
分布式环境下可靠数据同步及通讯的协议分析
2015-12-25 12:20刘皓
软件 2015年9期
刘皓

摘要:随着互联网技术的日益普及,分布式计算模型在企业中的应用越发显得重要。以往在要求高性能、高可用性环境下进行业务复杂计算往往注重于单台高价计算机的运算性能和可靠性,目前在分布式计算模型趋于成熟之后已经逐步转向采用多台廉价计算机协同计算来达到相同的目的,对企业应用架构而言,这不但大大降低了企业采用高性能计算的成本,也在业务可扩展性上提供了敏捷的渠道。在众多的分布式环境下的计算通信模型中,JGroups作为一个可靠的组播通信工具提供了一个非常优秀的轻量级分布式计算模型及实现。本文试图从分布式计算需要解决的几个重要问题出发,详细剖析JGroups框架在分布式计算的可靠性和通信协议上所提供的完整解决方案。
关键词:分布式计算;JGroups技术;组播;通信协议;高可用;集群
中图分类号:TP391.41
文献标识码:A
DOI:10.3969/j.issn.1003-6970.2015.09.029
0 引言
JGroups最初是由Bela Ban于1998年到1999年间在美国康奈尔大学攻读博士后学位时期着手开发的一款解决分布式环境下的计算机之间通讯的软件。2000年5月,SourceForge成立之后,Bela Ban看到了开源的力量,并决定将JGroups的源代码共享给互联网上其他有共同兴趣的爱好者。随着更多的开源软件爱好者的加入,JGroups迅速壮大起来。2003年,在JBOSS的创始人Sacha Labourey的邀请下,JGroups加入到JBoss的队伍中并成为之后JBoss Cache框架的核心通讯组件。2006年5月,著名的Linux操作系统产商Red Hat宣布收购JBoss,JGroups也随之成为了目前世界上主流开源软件服务提供商的核心软件框架之一。到目前为止,JGroups提供的分布式计算模型和通信协议通过软件开源过程的不断锤炼已经逐步成熟,事实上已经成为小规模计算机集群底层状态复制的行业标准。
1 分布式计算模型
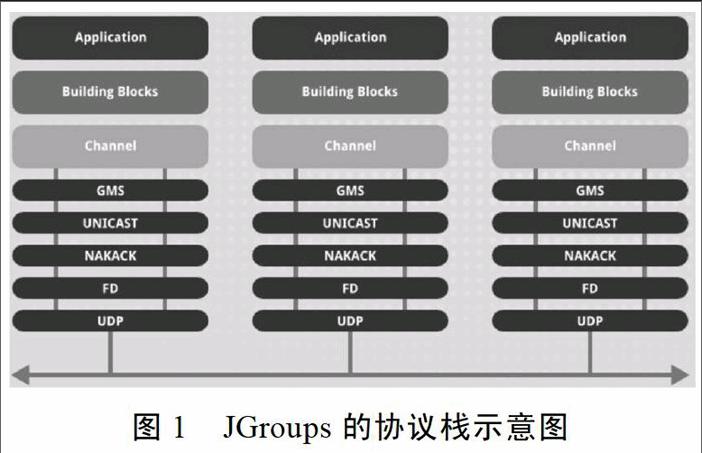
JGroups是由java编写的一个可靠的组播/多播通讯工具包,它不但支持可靠的组播通讯,也支持采用TCP协议来进行消息传递。其工作模式基于IP多播,可以在可靠性和群组成员管理上进行扩展。其基本思想是在计算机网络环境下,通过配置通信协议将多台计算机进行分组,在计算机分组中通过多套协议来保证可靠的消息通信和分组中每个成员异常状态监测,在此基础上可以为应用程序提供完整的分布式环境下的业务状态同步、任务分配和计算结果的收集。
从设计上来看,它提供了一种灵活兼容多种协议的协议栈。协议栈可以相互组合使用,用来适应不同产品的可靠性需求。这种协议栈可以让用户根据自己的应用的需求进行调整,主要是根据特定的网络环境下需要同步的数据量大小、计算节点集群的规模以及需要同步的频率定制适合自己的协议栈。
从应用上来看,它提供了分布式环境下有效的同步机制,提供了在集群计算节点之间通信统一的API,包含了从点到点以及由单个计算节点到全组的通信接口,可以很方便的保持各个计算节点状态一致性。
1.1 可靠的消息传输
在分布式计算环境中,保证计算节点之间数据通信的可靠性是计算机集群需要考察的一个最基本的能力。目前最通用的网络通信协议主要是TCP协议和UDP协议。在多台计算机协同工作的环境中,采用TCP协议可以很方便的达到消息可靠传输的目的,但是TCP协议要求计算机在网络中创建点到点之间有状态的SOCKET资源,如果需要将同一条消息发送给集群中的每一个节点,采用TCP协议将比采用UDP协议需要更多的网络流量,这在大规模的网络实时通信中对应用程序而言是一笔不小的开。UDP协议对网络资源的消耗代价很低,但UDP协议本身并不能保证通信过程中消息可以可靠的从消息发送者传递到消息接收者手中,所以如果要在集群环境中使用UDP协议达到可靠的消息传输的目的,需要在UDP协议之上增加新的协议进行控制。
在集群环境下使用UDP协议进行通信可以有效的降低集群网络环境的数据传输压力,JGroups通过UNICAST协议来保证消息的可靠传输,UNICAST协议在UDP的基础上增加了消息响应的步骤,以保证传输过程的完整性。原始的UDP协议不要求消息的接收者反馈给消息的发送者是否已经成功接收到消息,UNICAST在此基础上完善了消息反馈的过程。消息的反馈方式分为ACK和NAKACK两种:
ACK:消息的发送者不断的重复发送消息,直到所有的接收者都返回了确认消息已经收到,
