
用户定制主题聚焦爬虫的设计与实现
2015-12-20 06:59:12闵钰麟黄永峰
计算机工程与设计 2015年1期
闵钰麟,黄永峰
(1.清华大学 电子工程系 信息认知与智能系统研究所,北京100084;2.清华大学 信息科学与技术国家实验室,北京100084)
0 引 言
互联网时代用户的个性化需求越来越高,在实际应用场景下,不同用户的需求通常存在差异,他们希望在其特定领域及方向上进行 “定制化”的主题爬行。传统的聚焦爬虫在开始工作之前需要对指定主题进行建模和训练,在缺乏相应主题训练集的情况下无法完成任务,不能满足用户 “个性化”需求。本文设计并实现的定制主题聚焦爬虫不依赖于主题训练集,仅在用户提供少量未知主题的种子url(同一主题)的情况下完成主题爬行,得到针对该主题较高的收获率 (havest rate)。
1 相关工作分析
聚焦爬虫通过对url的优先级进行计算和排序,优先访问较高概率指向相同主题网页的url,从而得到较高的收获率[1]。目前改进聚焦爬虫的思路主要有4 种:第1 种是基于网页链接分析的方法,在论文[2]中,Hati定义了链接距离的计算方法并使用其对链接排序,Taylan在其论文中提出了基于朴素贝叶斯分类器的链接评分方法[3]。第2种思路是基于网页文本分析的方法,主要思路是计算网页文本或锚文本与主题的相关度,并使用相关度作为url排序的基准,例如G.Almpanidis提出了基于内容和链接分析的方法[4],Hong Wei Hao的 研 究[5]表 明,在 主 题 相 似 度 计 算中使用潜在语义索引 (latent semantic indexing)比TFIDF有更好的表现。第3 种为基于本体领域的方法,Yang提出了支持本体的网站模型[6]并将其用于聚焦爬虫,Punam利用特定领域的本体概念语义扩大搜索话题,模仿人类的认知搜索模式从SBS (social bookmarking site)找到潜在相关的网络资源[7]。第4 种方法基于用户日志,Sotiris Batsakis利用隐马尔科夫模型 (HMM)学习用户浏览行为并预测不同网页聚类之间的联系[8],Yajun Du提出了基于用户日志的形式概念分析 (CFA)方法并将其用于网页语义排名[9]。这些方法从不同角度出发提高聚焦爬虫的效率,但是他们一个共同的局限性就是需要事先构造主题训练集。
以基于网页内容的方法为例。基于网页内容的方法通常使用best-first策略对url进行排序。best-first策略的基本思想是如果一个页面和主题的相关度越高,则处于该页面上的链接指向的网页也属于该主题的概率就越大。bestfirst策略实现方法如下:
(1)构建具有一定规模的训练集,该训练集由网页文本构成,至少应该有两类,一类是与主题相关的网页文本,另一类是与主题不相关的网页文本。该训练集用于提取文本特征和主题建模。
(2)使用信息增益、χ2分布等方法提取该主题的特征,并统计特征词的IDF权重,特征词的IDF权重可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到
