
水利泵站远程监控安全系统设计
2015-12-25 11:57何宇施丛丛桑笑楠龚佳俊郎
软件 2015年9期
何宇++施丛丛++桑笑楠++龚佳俊++郎新赟++李千目

摘要:水利是一个信息密集型行业。水利信息包括水雨情信息、汛旱灾情信息、水量水质信息、水环境信息、水工程信息等。当今的水利建设过程中,往往侧重基础设施建设,而忽视了将水利建设与信息化、智能化相结合,从而导致其信息化程度不够,不能高效地管理、利用水利设备或有效进行洪涝预警,在效能、效益方面存在欠缺。本文充分利用现代信息技术,设计并实现了水利泵站远程监控系统。引入了水文监测、控制、预测模型及算法,对基于结构化支持向量机的泄洪联动技术进行了设计,从全局的高度设计建设具有开放性的信息化集成平台,实现信息共享和业务流程优化,提高泵站管理水平、运行调度水平、装备自动化水平、防洪抗旱调度决策水平。
关键词:水泵;远程控制;物联网
中图分类号:TP391.41
文献标识码:A
DOI:10.3969/j.issn.1003-6970.2015.09.018
0 引言
我国水利事业发展至今,在全国范围内从整体上已初步形成以大型泵站为中心的跨流域调水及防洪排涝体系,有力地加强了各地区抵御自然灾害的能力。目前,我国水利信息化的应用模式单调而传统,尽管部分流域已经构建完成了相关防汛系统基本实现了降雨洪水险情的自动管理和监测,但对集成信息实时监测、三维决策支持、防汛预案展示及信息采集维护等为一体的防汛指挥地理信息系统的研究却很少,大量历史数据中的潜在信息得不到挖掘,使得水利相关信息得不到有效利用,造成富硬件的浪费、误导决策者的科学决策。
尽管为了解决由水利、交通、能源等的大规模建设所引发许多迫切需要解决的水文问题,科技工作者已对相关领域的模型及原理进行了大量分析研究。这为水利检测积累了比较多的资料及经验,为解决这些问题打下了基础,促使水文的长足发展。由美国国家气象局(现名美国海洋大气和管理局,设计的交互式洪水预报系统NWSRFS(Nation Weather Service River Forecast Sys-tem)对水文洪涝信息预测模型的输入、输出标准化、规范化,已被该国内多河流预报中心日常规划使用。美国陆军工程师兵团开发的SHE(System HydrologicEuropean)软件包集成了多个常用水文模型,已在水利设计、洪涝预测等领域发挥重要作用。以及目前仍在广泛应用的产汇流理论和水文统计原理与方法,包括霍顿下渗理论、等流时线法、单位线法、马斯京根流量演算法、各种流域水文模型、经验频率公式、输沙率公式等,都在一定程度上解决了水文预报和分析计算问题,为水利工程的设计、施工调度及管理提供了可靠依据。
本文进行了水利泵站的远程监控系统的设计,系统能够根据系统所记录的大量水位、流量、温度等水文信息历史数据,结合实时水利周边信息,经过适当数据挖掘分析,实现对重要监测量的可靠预测,如对洪水到来时间及洪峰可能达到的强度进行预测评估。并对系统监控范围内的硬件设备等资源进行合理优化调度,建立起集信息感知、控制、管理、预测、优化调度于一体的泵站数字化智能化系统体系框架。
1 系统总体构架
