa(1998)曾对英语叙事性翻译文本进行了考察,得出翻译文本的高频词相对于低频词比例偏高的结论。这个结论是否符合以诗歌为体裁的英语译本呢?表4分别对两个语料库前30位、40位和50位的高频词目进行了统计。
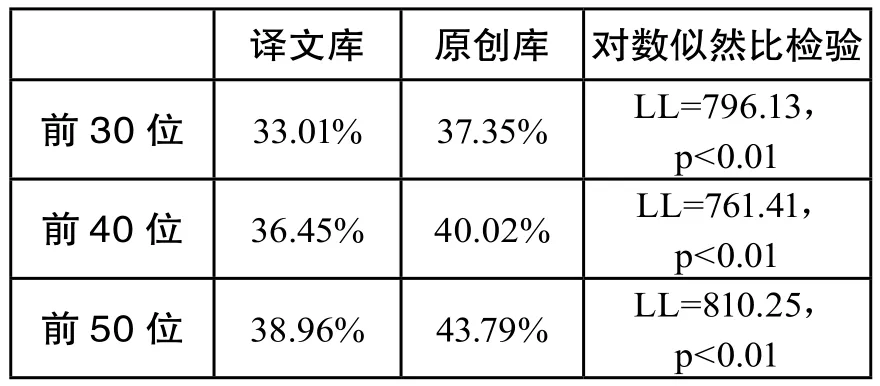
表4 两个语料库前30位、前40位和前50位的高频词统计
通过表4可以看出,译文库中高频词的使用频率低于原创库。这个结论不同于Laviosa的调查结果,但从另一个角度佐证了翻译诗歌用词丰富程度高于原创诗歌的结论。这个结果也说明了西方译者在汉诗翻译过程中并非反复使用耳熟能详的词汇谋篇布局,而是选用更加多样化的词汇,以期保证译文的异域文化色彩,增强读者的阅读体验。
2 句法层面
本研究采用以下两个假设对中国诗歌英译语言进行句法层面上的考察:(1)Laviosa(2002)提出的翻译文本的句子平均长度比非翻译文本句子平均长度短;(2)Olohan(2003)提出的非翻译文本的缩略成分使用比例高于翻译文本。
2.1 句子数量与句长信息
平均句长和句长标准差是指文本中句子的长度以及句式的变化程度。一般情况下,平均句长越长,文本句法结构越复杂;句长标准差越高,句式变化程度越大。

表5 两个语料库的句子数量及句长信息
由表5可知,原创诗歌比翻译诗歌句长更长,句式更加复杂。该结论虽然与假设 (1)相符,但这个结果的出现并非单纯由翻译语言自身显化所致,而与汉英诗歌的结构差异也有着密不可分的关系。“汉语诗歌精炼(concise),言简意赅,有时意在言外,内容重于形式,是一种文学语言;英语诗歌精确(precise),内容与形式基本统一,表层结构与深层结构矛盾较小,是一种科学的语言。”(姚红,2012)这种差异性体现在汉语诗歌句法简洁,省略较多,有些成分甚至不够明确;而英语诗歌则句法繁复,不惜使用长句以清晰地表达诗人的情感。汉诗的用句特点在译文中得到了充分的体现,与英语原创诗歌形成了强烈的对比。例如:
(4)床前明月光,疑是地上霜。举头望明月,低头思故乡。(李白《静夜思》)
One night thoughts, moonlight before my bed. Could it be frost? Head up, I watch the moon; Head down, I think of home.