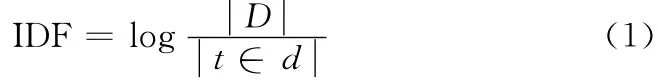
(3)利用VSM (vector space modle)模型将训练集中的主题映射到特征空间上,得到文本向量vt,其中n为文本特征维数,xt,i(i=1,2,...,n)为TF·IDF特征权重
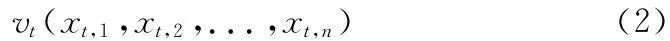
(4)对于一个新爬取的网页,同样使用VSM 模型将解析出的网页文本映射为向量vw
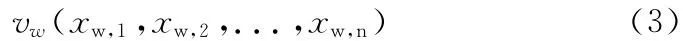
(5)使用余弦相似度评价网页文本与主题的相关度
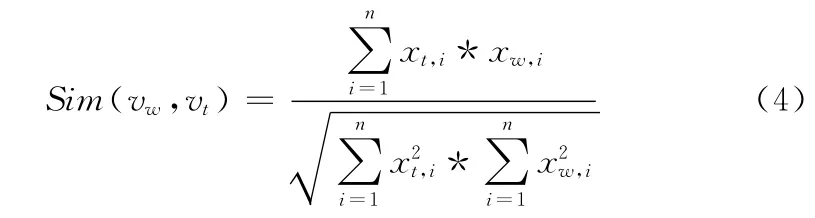
(6)将该页面上的url加入队列,并按照url所在页面与主题的相关度Sim(vw,vt)进行排序,这样聚焦爬虫每次从队列中取出的url均为与主题最相关的页面中的url。
通过分析可以发现,基于网页内容的聚焦爬虫需要提供该主题的训练集才能完成对特征提取以及主题向量的计算。实际上,几乎所有的聚焦爬虫均需要事先构建一个针对该主题的训练集,而对于个性化的用户需求来说,主要面对的问题是用户的需求千变万化,爬虫可能会因为缺乏用户需求主题的训练集而无法完成任务。
针对以上问题,本文提出基于聚类算法的自适应主题模型,用于指导聚焦爬虫在只有少量未知主题的url的情况下完成主题爬行。
2 自适应主题模型
2.1 主题建模
为了使模型能够准确地描述主题,本文引入文本聚类算法k-means的思想。k-means算法的目的是将一个文本库中的文本分为k类。对于一个含有n (n>k)个文本的它首先 随 机 选 定k 个 文 本 作 为 初 始 类 的 中 心Mi=1,..,k(xMi,1,xMi,2,...,xMi,m),其中m 为文本特征维数;对于剩下的每个文 本vt(xt,1,xt,2,...,xt,m),计算它到每个类中心的欧氏距离
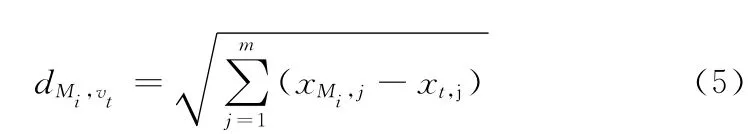
并把这个文本加入距离最近的类Mi,然后使用式 (6)更新该类的中心位置,为该类文本数目
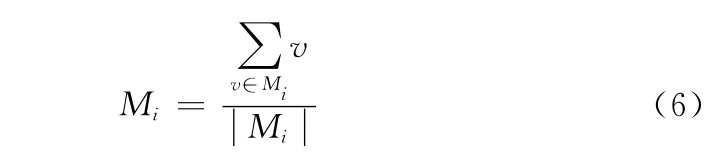
算法不断重复这一过程,直到满足某一收敛条件。
基于这一思想,对于用户给定的n个url,因为属于同一主题,我们可以认为这些url指向的网页已经聚为一类Mu,那么我 们 可 以 使 用 这n个 网 页 文 本vui(i=1,..,n)(xui,1,xui,2,...,xui,m)的中心位置来代表用户定制主题的向量

2.2 模型修正
在上一小节中我们基于聚类的主题模型得到了表征用户定制主题的向量,但是该模型存在着初始向量过少的问题。这些向量如果在特征空间上分布不均匀,那么它们的中心位置就不能很好地代表该主题。
为了能够简单直观地说明这个问题,我们以三维的特征空间为例。