本系统总体组成部分框架前端部分主体为分站视频监控器、水文数据采集设备等,采集到的数据经由连接各分站交换机的光纤传输,总站管理员通过访问局域网络内的客户端进行系统访问等各类操作。数据采集(DAQ,Data Acquisition),包括从被监测设备中获取信号,然后传送到上位机中对采集到的数据进行分析、处理的过程。系统基础数据采集模块流程图如图1所示:先对每个数据采集仪的固定IP和端口进行TCP连接,若连接成功,就发送数据采集指令,读取返回数据,如果连接不成功,就每隔一段时间继续连接,直到连接成功为止。
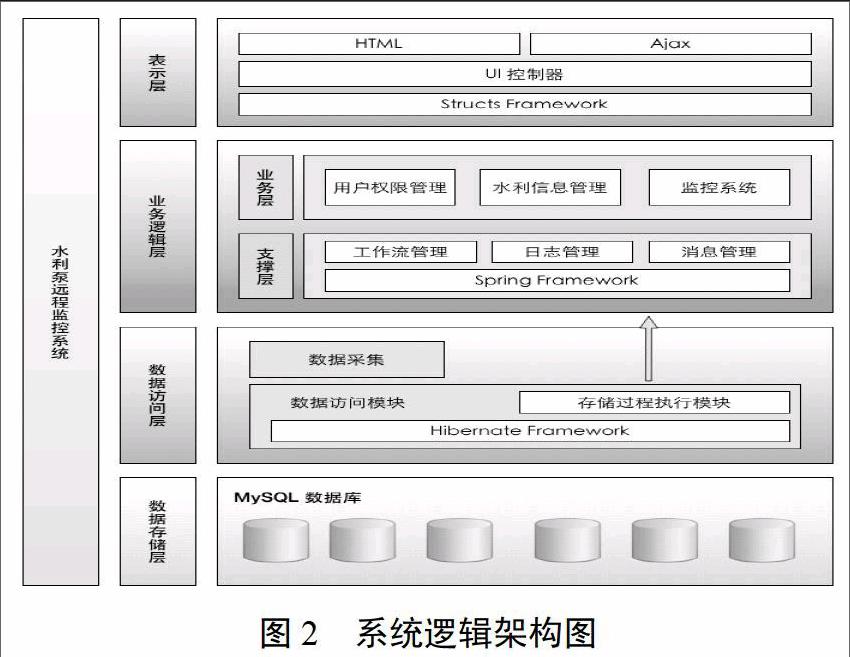
图2为泵站远程监控系统逻辑框架图。模块间的集成依赖Web Service技术提供的异构平台通信机制。由于各层间均为低耦合的模块化设计,在不影响整个系统正常运行情况下进行设备更换。层间通过TCP/IP协议实现通讯,不受网络平台的限制。各泵站监控系统既相对独立,又能通过配置信息监测和网络传输设备,形成泵站信息化监测站网体系,进一步提高各类信息自动采集、处理能力,提高了信息传输速度和数据采集的精度,更好地监控水情。整套设备能在恶劣条件下正常工作,全套设备的集成度高,各设备单元相匹配,各单元及总体功耗低,防水防破坏性好,易维护。
数据采集的过程是软件系统与硬件系统对接的过程,通过数据采集工作,系统获得了可用于进行监控、分析和查询的数据,而这些获取到的数据再经过一系列的转码工作之后,便可被保存到数据库。
系统通过传感器和电压表所采集到的数据将流人数据采集仪,并将其持久化至数据库中。数据库中的数据将用于实时监控,水泵、泵站的相应信息的统计与查询,同时也将根据异常数据来进行远程预警,最后,数据库中的数据也可用于报表的生成。
2 核心模块实现原理
系统的软件控制部分的Web平台的实现采用MVC模式,并使用J2EE开发中的典型技术SSH框架实现相关的设计和开发工作。本系统在业务逻辑层利用Hibemate框架提供对象持久化支持,Spring做IoC管理,管理java对象,同时也负责管理Struts和Hibernate的框架对象。给出Hibernate的DAO实现,Java类与数据库之间的转换和访问由Hibernate架构所实现的DAO类实现,最后由Spring做管理——管理Struts和Hibernate。
系统的基本业务流程:表示层由Struts进行URL路由和相应页面的渲染,页面使用标准的JSP实现,Struts框架根据客户端(Client)请求(Request)通过查询配置文件(struts-config.xml)并将该请求路由到相应的ActionServlet中完成业务逻辑处理,并通过响应传送(Response)对象将http页面返回客户端。在业务层中,Spring框架负责解除层与层之间的耦合,通过读取Bean.xml配置文件来向业务逻辑对象中注入(Inject)数据访问对象(Data Access Ob-ject),持久层则通过注明的ORM框架Hibernate实现数据库与面向对象模型的映射,并实现增删查改等逻辑。
使用SSH框架,修改数据访问层则不会影响到业务逻辑层,同样的,修改业务逻辑层也不会影响到数据访问层。同样的,前端的Struts框架则实现了良好的MVC风格,使得页面代码与Java代码得到了分离,系统的层次更为清晰,易于开发。