(5)Although she feeds me bread of bitterness and sinks into my throat her tiger’s tooth, stealing my breath of life, I will confess I love this cultured hell that test my youth!(Clande Mckay,America)
以上两诗都抒发了诗人对故乡的怀念之情。例(4)译文受汉诗结构影响,用句较短,意合程度高,语义联系依靠读者根据语境进行推测;例(5)为原创诗歌,用句较长,句式复杂,形合程度高,语义清晰直白,一目了然。为了能够进一步探索翻译诗歌与原创诗歌在句法使用上的差异,笔者对两个语料库中复杂句的使用情况进行了统计③。
通过表6的统计结果可以看出,译文库的衔接词使用比例明显小于原创库(χ2=513.38,p<0.000 1)。这说明与原创诗歌相比,翻译诗歌更加倾向于使用句长较短的简单句。这个结果与表5所得结论如出一辙。周求知(1994)曾经指出:“英语诗歌语言经常呈现出跳跃、闪现、凝聚的特征并包含丰富的涵义和大量的信息。”由此可以推断,英美诗歌大家笔下的经典之作通常会更富创造性,传达出更多的感情和内涵,他们会更加频繁地使用比较复杂的长句。而翻译诗歌更多地注重与原文的等值,其创造性和情感变化势必要低于原创诗歌,这也在一定程度上降低了翻译诗歌使用长句的频率。
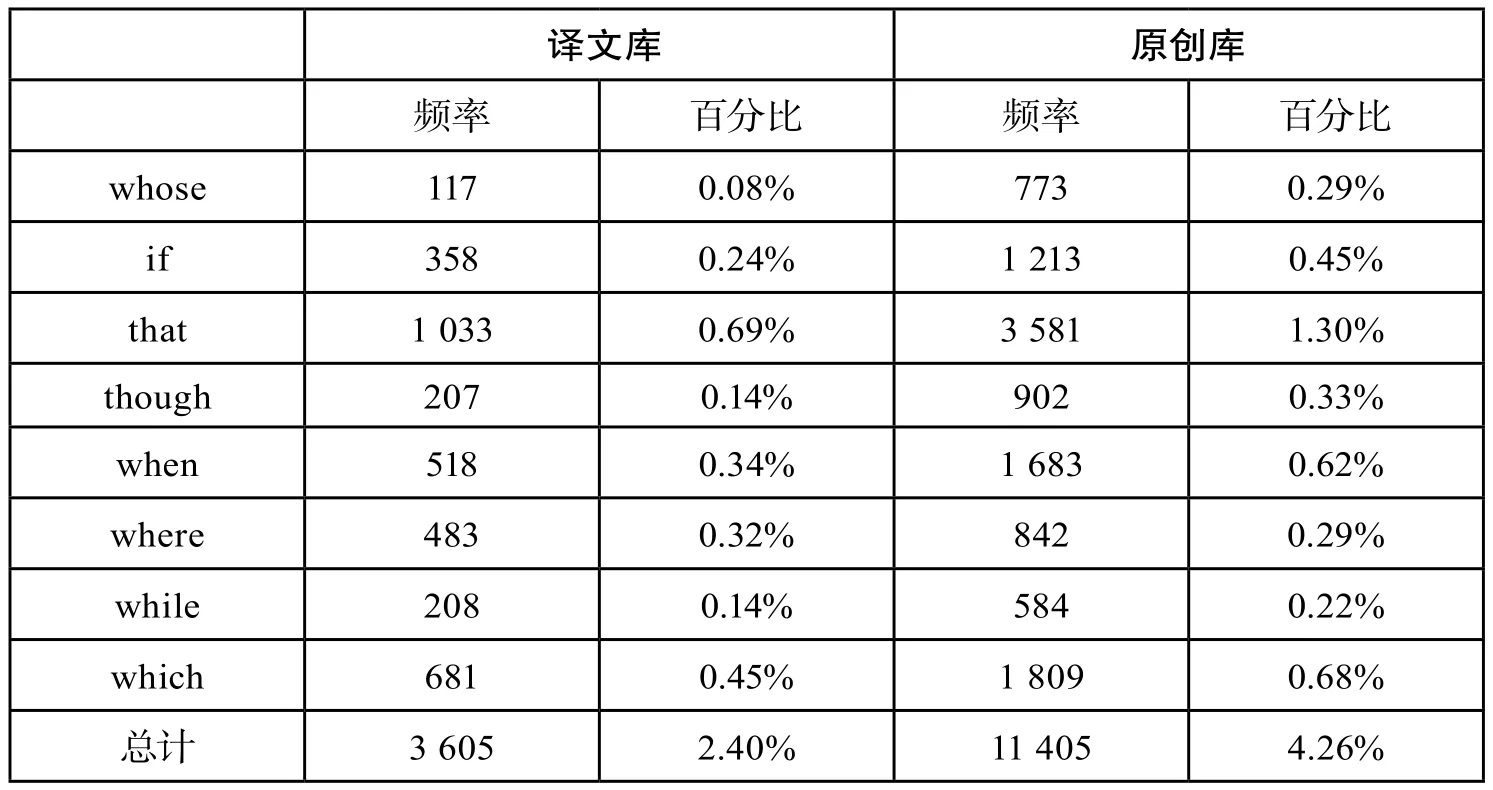
表6 两个语料库复杂句衔接成分统计
2.2 缩略成分的使用
通过对比翻译英语语料库(TEC)和英国国家语料库(BNC),Olohan(2003)发现翻译英语缩略成分的使用比例小于非翻译英语,这个结论可以反映出翻译文本的句法显化情况。缩略成分使用比例越小,文本风格越严肃,正式程度越高(Olohan,2004:100-101)。为了验证该结论对于诗歌译本是否有效,笔者对两个语料库缩略成分的使用情况进行了统计(见表 7)。
表7的统计结果显示,译文库与原创库缩略成分的使用情况具有显著性差异(χ2=239.23,p<0.01)。这个结果说明相较于原创诗歌,翻译诗歌的正式程度更高,该结论符合Olohan提出的假设。笔者对两个语料库进行进一步检索发现,英语原创诗歌缩略成分的使用范围更加广泛,原创库中出现的 ’en,’mong,’tis,’thro 和 t’was等省略形式均未出现在译文库中。这个结果再次印证了翻译诗歌在句法层面上的显化倾向。
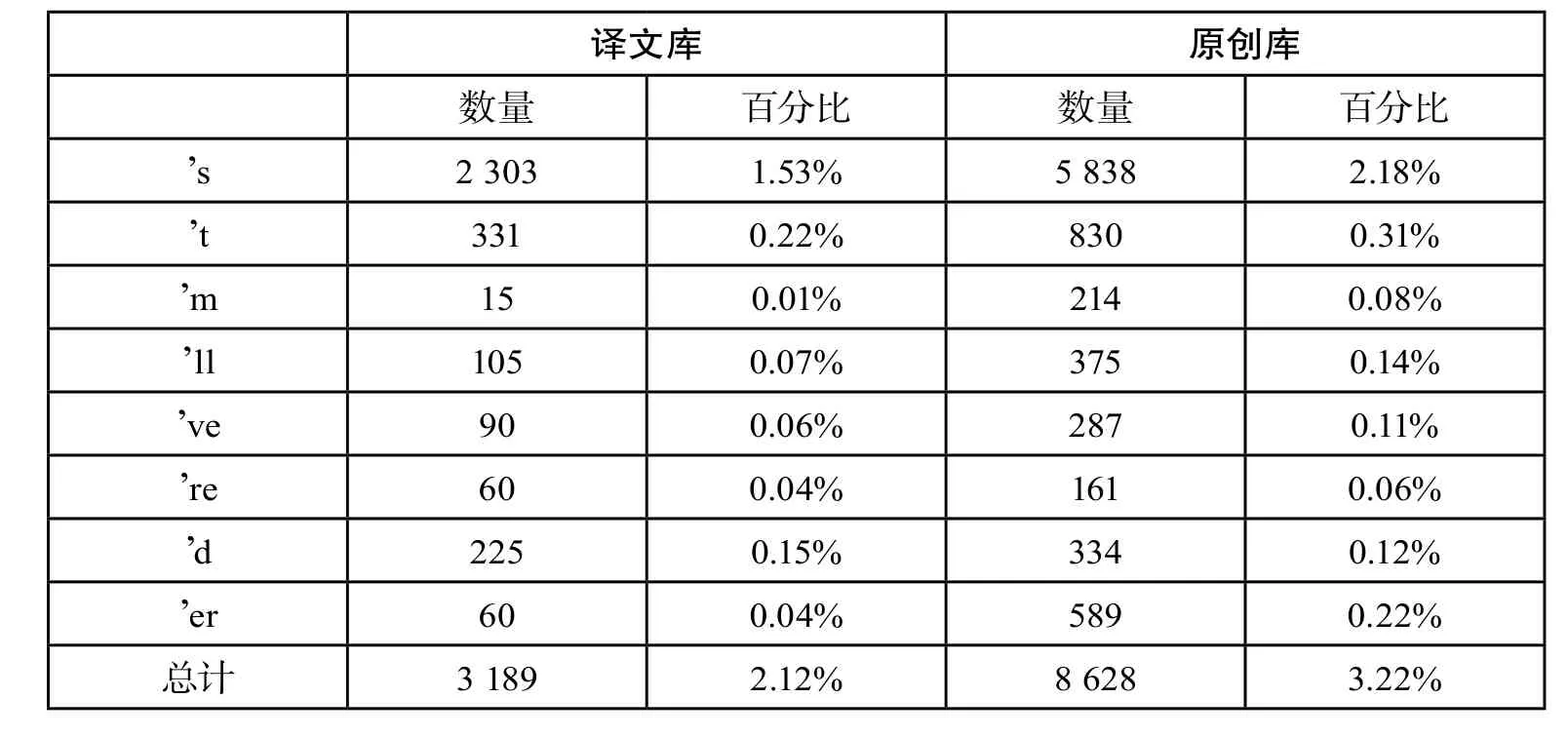
表7 两个语料库缩略成分使用
3 语篇层面
本文通过对比分析两个语料库的语篇可读性和语言变异情况,揭示翻译诗歌在语篇层面上的特征。
3.1 语篇可读性