NAKACK:消息的接收者不断请求消息发送者发送消息,直到消息的接收者确认所有收到的消息是完整的。
UNICAST协议需要保证消息的传输过程是可靠的,它依赖于一个不断发送消息的时间周期来进行循环,因此UNICAST的一项重要的配置属性timeout就来源于此:如果timeout值被设置为100,200,400,800,就表示如果消息发送者在等待100毫秒还没有接收到消息接收者的ACK消息,则消息发送者重新发送消息(第一次重发),消息发送者继续等待200毫秒仍然没有接收到ACK消息,则消息发送者再次重新发送消息(第二次重发),这样直到等待800毫秒进行第四次重发。在多播环境下,NAKACK协议基于ACK协议进行了扩展,在这种协议下,每个消息绑定一个序列号,消息接收者根据序列号确保消息按正确的顺序传递。如果接收者发现了一个序列号的缺失,接收者安排一个周期性的任务去要求发送者重新发送该序列号的消息,当缺失的序列号的消息收到,则请求数据同步的任务取消,并向消息的发送者提供消息完全抵达确认反馈。
1.2 分布式垃圾回收
由于UNICAST协议通过循环通信过程消息反复比对来保证消息传输的可靠性,这就要求集群中的所有节点必须保存已经接收到的消息用以判别消息是否存在错误以及是否需要进行消息重发。但是如果应用程序一直保存接收到的消息,则会面临内存溢出的问题。为了解决这个矛盾,JGroups通过STABLE协议负责周期性的释放所有节点上已经被所有节点收到的消息,从而达到回收各个节点上内存的目的。分布式垃圾回收过程定义了由集群的协调者组织的定期执行回收的周期,它可以通过控制每个节点上允许保留的消息数量或者单个节点上可以保留的消息所占用的内存空间大小来决定什么时间执行分布式垃圾回收动作,一旦集群的协调者通过周期性的任务检测到集群中的节点中保存的消息数量超过了预设的阀值,或者保留的消息占用的内存空间超过了预设的阀值则发出统一的垃圾回收指令,以释放全体计算节点的内存空间。
1.3 集群计算节点发现
JGroups为分布式环境下的计算机集群提供了一个高级抽象:通道(JChannel),每一个计算节点在启动之初都会通过通道连接到相应的集群。每个集群都有唯一的标识(ClusterName),计算节点通过通道和集群标识来判断自己属于哪一个计算工作群组。当集群中的节点开始工作时,它开始探测通道中是否存在有其他已经在运行的节点,如果存在多个已经运行的节点则需要找到集群当中的集群协调者进行通信。在通道中第一个启动的计算节点被认为是集群的协调者,它负责创建新的计算节点并将其通知到集群中的每个成员对象。集群成员发现协议用来发现集群中活跃的节点及集群的协调者,这个协议的名称是PING协议。
PING协议位于传输协议之上,任意一个节点对PING消息的反馈消息包括协调者的地址和自己的地址。JOIN PING消息发送后等待timeout属性定义的时间或num_initial_members属性定义的节点回复后,该加入的节点会根据反馈消息确定协调者,并向其发送JOIN消息。如果没有收到任何反馈,计算节点就认为自己是集群中第一个节点而作为协调者运行启动。
计算节点利用PING协议收集到的信息接着传递给集群成员管理协议(GMS),GMS协议与协调者的GMS通信,将新加入的节点加入到集群。发现协议通常也协助合并协议(MERGE2)处理集群分裂的情形。发现协议位于传输协议之上,因此需要传输协议的不同使用相应的发现协议。
1.4 计算节点状态检测与管理
集群中计算节点的状态管理主要由心跳协议(FD)、群组成员关系协议(GMS)、错误探测协议(FD-SOCK)和确认可疑协议(VERIFY_SUSPECT)等共同完成。
GMS协议
GMS即群组成员关系协议,该协议是JGroups协议栈中的重要协议,它维护者一个活着节点的列表。GMS负责群组成员加入和离开群组的请求,同时它也处理错误探测协议发送的SUSPECT协议。
FD协议
FD协议基于心跳消息(are-you-alive)。该协议需要任意一个节点周期性的Ping它的邻居节点,如果邻居节点没有返回,发生心跳消息的节点发送SUSPECT消息给集群协调者,集群协调者接收到SUSPECT消息后验证怀疑的节点是否死掉(VERIFY_SUSPECT),如果节点被确认为死掉,协调者更新集群成员关系视图,死掉的节点被移除。
FD-SOCK协议
错误探测协议FD_SOCK基于群组成员创建的TCP套接字环,FD_SOCK协议不使用心跳消息作为探测手段。集群中的任何一个节点都连接到它的邻居,集群中第一个节点连接到第二个节点,第二个节点连接到第三个节点,这样最后一个节点连接到第一个节点。这样如果某一个节点发送异常,它的邻居节点会发现异常,检测到错误。