主要封装包介绍如下:
com.njust.waterconservancy.action包:action层,前台MVC框架中Controller的具体体现,其角色相当于Servlet,负责处理来自前台的请求,并实现前后台交互。它能调用业务逻辑层的方法,并返回给前台一个页面或Json(视具体配置)。
com.njust.waterconservancy.service包:业务逻辑层接口。
com.njust.waterconservancy.service.impl包:业务逻辑层的实现层,Spring管理的Service对象放在该层,负责调用DAO方法。
com.njust.waterconservancy.ios.service包:iOS在服务器端的处理类,基于SOAP协议,处理iOS端发来的SOAP消息,处理完后将结果以SOAP消息的形式返回iOS端。
com.njust.waterconservancy.dao包:DAO(数据访问对象)层接口。
com.njust.waterconserv ancy.dao.impl包:DAO层接口的实现类,负责数据库的存取。
com.njust.waterconservancy.model包:数据库表、视图所对应实体类
com.njust.waterconservancy.web.vo包:是前后台交互的数据实体,负责接收前台发至后台的请求表单中的数据,一般作为Action层的模型。
com.njust.waterconservancy.web.filter包:验证用户信息是否完整并过滤用户请求。
在系统前后台所有数据对象间的通信以json形式进行。json是javascript的原生对象,是轻量数据传输方式。它本质上是通过描述一组名称/值对,实现彼此间的数据传输。以系统登录和报表生成为例:
(1)系统登录
本系统拥有当下B/S应用的多种特性,在用户登录环节,系统根据请求登录的用户所输入的ID,密码匹配成功后查找该用户的相应权限,并依此生成相对于该用户的菜单树。
在Web客户端打开浏览器,输入网址xxx/WS后回车,web服务器开始解析web.xml文件,启动Spring容器,加载Struts的Filter,并控制进入欢迎界面login.jsp。解析struts.xml,依据注解@userLogin寻找对应的UserLoginAction。而web前端由login.jsp和其引用的login.js组成,基于ExtJS框架完成界面设计和json数据向后台的传送。用户在输入用户名及密码时,系统会通过validate0方法对用户输入进行验证。只要用户的登录信息和数据库的信息匹配,系统便为之创建session并根据该用户信息对其进行相应业务逻辑操作,生成用户相应权限的菜单列表。
(2)报表生成
进入系统的报表菜单界面,选择“泵站基本建设情况”子菜单,可打印报表,或者进行修改、预览。当系统在后台生成发送报表请求后,由struts.xml文件导向实现报表生成的Action类BumpInfoAction,其中定义了实现报表生成的jasperToPdf方法。该方法调用了JasperReport API,是报表生成的关键。在Jasperreports.properties中将net.sf.jasperreports.awt.ignore.missing.font属性值置为true。考虑后期系统服务器的Linux系统移植我们将字体部署为Linux系统字体。部署完成后加载模版文件,控制转回前台界面bzjbqk.jsp,用户点击相应按钮即可实现报表下载。其余功能实现类似。