语篇可读性(text readability)可以用来从总体上衡量文本的难易程度。决定可读性的重要因素一般包括句子长度及用词难易度。目前较为权威的两种可读性信息统计方法为Fog Index和The Automated Readability Index计算公式,它们适合于测试任何类型文本的可读性。Fog Index计算公式为Fog Index=0.4(L+H),其中L指的是平均每句包含的单词数量,H指的是平均每百个单词所含的多音节单词数量。Fog Index测量的是看懂阅读内容所需要的受教育年限,指数越低,阅读内容越容易,6代表容易,20代表很难。The Automated Readability Index计算公式为The Automated Readability Index=4.71×(c÷w)+0.5×(w÷s)- 21.43, 其中c表示字母数量,w代表单词数,s代表文本中的句子数。The Automated Readability Index指数越低说明文本越为简单。
表8数据显示原创诗歌总体阅读难度高于翻译诗歌,翻译诗歌在语篇层面上存在简化趋势。笔者发现造成译文库简化的主要原因在于古典诗歌译文的语篇特征。古典诗歌译文的语篇难度远低于原创诗歌,而现代诗歌译文语篇难度高于原创诗歌。这个结论进一步证实了源语特征对翻译语言具有不可忽视的影响,即使同为诗歌体裁的不同表现形式(古体诗和现代诗),译文也有可能呈现出不同的语言特征。
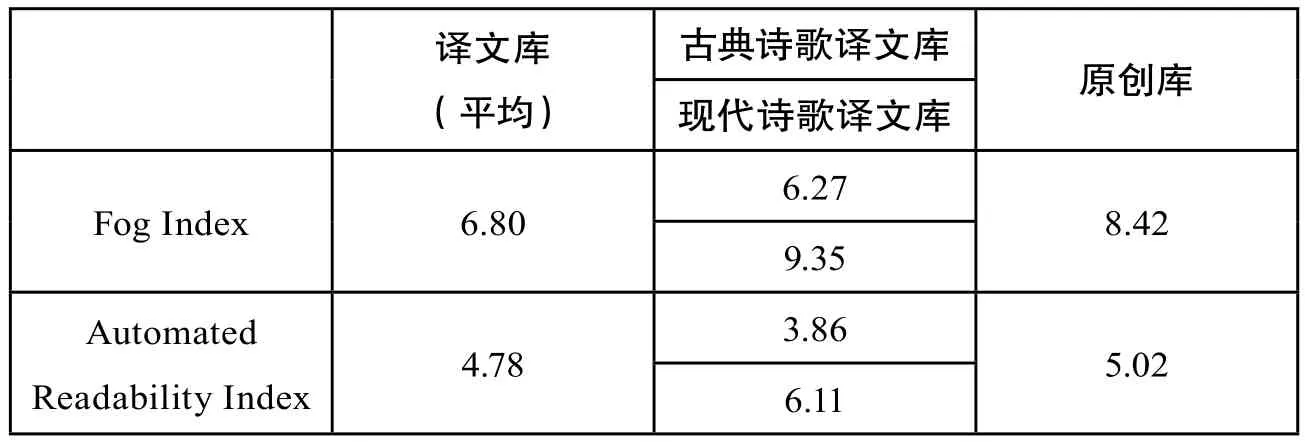
表8 两个语料库的语篇可读性指数
3.2 语言变异情况
诗歌是多种复杂的感情和心境在语言文字上的投射,不同于普通语言,诗歌语言的主要特点是以语法结构来明确事物之间的关系(周求知,1994)。为了追求“语不惊人死不休”的诗歌效果,诗人经常违背常规,大胆颠覆语法规则,产生语言变异(language deviation)。这种变异现象在普通语言使用中会被视为内容荒谬,逻辑混乱,而在诗歌语言中却可成为特殊而有效的表现手段。例如:
(6)Anyone lived in a pretty how town,
(with up so floating many bells down)
spring summer autumn winter,
He sang his didn’t he danced his did.(AnyoneLived in a Pretty How Town,E. E. Cummings)
(7)Our’ heart’s charity’s hearth’s fire, our thought’s chivalry’s throng’s Lord.(The Wreck of the Deutschland,G. M. Hopkins)
上面两例大胆打破了传统的英语语法规范,更好地传达出诗人的情感。笔者对译文库进行查询,没有发现原创英诗中常见的语言变异现象。从整体上看,翻译诗歌语言具有明显的范化倾向。也就是说,翻译诗歌在语言使用上更加贴近语法规范,但与原创诗歌存在一定差距。
四、结语