如图1所示,假设该主题的所有文本映射到特征空间后聚类形状为球形,那么这个球的中心,即图中 “O”所示位置,就可以代表这个主题 (类)的中心。
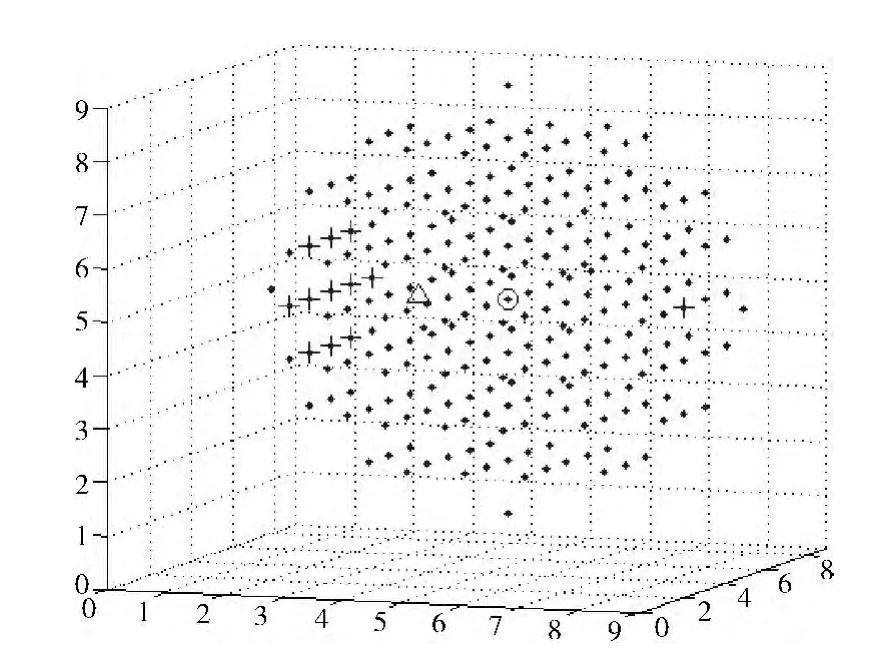
图1 初始向量在特征空间上不均匀分布
如果用户给定链接对应的网页文本映射到特征空间后为图中 “+”所示位置,则使用式 (7)计算后得到的主题中心位于图中的 “Δ”所在的位置。可以很明显地看到,通过计算得到的用户定制主题中心和实际的主题中心存在偏差。
为了解决这个问题,需要在爬行过程中寻找属于高相关度的网页来不断修正用户定制主题中心。基本思路是每下载一个网页,提取网页文本内容后映射为向量vw,使用式 (4)计 算 该 向 量 与vui(i=1,..,n)的 余 弦 相 似 度Sim(vw,vui),vui(i=1,..,n)为 初始链 接 对 应 的 网 页 文 本 向 量。在VSM模型中,两个向量的余弦相似度越接近于1,那么这两个向量所对应的话题就越相似。当Sim(vw,vui)大于某阈值时,我们可以认为该网页和用户提供的某个网页属于同一话题,即这个网页属于该主题,那么我们就能使用向量vw来更新用户定制主题中心。
用Mp(xp,1,xp,1,...,xp,m)表 示 更 新 前 的 主 题 中 心Mn(xn,1,xn,1,...,xn,m),表 示 更 新 后 的 主 题 中 心,vw(xw,1,xw,2,...,xw,m)表示用来更新主题中心的向量,那么更新公式可表达为
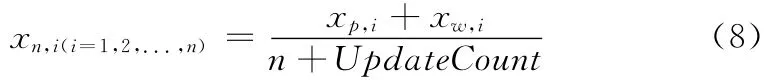
式中:n——用户给出的链接个数,UpdateCount——已更新次数。
使用该方法更新用户定制主题中心可以在一定程度上解决主题中心偏移的问题。
2.3 特征提取
在建模过程中需要解决的一个实际问题是特征的提取与特征权重的计算。
问题分析:初始信息只有用户给定的一组链接,无法使用传统的方法完成特征提取和IDF特征权重统计。
解决办法:利用初始页面的词频 (TF)作为特征的选取标准,特征权重也使用TF代替TF·IDF。
特征词一般选择最能够代表该主题的一类词,词频高低在一定程度上也能体现一个词在主题中的重要程度,单纯使用词频作为特征选择标准和特征权重会使一些常用但是没有具体意义的词 (又叫做停止词),例如“的” “了” “和”等词具有较高的权重。所以统计完词频之后需要先进行停止词的过滤再执行特征降维。去除掉停止词后可以大幅提高TF 作为特征权重的计算精度。
2.4 url排序策略
在得到用户定制主题的模型之后,我们可以在基于best-first的策略上进行改进。我们使用url所在页面对应的文本向 量vw(xw,1,xw,2,...,xw,m)与 用 户 定 制 主 题 中 心 点Mu(xu,1,xu,1,...,xu,m)的余弦相似度Sim(vw,Mu)来作为url优先级的衡量标准
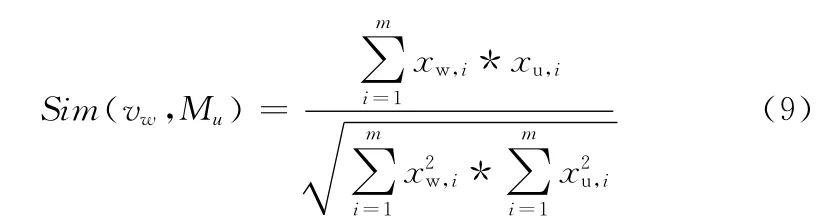