本系统的数据采集过程实现如下:
打开数据采集仪服务端程序后自动进行数据库连接,确认系统显示正确连接。
在菜单中点击“服务选项”,接着进行参数设定,进入参数设定界面根据需求设置相关参数。
与数据采集仪通信的参数默认设置为:
波特率:9600;载波位:8;停止位:1;无检验位;配置固定的IP地址,默认网关;采集泵机参数的间隔为1分钟。
设置完成后点击“CONNECTION”按钮即可打开该网口并进行通信。
打开网口后,便可根据数据采集仪协议,以及所设时间间隔自动发送指令,并将所采集的数据实时地传人数据库。
3 系统实现
用户在浏览器输入登录地址,填写用户名、密码并点击登录按钮,用户名和密码并通过系统验证后才能对用户权限进行授权并使得用户可以进行各种操作。
管理员权限的用户可以对本机构及下属机构的用户进行管理,包括查询、添加、删除、冻结、解冻用户;修改用户登录密码。
单击用户管理按钮后后,则显示用户管理界面,如下图示:
1)根据机构查询相应用户
当系统管理员可根据机构查看用户列表信息,如图6所示:
提供基本采集项属性数据的增、删、查、改;属性数据包括采集项类型名称、HEX编码(采集地址)、采集数值上限、采集数值下限、报警数值、校准数值等。
单击“采集项管理”,进入采集项管理界面:
图7显示了采集项基本信息表,包括采集项名称、HEX编码等。用户可编辑或删除相应采集项。
提供泵站设备列表,包括泵站、进水池等属性数据的添、改、删;属性数据包括所属机构、生产厂商、型号、采购人、采购人联系方式、新增时间、采集参数设置等。
单击“设备管理”,进入设备管理界面:
单击泵站数据查询节点,进入泵站数据查询界面,“采集参数”项可实时更新,如下图示:
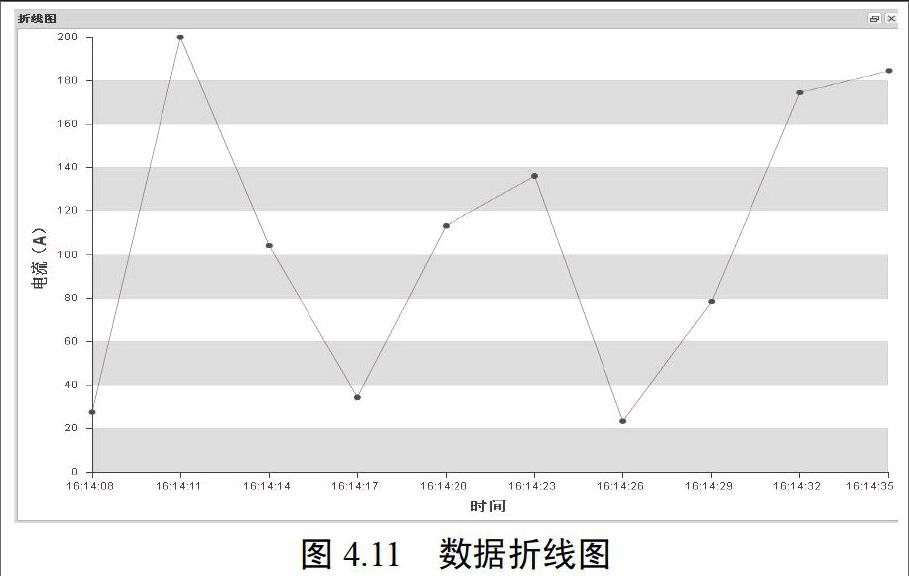
点击所需显示的泵站的显示图标按钮,出现对应折线图,如下图示:
4 结论
本水利泵站远程监控系统设计开发过程中,充分考虑到了系统功能完备性,综合应用目前较为流行且技术成熟的SSH框架和ExtjS Web前端开发技术、Web Service技术、Aj ax技术、Web GIS等技术的同时,进行实践、分析及优化。系统极大程度上满足泵站信息采集、设备管控、水文状态监控的需求,拥有较为友好的用户体验。并且可灵活拓展运用,经过适当规模性改变即可灵活应用于各类中小型排涝泵站及各类供水管网等,可使水务工作人员有效地掌握第一手实时水文数据并及早做出恰当处理预案,亦可增强泵站的安全性。
猜你喜欢
水泵技术(2021年5期)2021-12-31
昆钢科技(2021年1期)2021-04-13
科学与财富(2016年26期)2016-12-01
环球时报(2016-08-01)2016-08-01
设备管理与维修(2016年7期)2016-04-23
河南科技(2014年18期)2014-02-27
