
基于CBR的测试用例复用方法研究
2015-12-25 12:23许媛媛
软件 2015年9期
许媛媛


摘要:为了从已有的测试用例中提取经验知识、缩短测试用例设计时间,本文提出基于CBR(案例推理)的测试用例复用方法。首先对测试用例复用过程进行分析,指出测试用例检索是测试用例复用过程的关键。
在测试用例检索中采用K近邻法,并对K近邻法进行改进,同时在改进的算法中使用带权重的距离度量算法。在此基础上提出遗传模拟退火算法,该算法可对测试用例属性的权重进行优化,是遗传算法和模拟退火算法的结合,可以有效避免遗传算法的早熟问题,增强算法的全局寻优能力,缩短搜索时间。通过实验可以证明,该算法比标准的遗传算法和模拟退火算法具有更高的求解质量和求解效率。
关键词:测试用例复用;遗传模拟退火算法;案例推理;测试用例检索;属性权重。
中图分类号:TP301.6
文献标识码:A
DOI:10.3969/j.issn.1003-6970.2015.09.030
0 引言
随着软件广泛应用于各个领域,软件的质量问题逐渐得到人们的关注。软件测试是软件质量保证的重要手段,测试用例的设计占整个测试过程的60%,通过对测试用例的复用可以缩短测试设计时间,提高测试效率。
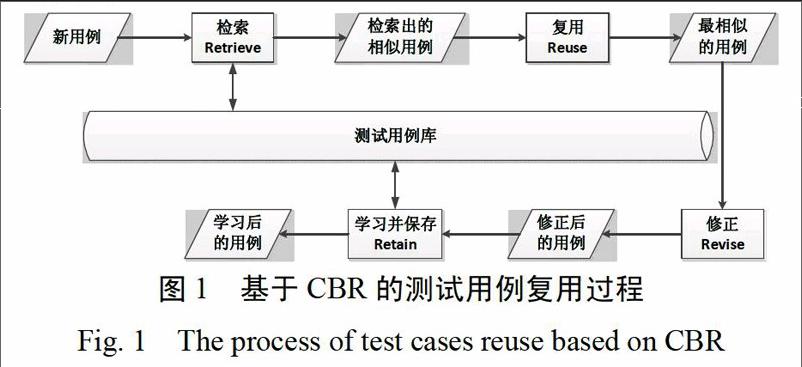
CBR是人工智能领域的一个重要推理技术,最早由耶鲁大学的Roger Schank教授与其合作者提出,旨在利用已有的案例解决新的问题。将CBR技术应用于测试用例复用,主要过程包括检索、复用、修正、保存。CBR模型的核心是案例检索,它直接决定了CBR整个过程的速度和精度,在目前的案例检索算法中,K近邻法由于简单直观而被普通采用,但也存在着两个问题,一是随着案例数目变多检索时间会线性增长,二是在距离度量算法中没有考虑特征权重。
对K近邻法进行改进,采用带权重的距离度量算法,提出遗传模拟退火算法并将其用于优化属性权重。该算法是两种算法的结合。遗传算法搜索速度快,强调的是两代之间的进化关系,具有较好的兼容性,容易与其他算法结合,缺点是其交配有可能使最优解遗失,陷入局部最优解。而模拟退火算法以某一接受概率采纳一个较差的解,因而可能会跳出局部最优解,是一个全局最优算法。遗传模拟退火算法结合了两种算法的优点,通过实验可以证明,该算法比标准的遗传算法和模拟退火算法具有更高的求解质量和求解效率。
1 基于CBR的测试用例复用技术
基于CBR的测试用例复用过程是一个循环过程,遵循4R模型,检索、复用、修正、保存,主要过程如图所示。
1.1 用例表示
建立用例库是复用过程的前提。测试用例包含名称、标识、说明、设计方法、前提和约束、测试输入、测试步骤、预期结果等要素,主要用于验证软件功能、性能、接口、人机交互界面、安装、卸载、文档等是否存在问题。
定义l测试用例可以表示为TC=
用例名称(Test Case Name,TCN):描述测试用例的名称;
用例标识(Test Case ID,TCI):用于唯一标识测试用例;
用例说明(Test Case Description,TCD):简要说明测试验证的功能点及测试方法;
设计方法(Design Technique,DT):说明采用的设计方法;
前提和约束(Precondition and Restriction,PR):说明执行的测试步骤所必须的前提条件;
测试输入(Test Case Input,TCIN):在执行过程中需要输入的具体内容,按照设计方法设计输入有效值、无效值、边界值等;
测试步骤(Test Case Process,TCP):把操作过程分成相对独立的测试步骤;