Sim(vw,Mu)越接近1,则页面vw与主题就越接近,该页面上的url在队列中排序越靠前。
3 用户定制主题爬虫实现
基于自适应主题模型,我们实现了用户定制主题聚焦爬虫。
系统框架如图2所示,使用java语言实现。
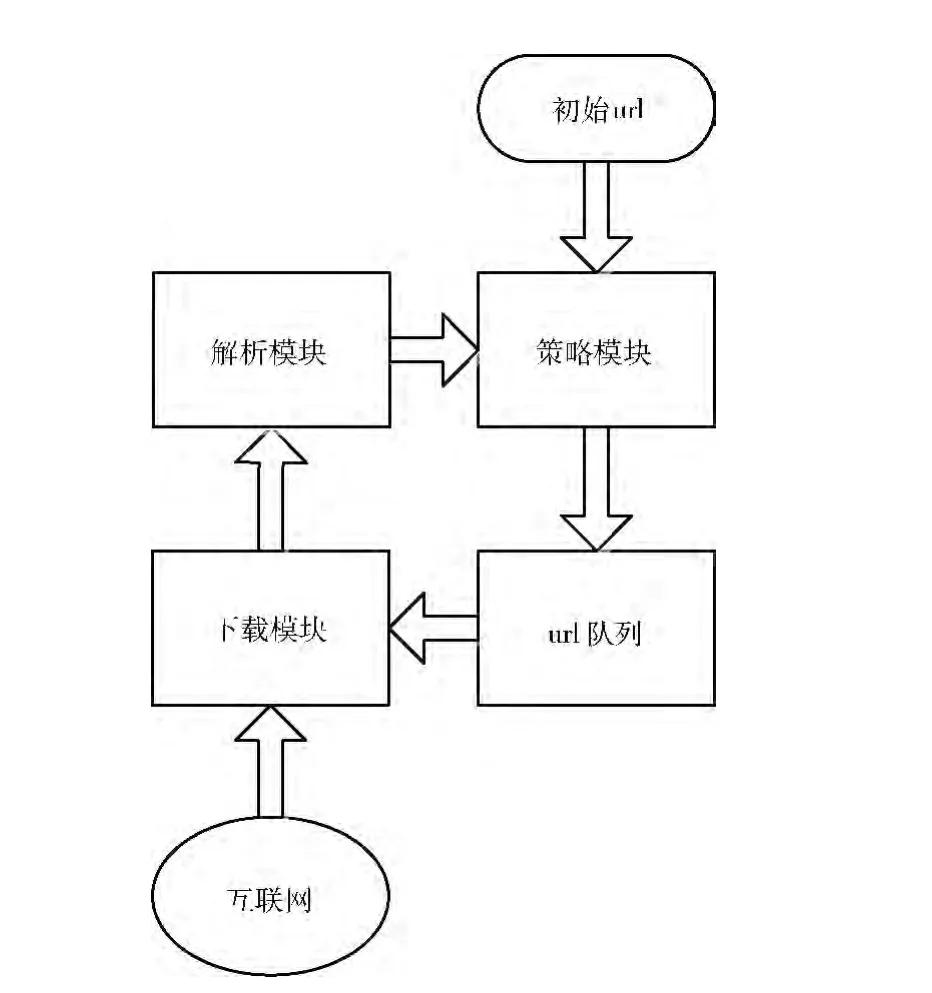
图2 用户定制主题爬虫结构
系统输入为同一主题的初始url,由用户自行指定。
系统框架中,下载模块基于httpclient实现download函数,可以根据url下载网页。
解析模块负责将该网页中的文本和链接解析出来交给策略模块处理。主要实现了两个函数extract_urls和extract_content。这两个函数均使用了第三方java包jsoup。jsoup可以通过css选择器的语法来取得html文档树中的特定节点。extract_urls函数选择所有含有href属性的<a>节点,并过滤掉其中href属性值结尾为exe、jpg等非html页面,最后返回这些链接和对应的锚文本。extract_content函数选择首先判断网页类型是topic型还是hub型,判断依据是所有锚文本的长度占整个页面文本长度的比例,如果该比值大于0.6,则认为该页面是hub型网页,否则认为该页面是topic类型;整个页面文本的提取过程为选择html文档树中所有节点,去掉其中<script>、<iframe>等特殊的节点,最后替换掉剩下节点的文本中换行符、空白符等无意义的符号,即得到了整个页面的文本;对于hub型网页,extract_content返回页面中的所有锚文本,对于topic型网页,extract_content返回页面文本去掉锚文本以后剩下的文本。
策略模块模块实现两个功能,一是依据自适应主题模型对初始url建模。过程为首先下载用户给出的初始链接,调用extract_content函数提取文本内容并完成特征提取,基于VSM 模型把网页文本转换为文本向量,然后计算这些文本向量的中心作为初始主题中心,并在后续的流程中更新主题中心。策略模块另一个功能是分析网页文本,对其中的未爬取url进行优先级评估,加入url队列并排序。具体做法为提取下载网页的文本和url,转换网页文本为文本向量,计算该向量和定制主题中心的距离,把该页面上的url去重后加入队列,并根据该距离对队列中的url进行排序。
系统工作流程如图3所示。
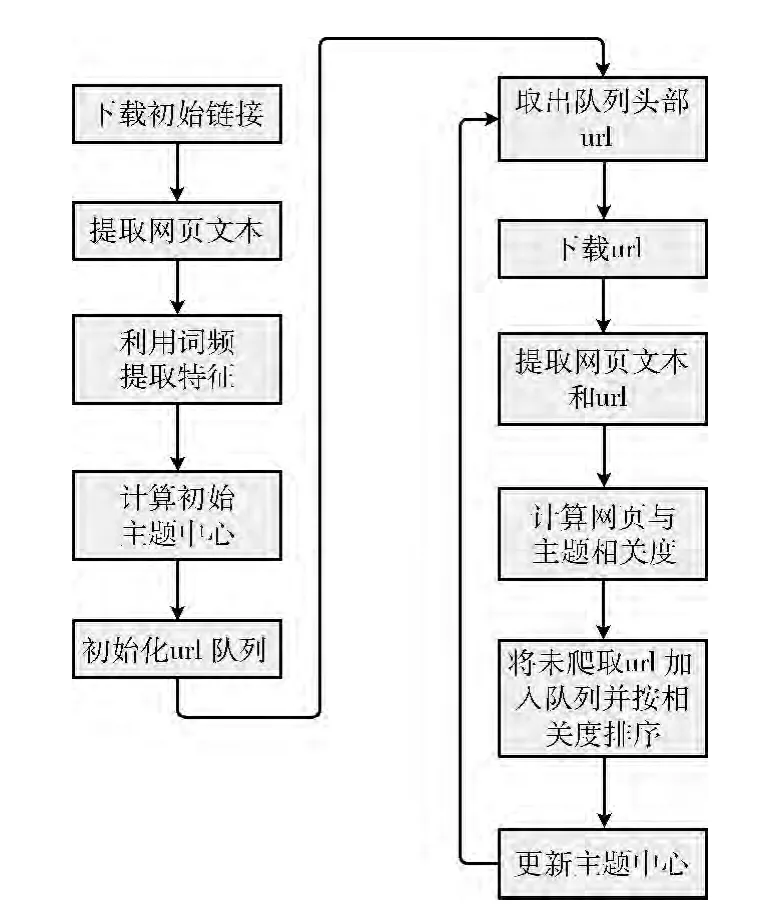
图3 用户定制主题爬虫工作流程
4 实 验
4.1 评价体系
通常情况下使用收获率 (HavestRate)来评价一个聚焦爬虫的性能
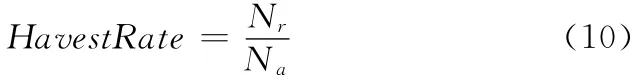
式中:Na——爬取网页的总量,Nr——爬取网页中和主题相关网页的数量。HavestRate 越高,则爬取相同数量网页的情况下,相关网页的数量就越高。在带宽一定的情况下,HavestRate 较高的聚焦爬虫能够在相同的时间内获取更多主题相关的网页,效率也就更高。