本研究通过自建可比语料库对诗歌的英语翻译语言特征进行了对比分析。分析结果表明,在词汇层面,翻译诗歌没有呈现出明显的简化特征,与原创诗歌相比用词更加丰富,更加华丽,这个结论与Laviosa对翻译小说进行的语言特征描述不符;在句法层面,翻译诗歌在平均句长、句式复杂程度以及缩略语的使用频率方面均低于原创诗歌,句法使用上存在显化倾向;在语篇层面,翻译诗歌在整体上体现出明显的范化趋势,与原创诗歌差别甚大。以上结果的产生不仅取决于翻译语言自身的语内扩张,同时与诗歌体裁也有着密切关系。
注释:
① 笔者未对原创语料库进行分类,因为原创库所选诗歌均由现代英语写成,译文库中两个子库的语料也均用现代英语翻译而成,两者具有可比性。
②Laviosa(1998)提出了英语翻译文本中四个词语使用模式:(1)翻译文本中的实义词相对于语法功能词的比例较低;(2)翻译文本中的高频词相对于低频词的比例较高;(3)翻译语料库的词表表头覆盖语料库范围较大(即最常用词语重复使用较为频繁);(4)翻译文本的词表表头包含的词目较少。
③ 由于衔接成分比较复杂,并且在其分类上也存在着一定的分歧,本研究只对分歧较小且具有统计学意义的衔接成分进行了检索分析。
[1] Baker, M. Corpora in Translation Studies: An Overview and Some Suggestions for Future Research[J]. Target, 1995, (7): 223-243.
[2] Baker, M. Corpora in Translation Studies: Corpus Linguistics and Translation Studies: Implications and Applications[A].In M.Baker, G. Francis & E. Tognini-Bonelli (eds.) Text and Technology: In Honour of John Sinclair[C]. Amsterdam: John Benjamins Publishing Company, 1993.
[3] Baker, M. Towards a Methodology for Investigating the Style of a Literary Translator[J]. Target, 2000, (2): 241-266.
[4] Gentzler, E. Contemporary Translation Theories[M]. Shanghai: Shanghai Foreign Language Education Press, 2004.
[5] Hu Zhuanglin. Linguistics: An Advanced Course Book[M]. Beijing: Beijing University Press, 2002.
[6] Laviosa, S. Core Patterns of Lexical Uses in a Comparable Corpus of English Narrative Prose[J]. Meta, 1998, (4): 43-47.