预期结果(Excepted Result,ER):执行测试步骤产生对应的预期结果;
1.2 基于K近邻的测试用例检索算法
案例的检索是CBR的核心,最常用的检索算法为K近邻法。K近邻法是一种基本的分类与回归方法,算法简单直观。对新的输入实例,在训练数据集中查找并计算与每个实例的距离,返回与该实例最近的K个实例,判断这些实例的类别,该输入实例属于类别最多的那个类。
基于K近邻的测试用例检索算法则是将测试用例的属性看作多维空间中的维,测试用例看作多维空间中的点,特征空间中两个点的距离是两个点相似度的反映,计算目标用例和测试用例库中已有用例的距离,返回距离最小的K个用例。
1.2.2 属性权重
用例中各个属性的重要性由属性的权重来表示,属性权重对检索的质量和速度都起到了重要作用。用例属性权重的确定方法主要有主观赋权法和客观赋权法。主观赋权法主要是专家根据主观经验来确定属性权重,如Delphi法、层次分析法等,研究较为成熟,但客观性较差。而客观赋权法是根据实际数据由数学规则来确定属性权重,如熵值法、均方差权重法、Critic法、最小二乘法、神经网络方法、遗传算法等,此类方法不依赖人的主观判断,因而客观性较强。为提高相似案例的检索能力,本文使用遗传模拟退火算法来优化属性权重。
2 基于遗传模拟退火算法的属性权重优化
2.1 遗传模拟退火算法
本文提出的遗传模拟退火算法通过引入模拟退火原理克服了遗传算法的早熟问题,同时提高了检索效率。
遗传算法是一种全局搜索算法,适合求解大规模的全局优化问题。借用了生物进化论中“适者生存”的规律,模拟生物遗传和进化过程中选择、交配、变异机制。缺点是可能陷入局部最优解,原因是在搜索过程中,根据优胜劣汰思想,种群优良个体增加而逐渐使其失去多样性,且变异概率较低,不足以跳出局部最优解,从而造成程序寻找不到全局最优解。
模拟退火算法源于对固体退火过程的模拟,以一定概率选择邻域中费用值大的状态。模拟退火的这种特性可以克服遗传算法可能陷入局部最优解的缺点。
遗传算法结合了这两种算法的特点,增强了搜索能力和效率。主要过程如下:
2.2 基于遗传模拟退火算法的属性权重优化
用例之间的相似度度量是用例检索的关键,而用例属性权重对用例的相似度度量起到了至关重要的作用。在改进的CBR检索算法中使用了带权重的距离度量算法,给用例的每个属性赋予一定的权重,通过遗传模拟退火算法优化属性权重。
遗传模拟退火算法首先随机产生一组初始解,通过选择、交配、变异的遗传操作开始寻求全局最优解,然后再对遗传操作所产生的个体进行模拟退火,并将模拟退火产生的结果作为下一代群体的初始解。循环此过程,直到满足终止规则,得到最终群体。
2.3 实验结果
利用测试用例作为实验数据,选择属性用例名称、用例说明、设计方法、前提和约束、测试输入、测试步骤、预期结果作为观测属性,测试用例的相似度作为决策属性。
通过遗传算法来确定这7个观测属性的权重,其中每个属性的权重代表了该属性对测试用例相似度的决定能力,结果如表1所示。
实验结果中,遗传模拟退火算法的分类精度最高,表明该算法比标准的遗传算法和模拟退火算法具有更高的求解质量。
3 结论
本文给出了基于CBR的测试用例复用方法,对检索算法K近邻法进行了改进,使用带权重的距离度量算法更能突出属性对测试用例相似度的不同影响。并给出了基于遗传模拟退火算法的属性权重优化,遗传模拟退火算法主要以遗传算法为主体,引入模拟退火的集中扩散机制和加速适应函数,该算法具有遗传算法的优胜劣汰思想,同时通过融入模拟退火算法思想克服了遗传算法的早熟问题,缩短了搜索时间。理论分析和实验结果均表明遗传模拟退火算法在求解质量和效率上优于标准的遗传算法和模拟退火算法。