4.2 实验结果
为了客观评价该聚焦爬虫的性能,我们以使用bestfirst策略和width-first(宽度优先)策略的爬虫作为对比。
3个爬虫都给定相同的10个体育新闻链接作为初始种子,基于best-first策略的爬虫事先使用搜狗语料库[10]进行主题的训练。
在3个爬虫各爬取了3000 个网页后对爬行过程中HavestRate 的变化统计如图4所示。从图中可以看到使用width-first策略的爬虫的效率最低,在爬行了3000个网页之后HavestRate降到40%以下。使用best-first策略的爬虫的效率最高,稳定以后HavestRate 基本能保持在75%以上。基于自适应主题模型的策略效率比best-first策略略低,在70%上下浮动,但也远远高于使用width-first策略的爬虫。比best-first策略效率低的原因是基于best-first策略的爬虫使用了语料库进行了训练,在特征提取和特征权重的计算上具有优势,并且拥有更多的数据来确定主题向量。
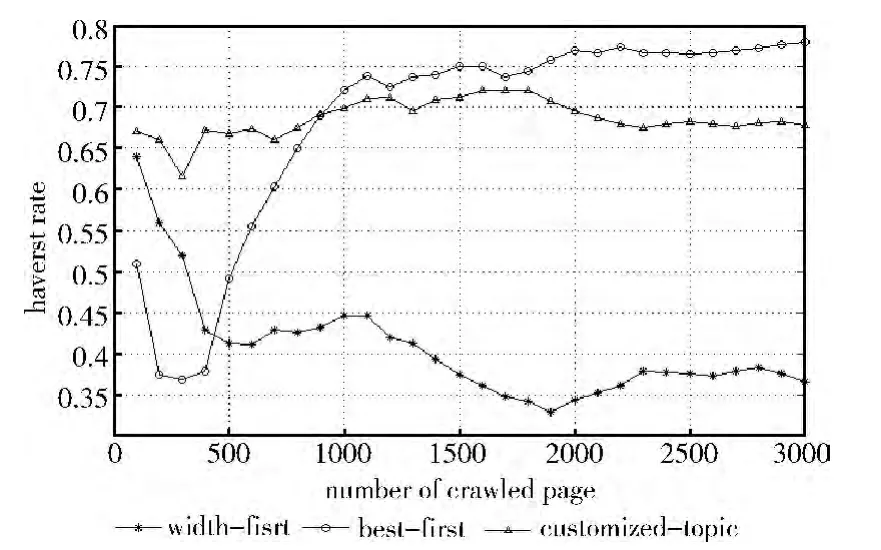
图4 实验结果
5 结束语
为解决传统聚焦爬虫无法对未知主题爬行的问题,本文提出了基于聚类算法的自适应主题建模方法和修正方法,并基于该模型实现用户定制主题聚焦爬虫。通过对比实验验证,在没有使用训练集的情况下,该爬虫达到了和使用训练集主题爬虫相当的效率。在用户只提供少量同一主题url的情况下,该爬虫就可以完成未知主题的爬行,这点是传统主题爬虫无法比拟的优势,具有实际的应用价值。
[1]PENG Tao.Reseach on topical web crawling technique for topic-specific search engine [D].Changchun:Jilin University,2007 (in Chinese).[彭涛.面向专业搜索引擎的主题爬行技术研究 [D].长春:吉林大学,2007.]
[2]Hati D,Kuma A.UDBFC:An effective focused crawling approach based on URL distance calculation [C]//Computer Science and Information Technology,2010.
[3]Taylan D,Dogus Univ,Poyraz M,et al.Intelligent focused crawler:Learning which links to crawl[C]//Innovations in Intelligent Systems and Applications,2011.
[4]Almpanidis G,Kotropoulos C,Pitas I.Combining text and link analysis for focused crawling-an application for vertical search engines [J].Information Systems,2007,32 (6):886-908.