VERIFY_SUSPECT协议
VERIFY_SUSPECT协议通过向被怀疑的对象发送确认消息来确认被怀疑的节点是否确实死掉了。这个操作是被集群的协调者执行的。如果确认节点死掉,则该节点将会被移至异常集群成员列表视图。
1.5 通讯流量控制
FC协议(Flow Control流量控制协议)用来在集群中调节单位时间内计算节点发送消息的字节数和消息接收的字节数。在现实中情况复杂的应用网络环境下,如果消息发送者的数据发送的速度超过了消息接收者数据处理消息的速度,经常会导致接收方陷入异常或者丢失消息,这将触发消息重发机制同时导致消息传输效率的急剧下降,流量控制协议负责调解此类状况。事实上,JGroups流量控制协议基于类似金融信贷的设计,一开始消息发送者和消息接收者都配置有相同的额度(字节数),发送者通过不断发送消息的字节数减少额度,接收者则通过计算已接收到的字节数增加额度,如果发送者的发送额度降低到某一阈值,接收者将已经接收到的字节数反馈给发送者,要求发送者继续发送后续的消息,如果发送者用完自己的额度,则发送者处于阻塞状态直到接收到接收者的所有消息数据。
消息裂解协议(FRAG2协议)用于处理超大消息数据的通信。当一个消息的大小大于某一确定的值时,通常这种字节数过大的消息经常会造成网络拥堵甚至在极端情况下会触发网络交换机的自我保护机制而直接断开通信端口,为了避免此类情况的发生,分裂协议将消息分裂成多个小消息,然后进行发送;而在接收端,同样分裂协议将分裂的消息进行重组。不管多播还是单播发送消息,分裂协议都可以起作用。
1.6 集群的分裂与重组
在情况复杂的网络环境中,处于工作状态中的集群分组可能由于网络故障而断开了网络通信,这将导致计算集群的分裂,每个分裂后的子集群将由GMS协议推举出最年长(最早启动的计算节点)的节点作为网络协调者。一旦网络恢复通信,两个分裂的集群通过JGroups通道和集群的唯一标识发现在集群中出现了两个网络协调者,它们将启动一个集群合并的进程,这个进程主要由集群合并协议(MERGE2)来负责调度完成。在合并的过程中,两个网络协调者将交换节点启动信息,从而推举出最年长的节点作为新的网络协调者。为了确保在集群环境中各个网络协调者都能达成一致的结果,每个协调者将所有成员的地址合并在一个列表中,然后对列表依据启动时间进行排序,在排序列表的第一位成员即是新的网络协调者。
1.7 集群的网络安全
为了保证只有经过验证的计算节点才能加入到集群计算,JGroups提供了通信安全加密协议。通常情况下,计算节点通讯的加密过程只针对消息主体内容进行加密,消息头数据是不经过加密的。如果需要对整个包含消息发送端的地址和消息接收端的地址完整通信报文进行加密,需要配置额外的属性encrypt_entire_message的值为true。需要注意的是,消息加密的过程可能会导致网络通信效率的下降,因为在每一次的网络通信过程中处理字符加密的过程也会消耗额外的计算机资源。
2 小结
本文对组成网络环境的计算机集群所需要考虑的数据通讯协议进行了分析。创建一个计算集群需要考虑如何在计算成员之间进行可靠的消息传输,集群服务启动之后如何探测和发现集群中网络计算成员,如何确定网络协调者的身份。网络协调者在运行状态下需要随时了解集群中每个成员的健康状态,一旦集群中某台机器出现了故障则需要将它从成员列表中删除,如果集群中加入了新的计算成员则需要由网络协调者将其加入到成员列表中并安排新成员的排序位置。同时需要考虑,如果网络通信出现故障后如何组织新的集群,网络通信恢复正常后如何将分裂的集群进行合并以恢复集群的运行。并在此基础上,讨论了集群环境下网络通信的安全性和网络数据传输的流量控制协议。
当前大数据计算技术越来越引起了人们的兴趣,从根本上来说,大数据的分布式计算模型也需要考虑到文中所讨论的这些应用场景,作为一个小型的网络集群解决方案,JGroups提供了很好的思路可以进行参考和学习。
猜你喜欢
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
成都信息工程大学学报(2017年5期)2018-01-23
中国交通信息化(2017年3期)2017-06-08
科学与财富(2016年15期)2016-11-24
广东石油化工学院学报(2016年6期)2016-05-17
系统工程与电子技术(2016年2期)2016-04-16
电测与仪表(2016年2期)2016-04-12
铁路通信信号工程技术(2014年1期)2014-02-28