[7] Laviosa, S. Corpus-based Translation Studies: Theory, Findings, Application[M]. Amsterdam: Rodopi, 2002.
[8] Olohan, M. How Frequent Are the Contraction? A Study of Contracted Forms in the Translational English Corpus[J]. Target,2003, (15): 59-89.
[9] Olohan, M. Introducing Corpora in Translation Studies[M]. London: Routledge, 2004.
[10] Ure, J. Lexical Density and Register Differentiation[A]. In G. Perren & J. Trim(eds.) Applications of Linguistics: Selected Papers of Second International Congress of Applied Linguistics[C]. Cambridge: Cambridge University Press, 1971.
[11] 程红.古诗词中列锦格的构成探究[J].沈阳师范大学学报, 2013, (2): 158-160.
[12] 高博, 陈建生.基于语料库的中国古典诗词译本中的翻译共性研究——以 《诗经》英译本为例[J].外国语言文学, 2011, (4):257-262.
[13] 肖忠华.英汉翻译中的汉语译文语料库研究[M].上海:上海交通大学出版社, 2012.
[14] 姚红.从诗歌翻译的角度浅谈汉语和英语之异同[J].三门峡职业技术学院学报, 2012, (3): 75-78.
[15] 余国良.语料库语言学的研究与应用[M].成都:四川大学出版社, 2008.
[16] 张敏.古诗词中并置意象的英译研究[J].考试周刊, 2009, (8): 42-44.
[17] 周求知.英语诗歌的语言特点[J].外语与外语教学, 1994, (4): 12-16.
猜你喜欢
初中生学习指导·中考版(2021年2期)2021-09-10 07:22:44
猪业科学(2021年3期)2021-05-21 02:05:36
幽默大师(2020年10期)2020-11-10 09:07:22
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
中华诗词(2019年1期)2019-11-14 23:33:56
猪业科学(2018年4期)2018-05-19 02:04:31
——记我的原创感悟
教学考试(高考数学)(2017年6期)2017-12-14 07:39:43
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
试题与研究·高考英语(2016年3期)2016-12-23 02:05:40
语言与翻译(2015年4期)2015-07-18 11:07:45