[5]Hong Weihao,Cui Xiamu,Xu Chengyin.An improved topic relevance algorithm for focused crawling [C]//Systems,Man,and Cybernetics,2011.
[6]Yang SY.A focused crawler with ontology-supported website models for information agents[C]//Expert Systems with Applications,2010.
[7]Punam Bedi,Anjali Thukral,Hema Banati.Focused crawling of tagged web resources using ontology [J].Computers and Electrical Engineering,2013,39 (2):613-628.
[8]Sotiris Batsakis,Euripides GM Petrakis,Evangelos Milios.Improving the performance of focused web crawlers[J].Data&Knowledge Engineering,2009,68 (10):1001-1013.
[9]Du Yajun,Hai Yufeng.Semantic ranking of web pages based on formal concept analysis [J].Journal of Systems and Software,2013,86 (1):187-197.
[10]Sogou corpus [EB/OL].http://www.sogou.com/labs/dl/c.html,2013 (in Chinese). [Sogou语料库 [EB/OL].http://www.sogou.com/labs/dl/c.html,2013.]
猜你喜欢
房地产导刊(2022年10期)2022-10-18 08:03:52
保健医苑(2022年1期)2022-08-30 08:39:14
现代信息科技(2021年21期)2021-05-07 02:54:12
电子制作(2018年10期)2018-08-04 03:24:38
电子测试(2018年1期)2018-04-18 11:53:04
电子制作(2017年2期)2017-05-17 03:54:56
电子制作(2017年9期)2017-04-17 03:00:46
电子测试(2015年18期)2016-01-14 01:22:58
计算机与网络(2014年7期)2014-03-25 10:57:07
电脑爱好者(2011年11期)2011-06-22 08:20:18
